Spanner ist eine stark konsistente, verteilte, skalierbare Datenbank, die von Google-Ingenieuren dafür entwickelt wurde, einige der wichtigsten Anwendungen von Google zu unterstützen. Es erweitert zentrale Ideen aus der Datenbank und den verteilten System-Communities auf ganz neue Weise. Spanner stellt diesen internen Spanner-Dienst als öffentlich verfügbaren Dienst auf der Google Cloud Platform bereit.
Da es die anspruchsvollen Betriebszeiten und Skalierungsanforderungen der wichtigsten Geschäftsanwendungen von Google bewältigen muss, ist Spanner von Grund auf als eine weit verbreitete Datenbank aufgebaut – der Dienst kann mehrere Rechner sowie mehrere Rechenzentren und Regionen umfassen. Diese Verteilung dient dazu, große Datensätze und große Arbeitslasten zu bewältigen, wobei gleichzeitig eine sehr hohe Verfügbarkeit garantiert wird. Spanner sollte außerdem die gleichen starken Konsistenzgarantien bieten, die von anderen Unternehmensdatenbanken bereitgestellt werden, um Entwicklern die Arbeit mit der Anwendung zu erleichtern. Es ist viel einfacher, Software für eine Datenbank zu erstellen und zu schreiben, die eine hohe Konsistenz (Strong Consistency) unterstützt, als für eine Datenbank, die nur die Konsistenz auf Zeilenebene, auf Entitätsebene oder überhaupt keine Konsistenz unterstützt.
In diesem Dokument wird beschrieben, wie Schreib- und Lesevorgänge in Spanner funktionieren und wie Spanner für Strong Consistency sorgt.
Ausgangspunkte
Es gibt einige Datensätze, die zu groß für einen einzelnen Rechner sind. Es gibt auch Szenarien, bei denen der Datensatz klein ist, aber die Arbeitslast zu schwer, um von nur einem Rechner verarbeitet zu werden. Es muss also eine Möglichkeit gefunden werden, die Daten in einzelne Teile aufzuteilen, die auf mehreren Rechnern gespeichert werden können. Unser Ansatz besteht darin, die Datenbanktabellen in zusammenhängende Schlüsselbereiche zu partitionieren, die als Splits bezeichnet werden. Ein einzelner Rechner kann mehrere Splits bereitstellen. Außerdem gibt es einen schnellen Suchdienst, um die Rechner zu ermitteln, die einen bestimmten Schlüsselbereich bereitstellen. Die Informationen darüber, wie Daten aufgeteilt werden und auf welchen Rechnern sie sich befinden, sind für Spanner-Nutzer transparent. Das Ergebnis ist ein System, das in der Lage ist, niedrige Latenz selbst bei starker Auslastung und in großen Umfang sowohl für Lese- als auch für Schreibvorgänge bereitzustellen.
Daten müssen auch trotz Fehlern zugänglich sein. Jeder Split wird auf mehreren Geräten in verschiedenen fehlerhaften Domains repliziert, um dies zu gewährleisten. Die konsistente Replikation in den verschiedenen Kopien des Splits wird vom Paxos-Algorithmus verwaltet. Solange ein Großteil der votierenden Replikate für den Split aktiv sind, kann in Paxos eins dieser Replikate als Leader bestimmt werden, der Schreibvorgänge verarbeitet und zulässt, dass andere Replikate Lesevorgänge bereitstellen.
Spanner bietet sowohl schreibgeschützte Transaktionen als auch Lese-Schreib-Transaktionen. Erstere sind der bevorzugte Transaktionstyp für Vorgänge (einschließlich SELECT-Anweisungen in SQL), die Ihre Daten nicht mutieren. Schreibgeschützte Transaktionen stellen weiterhin Strong Consistency bereit und verarbeiten standardmäßig die aktuelle Kopie Ihrer Daten. Sie können aber ausgeführt werden, ohne dass irgendeine interne Sperre erforderlich ist, wodurch sie schneller und skalierbarer sind. Lese-Schreib-Transaktionen werden für Transaktionen verwendet, die Daten einfügen, aktualisieren oder löschen. Dazu gehören auch Transaktionen, die Lesevorgänge gefolgt von einem Schreibvorgang durchführen. Diese sind weiterhin hoch skalierbar, aber schreibgeschützte Transaktionen führen Sperren ein und müssen von Paxos-Leadern orchestriert werden. Beachten Sie, dass das Sperren für Spanner-Clients transparent ist.
Viele frühere verteilte Datenbanksysteme haben aufgrund der kostenintensiven rechnerübergreifenden Kommunikation, die normalerweise erforderlich ist, keine Strong Consistency garantiert. Spanner ist in der Lage, mithilfe der von Google entwickelten Technologie TrueTime über die gesamte Datenbank hinweg Snapshots mit Strong Consistency bereitzustellen. Wie der Flux Capacitor in einer Zeitmaschine ca. im Jahr 1985 ist Spanner nur dank TrueTime möglich. Es handelt sich um eine API, mit der jeder Rechner in einem Google-Rechenzentrum die exakte globale Zeit mit einem hohen Grad an Genauigkeit (d. h. auf einige wenige Millisekunden genau) bestimmen kann. Dies ermöglicht es verschiedenen Spanner-Rechnern, die Reihenfolge von Transaktionsvorgängen oft ganz ohne Kommunikation zu analysieren (und diese Reihenfolge der vom Kunden beobachteten Reihenfolge anzugleichen). Google musste seine Rechenzentren mit spezieller Hardware (Atomuhren) ausstatten, damit TrueTime funktioniert. Die daraus resultierende Zeitgenauigkeit ist viel höher als die Genauigkeit, die von anderen Protokollen erzielt werden kann (z. B. NTP). Insbesondere weist Spanner allen Lese- und Schreibvorgängen einen Zeitstempel zu. Eine Transaktion zum Zeitstempel T1 spiegelt garantiert die Ergebnisse aller Schreibvorgänge wider, die vor T1 stattgefunden haben. Wenn ein Rechner einen Lesevorgang bei T2 erfüllen soll, muss seine Ansicht der Daten mindestens bis T2 aktuell sein. Durch TrueTime ist diese Feststellung in der Regel sehr günstig. Die Protokolle zur Gewährleistung der Konsistenz der Daten sind kompliziert, sie werden jedoch im ursprünglichen Spanner-Artikel und im Artikel zu Spanner und Konsistenz näher beschrieben.
Praktisches Beispiel
Die folgenden Beispiele zeigen, wie das alles funktioniert:
CREATE TABLE ExampleTable (
Id INT64 NOT NULL,
Value STRING(MAX),
) PRIMARY KEY(Id);
In diesem Beispiel haben wir eine Tabelle mit einem einfachen, ganzzahligen Primärschlüssel.
| Split | KeyRange |
|---|---|
| 0 | [-∞,3) |
| 1 | [3,224) |
| 2 | [224,712) |
| 3 | [712,717) |
| 4 | [717,1265) |
| 5 | [1265,1724) |
| 6 | [1724,1997) |
| 7 | [1997,2456) |
| 8 | [2456,∞) |
Angesichts des Schemas für ExampleTable oben ist der Primärschlüsselbereich in Splits partitioniert. Beispiel: Wenn eine Zeile in ExampleTable mit einem Id von 3700 vorhanden ist, wird sie in Spalte 8 gespeichert. Wie oben beschrieben, wird Split 8 selbst auf mehreren Rechnern repliziert.
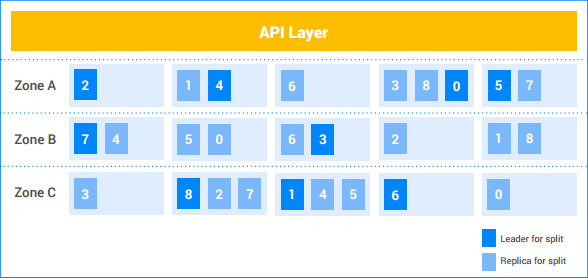
In diesem Beispiel hat der Kunde fünf Knoten und die Instanz wird in drei Zonen repliziert. Die neun Splits sind mit den Zahlen 0 – 8 nummeriert, wobei der Paxos-Leader für jeden Split dunkel gefärbt ist. Die Splits haben außerdem Replikate in jeder Zeile (hell gefärbt). Die Verteilung der Splits zwischen den Knoten weichen möglicherweise von Zone zu Zone ab und die Paxos-Leader befinden sich nicht alle in derselben Zone. Dank dieser Flexibilität kann Spanner robuster mit bestimmten Arten von Ladeprofilen und Fehlermodi umgehen.
Schreibvorgang mit einem einzelnen Split
Angenommen, der Kunde möchte eine neue Zeile (7, "Seven") in ExampleTable einfügen.
- API Layer sucht den Split mit dem Schlüsselbereich, in dem
7enthalten ist. Er befindet sich in Split 1. - API Layer sendet die Schreibanfrage an den Leader von Split 1.
- Der Leader startet eine Transaktion.
- Der Leader versucht, eine Schreibsperre für die Zeile
Id=7abzurufen. Dabei handelt es sich um einen lokalen Vorgang. Wenn eine andere gleichzeitige Lese-Schreib-Transaktion gerade diese Zeile liest, dann erhält die andere Transaktion eine Lesesperre und die aktuelle Transaktion blockiert, bis sie die Schreibsperre abrufen kann.- Es ist möglich, dass die Transaktion A auf die Sperre wartet, die Transaktion B gerade verwendet, und Transaktion B auf die Sperre wartet, die Transaktion A gerade verwendet. Da keine der beiden Transaktionen eine Sperre freigibt, bevor sie alle Sperren erhalten hat, kann es hierbei zum Deadlock kommen. Spanner verwendet den Standard-Deadlock-Präventionsalgorithmus "wound-wait", um sicherzustellen, dass die Transaktionen weiterarbeiten können. Insbesondere wartet eine "jüngere" Transaktion auf eine durch eine "ältere" Transaktion gehaltene Sperre, aber eine "ältere" Transaktion wird eine jüngere Transaktion, die eine durch die ältere Transaktion angeforderte Sperre hält, abbrechen. Deshalb kommt es niemals zu Deadlock-Zyklen durch Sperre-Warteschleifen.
- Nachdem die Sperre abgerufen wurde, weist Leader der Transaktion einen Zeitstempel basierend auf TrueTime zu.
- Dieser Zeitstempel ist garantiert höher als jeder Zeitstempel einer vorher übergebenen Transaktion, die mit den Daten in Berührung gekommen ist. Dadurch stimmt die Reihenfolge der Transaktionen (wie sie vom Client erkannt wird) mit der Reihenfolge der Änderungen an den Daten tatsächlich überein.
- Der Leader teilt den Split 1-Replikaten die Informationen über die Transaktionen und ihrem Zeitstempel mit. Sobald eine Mehrzahl der Replikate die Transaktionsmutation an einem stabilen Speicherplatz (im verteilten Dateisystem) gespeichert hat, wird die Transaktion übergeben. Dies stellt sicher, dass die Transaktion selbst dann wiederherstellbar ist, wenn bei einer Minderheit der Rechner ein Fehler auftritt. (Die Replikate wenden die Mutationen noch nicht auf ihre Kopie der Daten an.)
Der Leader wartet, bis er sicher sein kann, dass der Zeitstempel der Transaktion in Echtzeit bestanden hat. Dies dauert in der Regel einige wenige Millisekunden, um Unsicherheiten beim TrueTime-Zeitstempel abwarten zu können. Dies gewährleistet Strong Consistency – wenn ein Kunde einmal das Ergebnis einer Transaktion erfahren hat, wird garantiert, dass alle anderen Leser die Auswirkungen der Transaktion sehen. Diese "Commit-Wartezeit" überschneidet sich in der Regel mit der Replikat-Kommunikation im obigen Schritt, sodass die tatsächlichen Latenzkosten minimal sind. Weitere Informationen dazu finden Sie in diesem Artikel.
Der Leader antwortet dem Kunden, um ihm mitzuteilen, dass die Transaktion übergeben wurde, und meldet optional den Commit-Zeitstempel der Transaktion.
Parallel zur Antwort an den Kunden werden die Transaktionsmutationen auf die Daten angewendet.
- Der Leader wendet die Mutationen auf seine Kopie der Daten an und gibt dann seine Transaktionssperren frei.
- Außerdem beauftragt der Leader die anderen Split 1-Replikate, die Mutation auf ihre Kopien der Daten anzuwenden.
- Jede Lese-Schreib- oder schreibgeschützte Transaktion, die die Auswirkungen der Mutationen sehen sollte, wartet, bis die Mutationen angewendet werden, bevor sie versucht, die Daten zu lesen. Dies wird für Lese-Schreib-Transaktionen durchgesetzt, weil die Transaktion eine Lesesperre benötigt. Für schreibgeschützte Transaktionen wird dies durchgeführt, indem der Zeitstempel des Lesevorgangs mit dem der zuletzt angewendeten Daten verglichen wird.
All das geschieht normalerweise in wenigen Millisekunden. Hierbei handelt es sich um die günstigste Art von Schreibvorgängen bei Spanner, da nur ein einzelner Split verwendet wird.
Schreibvorgänge mit mehreren Splits
Wenn mehrere Splits beteiligt sind, ist eine zweite Koordinationsstufe (mithilfe des standardmäßigen Zwei-Phasen-Commit-Algorithmus) erforderlich.
Angenommen, die Tabelle enthält viertausend Zeilen:
| 1 | "eins" |
| 2 | "zwei" |
| ... | ... |
| 4000 | "viertausend" |
Nehmen wir außerdem an, der Kunde möchte den Wert für die Zeile 1000 lesen und einen Wert in die Zeilen 2000, 3000 und 4000 innerhalb einer Transaktion schreiben. Dies wird innerhalb einer Lese-Schreib-Transaktion so ausgeführt:
- Der Kunde startet eine Lese-Schreib-Transaktion t.
- Der Kunde gibt eine Leseanforderung für die Zeile 1.000 an API Layer aus und markiert diese als Teil von t.
- API Layer sucht nach dem Split, dem der Schlüssel
1000gehört. Er befindet sich in Split 4. API Layer sendet eine Leseanforderung an den Leader von Split 4 und markiert diesen als Teil von t.
Der Leader von Split 4 versucht, eine Lesesperre für die Zeile
Id=1000zu erhalten. Dabei handelt es sich um einen lokalen Vorgang. Wenn eine andere gleichzeitige Transaktion über eine Schreibsperre für diese Zeile verfügt, wird die aktuelle Transaktion blockiert, bis sie die Sperre abrufen kann. Diese Lesesperre verhindert jedoch nicht, dass andere Transaktionen Lesesperren erhalten.- Wie bei einer einzelnen Aufteilung wird die Blockierung durch „wound-wait“ verhindert.
Der Leader sucht den Wert für
Id1000("Tausend") und gibt das Leseergebnis an den Client zurück.
Später...Der Client gibt eine Commit-Anfrage für die Transaktion t aus. Diese Commit-Anfrage enthält drei Mutationen:
[2000, "Dos Mil"],[3000, "Tres Mil"]und[4000, "Quatro Mil"].- Alle an einer Transaktion beteiligten Splits werden zu Teilnehmern an der Transaktion. In diesem Fall sind Split 4 (der den Lesevorgang für den Schlüssel
1000bereitgestellt hat), Split 7 (der die Mutation für Schlüssel2000verarbeitet) und Split 8 (der die Mutationen für Schlüssel3000und Schlüssel4000verarbeitet) Teilnehmer.
- Alle an einer Transaktion beteiligten Splits werden zu Teilnehmern an der Transaktion. In diesem Fall sind Split 4 (der den Lesevorgang für den Schlüssel
Ein Teilnehmer wird zum Koordinator. In diesem Fall wird möglicherweise der Leader für Split 7 zum Koordinator. Die Aufgabe des Koordinators besteht darin, sicherzustellen, dass die Transaktion entweder für alle Teilnehmer übergeben oder individuell abgebrochen wird. Das heißt, sie kann nicht bei einem Teilnehmer übergeben und bei einem anderen abgebrochen werden.
- Die von den Teilnehmern und Koordinatoren geleistete Arbeit wird tatsächlich von den Leader-Rechnern dieser Splits erledigt.
Die Teilnehmer rufen Sperren ab. (Dies ist die erste Phase des Zwei-Phasen-Commits.)
- Split 7 erhält eine Schreibsperre für den Schlüssel
2000. - Split 8 ruft eine Schreibsperre für Schlüssel
3000und Schlüssel4000ab. - Split 4 überprüft, ob es noch eine Lesesperre für den Schlüssel
1000besitzt (mit anderen Worten, ob die Sperre nicht aufgrund eines Rechnerabsturzes oder des Wound-Wait-Algorithmus verloren gegangen ist). - Jeder Teilnehmer-Split zeichnet seinen Satz von Sperren auf, indem er sie (zumindest) auf die Mehrheit der Split-Replikate repliziert. Auf diese Weise bleiben die Sperren auch bei mehreren Serverabstürzen erhalten.
- Wenn alle Teilnehmer den Koordinator erfolgreich darüber informiert haben, dass ihre Sperren gehalten werden, kann die Gesamttransaktion durchgeführt werden. Dies stellt sicher, dass es einen Zeitpunkt gibt, an dem alle von der Transaktion benötigten Sperren gehalten werden. Dieser Zeitpunkt wird zum Commit-Zeitpunkt der Transaktion, wodurch sichergestellt wird, dass die Auswirkungen dieser Transaktion in die Reihenfolge der Transaktionen davor oder danach eingeordnet werden können.
- Es ist möglich, dass die Sperre nicht abgerufen werden kann (z. B. wenn wir über den Wound-Wait-Algorithmus erfahren, dass es möglicherweise einen Deadlock gibt). Wenn ein Teilnehmer angibt, dass er den Commit der Transaktion nicht durchführen kann, wird die gesamte Transaktion abgebrochen.
- Split 7 erhält eine Schreibsperre für den Schlüssel
Wenn alle Teilnehmer und der Koordinator die Sperren erfolgreich abrufen, übergibt der Koordinator (Split 7) die Transaktion. Er ordnet der Transaktion basierend auf TrueTime einen Zeitstempel zu.
- Diese Commit-Entscheidung sowie die Mutationen für Schlüssel
2000werden in den Mitgliedern von Split 7 repliziert. Sobald eine Mehrheit der Split 7-Replikate die Commit-Entscheidung an einem stabilen Speicherplatz aufgezeichnet hat, wird die Transaktion übergeben.
- Diese Commit-Entscheidung sowie die Mutationen für Schlüssel
Der Koordinator kommuniziert das Transaktionsergebnis mit allen Teilnehmern. (Dies ist die zweite Phase des Zwei-Phasen-Commits.)
- Jeder Teilnehmer-Leader repliziert die Commit-Entscheidung auf die Replikaten des Teilnehmer-Splits.
Wenn die Transaktion abgeschlossen ist, wenden der Koordinator und alle Teilnehmer die Mutationen auf die Daten an.
- Wie im Falle einer einzelnen Aufteilung müssen nachfolgende Leser von Daten beim Koordinator oder den Teilnehmern warten, bis die Daten angewendet werden.
Der Koordinations-Leader teilt dem Kunden mit, dass die Transaktion übergeben wurde, und gibt optional den Zeitstempel der Transaktion zurück.
- Wie bei einer einzelnen Aufteilung wird das Ergebnis dem Kunden nach einer Commit-Warteschleife mitgeteilt, um Strong Consistency zu gewährleisten.
All das geschieht in einigen Millisekunden, allerdings dauert es in der Regel aufgrund der zusätzlichen splitübergreifenden Koordination etwas länger als bei einem einzelnen Split.
Starke Lesevorgänge (mit mehreren Splits)
Angenommen, der Client möchte im Rahmen einer schreibgeschützten Transaktion alle Zeilen lesen, in denen Id >= 0 und Id < 700 enthalten sind.
- API Layer sucht die Splits, die einen beliebigen Schlüssel im Bereich
[0, 700)enthalten. Diese Zeilen gehören zu Split 0, Split 1 und Split 2. - Da dies ein starker Lesevorgang über mehrere Rechner hinweg ist, wählt API Layer den Lesezeitstempel mithilfe des aktuellen TrueTime aus. Dadurch wird sichergestellt, dass beide Lesevorgänge Daten aus demselben Snapshot der Datenbank zurückgeben.
- Andere Arten von Lesevorgängen wie veraltete Lesevorgänge wählen auch einen Zeitstempel aus, an dem der Lesevorgang ausgeführt werden soll (aber der Zeitstempel kann auch in der Vergangenheit liegen).
- API Layer sendet die Leseanfrage an einige Replikate von Split 0, einige Replikate von Split 1 und einige Replikate von Split 2. Es enthält auch den Lesezeitstempel, den es im vorherigen Schritt ausgewählt hat.
Bei starken Lesevorgängen führt das ausführende Replikat in der Regel einen RPC an den Leader aus, um nach dem Zeitstempel der letzten Transaktion zu fragen, die es anwenden muss. Sobald diese Transaktion angewendet wurde, kann der Lesevorgang fortgesetzt werden. Wenn das Replikat der führende Knoten ist oder feststellt, dass es anhand seines internen Zustands und von TrueTime ausreichend auf dem neuesten Stand ist, um die Anfrage zu bearbeiten, wird die Leseanfrage direkt ausgeführt.
Die Ergebnisse der Replikate werden kombiniert und an den Kunden zurückgegeben (über API Layer).
Beachten Sie, dass Lesevorgänge keine Sperren in schreibgeschützten Transaktionen erhalten. Da Lesevorgänge potentiell von jedem aktuellen Replikat eines gegebenen Splits bedient werden können, kann der Lesedurchsatz des Systems sehr hoch sein. Wenn der Kunde in der Lage ist, Lesevorgänge zu tolerieren, die mindestens 10 Sekunden alt sind, kann der Lesedurchsatz sogar noch höher sein. Da der Leader die Replikate in der Regel mit dem aktuellen sicheren Zeitstempel aktualisiert, kann bei Lesevorgängen mit einem veralteten Zeitstempel ein zusätzlicher RPC an den Leader vermieden werden.
Fazit
In der Regel stellen Designer verteilter Datenbanken fest, dass starke Transaktionsgarantien aufgrund der benötigten rechnerübergreifenden Kommunikation teuer sind. Spanner zielt darauf ab, die Transaktionskosten zu reduzieren, um sie auch in großem Umfang und trotz Verteilung bezahlbar zu machen. Eine wichtige Rolle spielt dabei TrueTime, das die rechnerübergreifende Kommunikation für viele Koordinationstypen reduziert. Darüber hinaus hat sorgfältige Entwicklung und Leistungsoptimierung zu einem System geführt, das leistungsfähig ist, auch wenn es starke Garantien bietet. Bei Google haben wir festgestellt, dass dies die Entwicklung von Anwendungen auf Spanner im Vergleich zu anderen Datenbanksystemen mit schwächeren Garantien erheblich erleichtert. Wenn sich Anwendungsentwickler nicht um Race-Bedingungen oder Inkonsistenzen in ihren Daten kümmern müssen, können sie sich auf das konzentrieren, was ihnen wirklich am Herzen liegt: das Erstellen und Verbreiten einer tollen Anwendung.