このページでは、CPU 使用率の指標およびグラフとその他のイントロスペクション ツールを使用して、データベース内の高 CPU 使用率を調査する方法について説明します。
システムタスクとユーザータスクのどちらが高 CPU 使用率の原因になっているかを特定する
Google Cloud コンソールには、Spanner 用のいくつかのモニタリング ツールが用意されており、インスタンスで最も重要な指標のステータスを確認できます。これらのうちの一つは CPU 使用率 - 合計と呼ばれるグラフです。このグラフは、タスクの優先度とオペレーション タイプごとに分類した、インスタンスの CPU リソースの割合(%)で表した合計 CPU 使用率を示しています。タスクには、読み取りや書き込みなどのユーザータスクと、コンパクションやインデックス バックフィルなどの自動バックグラウンド タスクをカバーするシステムタスクの 2 種類があります。
図 1 に、CPU 使用率 - 合計グラフの例を示します。
![[CPU 使用率 - 合計] グラフの例](https://cloud.google.com/static/spanner/docs/images/cpu-utilization-total-chart.png?hl=ja)
図 1. Google Cloud コンソールの Monitoring ダッシュボードの [CPU 使用率 - 合計] グラフ。
次に、CPU 使用率が大幅に増加したことを示すアラートを Cloud Monitoring から受信したとします。 Google Cloud コンソールでインスタンスの [Monitoring] ダッシュボードを開き、Cloud コンソールで [CPU 使用率 - 合計] グラフを調べます。図 1 に示すように、優先度の高いユーザータスクによる CPU 使用率の増加を確認できます。次のステップでは、この CPU 使用率の増加の原因となっている優先度の高いユーザー オペレーションを特定します。
Query Insights ダッシュボードを使用して、この指標と他の指標を時系列で可視化できます。事前に構築されたダッシュボードは、CPU 使用率の急上昇を確認し、非効率的なクエリを特定する際に活用できます。
CPU 使用率の急上昇の原因となっているユーザー オペレーションを特定する
図 1 の [CPU 使用率 - 合計] グラフは、優先度の高いユーザータスクが CPU 使用率が高くなっていることを示しています。
次に、Cloud コンソールの [オペレーション タイプ別の CPU 使用率] グラフを確認します。このグラフは、ユーザーが開始した優先度が高、中、低のオペレーションごとに CPU 使用率の内訳を示しています。
ユーザー開始型のオペレーションとは
ユーザー開始オペレーションは、API リクエストによって開始されるオペレーションです。Spanner では、これらのリクエストがオペレーション タイプまたはカテゴリにグループ化されます。各オペレーション タイプは、[オペレーション タイプ別の CPU 使用率] グラフに線で表示されます。次の表に、各オペレーション タイプに含まれる API メソッドを示します。
| オペレーション | API メソッド | 説明 |
|---|---|---|
| read_readonly | Read StreamingRead |
キールックアップとスキャンを使用してデータベースから行を取得する読み取りなどがあります。 |
| read_readwrite | Read StreamingRead |
読み取り / 書き込みトランザクション内の読み取りなどがあります。 |
| read_withpartitiontoken | Read StreamingRead |
パーティション トークンを使用した読み取りオペレーションなどがあります。 |
| executesql_select_readonly | ExecuteSql ExecuteStreamingSql |
Select SQL ステートメントの実行とストリーム クエリの変更が含まれます。 |
| executesql_select_readwrite | ExecuteSql ExecuteStreamingSql |
読み取り / 書き込みトランザクション内での select ステートメントの実行などがあります。 |
| executesql_select_withpartitiontoken | ExecuteSql ExecuteStreamingSql |
パーティション トークンを使用した select ステートメントの実行などがあります。 |
| executesql_dml_readwrite | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
DML SQL ステートメントの実行などがあります。 |
| executesql_dml_partitioned | ExecuteSql ExecuteStreamingSql ExecuteBatchDml |
パーティション化 DML SQL ステートメントの実行などがあります。 |
| beginorcommit | BeginTransaction Commit Rollback |
トランザクションの開始、commit、ロールバックなどがあります。 |
| misc | PartitionQuery PartitionRead GetSession CreateSession |
PartitionQuery、PartitionRead、データベースの作成、インスタンスの作成、セッション関連のオペレーション、内部の緊急性の高い処理オペレーションなどがあります。 |
以下は、オペレーション タイプ別 CPU 使用率の指標のグラフの例です。
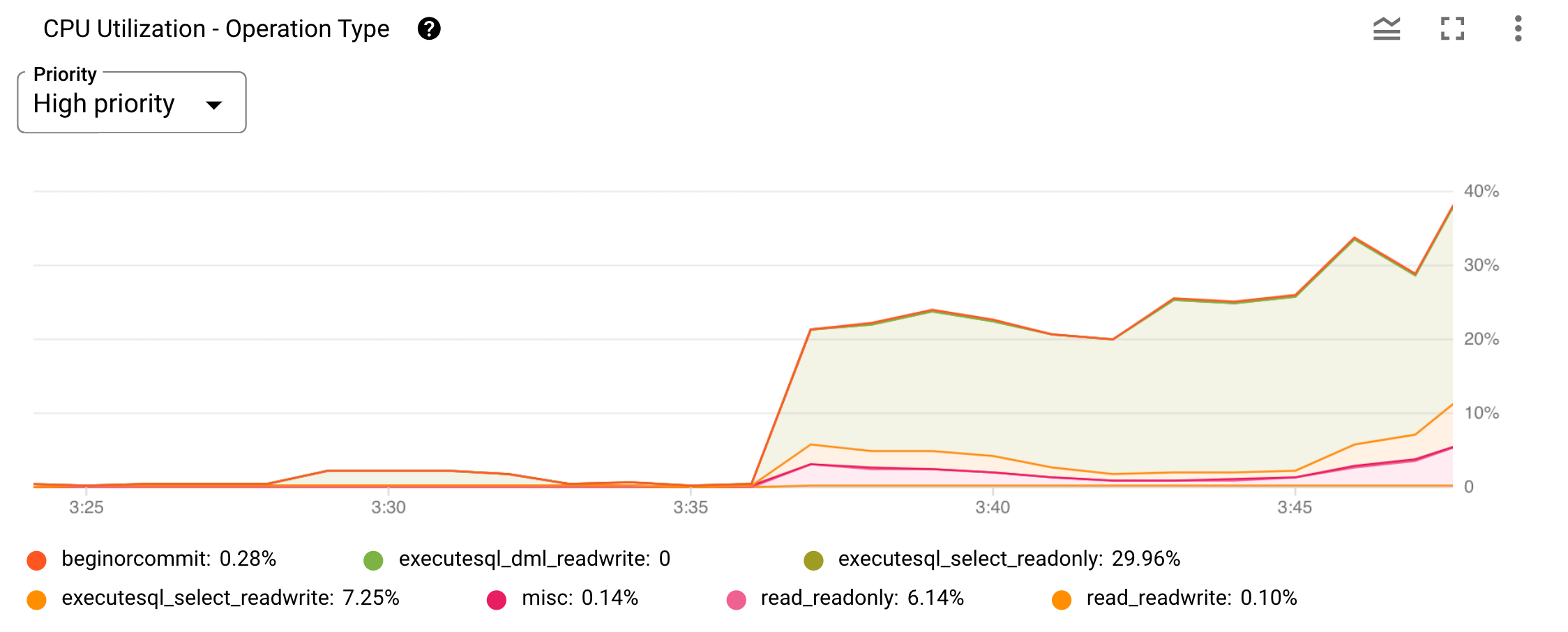
図 2. Google Cloud コンソールの [オペレーション タイプ別の CPU 使用率] グラフ。
グラフの上部にある [優先度] メニューを使用して、表示を特定の優先度に制限できます。各オペレーション タイプまたはカテゴリが折れ線グラフにプロットされます。グラフの下に表示されるカテゴリは、各グラフを表します。各グラフの表示と非表示を切り替えるには、各カテゴリ フィルタを選択または選択解除します。
または、次のように Metrics Explorer でこのグラフを作成することもできます。
Metrics Explorer で [オペレーション タイプ別の CPU 使用率] グラフを作成する
- Google Cloud コンソールで [Monitoring] を選択するか、次のボタンを使用します。
- ナビゲーション パネルで [Metrics Explorer] を選択します。
-
[Find resource type and metric] フィールドに値「
spanner.googleapis.com/instance/cpu/utilization_by_operation_type」を入力し、ボックスの下に表示される行を選択します。 -
[フィルタ] フィールドに値「
instance_id」を入力し、確認するインスタンス ID を入力して、[>Apply] をクリックします。 -
[グループ条件] フィールドでプルダウン リストから [
category] を選択します。グラフには、ユーザータスクの CPU 使用率がオペレーション タイプ別またはカテゴリ別に表示されます。
こうして、前のセクションで取り上げた優先度別の CPU 使用率指標を使って CPU 使用率の増加の原因がユーザータスクとシステムタスクのどちらかを判定する一方で、オペレーション タイプ別の CPU 使用率指標を使って詳細を調査し、CPU 使用率の急増の原因となったユーザー開始型のオペレーションの種類を確認できます。
CPU 使用率の増加の原因となっているユーザー リクエストを特定する
図 2 に示されている executesql_select_readonly オペレーション タイプグラフで CPU 使用率の急増の原因となったユーザー リクエストを判別するには、組み込みのイントロスペクション統計情報テーブルを使って詳しく分析します。
次の表を参考にして、CPU 使用率が高いオペレーション タイプを使ってクエリを実行する統計テーブルを判別してください。
| オペレーションのタイプ | クエリ | 読み取り | トランザクション |
|---|---|---|---|
| read_readonly | いいえ | はい | いいえ |
| read_readwrite | いいえ | はい | はい |
| read_withpartitiontoken | いいえ | はい | いいえ |
| executesql_select_readonly | はい | いいえ | いいえ |
| executesql_select_withpartitiontoken | はい | いいえ | いいえ |
| executesql_select_readwrite | はい | いいえ | はい |
| executesql_dml_readwrite | はい | いいえ | はい |
| executesql_dml_partitioned | いいえ | いいえ | はい |
| beginorcommit | いいえ | いいえ | はい |
たとえば、read_withpartitiontoken が問題である場合は、読み取り統計情報を使用してトラブルシューティングを行います。
このシナリオの場合、CPU 使用率の増加の原因は、executesql_select_readonly オペレーションにあると思われます。上記の表に基づいて、クエリ統計情報を確認し、コストが高いクエリ、頻繁に実行されるクエリ、大量のデータをスキャンするクエリを調べます。
それまでの 1 時間で CPU 使用率が最も高かったクエリを調べるには、query_stats_top_hour 統計テーブルで次のクエリを実行します。
SELECT text,
execution_count AS count,
avg_latency_seconds AS latency,
avg_cpu_seconds AS cpu,
execution_count * avg_cpu_seconds AS total_cpu
FROM spanner_sys.query_stats_top_hour
WHERE interval_end =
(SELECT MAX(interval_end)
FROM spanner_sys.query_stats_top_hour)
ORDER BY total_cpu DESC;
出力には、CPU 使用率で並べ替えられたクエリが表示されます。CPU 使用率が最も高いクエリを特定したら、チューニングするための次のオプションを試すことができます。
クエリ実行プランを確認し、高 CPU 使用率の原因となっている可能性のある非効率なクエリを特定します。
クエリを確認して、SQL のベスト プラクティスに従っていることを確認します。
データベースのスキーマ設計を見直し、クエリが効率的に処理されるようにスキーマを更新します。
Spanner が一定間隔でクエリを実行する回数のベースラインを設定します。ベースラインを使用すると、通常の動作からの予期しない逸脱の原因を検出して調査できます。
CPU 使用率の高いクエリが見つからなかった場合は、インスタンスにコンピューティング容量を追加します。コンピューティング容量を追加すると、CPU リソースが増加し、Spanner でより多くのワークロードを処理できるようになります。詳細については、コンピューティング容量の増加をご覧ください。
次のステップ
CPU 使用率の指標について学習する。
別のイントロスペクション ツールについて学習する。
Cloud Monitoring によるモニタリングについて学習する。
Spanner に関する SQL のベスト プラクティスについて学習する。
Cloud Spanner からの指標のリストを確認する。