Questo tutorial spiega come ridurre i costi eseguendo il deployment di uno strumento di scalabilità automatica pianificato su Google Kubernetes Engine (GKE). Questo tipo di gestore della scalabilità automatica aumenta o diminuisce le dimensioni dei cluster in base a una pianificazione basata sull'ora del giorno o sul giorno della settimana. Un gestore della scalabilità automatica pianificata è utile se il traffico ha un flusso prevedibile, ad esempio se sei un rivenditore regionale o se il tuo software è destinato a dipendenti il cui orario di lavoro è limitato a una parte specifica della giornata.
Il tutorial è rivolto a sviluppatori e operatori che vogliono scalare in modo affidabile i cluster prima che si verifichino picchi e ridimensionarli di nuovo per risparmiare denaro di notte, nei fine settimana o in qualsiasi altro momento in cui sono online meno utenti. L'articolo presuppone che tu conosca Docker, Kubernetes, Kubernetes CronJobs, GKE e Linux.
Introduzione
Molte applicazioni presentano pattern di traffico irregolari. Ad esempio, i lavoratori di un'organizzazione potrebbero interagire con un'applicazione solo durante il giorno. Di conseguenza, i server del data center per quell'applicazione sono inattivi di notte.
Oltre ad altri vantaggi, Google Cloud può aiutarti a risparmiare denaro allocando dinamicamente l'infrastruttura in base al carico di traffico. In alcuni casi, una semplice configurazione di scalabilità automatica può gestire la sfida dell'allocazione del traffico irregolare. Se è il tuo caso, continua così. Tuttavia, in altri casi, i cambiamenti drastici nei pattern di traffico richiedono configurazioni di scalabilità automatica più ottimizzate per evitare l'instabilità del sistema durante gli scale up ed evitare il provisioning eccessivo del cluster.
Questo tutorial si concentra sugli scenari in cui i cambiamenti bruschi nei pattern di traffico sono ben compresi e vuoi dare suggerimenti al gestore della scalabilità automatica in modo che sappia che la tua infrastruttura sta per subire picchi. Questo documento mostra come scalare i cluster GKE al mattino e ridurli di notte, ma puoi utilizzare un approccio simile per aumentare e diminuire la capacità per qualsiasi evento noto, come eventi di scalabilità di picco, campagne pubblicitarie o traffico del fine settimana.
Riduzione delle dimensioni di un cluster se hai sconti per impegno di utilizzo
Questo tutorial spiega come ridurre i costi ridimensionando i cluster GKE al minimo durante le ore non di punta. Tuttavia, se hai acquistato uno sconto per utilizzo garantito, è importante capire come questi sconti funzionano in combinazione con lo scaling automatico.
I contratti basati sull'impegno di utilizzo ti offrono prezzi molto scontati quando ti impegni a pagare una quantità prestabilita di risorse (vCPU, memoria e altre). Tuttavia, per determinare la quantità di risorse da impegnare, devi sapere in anticipo quante risorse utilizzano i tuoi workload nel tempo. Per aiutarti a ridurre i costi, il seguente diagramma illustra le risorse che devi e non devi includere nella pianificazione.

Come mostra il diagramma, l'allocazione delle risorse nell'ambito di un contratto di utilizzo impegnato è piatta. Le risorse coperte dal contratto devono essere utilizzate la maggior parte del tempo per valere l'impegno che hai preso. Pertanto, non devi includere le risorse utilizzate durante i picchi nel calcolo delle risorse di cui è stato eseguito il commit. Per le risorse con picchi, ti consigliamo di utilizzare le opzioni di scalabilità automatica di GKE. Queste opzioni includono lo scalatore automatico pianificato descritto in questo articolo o altre opzioni gestite descritte in Best practice per l'esecuzione di applicazioni Kubernetes con ottimizzazione dei costi su GKE.
Se hai già un contratto di utilizzo impegnato per una determinata quantità di risorse, non riduci i costi ridimensionando il cluster al di sotto di questo minimo. In questi scenari, ti consigliamo di provare a pianificare alcuni job per colmare le lacune durante i periodi di bassa domanda di risorse di calcolo.
Architettura
Il seguente diagramma mostra l'architettura dell'infrastruttura e del gestore della scalabilità automatica pianificata di cui esegui il deployment in questo tutorial. Lo strumento di scalabilità automatica pianificata è costituito da un insieme di componenti che collaborano per gestire lo scaling in base a una pianificazione.

In questa architettura, un insieme di CronJobs di Kubernetes esporta informazioni note sui pattern di traffico in una metrica personalizzata di Cloud Monitoring. Questi dati vengono poi letti da un gestore della scalabilità automatica pod orizzontale (HPA) di Kubernetes come input per determinare quando l'HPA deve scalare il workload. Insieme ad altre metriche di carico, come l'utilizzo della CPU target, HPA decide come scalare le repliche per un determinato deployment.
Obiettivi
- Creare un cluster GKE.
- Esegui il deployment di un'applicazione di esempio che utilizza un HPA di Kubernetes.
- Configura i componenti per il gestore della scalabilità automatica pianificata e aggiorna HPA in modo che legga da una metrica personalizzata pianificata.
- Configura un avviso da attivare quando lo scalatore automatico pianificato non funziona correttamente.
- Genera carico per l'applicazione.
- Esamina il modo in cui HPA risponde ai normali aumenti di traffico e alle metriche personalizzate pianificate che configuri.
Il codice per questo tutorial si trova in un repository GitHub.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the GKE, Artifact Registry and the Cloud Monitoring APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the GKE, Artifact Registry and the Cloud Monitoring APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
prepara l'ambiente
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
In Cloud Shell, configura l'ID progetto Google Cloud , il tuo indirizzo email e la zona e la regione di calcolo:
PROJECT_ID=YOUR_PROJECT_ID ALERT_EMAIL=YOUR_EMAIL_ADDRESS gcloud config set project $PROJECT_ID gcloud config set compute/region us-central1 gcloud config set compute/zone us-central1-fSostituisci quanto segue:
YOUR_PROJECT_ID: il nome del progetto Google Cloud per il progetto che stai utilizzando.YOUR_EMAIL_ADDRESS: un indirizzo email a cui ricevere una notifica quando lo scalatore automatico pianificato non funziona correttamente.
Se vuoi, puoi scegliere una regione e una zona diverse per questo tutorial.
Clona il repository GitHub
kubernetes-engine-samples:git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples/ cd kubernetes-engine-samples/cost-optimization/gke-scheduled-autoscalerIl codice in questo esempio è strutturato nelle seguenti cartelle:
- Root: contiene il codice utilizzato dai CronJob per esportare le metriche personalizzate in Cloud Monitoring.
k8s/: contiene un esempio di deployment con un HPA Kubernetes.k8s/scheduled-autoscaler/: contiene i CronJob che esportano una metrica personalizzata e una versione aggiornata dell'HPA per leggere da una metrica personalizzata.k8s/load-generator/: contiene un deployment Kubernetes con un'applicazione per simulare l'utilizzo orario. Un deployment è un oggetto API Kubernetes che consente di eseguire più repliche di pod distribuite tra i nodi di un cluster.monitoring/: contiene i componenti di Cloud Monitoring che configuri in questo tutorial.
In Cloud Shell, crea un cluster GKE per eseguire lo scalatore automatico pianificato:
gcloud container clusters create scheduled-autoscaler \ --enable-ip-alias \ --release-channel=stable \ --machine-type=e2-standard-2 \ --enable-autoscaling --min-nodes=1 --max-nodes=10 \ --num-nodes=1 \ --autoscaling-profile=optimize-utilizationL'output è simile al seguente:
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS scheduled-autoscaler us-central1-f 1.22.15-gke.100 34.69.187.253 e2-standard-2 1.22.15-gke.100 1 RUNNINGNon si tratta di una configurazione di produzione, ma di una configurazione adatta a questo tutorial. In questa configurazione, configuri il gestore della scalabilità automatica del cluster con un minimo di 1 nodo e un massimo di 10 nodi. Puoi anche attivare il profilo
optimize-utilizationper velocizzare il processo di riduzione.Esegui il deployment dell'applicazione di esempio senza lo strumento di scalabilità automatica pianificata:
kubectl apply -f ./k8sApri il file
k8s/hpa-example.yaml.Il seguente elenco mostra i contenuti del file.
Tieni presente che il numero minimo di repliche (
minReplicas) è impostato su 10. Questa configurazione imposta anche la scalabilità del cluster in base all'utilizzo della CPU (impostazioniname: cpuetype: Utilization).Attendi che l'applicazione diventi disponibile:
kubectl wait --for=condition=available --timeout=600s deployment/php-apache EXTERNAL_IP='' while [ -z $EXTERNAL_IP ] do EXTERNAL_IP=$(kubectl get svc php-apache -o jsonpath={.status.loadBalancer.ingress[0].ip}) [ -z $EXTERNAL_IP ] && sleep 10 done curl -w '\n' http://$EXTERNAL_IPQuando l'applicazione è disponibile, l'output è il seguente:
OK!Verifica le impostazioni:
kubectl get hpa php-apacheL'output è simile al seguente:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 9%/60% 10 20 10 6d19hLa colonna
REPLICASmostra10, che corrisponde al valore del campominReplicasnel filehpa-example.yaml.Controlla se il numero di nodi è aumentato a 4:
kubectl get nodesL'output è simile al seguente:
NAME STATUS ROLES AGE VERSION gke-scheduled-autoscaler-default-pool-64c02c0b-9kbt Ready <none> 21S v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-ghfr Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-gvl9 Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-t9sr Ready <none> 21s v1.17.9-gke.1504Quando hai creato il cluster, hai impostato una configurazione minima utilizzando il flag
min-nodes=1. Tuttavia, l'applicazione che hai deployment all'inizio di questa procedura richiede più infrastruttura perchéminReplicasnel filehpa-example.yamlè impostato su 10.L'impostazione di
minReplicassu un valore come 10 è una strategia comune utilizzata da aziende come i rivenditori, che prevedono un aumento improvviso del traffico nelle prime ore della giornata lavorativa. Tuttavia, l'impostazione di valori elevati per HPAminReplicaspuò aumentare i costi perché il cluster non può ridursi, nemmeno di notte quando il traffico dell'applicazione è basso.In Cloud Shell, installa l'adattatore delle metriche personalizzate - Cloud Monitoring nel tuo cluster GKE:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml kubectl wait --for=condition=available --timeout=600s deployment/custom-metrics-stackdriver-adapter -n custom-metricsQuesto adattatore consente la scalabilità automatica dei pod in base alle metriche personalizzate di Cloud Monitoring.
Crea un repository in Artifact Registry e concedi le autorizzazioni di lettura:
gcloud artifacts repositories create gke-scheduled-autoscaler \ --repository-format=docker --location=us-central1 gcloud auth configure-docker us-central1-docker.pkg.dev gcloud artifacts repositories add-iam-policy-binding gke-scheduled-autoscaler \ --location=us-central1 --member=allUsers --role=roles/artifactregistry.readerCrea e invia il codice dell'esportatore di metrica personalizzata:
docker build -t us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter . docker push us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporterEsegui il deployment dei CronJob che esportano le metriche personalizzate e della versione aggiornata dell'HPA che legge queste metriche personalizzate:
sed -i.bak s/PROJECT_ID/$PROJECT_ID/g ./k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml kubectl apply -f ./k8s/scheduled-autoscalerApri ed esamina il file
k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml.Il seguente elenco mostra i contenuti del file.
Questa configurazione specifica che i CronJob devono esportare il conteggio delle repliche dei pod suggerito in una metrica personalizzata chiamata
custom.googleapis.com/scheduled_autoscaler_examplein base all'ora del giorno. Per facilitare la sezione di monitoraggio di questo tutorial, la configurazione del campo della pianificazione definisce gli aumenti e le riduzioni orari. Per la produzione, puoi personalizzare questa pianificazione in base alle esigenze della tua attività.Apri ed esamina il file
k8s/scheduled-autoscaler/hpa-example.yaml.Il seguente elenco mostra i contenuti del file.
Questa configurazione specifica che l'oggetto HPA deve sostituire l'HPA che è stato implementato in precedenza. Tieni presente che la configurazione riduce il valore in
minReplicasa 1. Ciò significa che il workload può essere ridotto al minimo. La configurazione aggiunge anche una metrica esterna (type: External). Questa aggiunta significa che la scalabilità automatica ora viene attivata da due fattori.In questo scenario con più metriche, HPA calcola un numero di repliche proposto per ogni metrica e poi sceglie la metrica che restituisce il valore più alto. È importante capire che lo strumento di scalabilità automatica pianificata può proporre che in un determinato momento il conteggio dei pod sia 1. Tuttavia, se l'utilizzo effettivo della CPU è superiore al previsto per un pod, HPA crea più repliche.
Controlla di nuovo il numero di nodi e repliche HPA eseguendo di nuovo ciascuno di questi comandi:
kubectl get nodes kubectl get hpa php-apacheL'output visualizzato dipende dalle azioni eseguite di recente dal gestore della scalabilità automatica pianificata. In particolare, i valori di
minReplicasenodessaranno diversi in momenti diversi del ciclo di scalabilità.Ad esempio, tra i minuti 51 e 60 circa di ogni ora (che rappresentano un periodo di picco del traffico), il valore HPA per
minReplicassarà 10 e il valore dinodessarà 4.Al contrario, per i minuti da 1 a 50 (che rappresentano un periodo di traffico inferiore), il valore di HPA
minReplicassarà 1 e il valore dinodessarà 1 o 2, a seconda del numero di pod allocati e rimossi. Per i valori inferiori (da 1 a 50 minuti), potrebbero essere necessari fino a 10 minuti prima che il cluster completi la riduzione.In Cloud Shell, crea un canale di notifica:
gcloud beta monitoring channels create \ --display-name="Scheduled Autoscaler team (Primary)" \ --description="Primary contact method for the Scheduled Autoscaler team lead" \ --type=email \ --channel-labels=email_address=${ALERT_EMAIL}L'output è simile al seguente:
Created notification channel NOTIFICATION_CHANNEL_ID.Questo comando crea un canale di notifica di tipo
emailper semplificare i passaggi del tutorial. Negli ambienti di produzione, ti consigliamo di utilizzare una strategia meno asincrona impostando il canale di notifica susmsopagerduty.Imposta una variabile con il valore visualizzato nel segnaposto
NOTIFICATION_CHANNEL_ID:NOTIFICATION_CHANNEL_ID=NOTIFICATION_CHANNEL_IDEsegui il deployment del criterio di avviso:
gcloud alpha monitoring policies create \ --policy-from-file=./monitoring/alert-policy.yaml \ --notification-channels=$NOTIFICATION_CHANNEL_IDIl file
alert-policy.yamlcontiene la specifica per inviare un avviso se la metrica è assente dopo cinque minuti.Vai alla pagina Avvisi di Cloud Monitoring per visualizzare il criterio di avviso.
Fai clic su Norme di scalabilità automatica pianificata e verifica i dettagli delle norme di avviso.
In Cloud Shell, esegui il deployment del generatore di carico:
kubectl apply -f ./k8s/load-generatorIl seguente elenco mostra lo script
load-generator:command: ["/bin/sh", "-c"] args: - while true; do RESP=$(wget -q -O- http://php-apache.default.svc.cluster.local); echo "$(date +%H)=$RESP"; sleep $(date +%H | awk '{ print "s("$0"/3*a(1))*0.5+0.5" }' | bc -l); done;Questo script viene eseguito nel cluster finché non elimini il deployment di
load-generator. Effettua richieste al tuo serviziophp-apacheogni pochi millisecondi. Il comandosleepsimula le variazioni della distribuzione del carico durante il giorno. Utilizzando uno script che genera traffico in questo modo, puoi capire cosa succede quando combini l'utilizzo della CPU e le metriche personalizzate nella configurazione HPA.In Cloud Shell, crea una nuova dashboard:
gcloud monitoring dashboards create \ --config-from-file=./monitoring/dashboard.yamlVai alla pagina Dashboard di Cloud Monitoring:
Fai clic su Dashboard del gestore della scalabilità automatica pianificata.
La dashboard mostra tre grafici. Devi attendere almeno 2 ore (idealmente, 24 ore o più) per vedere le dinamiche di scalabilità orizzontale e riduzione della scalabilità orizzontale e per vedere in che modo la diversa distribuzione del carico durante il giorno influisce sulla scalabilità automatica.
Per farti un'idea di cosa mostrano i grafici, puoi studiare i seguenti grafici, che presentano una visualizzazione di un'intera giornata:
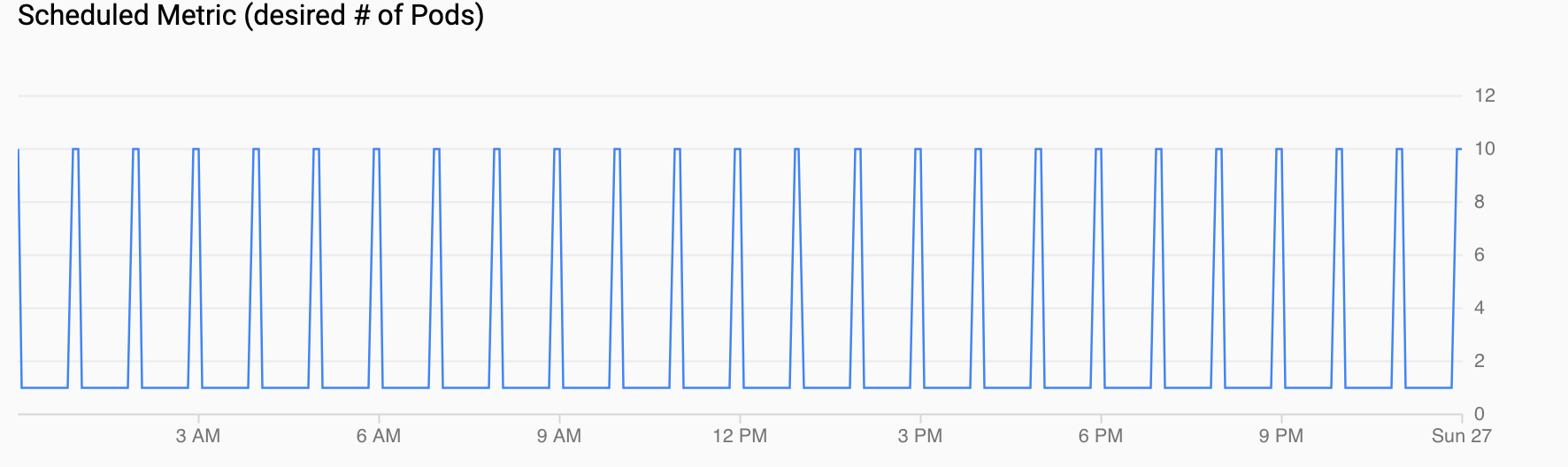
Metrica pianificata (numero desiderato di pod) mostra una serie temporale della metrica personalizzata esportata in Cloud Monitoring tramite i CronJob che hai configurato in Configurazione di uno scalatore automatico pianificato.
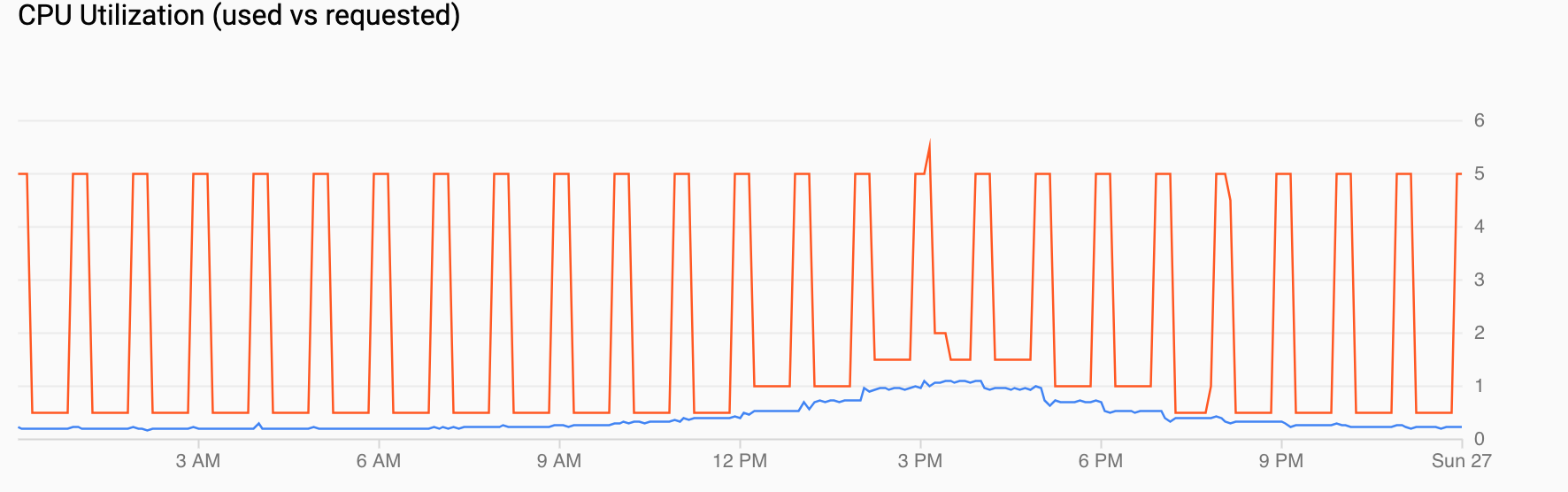
Utilizzo CPU (richiesta rispetto all'utilizzo) mostra una serie temporale di CPU richiesta (rosso) e utilizzo effettivo della CPU (blu). Quando il carico è basso, HPA rispetta la decisione di utilizzo del gestore della scalabilità automatica pianificata. Tuttavia, quando il traffico aumenta, l'HPA aumenta il numero di pod in base alle necessità, come puoi vedere per i punti dati tra le 12:00 e le 18:00.
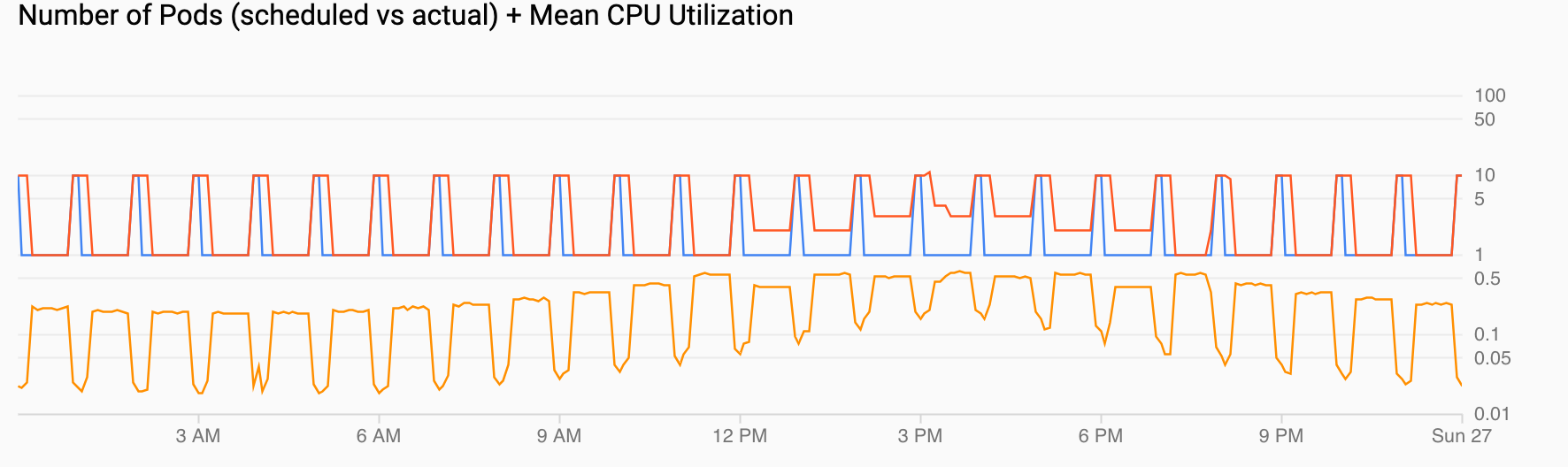
Numero di pod (pianificati vs effettivi) + Utilizzo medio della CPU mostra una visualizzazione simile a quelle precedenti. Il conteggio dei pod (rosso) aumenta a 10 ogni ora come pianificato (blu). Il conteggio dei pod aumenta e diminuisce naturalmente nel tempo in risposta al carico (12:00 e 18:00). L'utilizzo medio della CPU (arancione) rimane al di sotto del target che hai impostato (60%).
Crea il cluster GKE
Esegui il deployment dell'applicazione di esempio
Configurare un gestore della scalabilità automatica pianificata
Configura avvisi per quando il gestore della scalabilità automatica pianificata non funziona correttamente
In un ambiente di produzione, in genere vuoi sapere quando i CronJob non
compilano la metrica personalizzata. A questo scopo, puoi creare un avviso che
si attiva quando qualsiasi stream custom.googleapis.com/scheduled_autoscaler_example è
assente per un periodo di cinque minuti.
Genera carico per l'applicazione di esempio
Visualizzare la scalabilità in risposta al traffico o alle metriche pianificate
In questa sezione, esamini le visualizzazioni che mostrano gli effetti dello scale up e dello scale down.
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Scopri di più sull'ottimizzazione dei costi di GKE in Best practice per l'esecuzione di applicazioni Kubernetes con ottimizzazione dei costi su GKE.
- Trova suggerimenti di progettazione e best practice per ottimizzare i costi dei Google Cloud carichi di lavoro nel Google Cloud Well-Architected Framework: ottimizzazione dei costi.
- Esplora architetture, diagrammi e best practice di riferimento su Google Cloud. Consulta il nostro Cloud Architecture Center.