このページでは、NoSQL データベースを Cassandra から Spanner に移行する方法について説明します。
Cassandra と Spanner はどちらも、高いスケーラビリティと低レイテンシを必要とするアプリケーション向けに構築された大規模な分散データベースです。どちらのデータベースも要求の厳しい NoSQL ワークロードをサポートできますが、Spanner にはデータモデリング、クエリ、トランザクション オペレーション用の高度な機能が用意されています。Spanner は Cassandra クエリ言語(CQL)をサポートしています。
Spanner が NoSQL データベースの基準を満たす仕組みの詳細については、非リレーショナル ワークロード用の Spanner をご覧ください。
移行の制約
Cassandra から Spanner の Cassandra エンドポイントに正常に移行するには、Cassandra ユーザー向けの Spanner で、Spanner のアーキテクチャ、データモデル、データ型が Cassandra とどのように異なるかを確認する必要があります。移行を開始する前に、Spanner と Cassandra の機能の違いを慎重に検討してください。
移行プロセス
移行プロセスは次のステップから構成されます。
- スキーマとデータモデルを変換する。
- 受信データの二重書き込みを設定する。
- Cassandra から Spanner に過去のデータを一括でエクスポートする。
- データを検証して、移行プロセス全体でデータの完全性を確保する。
- アプリケーションが Cassandra ではなく Spanner を使用するように設定する。
- 省略可。Spanner から Cassandra へのリバース レプリケーションを実行する。
スキーマとデータモデルを変換する
Cassandra から Spanner にデータを移行する最初のステップは、データ型とモデリングの違いを処理しながら、Cassandra データスキーマを Spanner のスキーマに適応させることです。
テーブル宣言の構文は、Cassandra と Spanner でかなり似ています。テーブル名、列名と型、行を一意に識別する主キーを指定します。主な違いは、Cassandra はハッシュ パーティショニングで、主キーの 2 つの部分(ハッシュ化されたパーティション キーと並べ替えられたクラスタリング列)を区別するのに対し、Spanner は範囲パーティショニングです。Spanner の主キーは、クラスタリング列のみがあり、パーティションはバックグラウンドで自動的に維持されると考えることができます。Cassandra と同様に、Spanner は複合主キーをサポートしています。
Cassandra データスキーマを Spanner に変換するには、次の手順をおすすめします。
- Cassandra の概要を確認して、Cassandra と Spanner のデータスキーマの類似点と相違点を確認し、さまざまなデータ型をマッピングする方法を確認します。
- Cassandra から Spanner へのスキーマ変換ツールを使用して、Cassandra データスキーマを抽出し、Spanner に変換します。
- データ移行を開始する前に、適切なデータスキーマを使用して Spanner テーブルが作成されていることを確認します。
受信データのライブ マイグレーションを設定する
Cassandra から Spanner にゼロ ダウンタイムで移行するには、受信データのライブ マイグレーションを設定します。ライブ マイグレーションでは、リアルタイム レプリケーションを使用してダウンタイムを最小限に抑え、アプリケーションの継続的な可用性を確保することに重点を置いています。
一括移行の前に、ライブ マイグレーション プロセスを開始します。次の図は、ライブ マイグレーションのアーキテクチャ ビューを示しています。
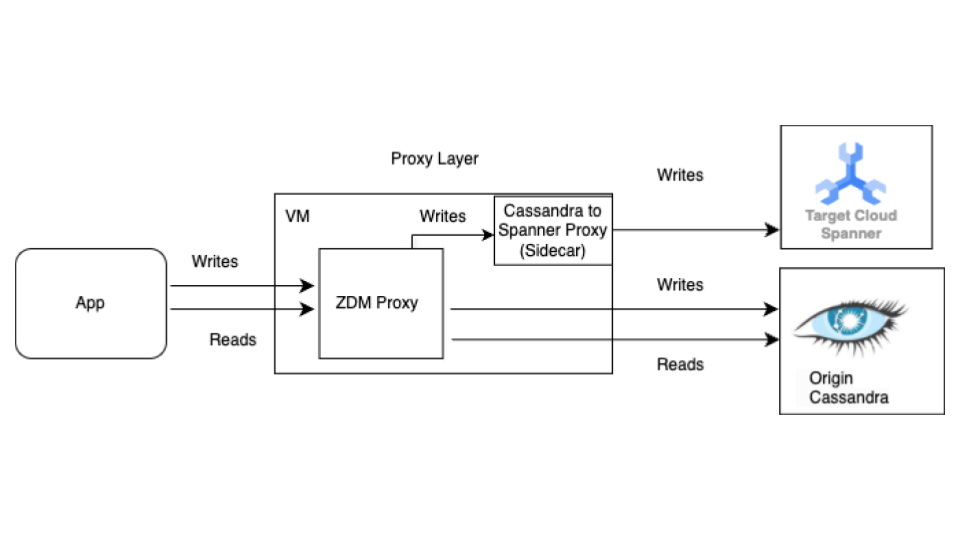
ライブ マイグレーション アーキテクチャには、次の主なコンポーネントがあります。
- 移行元: ソース Cassandra データベース。
- 移行先: 移行先の Spanner データベース。ここでは、Cassandra スキーマと互換性のあるスキーマを使用して、 Spanner インスタンスとデータベースをプロビジョニング済みであると想定しています(Spanner のデータモデルと機能に必要な適応を行っていることも前提としています)。
Datastax ZDM プロキシ: ZDM プロキシは、Cassandra から Cassandra への移行用に DataStax によって構築された二重書き込みプロキシです。このプロキシは Cassandra クラスタを模倣し、アプリケーションを変更せずにプロキシを使用できるようにします。このツールは、アプリケーションと通信し、移行元データベースと移行先データベースへの二重書き込みを実行するために内部で使用されます。通常、移行元と移行先の両方の Cassandra クラスタで使用されますが、この設定では、Cassandra-Spanner プロキシ(サイドカーとして実行)をターゲットとして使用するように構成されています。これにより、受信した読み取りはすべて移行元に転送され、移行元のレスポンスがアプリケーションに返されます。また、受信した各書き込みは移行元と宛先の両方に転送されます。
- 移行元と宛先の両方への書き込みが成功すると、アプリケーションは成功メッセージを受け取ります。
- 移行元への書き込みが失敗し、移行先への書き込みが成功した場合、アプリケーションは移行元の失敗メッセージを受信します。
- 移行先への書き込みが失敗し、移行元への書き込みが成功した場合、アプリケーションは移行先の失敗メッセージを受信します。
- 移行元と移行先の両方への書き込みが失敗した場合、アプリケーションは移行元の障害メッセージを受け取ります。
Cassandra-Spanner プロキシ: Cassandra 宛ての Cassandra クエリ言語(CQL)トラフィックをインターセプトし、Spanner API 呼び出しに変換するサイドカー アプリケーション。これにより、アプリケーションとツールは Cassandra クライアントを使用して Spanner とやり取りできます。
クライアント アプリケーション: ソース Cassandra クラスタに対してデータの読み取りと書き込みを行うアプリケーション。
プロキシの設定
ライブ マイグレーションを行う最初のステップは、プロキシをデプロイして構成することです。Cassandra-Spanner プロキシは、ZDM プロキシのサイドカーとして実行されます。サイドカー プロキシは、Spanner への ZDM プロキシ書き込みオペレーションのターゲットとして機能します。
Docker を使用した単一インスタンスのテスト
初期テストでは、Docker を使用してプロキシの単一インスタンスをローカルまたは VM で実行できます。
前提条件
- プロキシが実行されている VM に、アプリケーション、移行元の Cassandra データベース、Spanner データベースへのネットワーク接続があることを確認します。
- Docker をインストールします。
- Spanner インスタンスとデータベースへの書き込みに必要な権限を持つサービス アカウント キー ファイルがあることを確認します。
- Spanner のインスタンスとデータベース、スキーマを設定します。
- Spanner データベース名が、移行元の Cassandra キースペース名と同じであることを確認します。
- spanner-migration-tool リポジトリのクローンを作成します。
ZDM Proxy をダウンロードして構成する
sources/cassandraディレクトリに移動します。entrypoint.shファイルとDockerfileファイルが Dockerfile と同じディレクトリにあることを確認します。次のコマンドを実行してローカル イメージをビルドします。
docker build -t zdm-proxy:latest .
ZDM Proxy を実行する
- 次のコマンドを実行する場所のローカルに
zdm-config.yamlとkeyfilesが存在することを確認します。 - サンプルの zdm-config yaml ファイルを開きます。
- ZDM が受け入れるフラグのリストを確認します。
次のコマンドを使用してコンテナを実行します。
sudo docker run --restart always -d -p 14002:14002 \ -v zdm-config-file-path:/zdm-config.yaml \ -v local_keyfile:/var/run/secret/keys.json \ -e SPANNER_PROJECT=SPANNER_PROJECT_ID \ -e SPANNER_INSTANCE=SPANNER_INSTANCE_ID \ -e SPANNER_DATABASE=SPANNER_DATABASE_ID \ -e GOOGLE_APPLICATION_CREDENTIALS="/var/run/secret/keys.json" \ -e ZDM_CONFIG=/zdm-config.yaml \ zdm-proxy:latest
プロキシの設定を確認する
docker logsコマンドを使用して、起動中にエラーがないかプロキシのログを確認します。docker logs container-idcqlshコマンドを実行して、プロキシが正しく設定されていることを確認します。cqlsh VM-IP 14002VM-IP は、VM の IP アドレスに置き換えます。
Terraform を使用した本番環境の設定:
本番環境では、提供されている Terraform テンプレートを使用して、Cassandra-Spanner プロキシのデプロイをオーケストレートすることをおすすめします。
前提条件
- Terraform をインストールします。
- リソースの作成に適切な権限を持つデフォルト認証情報がアプリケーションに存在することを確認します。
- サービス キー ファイルに、Spanner への書き込みに関連する権限があることを確認します。このファイルはプロキシで使用されます。
- Spanner のインスタンスとデータベース、スキーマを設定します。
- Dockerfile、
entrypoint.sh、サービス キー ファイルがmain.tfファイルと同じディレクトリにあることを確認します。
Terraform 変数を構成する
- プロキシのデプロイ用の Terraform テンプレートがあることを確認します。
- 設定の変数で
terraform.tfvarsファイルを更新します。
Terraform を使用したテンプレートのデプロイ
Terraform スクリプトは次のことを行います。
- 指定された数に基づいてコンテナ用に最適化された VM を作成します。
- VM ごとに
zdm-config.yamlファイルを作成し、トポロジ インデックスを割り当てます。ZDM プロキシでは、構成ファイルyamlのPROXY_TOPOLOGY_ADDRESSESフィールドとPROXY_TOPOLOGY_INDEXフィールドを使用してトポロジを構成するために、マルチ VM 設定が必要です。 - 関連ファイルを各 VM に転送し、Docker Build をリモートで実行してコンテナを起動します。
テンプレートをデプロイする手順は次のとおりです。
terraform initコマンドを使用して Terraform を初期化します。terraform initterraform planコマンドを実行して、Terraform がインフラストラクチャに加える予定の変更を確認します。terraform plan -var-file="terraform.tfvars"リソースが正常に見える場合は、
terraform applyコマンドを実行します。terraform apply -var-file="terraform.tfvars"Terraform スクリプトが停止したら、
cqlshコマンドを実行して、VM にアクセスできることを確認します。cqlsh VM-IP 14002VM-IP は、VM の IP アドレスに置き換えます。
ZDM プロキシを参照するようにクライアント アプリケーションを設定する
クライアント アプリケーションの構成を変更し、コンタクト ポイントを移行元の Cassandra クラスタではなく、プロキシを実行する VM として設定します。
アプリケーションを徹底的にテストします。書き込みオペレーションが移行元の Cassandra クラスタの両方に適用されていることを確認します。Spanner データベースを確認して、Cassandra-Spanner プロキシを使用して Spanner に接続していることを確認します。読み取りは移行元の Cassandra から提供されます。
データを Spanner に一括でエクスポートする
一括データ移行では、データベース間で大量のデータを転送します。多くの場合、ダウンタイムを最小限に抑え、データの整合性を確保するために、慎重な計画と実行が必要になります。手法としては、ETL(抽出、変換、読み込み)プロセス、データベースの直接レプリケーション、専用の移行ツールなどがあります。これらはすべて、構造と精度を維持しながらデータを効率的に移動することを目的としています。
Cassandra から Spanner にデータを一括で移行するには、Spanner の SourceDB to Spanner Dataflow テンプレートを使用することをおすすめします。Dataflow は、 Google Cloud 分散抽出、変換、読み込み(ETL)サービスです。データ パイプラインを実行するためのプラットフォームを提供し、複数のマシンで大量のデータを並列に読み取って処理します。SourceDB to Spanner Dataflow テンプレートは、Cassandra からの高度な並列読み取りを実行し、必要に応じてソースデータを変換して、ターゲット データベースとして Spanner に書き込むように設計されています。
Cassandra 構成ファイルを使用して、Cassandra から Spanner への一括移行の手順を実施します。
データの整合性を確認する
データベース移行中のデータ検証は、データの精度と完全性を確保するために重要です。移行元の Cassandra データベースと移行先の Spanner データベースのデータを比較して、データの欠落、破損、不一致などの不一致を特定します。一般的なデータ検証手法には、チェックサム、行数、詳細なデータ比較などがあります。これらはすべて、移行されたデータが元のデータを正確に表すことを保証することを目的としています。
一括データ移行が完了し、二重書き込みがまだアクティブな場合は、データの整合性を検証し、不一致を修正する必要があります。次のようなさまざまな理由により、二重書き込みフェーズ中に Cassandra と Spanner の間で差異が生じる可能性があります。
- 二重書き込みの失敗。書き込みオペレーションは、一時的なネットワークの問題やその他のエラーが原因で、あるデータベースでは成功しても、別のデータベースでは失敗することがあります。
- 軽量トランザクション(LWT)。アプリケーションで LWT(比較と設定)オペレーションを使用している場合、データセットの違いにより、一方のデータベースでは成功しても、もう一方のデータベースでは失敗することがあります。
- 単一の主キーに対する秒間クエリ数(QPS)が多い。同じパーティション キーへの書き込み負荷が非常に高い場合、ネットワークのラウンドトリップ時間が異なるため、移行元と移行先でイベントの順序が異なり、不整合が発生する可能性があります。
一括ジョブと二重書き込みの並列実行: 二重書き込みと並行して実行される一括移行では、次のようなさまざまな競合状態により、差異が生じる可能性があります。
- Spanner の余分な行: 二重書き込みがアクティブなときに一括移行が実行されると、一括移行ジョブによってすでに読み取られて移行先に書き込まれた行がアプリケーションによって削除されることがあります。
- 一括書き込みと二重書き込み間の競合状態: 一括ジョブが Cassandra から行を読み取り、二重書き込みの完了後に受信した書き込みが Spanner の行を更新すると、行のデータが古くなるなどの競合状態が発生することがあります。
- 列の部分更新: 既存の行の列のサブセットを更新すると、他の列が null の Spanner のエントリが作成されます。一括更新では既存の行が上書きされないため、Cassandra と Spanner の間で行が分散します。
このステップでは、移行元と移行先のデータベース間でデータを検証して調整します。検証では、移行元と移行先を比較して不整合を特定しますが、調整では、これらの不整合を解決してデータの整合性を達成することに重点を置きます。
Cassandra と Spanner のデータを比較する
行数と行の実際の内容の両方を検証することをおすすめします。
データの比較方法(カウントと行の両方の照合)は、アプリケーションのデータ不整合に対する許容度と、完全な検証の要件によって異なります。
データを検証する方法は 2 つあります。
アクティブ検証は、二重書き込みがアクティブなときに実行されます。このシナリオでは、データベース内のデータは引き続き更新されます。Cassandra と Spanner の行数や行の内容が完全に一致しない場合があります。差異がデータベース上のアクティブな負荷のみによるものであり、他のエラーによるものではないことを確認することが目標です。差異がこれらの制限内にある場合は、カットオーバーを続行できます。
静的検証を行うには、ダウンタイムが必要です。要件で、正確なデータ整合性を保証する強力な静的検証が求められる場合は、両方のデータベースへの書き込みを一時的に停止する必要があります。その後、Spanner データベースでデータを検証し、差異を調整します。
データの整合性と許容可能なダウンタイムに関する特定の要件に基づいて、検証のタイミングと適切なツールを選択します。
Cassandra と Spanner の行数を比較する
データ検証の方法の一つは、移行元と移行先のデータベースでテーブルの行数を比較することです。カウント検証を行う方法はいくつかあります。
小規模なデータセット(テーブルあたり 1,000 万行未満)で移行する場合は、この一致する行をカウントするスクリプトを使用して、Cassandra と Spanner の行数をカウントできます。この方法では、短時間で正確なカウントが返されます。Cassandra のデフォルトのタイムアウトは 10 秒です。カウントが完了する前にスクリプトがタイムアウトする場合は、ドライバ リクエストのタイムアウトとサーバーサイドのタイムアウトを増やすことを検討してください。
大規模なデータセット(テーブルあたり 1,000 万行を超える)を移行する場合、Spanner のカウントクエリは問題なくスケーリングされますが、Cassandra クエリはタイムアウトする傾向があることに注意してください。このような場合は、DataStax Bulk Loader ツールを使用して Cassandra テーブルから行数を取得することをおすすめします。Spanner のカウントでは、ほとんどの大規模な負荷に対して SQL
count(*)関数を使用するだけで十分です。すべての Cassandra テーブルに対して一括読み込みツールを実行し、Spanner テーブルからカウントを取得して、2 つを比較することをおすすめします。これは、手動またはスクリプトを使用して行うことができます。
行の不一致を検証する
移行元と移行先のデータベースの行を比較して、行の不一致を特定することをおすすめします。行の検証を行う方法は 2 つあります。どちらを使用するかは、アプリケーションの要件によって異なります。
- ランダムに選択した行のセットを検証する。
- データセット全体を検証する。
行のランダム サンプルを検証する
大規模なワークロードでは、データセット全体を検証すると費用と時間がかかります。この場合は、サンプリングを使用してデータのランダムなサブセットを検証し、行の不一致を確認できます。これを行う一つの方法は、Cassandra でランダムな行を選択し、Spanner で対応する行を取得してから、値(または行ハッシュ)を比較することです。
この方法の利点は、データセット全体をチェックするよりも早く完了し、実行が簡単なことです。デメリットは、データのサブセットであるため、エッジケースのデータに差異が生じる可能性があることです。
Cassandra からランダムな行をサンプリングするには、次の操作を行う必要があります。
- トークンの範囲 [
-2^63,2^63 - 1] の乱数を生成します。 - 行
WHERE token(PARTITION_KEY) > GENERATED_NUMBERを取得します。
validation.go サンプル スクリプトは、行をランダムに取得し、Spanner データベース内の行と照合します。
データセット全体を検証する
データセット全体を検証するには、元の Cassandra データベース内のすべての行を取得します。主キーを使用して、対応する Spanner データベースの行をすべて取得します。その後、行を比較して違いを確認します。大規模なデータセットの場合は、Apache Spark や Apache Beam などの MapReduce ベースのフレームワークを使用して、データセット全体を信頼性と効率性の高い方法で検証できます。
これの利点は、完全な検証によりデータの整合性が高まる点です。デメリットは、Cassandra の読み取り負荷が増加することと、大規模なデータセット用の複雑なツールを構築するために投資が必要になることです。また、大規模なデータセットの検証が完了するまでに非常に時間がかかることもあります。
また、トークン範囲をパーティショニングし、Cassandra リングを並列でクエリする方法があります。Cassandra の行ごとに、パーティション キーを使用して同等の Spanner 行が取得されます。この 2 つの行が比較され、不一致が検出されます。バリデータ ジョブの構築時に考慮すべき点については、行を照合して Cassandra を検証するヒントをご覧ください。
データまたは行数の不整合を調整する
データ整合性の要件に応じて、Cassandra から Spanner に行をコピーし、検証フェーズで特定された不一致を調整できます。調整を行う一つの方法は、完全なデータセット検証に使用されるツールを拡張し、不一致が見つかった場合に正しい行を Cassandra から移行先の Spanner データベースにコピーすることです。詳細については、実装に関する考慮事項をご覧ください。
Cassandra ではなく Spanner を参照するようにアプリケーションを設定する
移行後のデータの精度と完全性を検証したら、Cassandra ではなく Spanner(またはデータのライブ マイグレーションに使用されるプロキシ アダプタ)を参照するようにアプリケーションを移行するタイミングを選択します。これをカットオーバーと呼びます。
カットオーバーを行う手順は次のとおりです。
次のいずれかの方法で、クライアント アプリケーションが Spanner インスタンスに直接接続できるように構成を変更します。
- Cassandra をサイドカーとして実行されている Cassandra アダプタに接続します。
- ドライバ JAR をエンドポイント クライアントに変更します。
前の手順で準備した変更を適用して、Spanner を参照するようにアプリケーションを設定します。
エラーやパフォーマンスの問題をモニタリングするように、アプリケーションのモニタリングを設定します。Cloud Monitoring を使用して Spanner の指標をモニタリングします。詳細については、Cloud Monitoring でインスタンスをモニタリングするをご覧ください。
カットオーバーが正常に完了し、動作の安定が確認できたら、ZDM プロキシと Cassandra-Spanner プロキシ インスタンスを廃止します。
Spanner から Cassandra へのリバース レプリケーションを実行する
リバース レプリケーションは、Spanner to
SourceDB Dataflow テンプレートを使用して実行できます。リバース レプリケーションは、Spanner で予期しない問題が発生し、サービスを中断することなく元の Cassandra データベースにフェイルバックする必要がある場合に便利です。
行を照合して Cassandra を検証する際のヒント
SELECT * を使用して Cassandra(または他の任意のデータベース)でテーブル全体のスキャンを実行するのは、時間がかかり非効率的です。この問題を解決するには、Cassandra データセットを管理可能なパーティションに分割し、パーティションを同時に処理します。そのためには、次の操作を行います。
- データセットをトークン範囲に分割する
- パーティションを並列でクエリする
- 各パーティション内のデータを読み取る
- Spanner から対応する行を取得する
- 拡張性のための検証ツールを設計する
- 不一致を報告してログに記録する
データセットをトークン範囲に分割する
Cassandra は、パーティション キー トークンに基づいてデータをノード間で分散します。Cassandra クラスタのトークン範囲は -2^63~2^63 -
1 です。同じサイズのトークン範囲を一定数定義して、キースペース全体を小さなパーティションに分割できます。トークン範囲を構成可能な partition_size パラメータで分割し、範囲全体をすばやく処理するように調整することをおすすめします。
パーティションを並列でクエリする
トークン範囲を定義したら、複数の並列プロセスまたはスレッドを起動できます。各プロセスまたはスレッドは、特定の範囲内のデータを検証します。範囲ごとに、パーティション キー(pk)で token() 関数を使用して CQL クエリを作成できます。
特定のトークン範囲のクエリの例を次に示します。
SELECT *
FROM your_keyspace.your_table
WHERE token(pk) >= partition_min_token AND token(pk) <= partition_max_token;
定義されたトークン範囲を反復処理し、これらのクエリを移行元の Cassandra クラスタに対して(または Cassandra から読み取るように構成された ZDM プロキシを介して)並行して実行することで、分散方式でデータを効率的に読み取ることができます。
各パーティション内のデータを読み取る
各並列プロセスは範囲ベースのクエリを実行し、Cassandra からデータのサブセットを取得します。パーティションから取得されたデータの量を確認して、並列処理とメモリ使用量のバランスを確保します。
Spanner から対応する行を取得する
Cassandra から取得された行ごとに、ソース行キーを使用して、移行先の Spanner データベースから対応する行を取得します。
行を比較して不一致を特定する
Cassandra 行と対応する Spanner 行(存在する場合)の両方を取得したら、それらのフィールドを比較して不一致を特定する必要があります。この比較では、潜在的なデータ型の違いと、移行中に適用された変換を考慮する必要があります。アプリケーションの要件に基づいて、不一致を構成する明確な基準を定義することをおすすめします。
拡張性のための検証ツールを設計する
検証ツールは、調整のために拡張できるように設計します。たとえば、検出された不一致に対して、Cassandra から Spanner に正しいデータを書き込む機能を追加できます。
不一致を報告してログに記録する
検出された不一致は、調査と調整ができるように十分なコンテキストと一緒にログに記録することをおすすめします。これには、主キー、異なる特定のフィールド、Cassandra と Spanner の両方の値が含まれます。検出された不一致の数と種類に関する統計情報を集計することもできます。
Cassandra データで TTL を有効または無効にする
このセクションでは、Spanner テーブルの Cassandra データで有効期間(TTL)を有効または無効にする方法について説明します。概要については、有効期間(TTL)をご覧ください。
Cassandra データで TTL を有効にする
このセクションの例では、次のスキーマを持つテーブルがあるとします。
CREATE TABLE Singers (
SingerId INT64 OPTIONS (cassandra_type = 'bigint'),
AlbumId INT64 OPTIONS (cassandra_type = 'int'),
) PRIMARY KEY (SingerId);
既存のテーブルで行レベルの TTL を有効にするには、次の操作を行います。
各行の有効期限のタイムスタンプを保存するタイムスタンプ列を追加します。この例では、列の名前は
ExpiredAtですが、任意の名前を使用できます。ALTER TABLE Singers ADD COLUMN ExpiredAt TIMESTAMP;行削除ポリシーを追加して、有効期限が切れた行を自動的に削除します。
INTERVAL 0 DAYは、有効期限に達すると行が直ちに削除されることを意味します。ALTER TABLE Singers ADD ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY));cassandra_ttl_modeをrowに設定すると、行レベルの TTL が有効になります。ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'row');必要に応じて、
cassandra_default_ttlを設定してデフォルトの TTL 値を構成します。値は秒単位です。ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 10000);
Cassandra データで TTL を無効にする
このセクションの例では、次のスキーマを持つテーブルがあるとします。
CREATE TABLE Singers (
SingerId INT64 OPTIONS ( cassandra_type = 'bigint' ),
AlbumId INT64 OPTIONS ( cassandra_type = 'int' ),
ExpiredAt TIMESTAMP,
) PRIMARY KEY (SingerId),
ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY)), OPTIONS (cassandra_ttl_mode = 'row');
既存のテーブルで行レベルの TTL を無効にするには、次の操作を行います。
必要に応じて、
cassandra_default_ttlを 0 に設定して、デフォルトの TTL 値をクリーンアップします。ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 0);行レベルの TTL を無効にするには、
cassandra_ttl_modeをnoneに設定します。ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'none');行削除ポリシーを削除します。
ALTER TABLE Singers DROP ROW DELETION POLICY;有効期限のタイムスタンプ列を削除します。
ALTER TABLE Singers DROP COLUMN ExpiredAt;
実装に関する注意事項
- フレームワークとライブラリ: スケーラブルなカスタム検証を行うには、Apache Spark や Dataflow(Beam)などの MapReduce ベースのフレームワークを使用します。サポートされている言語(Python、Scala、Java)を選択し、Cassandra と Spanner のコネクタ(プロキシの使用など)を使用します。これらのフレームワークにより、大規模なデータセットを効率的に並列処理して包括的な検証を行うことができます。
- エラー処理と再試行: 堅牢なエラー処理を実装して、ネットワーク接続の問題や、いずれかのデータベースの一時的な使用不可などの潜在的な問題を管理します。一時的な障害に対して再試行メカニズムを実装することを検討してください。
- 構成: トークン範囲、両方のデータベースの接続の詳細、比較ロジックを構成可能にします。
- パフォーマンスの調整: 並列プロセスの数とトークン範囲のサイズをテストして、特定の環境とデータ量に合わせて検証プロセスを最適化します。検証中に Cassandra クラスタと Spanner クラスタの両方の負荷をモニタリングします。
次のステップ
- Cassandra の概要で、Spanner と Cassandra の比較を確認する。
- Cassandra アダプタを使用して Spanner に接続する方法を確認する。