このチュートリアルでは、Amazon DynamoDB から Spanner に移行する方法を説明します。このチュートリアルは主に、NoSQL システムから Spanner への移行を考えているアプリ所有者を対象としています。Spanner は完全にリレーショナルでフォールト トレラント、かつ拡張性の高い SQL データベース システムであり、トランザクションをサポートしています。Amazon DynamoDB テーブルの使用方法がタイプとレイアウトの面で一貫していれば、Spanner へのマッピングは容易です。Amazon DynamoDB のテーブルに含まれているデータ型や値が限定されていない場合は、Datastore や Firestore など他の NoSQL サービスに移行するほうが簡単かもしれません。
このチュートリアルでは、データベース スキーマ、データ型、NoSQL の基本、リレーショナル データベース システムについての知識があることを前提としています。このチュートリアルでは主に、定義済みのタスクを実行して移行を行ってみます。チュートリアルの終了後は、提示されたコードや手順を環境に合わせて変更できます。
次のアーキテクチャ図は、このチュートリアルでデータの移行に使用するコンポーネントの概要を示しています。

目標
- Amazon DynamoDB から Spanner にデータを移行する。
- Spanner データベースおよび移行テーブルを作成する。
- NoSQL スキーマをリレーショナル スキーマにマッピングする。
- Amazon DynamoDB を使用するサンプル データセットを作成しエクスポートする。
- Amazon S3 と Cloud Storage の間でデータを転送する。
- Dataflow を使用して Spanner にデータをロードする。
費用
このチュートリアルでは、課金対象である次の Google Cloud コンポーネントを使用します。
Spanner の請求料金は、インスタンスのコンピューティング容量と毎月の請求期間に格納されたデータの量に基づいて決定されます。このチュートリアルでは、これらのリソースを最小限の構成で利用し、最後にクリーンアップします。実際のシナリオでは、スループットとストレージの要件を予測し、Spanner インスタンスのドキュメントを使用して、必要なコンピューティング容量を判断します。
このチュートリアルでは、Google Cloud のリソースに加えて、次の Amazon Web Services(AWS)リソースを使用します。
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
これらのサービスは移行プロセスにのみ必要になります。チュートリアルの最後には、指示に従ってすべてのリソースをクリーンアップし、不要な料金が発生しないようにしてください。こうした料金の見積りには、AWS 料金計算ツールを利用します。
予想使用量に基づいて費用の見積りを生成するには、料金計算ツールを使用します。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
環境を準備する
このチュートリアルでは、Cloud Shell でコマンドを実行します。Cloud Shell では Google Cloud のコマンドラインにアクセスできるほか、Google Cloud で開発を行うために必要な Google Cloud CLI などのツールも利用できます。Cloud Shell の初期化には数分かかることがあります。
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- デフォルトの Compute Engine ゾーンを設定します。例:
us-central1-bgcloud config set compute/zone us-central1-b - サンプルコードが格納された GitHub リポジトリのクローンを作成します。 git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git
- クローンされたディレクトリに移動します。 cd dynamodb-spanner-migration
- Python 仮想環境を作成します。 pip3 install virtualenv virtualenv env
- 仮想環境をアクティブにします。 source env/bin/activate
- 必要な Python モジュールをインストールします。 pip3 install -r requirements.txt
AWS アクセスを構成する
このチュートリアルでは、Amazon DynamoDB テーブル、Amazon S3 バケット、その他のリソースを作成して削除します。これらのリソースにアクセスするには、まず必要な AWS Identity and Access Management(IAM)権限を作成する必要があります。テスト アカウントまたはサンドボックス AWS アカウントを使用すれば、同じアカウントで本番環境のリソースに影響を及ぼす心配もありません。
AWS Lambda の AWS IAM 役割を作成する
このセクションでは、チュートリアル後半のステップで AWS Lambda が使用する AWS IAM 役割を作成します。
- AWS console で、[IAM] セクションに移動し、[Roles] をクリックしてから、[Create role] を選択します。
- [Trusted entity type] で、[AWS service] が選択されていることを確認します。
- [ユースケース] で [Lambda] を選択し、[次へ] をクリックします。
- [Permission policies] フィルタ ボックスに「
AWSLambdaDynamoDBExecutionRole」と入力し、Returnキーを押して検索します。 - [AWSLambdaDynamoDBExecutionRole] チェックボックスをオンにして、[次へ] をクリックします。
- [Role name] ボックスに「
dynamodb-spanner-lambda-role」と入力し、[Create role] をクリックします。
AWS IAM ユーザーを作成する
次の手順に従って、AWS リソースにプログラムでアクセスできる AWS IAM ユーザーを作成します。AWS リソースはこのチュートリアルを通して使用します。
- AWS コンソールの [IAM] セクションから、[ユーザー] をクリックし、[ユーザーを追加] を選択します。
- [User name] ボックスに「
dynamodb-spanner-migration」と入力します。 [アクセスタイプ] で、左側のチェックボックス [Access key -Programmatic access] をオンにします。
[Next: Permissions] をクリックします。
[Attach existing policies directly] をクリックし、[検索] ボックスを使用して、次の 3 つのポリシーの横にあるチェックボックスをオンにします。
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
[Next: Tags] と [Next: Review] をクリックしてから、[ユーザーの作成] をクリックします。
[Show] をクリックして、認証情報を表示します。新しく作成されたユーザーのアクセスキー ID とシークレット アクセスキーが表示されます。次のセクションで認証情報が必要になるため、このウィンドウは開いたままにしておきます。これらの認証情報は安全な場所に保管してください。この情報を使用すればアカウントを改ざんし、環境に影響を与えることが可能になるためです。このチュートリアルの最後に、IAM ユーザーを削除できます。
AWS コマンドライン インターフェースを構成する
Cloud Shell で、AWS コマンドライン インターフェース(CLI)を構成します。
aws configure
次の出力が表示されます。
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- 作成した AWS IAM アカウントから、
ACCESS KEY IDとSECRET ACCESS KEYを入力します。 - [Default region name] フィールドに「
us-west-2」と入力します。他のフィールドはデフォルト値のままにしておきます。
- 作成した AWS IAM アカウントから、
AWS IAM コンソール ウィンドウを閉じます。
データモデルを理解する
次のセクションでは、Amazon DynamoDB と Spanner のデータ型、キー、インデックスの類似点および相違点を概説します。
データ型
Spanner は GoogleSQL データ型を使用します。次の表は、Amazon DynamoDB のデータ型がどのように Spanner のデータ型にマッピングされるかを示しています。
| Amazon DynamoDB | Spanner |
|---|---|
| 数値 | 精度または使用目的に応じて、INT64、FLOAT64、TIMESTAMP、または DATE にマッピングされます。 |
| 文字列 | 文字列 |
| ブール値 | BOOL |
| Null | 明示的な型はありません。列には NULL 値を入れることができます。 |
| バイナリ | バイト |
| セット | 配列 |
| マップとリスト | 構造が一貫しており、テーブルの DDL 構文を使用して記述できる場合は構造体。 |
主キー
Amazon DynamoDB の主キーは一意性を確立するもので、ハッシュキーか、ハッシュキーと範囲キーの組み合わせのいずれかになります。このチュートリアルはまず、主キーがハッシュキーである Amazon DynamoDB テーブルの移行を実際にやってみることから始まります。このハッシュキーは Spanner テーブルの主キーになります。後で記載するインターリーブされたテーブルのセクションでは、Amazon DynamoDB テーブルが、ハッシュキーと範囲キーで構成される主キーを使用する状況をモデリングします。
セカンダリ インデックス
Amazon DynamoDB と Spanner はいずれも、非主キー属性でのインデックスの作成をサポートしています。Amazon DynamoDB テーブルのセカンダリ インデックスをメモしておきます。このセクションの後半で Spanner テーブルでインデックスを作成する際に使用します。
サンプル テーブル
このチュートリアルを効率よく進めるために、次のサンプル テーブルを Amazon DynamoDB から Spanner に移行します。
| Amazon DynamoDB | Spanner | |
|---|---|---|
| テーブル名 |
Migration
|
Migration
|
| 主キー |
"Username" : String
|
"Username" : STRING(1024)
|
| キーのタイプ | ハッシュ | なし |
| その他のフィールド |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
Amazon DynamoDB テーブルを準備する
次のセクションでは、Amazon DynamoDB のソーステーブルを作成し、そこにデータを追加します。
Cloud Shell で、サンプル テーブル属性を使用する Amazon DynamoDB テーブルを作成します。
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75テーブルのステータスが
ACTIVEであることを確認します。aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'テーブルにサンプルデータを追加します。
python3 make-fake-data.py --table Migration --items 25000
Spanner データベースの作成
可能な限り最小のコンピューティング容量(100 処理ユニット)で Spanner インスタンスを作成します。このチュートリアルの範囲では、このコンピューティング容量で十分です。本番環境の場合は、Spanner インスタンスのドキュメントを参照して、データベースのパフォーマンス要件を満たす適切なコンピューティング容量を決定してください。
この例では、データベースと同時にテーブル スキーマを作成します。データベースを作成した後は、スキーマの更新を行うことも可能であり一般的です。
デフォルトの Compute Engine ゾーンを設定した同じリージョンに Spanner インスタンスを作成します。例:
us-central1gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"Spanner インスタンスにサンプル テーブルとともにデータベースを作成します。
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"
移行を準備する
次のセクションでは、Amazon DynamoDB ソーステーブルをエクスポートし、Pub/Sub レプリケーションを設定して、エクスポート中に発生したデータベースへの変更を取得する方法について説明します。
変更を Pub/Sub にストリーミングする
データベースの変更を Pub/Sub にストリーミングするには、AWS Lambda 関数を使用します。
Cloud Shell で、ソーステーブルでの Amazon DynamoDB ストリームを有効にします。
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES変更を受け取るための Pub/Sub トピックを設定します。
gcloud pubsub topics create spanner-migration
次の出力が表示されます。
Created topic [projects/your-project/topics/spanner-migration].
テーブルの更新を Pub/Sub トピックに push する IAM サービス アカウントを作成します。
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"次の出力が表示されます。
Created service account [spanner-migration].
IAM ポリシー バインディングを作成して、サービス アカウントに Pub/Sub に公開する権限を持つようにします。
GOOGLE_CLOUD_PROJECTは、Google Cloud プロジェクトの名前で置き換えます。gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com次の出力が表示されます。
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
サービス アカウントの認証情報を作成します。
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.com次の出力が表示されます。
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
AWS Lambda 関数を準備しパッケージ化して、Amazon DynamoDB テーブルの変更を Pub/Sub トピックに push します。
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd - zip -g pubsub-lambda.zip ddbpubsub.py
前に作成した Lambda 実行の役割の Amazon Resource Name(ARN)を取得する変数を作成します。
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)pubsub-lambda.zipパッケージを使用して、AWS Lambda 関数を作成します。aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"次の出力が表示されます。
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128, ... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }Create a variable to capture the ARN of the Amazon DynamoDB stream for your table.
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)Lambda 関数を Amazon DynamoDB テーブルに関連付けます。
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZONテスト中の応答性を最適化するには、前のコマンドの末尾に
--batch-size 1を追加します。こうするとアイテムを作成、更新、または削除するたびに関数がトリガーされます。出力は次のようになります。
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...
Amazon DynamoDB テーブルを Amazon S3 にエクスポートする
Cloud Shell で、以降の複数のセクションで使用するバケット名の変数を作成します。
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-exportDynamoDB エクスポートを受け取る Amazon S3 バケットを作成します。
aws s3 mb s3://${BUCKET}AWS Management Console で、[DynamoDB] に移動し、[テーブル] をクリックします。
[
Migration] テーブルをクリックします。[Exports and stream] タブで [Export to S3] をクリックします。
プロンプトが表示されたら、
point-in-time-recovery(PITR)を有効にします。[Browse S3] をクリックして、以前に作成した S3 バケットを選択します。
[エクスポート] をクリックします。
更新アイコンをクリックして、エクスポート ジョブのステータスを更新します。ジョブのエクスポートが完了するまで数分かかります。
プロセスが終了したら、出力バケットを確認します。
aws s3 ls --recursive s3://${BUCKET}この手順には約 5 分かかります。完了すると、次のような出力が表示されます。
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
移行を実行する
Pub/Sub 配信が開始されたため、エクスポート後に発生したテーブルの変更をすべて push できます。
エクスポートしたテーブルを Cloud Storage にコピーする
Cloud Shell で、Amazon S3 からエクスポートされたファイルを受信する Cloud Storage バケットを作成します。
gcloud storage buckets create gs://${BUCKET}Amazon S3 から受信したファイルを Cloud Storage に同期します。ほとんどのコピー オペレーションには、
rsyncコマンドが有効です。エクスポート ファイルが大きい(数 GB 以上の)場合は、Cloud Storage Transfer Service を使用して、バックグラウンド転送を管理します。gcloud storage rsync s3://${BUCKET} gs://${BUCKET} --recursive --delete-unmatched-destination-objects
データを一括インポートする
エクスポートされたファイルのデータを Spanner テーブルに書き込むには、サンプルの Apache Beam コードを使用して Dataflow ジョブを実行します。
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"Google Cloud コンソールで、インポート ジョブの進行状況を確認するには、Dataflow に移動します。
ジョブの実行中、実行グラフを表示してログを検討できます。[Status] が [Running] と表示されているジョブをクリックします。
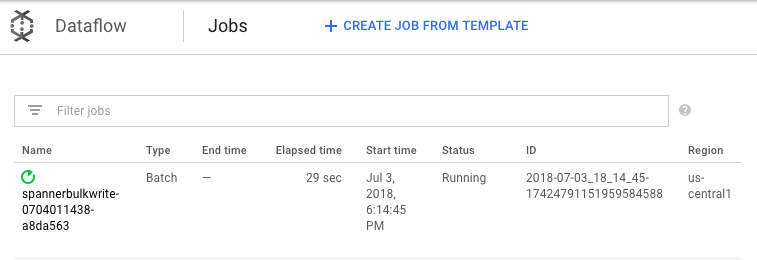
各ステージをクリックすると、処理済みの要素の数が表示されます。すべてのステージが [Succeeded] になると、インポートは完了です。Amazon DynamoDB テーブルで作成された要素と同じ数の要素が、各ステージで処理済みと表示されます。
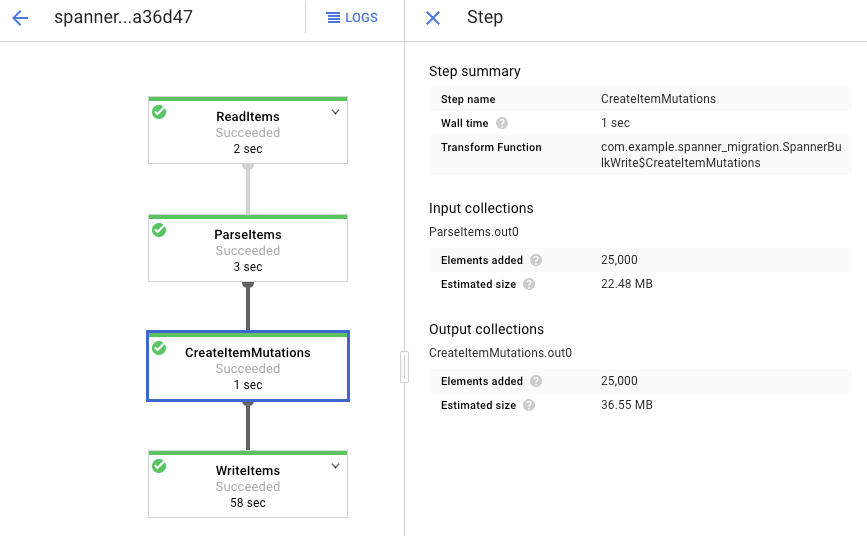
宛先 Spanner テーブルのレコード数が Amazon DynamoDB テーブルの項目数と一致していることを確認します。
aws dynamodb describe-table --table-name Migration --query Table.ItemCount gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"
次の出力が表示されます。
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
各テーブルのランダムなエントリをサンプリングして、データが一貫していることを確認します。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"次の出力が表示されます。
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
前の手順の Spanner クエリで返されたものと同じ
Usernameを使用して、Amazon DynamoDB テーブルに対するクエリを実行します。例:aallen2538値は、データベース内のサンプルデータに固有のものです。aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'他のフィールドの値は、Spanner 出力の値と一致する必要があります。次の出力が表示されます。
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }
新しい変更をレプリケートする
一括インポート ジョブが完了したら、ストリーミング ジョブを設定して、進行中の更新をソーステーブルから Spanner に書き込みます。Pub/Sub のイベントに登録し、それを Spanner に書き込みます。
作成した Lambda 関数は、ソース Amazon DynamoDB テーブルへの変更を取得し、それを Pub/Sub に公開するよう構成されています。
AWS Lambda がイベントを送信する宛先となる Pub/Sub トピックのサブスクリプションを作成します。
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migration次の出力が表示されます。
Created subscription [projects/your-project/subscriptions/spanner-migration].
Pub/Sub に入ってくる変更をストリーミングして Spanner テーブルに書き込むには、Cloud Shell から Dataflow ジョブを実行します。
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"ジョブの進行状況を確認するには、一括読み込みの手順と同様、Google Cloud コンソールで Dataflow に移動します。
[Status] が [Running] のジョブをクリックします。
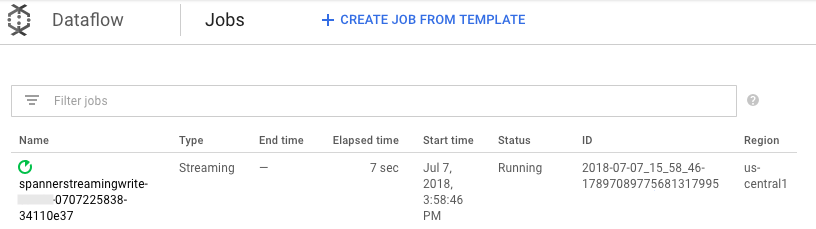
処理グラフには前と同様の出力が表示されますが、処理済みの各項目がステータス ウィンドウでカウントされます。システムの遅延時間は、Spanner テーブルに変更が反映されるまでに生じると思われる遅延の大まかな予想です。
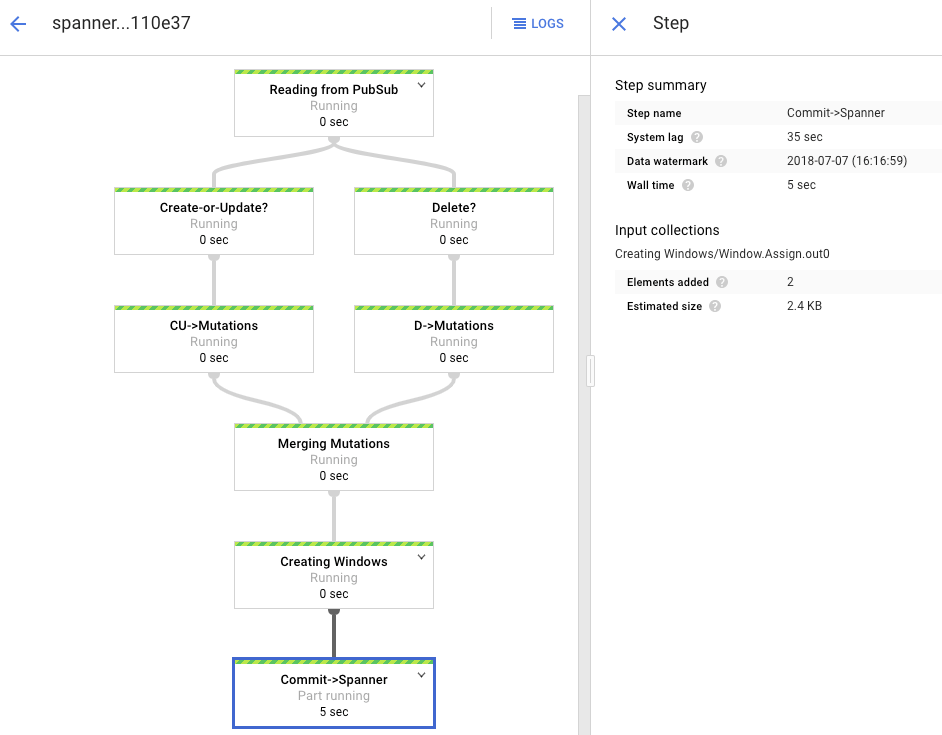
一括読み込みフェーズで実行した Dataflow ジョブは、制限付きデータセットとも呼ばれる一連の有限の入力でした。この Dataflow ジョブは、Pub/Sub をストリーミング ソースとして使用しており、制限なしとみなされます。この 2 種類のソースの詳細については、Apache Beam プログラミング ガイドの PCollection の項を参照してください。このステップの Dataflow ジョブはアクティブのままにされるため、終了しても停止しません。ストリーミング Dataflow ジョブのステータスは、[Succeeded] ではなく [Running] のままになります。
レプリケーションを検証する
ソーステーブルになんらかの変更を加えて、その変更が Spanner テーブルにレプリケートされることを確認します。
Spanner で存在しない行を照会します。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"結果は返されません。
Spanner のクエリで使用したのと同じキーを使用して、Amazon DynamoDB にレコードを作成します。コマンドが正常に実行された場合、出力は生成されません。
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'同じクエリを再度実行して、その行が今は Spanner にあることを確認します。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"出力には挿入された行が表示されます。
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
元の項目の一部の属性を変更し、Amazon DynamoDB テーブルを更新します。
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEW出力は次のようになります。
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }変更が Spanner テーブルに伝播されていることを確認します。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"出力は次のように表示されます。
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
Amazon DynamoDB のソーステーブルからテスト項目を削除します。
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'対応する行が Spanner テーブルから削除されていることを確認します。変更が伝播されると、次のコマンドはゼロ行を返します。
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"
インターリーブ テーブルを使用する
Spanner は、テーブルのインターリーブのコンセプトをサポートしています。これはトップレベルの項目に、そのトップレベル項目に関連する複数のネストされた項目があるという設計モデルです(お客様とその注文、プレーヤーとそのゲームスコアなど)。Amazon DynamoDB ソーステーブルで、ハッシュキーと範囲キーで構成される主キーを使用する場合は、次の図のように、インターリーブ テーブルのスキーマをモデリングできます。この構造では親テーブルのフィールドを結合しながら、インターリーブ テーブルを効率的に照会できます。

セカンダリ インデックスを適用する
データを読み込んだ後にセカンダリ インデックスを Spanner テーブルに適用することは、ベスト プラクティスのひとつです。レプリケーションはすでに機能しているため、セカンダリ インデックスを設定してクエリを高速化します。Spanner のセカンダリ インデックスは、Spanner テーブルと同様、完全整合性を備えています。ただし、多くの NoSQL データベースで一般的な結果整合性とは異なります。この機能はアプリの設計を簡素化するのに役立ちます。
インデックスを使用しないクエリを実行します。ここでは特定の列の値を指定して、上位 N 個のオカレンスを探します。これは Amazon DynamoDB における、データベースの効率性を高めるための一般的なクエリです。
Spanner に移動します。
[Spanner Studio] をクリックします。
![[Query] ボタン](https://cloud.google.com/static/spanner/docs/images/migrating-dynamodb-to-cloud-spanner-7query.png?authuser=00&hl=ja)
[Query] フィールドに次のクエリを入力し、[Run query] をクリックします。
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
クエリが実行されたら、[Explanation] をクリックして、[Rows scanned] と [Rows returned] をメモします。インデックスがない場合、Spanner はテーブル全体をスキャンして、クエリに一致するデータの小さなサブセットを返します。
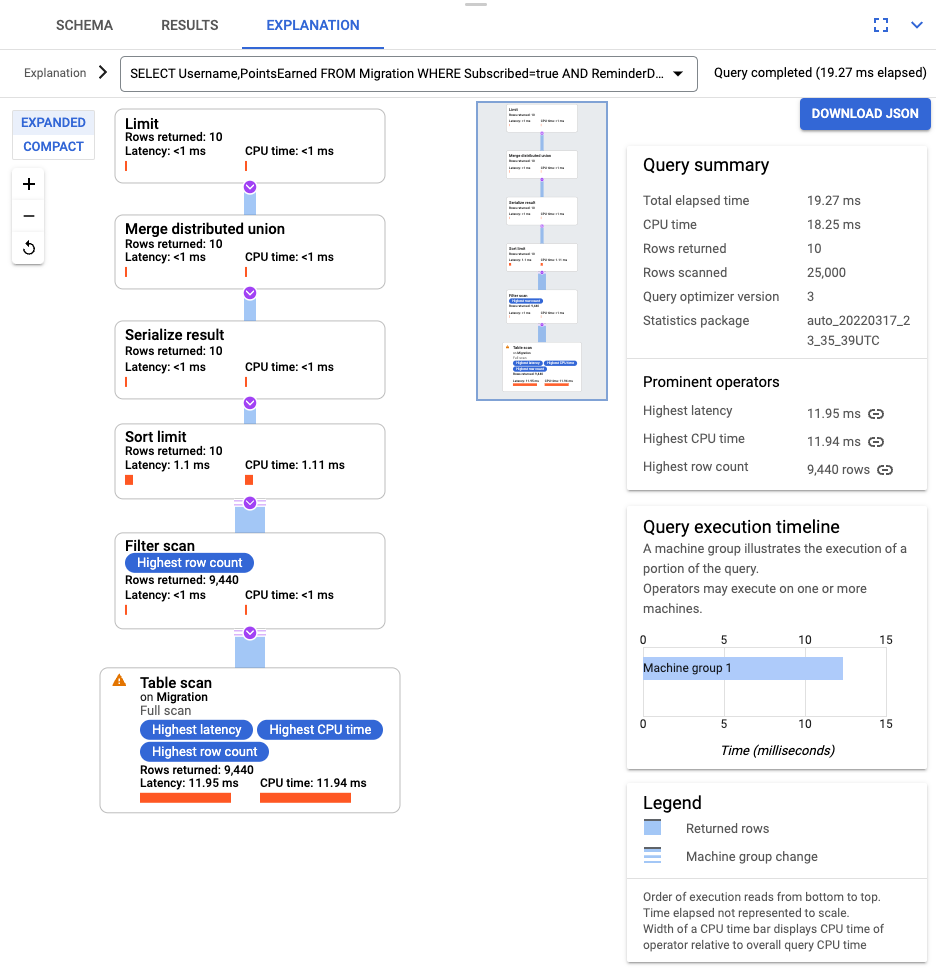
これが一般的に発生するクエリを表している場合は、Subscribed 列と ReminderDate 列に複合インデックスを作成します。Spanner コンソールで、左側のナビゲーション ペインで [インデックス] を選択し、[インデックスの作成] をクリックします。
テキスト ボックスにインデックス定義を入力します。
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
バックグラウンドでのデータベース構築を開始するには、[Create] をクリックします。
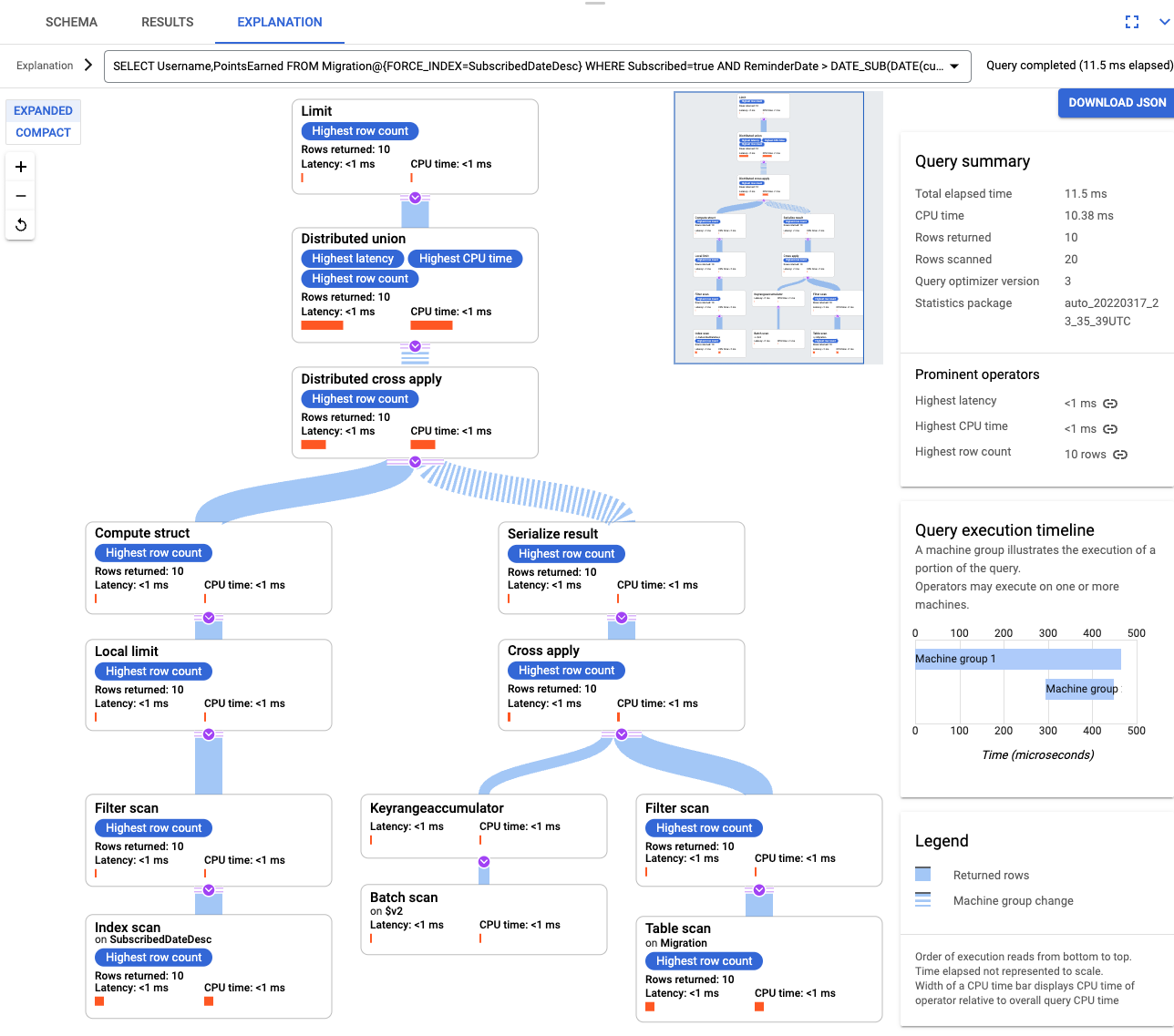
インデックスが作成されたら、再度クエリを実行して、インデックスを追加します。
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10クエリの説明をもう一度確認します。[Rows scanned] の数が減っていることを確認してください。各ステップで返される [Rows returned] は、クエリによって返される数と一致します。
インターリーブされたインデックス
Spanner ではインターリーブされたインデックスを設定できます。前のセクションで説明したセカンダリ インデックスは、データベース階層のルートにあり、従来のデータベースと同じ方法でインデックスを使用します。インターリーブされたインデックスは、インターリーブされた行のコンテキスト内にあります。インターリーブされたインデックスを適用する場所の詳細については、インデックス オプションをご覧ください。
データモデルに合わせて調整する
このチュートリアルの移行部分を自分の状況に適応させるには、Apache Beam のソースファイルを変更してください。実際の移行ウィンドウ中には、ソーススキーマを変更しないようにしてください。そうでないと、データが失われる可能性があります。
受信 JSON を解析してミューテーションを構築するには、GSON を使用します。JSON 定義はデータに合わせて調整します。
対応する JSON マッピングを調整します。
前の手順では、Apache Beam のソースコードを一括インポート用に変更しました。次に同様の方法で、パイプラインのストリーミング部分のソースコードを変更します。最後に、Spanner ターゲット データベースのテーブル作成スクリプト、スキーマ、およびインデックスを調整します。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトを削除する
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
AWS リソースの削除
このチュートリアル以外で AWS アカウントを使用する場合、次のリソースを削除する際は慎重に行ってください。
- Migration という名前の DynamoDB テーブルを削除する。
- 移行手順で作成した Amazon S3 バケットと Lambda 関数を削除します。
- 最後に、このチュートリアルで作成した AWS IAM ユーザーを削除します。
次のステップ
- Spanner スキーマを最適化する方法について読む。
- Dataflow をより複雑な状況で使用する方法を学習する。