Mit der Visualisierung des Abfrageplans können Sie schnell die Struktur des Abfrageplans nachvollziehen, der von Spanner zum Bewerten einer Abfrage ausgewählt wurde. In diesem Leitfaden wird beschrieben, wie Sie einen Abfrageplan verwenden können, um die Ausführung Ihrer Abfragen besser nachvollziehen zu können.
Hinweise
Lesen Sie sich die folgenden Informationen durch, um sich mit den in dieser Anleitung genannten Teilen der Google Cloud Console-Benutzeroberfläche vertraut zu machen:
Abfrage in der Google Cloud Konsole ausführen
- Rufen Sie in der Google Cloud Console die Seite Spanner-Instanzen auf.
-
Wählen Sie den Namen der Instanz aus, die die Datenbank enthält, die Sie abfragen möchten.
In derGoogle Cloud console wird die Seite Übersicht der Instanz angezeigt.
-
Wählen Sie den Namen der Datenbank aus, die Sie abfragen möchten.
In derGoogle Cloud -Konsole wird die Seite Übersicht der Datenbank angezeigt.
-
Klicken Sie im Seitenmenü auf Spanner Studio.
In derGoogle Cloud -Konsole wird die Seite Spanner Studio der Datenbank angezeigt.
- Geben Sie die SQL-Abfrage in den Editorbereich ein.
-
Klicken Sie auf Ausführen.
Spanner führt die Abfrage aus.
- Klicken Sie auf den Tab Erklärung, um die Abfrageplan-Visualisierung anzuzeigen.
Einführung in den Abfrageeditor
Die Spanner Studio-Seite enthält Abfrage-Tabs, auf denen Sie SQL-Abfrage- und DML-Anweisungen eingeben oder einfügen, diese für Ihre Datenbank ausführen und deren Ergebnisse und Abfrageausführungspläne aufrufen können. Die Schlüsselkomponenten der Spanner Studio-Seite sind im folgenden Screenshot nummeriert.
- In der Tab-Leiste werden die geöffneten Abfragetabs angezeigt. Wenn Sie einen neuen Tab erstellen möchten, klicken Sie auf Neuer Tab.
Die Tableiste enthält auch eine Liste von Abfragevorlagen, die Sie verwenden können, um Abfragen einzufügen, die Informationen zu Datenbankabfragen, Transaktionen, Lesevorgängen und mehr liefern. Weitere Informationen hierzu finden Sie unter Überblick über Tools zur Selbstbeobachtung.
- In der Befehlsleiste des Editors finden Sie die folgenden Optionen:
- Der Befehl Ausführen führt die im Bearbeitungsbereich eingegebenen Anweisungen aus und erzeugt Abfrageergebnisse auf dem Tab Ergebnisse und Abfrageausführungspläne auf dem Tab Erklärung. Ändern Sie das Standardverhalten über das Drop-down-Menü, um die Optionen Nur Ergebnisse oder Nur Erklärung zu verwenden.
Wenn Sie etwas im Editor markieren, wird der Befehl Ausführen in Auswahl ausführen geändert, sodass Sie nur das ausführen können, was Sie ausgewählt haben.
- Mit dem Befehl Abfrage löschen wird der gesamte Text im Editor gelöscht und die Untertabs Ergebnisse und Erklärung werden geleert.
- Mit dem Befehl Format query (Abfrage formatieren) werden Anweisungen im Editor so formatiert, dass sie leichter zu lesen sind.
- Mit dem Befehl Tastenkombinationen wird eine Liste der Tastenkombinationen angezeigt, die Sie im Editor verwenden können.
- Über den Link Hilfe zur SQL-Abfrage wird ein Browser-Tab mit der Dokumentation zur SQL-Abfragesyntax geöffnet.
Abfragen werden automatisch validiert, wenn sie im Editor aktualisiert werden. Wenn die Anweisungen gültig sind, wird in der Befehlsleiste des Editors ein Bestätigungshäkchen und die Meldung Gültig angezeigt. Falls Probleme auftreten, wird eine Fehlermeldung mit Details angezeigt.
- Der Befehl Ausführen führt die im Bearbeitungsbereich eingegebenen Anweisungen aus und erzeugt Abfrageergebnisse auf dem Tab Ergebnisse und Abfrageausführungspläne auf dem Tab Erklärung. Ändern Sie das Standardverhalten über das Drop-down-Menü, um die Optionen Nur Ergebnisse oder Nur Erklärung zu verwenden.
- Im Editor geben Sie SQL-Abfrage und DML-Anweisungen ein.
Sie sind farblich gekennzeichnet und für mehrzeilige Anweisungen werden automatisch Zeilennummern hinzugefügt.
Wenn Sie mehr als eine Anweisung im Editor eingeben, müssen Sie nach jeder Anweisung ein abschließendes Semikolon verwenden, mit Ausnahme der letzten.
- Der untere Bereich eines Abfragetabs enthält drei Untertabs:
- Auf dem Untertab Schema werden die Tabellen in der Datenbank und ihre Schemas angezeigt. Sie können sie als schnelle Referenz beim Verfassen von Anweisungen im Editor verwenden.
- Auf dem Untertab Ergebnisse werden die Ergebnisse angezeigt, wenn Sie die Anweisungen im Editor ausführen. Bei Abfragen wird eine Ergebnistabelle angezeigt und bei DML-Anweisungen wie
INSERTund >UPDATEwird eine Meldung angezeigt, wie viele Zeilen betroffen waren. - Auf dem Untertab Erklärung werden visuelle Grafiken der Abfragepläne angezeigt, die beim Ausführen der Anweisungen im Editor erstellt werden.
- Die Untertabs Ergebnisse und Erklärung bieten beide eine Anweisungsauswahl, mit der Sie die Anweisung auswählen können, deren Ergebnisse oder Abfrageplan Sie aufrufen möchten.
Abfragepläne mit Stichproben ansehen
- Rufen Sie in der Google Cloud Console die Seite Spanner-Instanzen auf.
-
Klicken Sie auf den Namen der Instanz mit den Anfragen, die Sie untersuchen möchten.
In derGoogle Cloud console wird die Seite Übersicht der Instanz angezeigt.
-
Klicken Sie im Menü Navigation unter der Überschrift „Observability“ auf Query Insights.
In derGoogle Cloud console wird die Seite Statistiken zu Anfragen der Instanz angezeigt.
-
Wählen Sie im Datenbank-Drop-down-Menü die Datenbank mit den zu untersuchenden Anfragen aus.
In derGoogle Cloud -Konsole werden die Informationen zur Abfragelast für die Datenbank angezeigt. In der Tabelle „Top-N-Abfragen und -Anfrage-Tags“ wird die Liste der Top-Abfragen und ‑Anfrage-Tags nach CPU-Auslastung sortiert angezeigt.
-
Suchen Sie die Abfrage mit hoher CPU-Auslastung, für die Sie Stichproben von Abfrageplänen ansehen möchten. Klicken Sie auf den FPRINT-Wert dieser Abfrage.
Auf der Seite Abfragedetails sehen Sie ein Diagramm mit Beispielabfrageplänen für Ihre Abfrage im Zeitverlauf. Sie können maximal sieben Tage vor der aktuellen Zeit herauszoomen. Hinweis: Abfragepläne werden für Abfragen mit partitionTokens, die über die PartitionQuery API abgerufen wurden, und für partitionierte DML-Abfragen nicht unterstützt.
-
Klicken Sie auf einen der Punkte im Diagramm, um einen älteren Abfrageplan aufzurufen und die Schritte während der Abfrageausführung zu visualisieren. Sie können auch auf einen beliebigen Operator klicken, um erweiterte Informationen dazu aufzurufen.
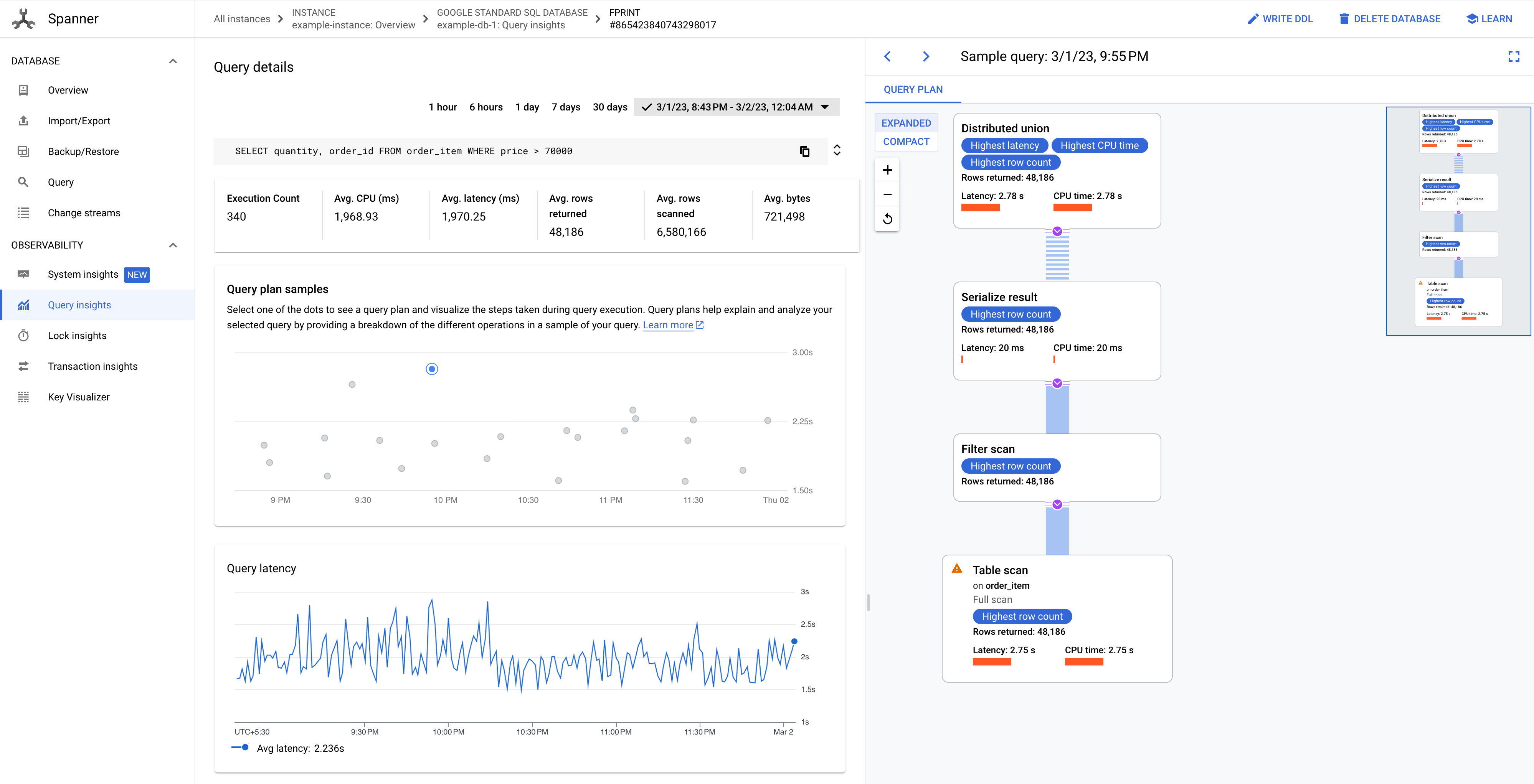
Abbildung 8: Diagramm „Beispiele für Abfragepläne“
In einigen Fällen möchten Sie möglicherweise Stichproben von Abfrageplänen ansehen und die Leistung einer Abfrage im Zeitverlauf vergleichen. Für Abfragen, die mehr CPU verbrauchen, behält Spanner Stichproben von Abfrageplänen 30 Tage lang auf der Seite Query Insights der Google Cloud -Konsole bei. So rufen Sie Stichproben von Abfrageplänen auf:
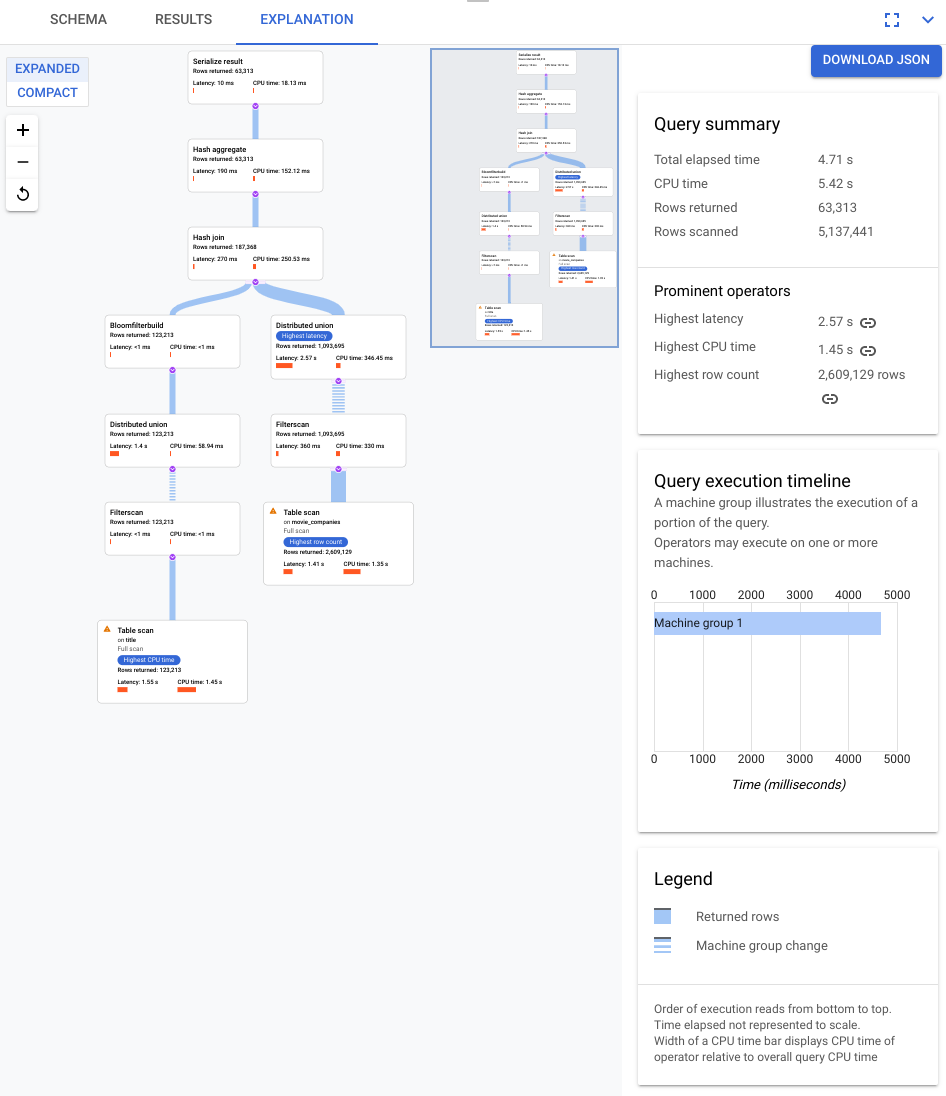
Einführung in die Abfrageplan-Visualisierung
Die Schlüsselkomponenten der Visualisierung sind im folgenden Screenshot annotiert und ausführlicher beschrieben. Nachdem Sie eine Abfrage auf einem Abfragetab ausgeführt haben, wählen Sie den Tab ERKLÄRUNG unter dem Abfrageeditor aus, um die Visualisierung des Abfrageausführungsplans zu öffnen.
Der Datenfluss im folgenden Diagramm ist von unten nach oben, d. h. alle Tabellen und Indexe befinden sich unten im Diagramm und die endgültige Ausgabe oben.
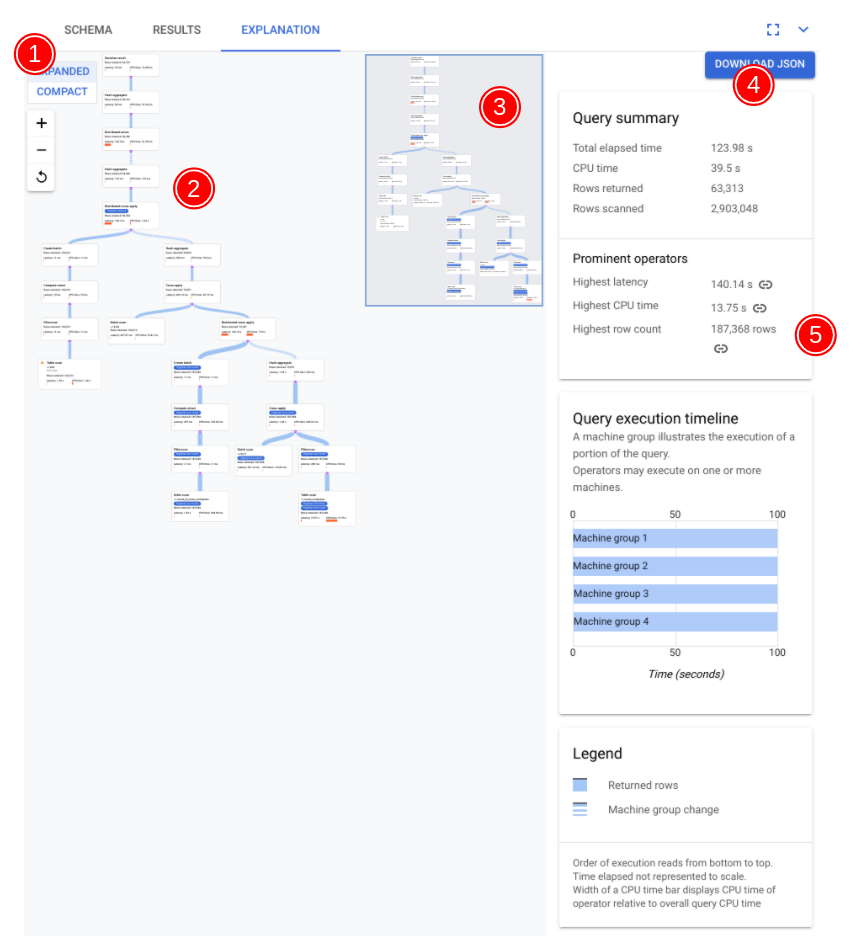
- Die Visualisierung Ihres Plans kann je nach ausgeführter Abfrage groß sein. Wenn Sie Details ein- oder ausblenden möchten, verwenden Sie die Ansichtsauswahl ERWEITERT/KOMPAKT. Mit der Zoomsteuerung können Sie festlegen, wie viel vom Plan Sie jeweils sehen.
- Die Algebra, die beschreibt, wie Spanner die Abfrage ausführt, wird als azyklischer Graph dargestellt. Jeder Knoten entspricht einem Iterator, der Zeilen aus seinen Eingaben verarbeitet und Zeilen für das übergeordnete Element erzeugt. Ein Beispielplan ist in Abbildung 9 dargestellt. Klicken Sie auf das Diagramm, um eine vergrößerte Ansicht einiger Details des Plans aufzurufen.
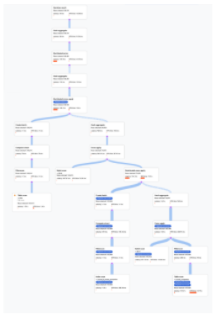
Abbildung 9. Beispiel für einen visuellen Plan (zum Vergrößern klicken) 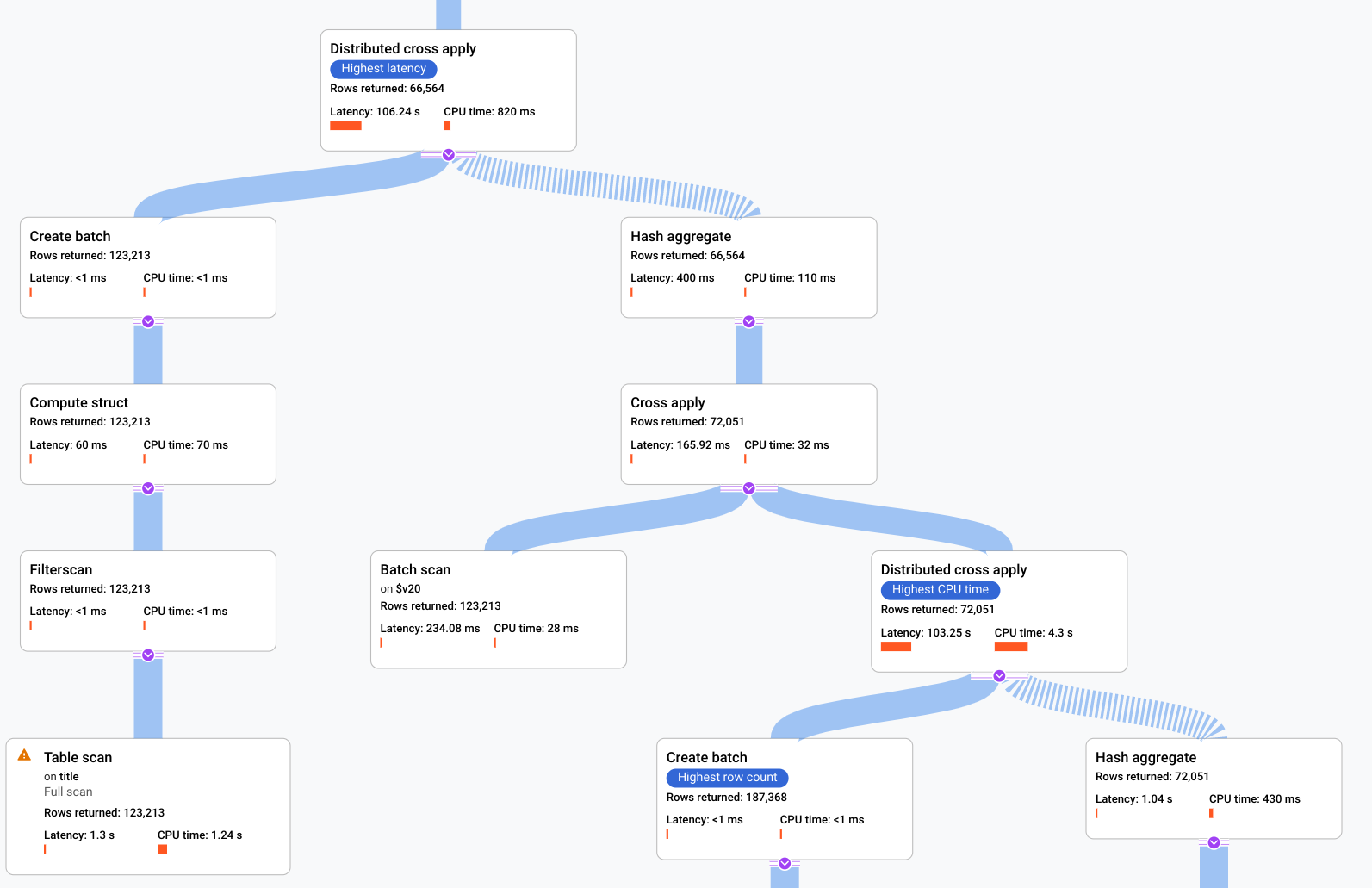
Jeder Knoten oder jede Karte im Graph stellt einen Iterator dar und enthält die folgenden Informationen:
- Der Name des Iterators. Ein Iterator verarbeitet Zeilen aus seiner Eingabe und erzeugt Zeilen.
- Laufzeitstatistiken, die angeben, wie viele Zeilen zurückgegeben wurden, wie hoch die Latenz war und wie viel CPU verbraucht wurde.
- Wir stellen die folgenden visuellen Hinweise zur Verfügung, um Ihnen zu helfen, potenzielle Probleme im Abfrageausführungsplan zu erkennen.
- Rote Balken in einem Knoten sind visuelle Indikatoren für den Prozentsatz der Latenz oder CPU-Zeit für diesen Iterator im Vergleich zum Gesamtwert für die Abfrage.
- Die Dicke der Linien, die die einzelnen Knoten verbinden, entspricht der Anzahl der Zeilen. Je dicker die Linie, desto mehr Zeilen werden an den nächsten Knoten übergeben. Die tatsächliche Anzahl der Zeilen wird auf jeder Karte und angezeigt, wenn Sie den Mauszeiger auf einen Connector bewegen.
- Auf einem Knoten, für den ein vollständiger Tabellenscan durchgeführt wurde, wird ein Warndreieck angezeigt. Weitere Details im Infobereich enthalten Empfehlungen wie das Hinzufügen eines Index oder das Überarbeiten der Abfrage oder des Schemas, um einen vollständigen Scan zu vermeiden.
- Wählen Sie eine Karte im Plan aus, um Details im Informationsfenster auf der rechten Seite aufzurufen (5).
- Die Miniübersicht des Ausführungsplans zeigt eine verkleinerte Ansicht des gesamten Plans an und ist nützlich, um die Gesamtform des Ausführungsplans zu bestimmen und schnell zu verschiedenen Teilen des Plans zu wechseln. Ziehen Sie den Mauszeiger direkt auf der Miniübersicht oder klicken Sie auf die Stelle, auf die Sie den Fokus richten möchten, um zu einem anderen Teil des visuellen Plans zu gelangen.
Wählen Sie JSON HERUNTERLADEN aus, um eine JSON-Version des Ausführungsplans herunterzuladen. Dies ist hilfreich bei der Fehlerbehebung. Sie können sie auch weitergeben, wenn Sie sich für Support an das Spanner-Team wenden. Wenn Sie die JSON-Datei speichern, wird nicht das Ergebnis der Abfrage gespeichert.
So laden Sie eine JSON-Version des Ausführungsplans herunter und speichern sie, um sie später zu visualisieren:
- Führen Sie in Spanner Studio eine Abfrage aus.
- Wählen Sie den Tab Erklärung aus.
- Klicken Sie auf JSON HERUNTERLADEN, um die JSON-Version des Ausführungsplans herunterzuladen.
- Speichern Sie den Inhalt der JSON-Datei und kopieren Sie ihn.
- Öffnen Sie einen neuen Tab für den Abfrageeditor.
- Geben Sie im Editor-Tab Folgendes ein:
PROTO: CONTENT_OF_JSON
- Klicken Sie auf Ausführen.
- Wählen Sie unter dem Abfrageeditor den Tab Erklärung aus, um eine visuelle Darstellung des heruntergeladenen Ausführungsplans aufzurufen.
- Im Informationsbereich werden detaillierte Kontextinformationen zum ausgewählten Knoten im Abfrageplandiagramm angezeigt. Die Informationen sind in die folgenden Kategorien unterteilt.
- Iterator-Informationen enthalten Details sowie Laufzeitstatistiken für die Iterator-Karte, die Sie im Graph ausgewählt haben.
- Die Abfragezusammenfassung enthält Details zur Anzahl der zurückgegebenen Zeilen und zur Ausführungszeit der Abfrage. Hervorgehobene Operatoren sind solche, die eine erhebliche Latenz aufweisen, eine erhebliche Menge an CPU im Vergleich zu anderen Operatoren verbrauchen und eine erhebliche Anzahl von Datenzeilen zurückgeben.
- Die Zeitachse der Abfrageausführung ist ein zeitbasierter Graph, der zeigt, wie lange jede Maschinengruppe ihren Teil der Abfrage ausgeführt hat. Es kann sein, dass eine Maschinengruppe nicht unbedingt für die gesamte Dauer der Abfrage ausgeführt wird. Es ist auch möglich, dass eine Maschinengruppe während der Ausführung der Abfrage mehrmals ausgeführt wurde. Die Zeitachse zeigt hier jedoch nur den Beginn der ersten Ausführung und das Ende der letzten Ausführung an.
Abfrage mit geringer Leistung optimieren
Angenommen, Ihr Unternehmen betreibt eine Online-Filmdatenbank mit Informationen zu Filmen wie Besetzung, Produktionsfirmen, Filmdetails usw. Der Dienst wird auf Spanner ausgeführt, hat aber in letzter Zeit einige Leistungsprobleme.
Als Hauptentwickler des Dienstes werden Sie gebeten, diese Leistungsprobleme zu untersuchen, da sie zu schlechten Bewertungen des Dienstes führen. Sie öffnen die Google Cloud Console, rufen Ihre Datenbankinstanz auf und öffnen dann den Abfrageeditor. Geben Sie die folgende Abfrage in den Editor ein und führen Sie sie aus.
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
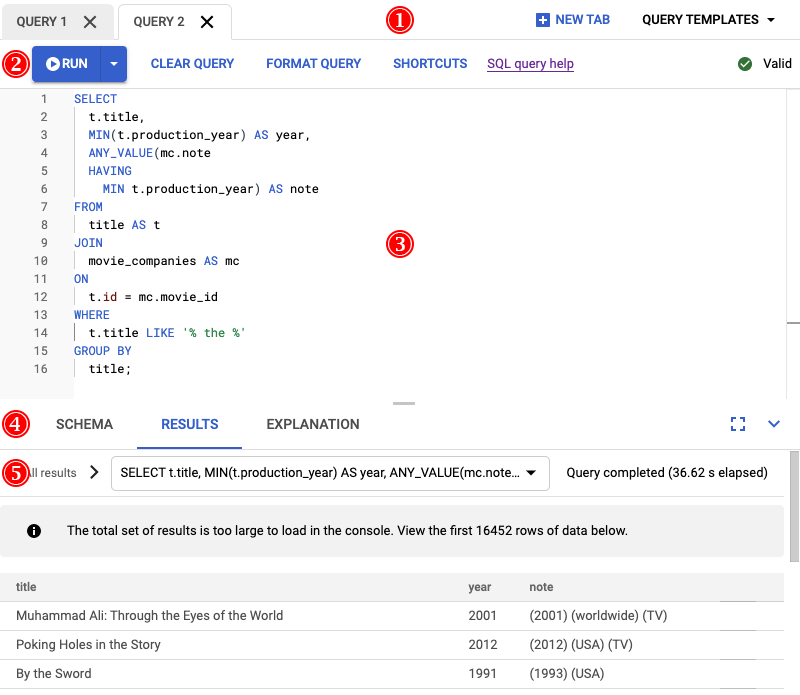
Das Ergebnis der Ausführung dieser Abfrage ist im folgenden Screenshot zu sehen. Wir haben die Abfrage im Editor formatiert, indem wir ABFRAGE FORMATIEREN ausgewählt haben. Außerdem wird oben rechts auf dem Bildschirm angezeigt, dass die Anfrage gültig ist.
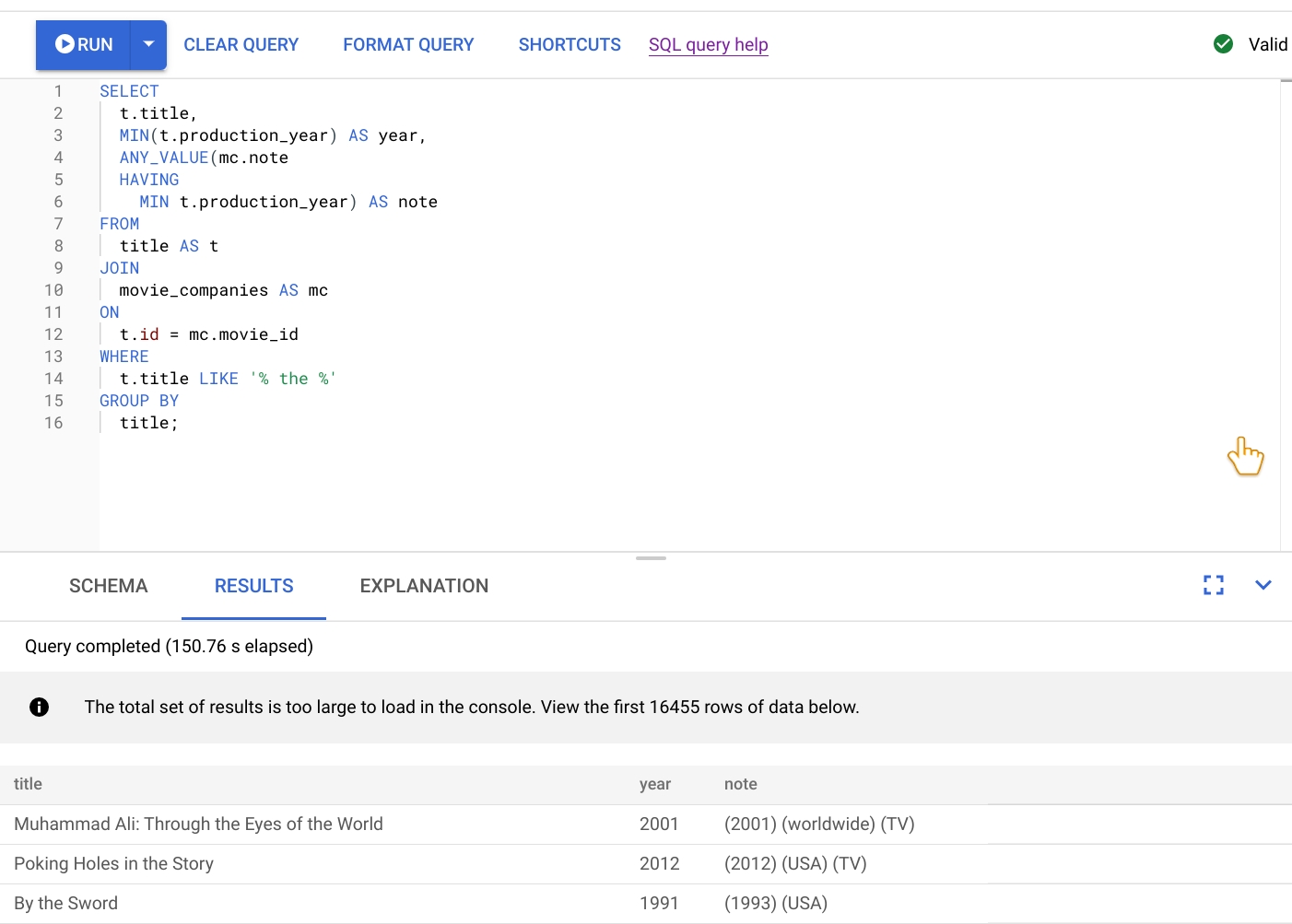
Auf dem Tab ERGEBNISSE unter dem Abfrageeditor sehen Sie, dass die Abfrage in etwas mehr als zwei Minuten abgeschlossen wurde. Sie sehen sich die Abfrage genauer an, um festzustellen, ob sie effizient ist.
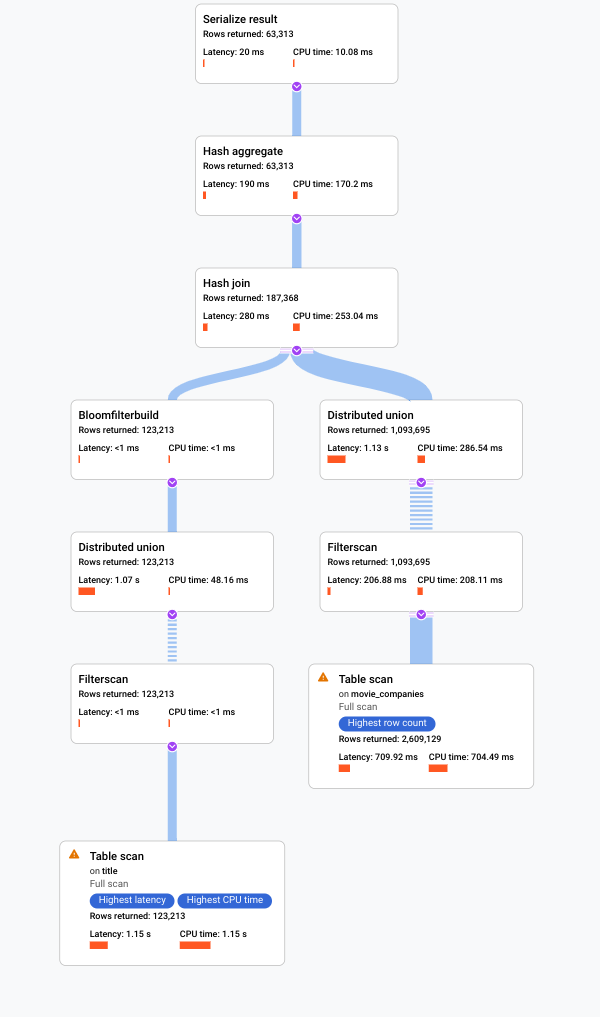
Langsame Abfrage mit der Abfrageplan-Visualisierung analysieren
An dieser Stelle wissen wir, dass die Abfrage im vorherigen Schritt mehr als zwei Minuten dauert, wir wissen jedoch nicht, ob die Abfrage so effizient wie möglich ist und ob diese Dauer daher erwartbar ist.
Wählen Sie den Tab ERKLÄRUNG direkt unter dem Abfrageeditor aus, um eine visuelle Darstellung des Ausführungsplans aufzurufen, den Spanner zum Ausführen der Abfrage und Zurückgeben der Ergebnisse erstellt hat.
Der im folgenden Screenshot gezeigte Plan ist relativ groß. Selbst bei dieser Zoomstufe können Sie jedoch Folgendes erkennen.
Anhand der Zusammenfassung der Abfrage im Informationsbereich rechts sehen wir, dass fast 3 Millionen Zeilen gescannt und weniger als 64.000 zurückgegeben wurden.
Im Bereich Zeitachse der Abfrageausführung sehen wir außerdem, dass vier Maschinengruppen an der Abfrage beteiligt waren. Eine Maschinengruppe ist für die Ausführung eines Teils der Abfrage verantwortlich. Operatoren können auf einer oder mehreren Maschinen ausgeführt werden. Wenn Sie in der Zeitachse eine Maschinengruppe auswählen, wird im visuellen Plan hervorgehoben, welcher Teil der Abfrage in dieser Gruppe ausgeführt wurde.
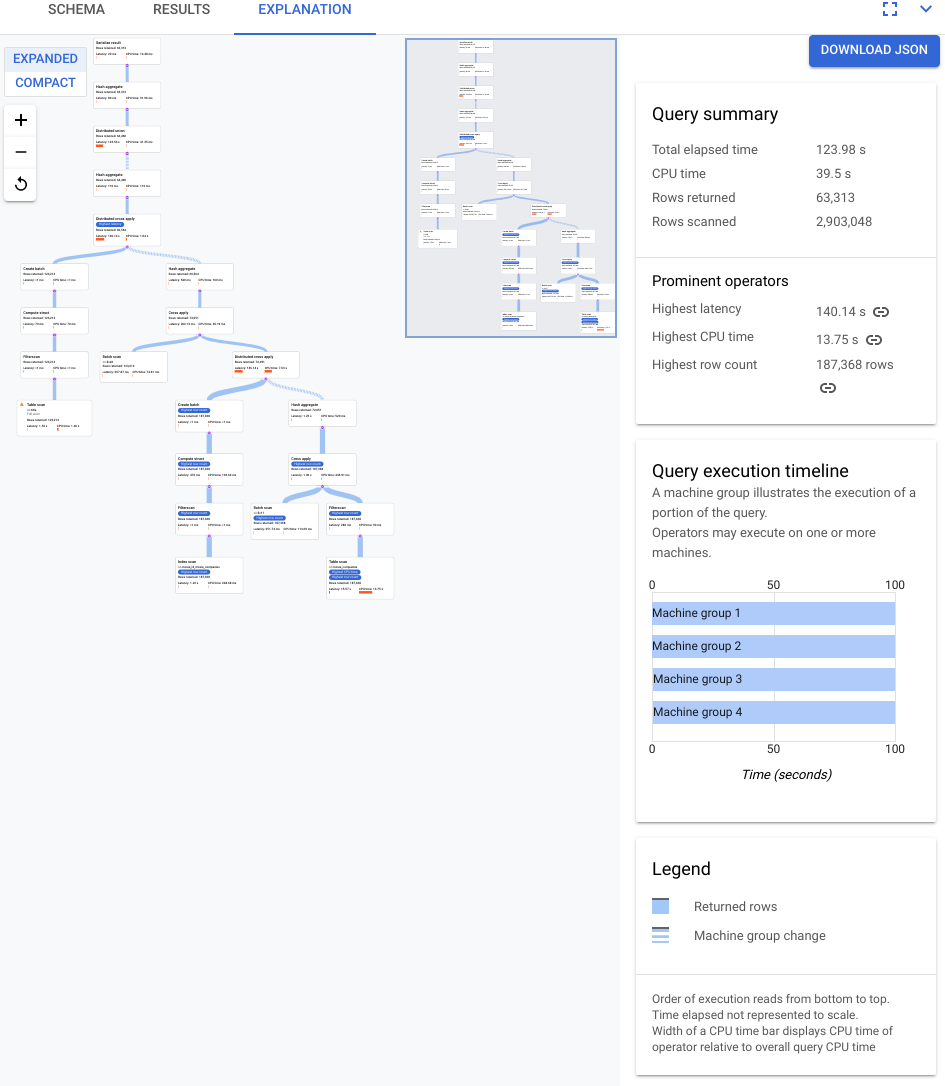
Aufgrund dieser Faktoren entscheiden Sie, dass eine Leistungsverbesserung möglich ist, indem Sie den Join von einem Apply-Join, der von Spanner standardmäßig ausgewählt wurde, zu einem Hash-Join ändern.
Abfrage verbessern
Um die Leistung der Abfrage zu verbessern, verwenden Sie einen Join-Hinweis, um die Join-Methode in einen Hash-Join zu ändern. Diese Join-Implementierung führt eine setbasierte Verarbeitung aus.
Hier ist die aktualisierte Abfrage:
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
Der folgende Screenshot zeigt die aktualisierte Abfrage. Wie im Screenshot zu sehen ist, wurde die Abfrage in weniger als 5 Sekunden abgeschlossen. Das ist eine deutliche Verbesserung gegenüber den 120 Sekunden, die vor dieser Änderung erforderlich waren.
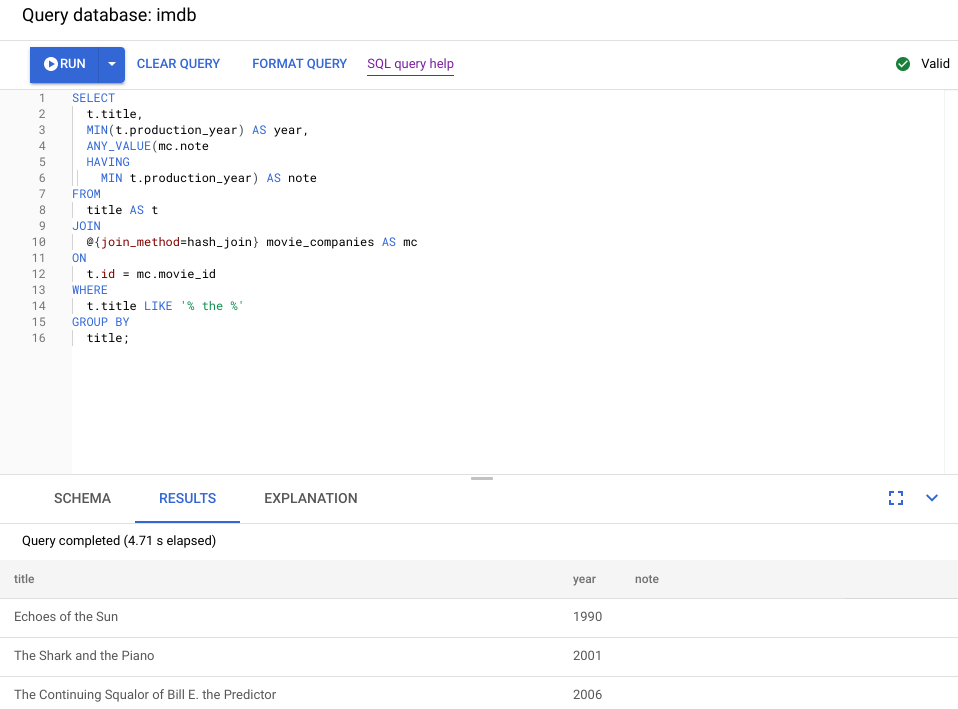
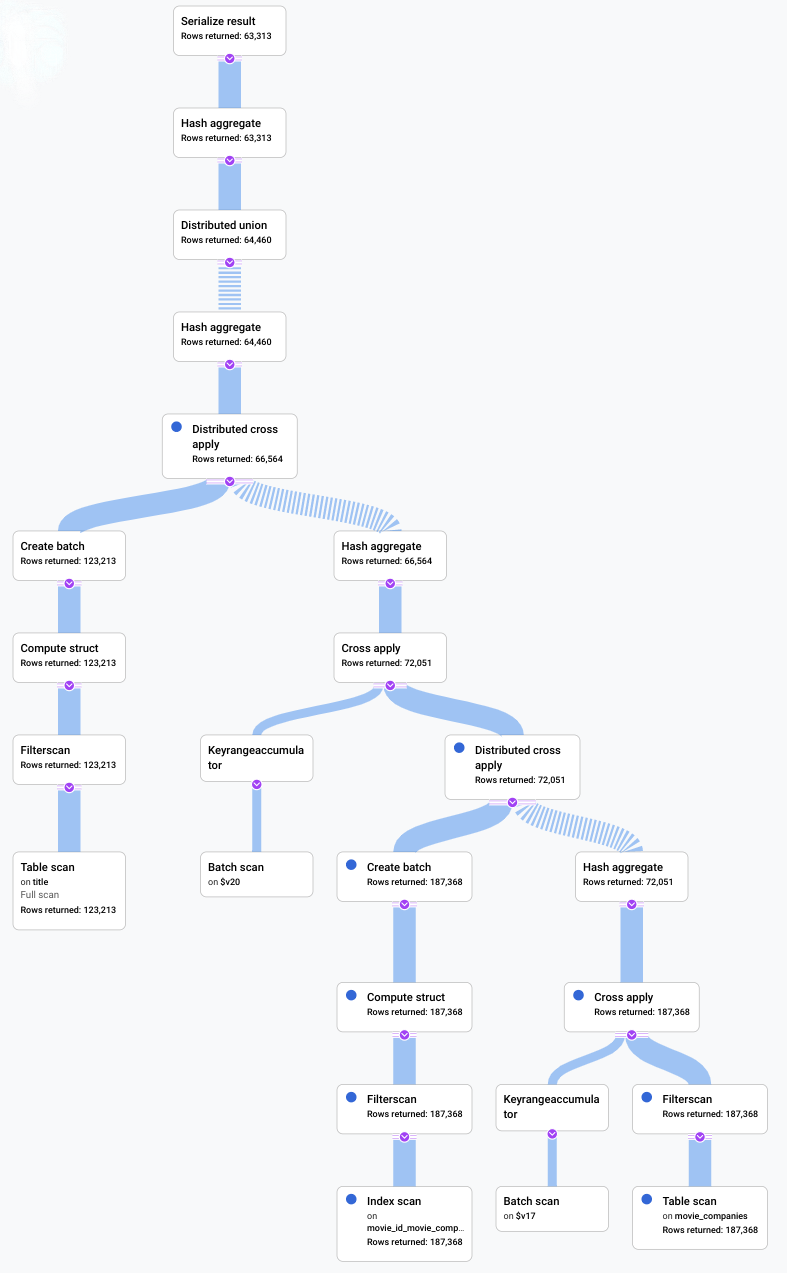
Sehen wir uns den neuen visuellen Plan an, der im folgenden Diagramm dargestellt ist, um zu erfahren, was er uns über diese Verbesserung verrät.
Sie können augenblicklich einige Unterschiede bemerken:
An der Ausführung dieser Abfrage war nur eine Maschinengruppe beteiligt.
Die Anzahl der Aggregationen wurde drastisch reduziert.
Fazit
In diesem Szenario haben wir eine langsame Abfrage ausgeführt und uns den visuellen Plan angesehen, um nach Ineffizienzen zu suchen. Im Folgenden finden Sie eine Zusammenfassung der Anfragen und Pläne vor und nach den Änderungen. Auf jedem Tab wird die ausgeführte Abfrage und eine kompakte Ansicht der Visualisierung des vollständigen Abfrageausführungsplans angezeigt.
Vor
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
Nach
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
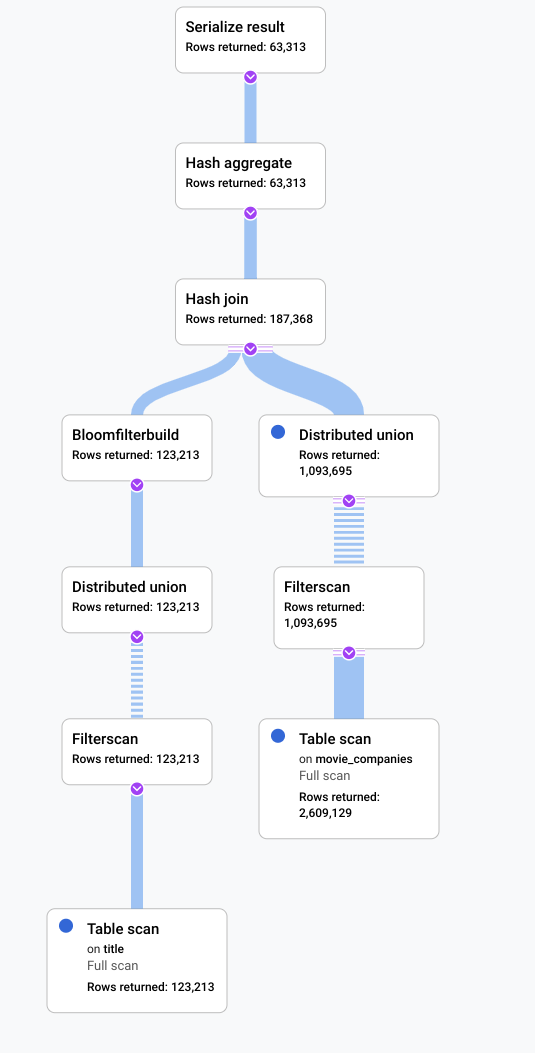
Ein Indikator dafür, dass in diesem Szenario etwas verbessert werden könnte, war, dass ein großer Anteil der Zeilen aus der Tabelle Titel den Filter LIKE
'% the %' qualifiziert hat. Die Suche in einer anderen Tabelle mit so vielen Zeilen ist wahrscheinlich teuer. Durch das Ändern unserer Join-Implementierung in einen Hash-Join wurde die Leistung erheblich verbessert.
Nächste Schritte
Die vollständige Abfrageplanreferenz finden Sie unter Abfrageausführungspläne.
Die vollständige Operatorreferenz finden Sie unter Abfrageausführungsoperatoren.