Spanner データベースでは、テーブルの主キーごとに Spanner により自動的にインデックスが作成されます。たとえば、Singers の主キー列は自動的にインデックスに登録されるため、操作は必要はありません。
他の列のセカンダリ インデックスを作成することもできます。セカンダリ インデックスを列に追加すると、その列のデータをより効率的に検索できるようになります。たとえば、アルバムをタイトル別にすばやく検索する必要がある場合は、Spanner でテーブル全体をスキャンしなくてもいいように、AlbumTitle にセカンダリ インデックスを作成する必要があります。
同じ例で読み取り / 書き込みトランザクション内で検索を行う場合、より効率的な検索では、テーブル全体をロックしたままにすることも回避します。これにより、AlbumTitle の検索範囲外のテーブルの行に対する挿入や更新が可能になります。
セカンダリ インデックスは、ルックアップを使用することで得られるメリットに加えて、Spanner でより効率的にスキャンを実行し、全テーブル スキャンではなくインデックス スキャンを行うこともできます。
Spanner は、各セカンダリ インデックスに次のデータを格納します。
- ベーステーブルのすべてのキー列
- インデックスに含まれるすべての列
- インデックス定義の省略可能な
STORING句(GoogleSQL 言語データベース)またはINCLUDE句(PostgreSQL 言語データベース)で指定されたすべての列。
Spanner では、セカンダリ インデックスが適切なクエリに使用されるように、テーブルを経時的に分析します。
セカンダリ インデックスを追加する
セカンダリ インデックスを最も効率的に追加できるタイミングは、テーブルの作成時です。テーブルとそのインデックスを同時に作成するには、新しいテーブルと新しいインデックスの DDL ステートメントを 1 つのリクエストで Spanner に送信します。
Spanner では、データベースでトラフィックを引き続き処理しながら、既存のテーブルに新しいセカンダリ インデックスを追加することもできます。Spanner での他のスキーマの更新と同様、既存のデータベースにインデックスを追加する際にデータベースをオフラインにする必要はありません。列またはテーブル全体をロックする必要もありません。
既存のテーブルに新しいインデックスが追加されると、Spanner はインデックスを自動的にバックフィルまたは入力し、インデックスに登録されているデータの最新状態を反映します。Spanner によって管理されるこのプロセスは、低い優先度でノードリソースを使用してバックグラウンドで実行されます。インデックスのバックフィル速度は、インデックスの作成中に変化するノードリソースに対応します。バックフィルはデータベースのパフォーマンスに大きな影響を与えません。
インデックスの作成には数分から数時間かかります。インデックスの作成はスキーマ更新であるため、他のスキーマ更新と同じパフォーマンス制約でバインドされます。セカンダリ インデックスを作成するために必要な時間は、次の要因によって決まります。
- データセットのサイズ
- インスタンスのコンピューティング容量
- インスタンスの負荷
インデックスのバックフィル プロセスの進捗状況を確認するには、進捗状況のセクションをご覧ください。
セカンダリ インデックスの最初の部分として commit タイムスタンプ列を使用すると、ホットスポットが作成され、書き込みパフォーマンスが低下する可能性があるので注意してください。
スキーマでセカンダリ インデックスを定義するには、CREATE INDEX ステートメントを使用します。次に例を示します。
データベースのすべての Singers を姓名でインデックスに登録するには、次のステートメントを使用します。
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
データベースのすべての Songs のインデックスを SongName の値で登録するには:
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
特定の歌手の曲のみインデックスを登録するには、INTERLEAVE IN 句を使用して、次のようにテーブル Singers のインデックスをインターリーブします。
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
特定のアルバムの楽曲のみインデックスを登録するには:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
SongName の降順でインデックスに登録するには:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
以前の DESC アノテーションが SongName に適用されることに注意してください。他のインデックス キーの降順でインデックスに登録するには、DESC と SingerId DESC, AlbumId DESC というアノテーションを付けます。
また、PRIMARY_KEY は予約語であり、インデックスの名前としては使用できないことにご注意ください。これは、主キーの仕様を持つテーブルが作成される際に作成される疑似インデックスに与えられる名前です。
インターリーブされていないインデックスとインターリーブされたインデックスの選択の詳細とベスト プラクティスについては、インデックス オプションと値が単調に増加または減少する列へのインターリーブされたインデックスの使用をご覧ください。
インデックスとインターリーブ
Spanner インデックスは他のテーブルとインターリーブして、インデックス行を別のテーブルの行と配置できます。Spanner テーブルのインターリーブと同様、インデックスの親の主キー列はインデックスに登録される列の接頭辞で、型と並べ替え順序が一致している必要があります。インターリーブ テーブルとは異なり、列名の一致は必要ありません。インターリーブ インデックスの各行は、関連する親の行とともに物理的に格納されます。
たとえば、次のスキーマについて考えてみましょう。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
データベース内のすべての Singers を姓名でインデックスに登録するには、インデックスを作成する必要があります。インデックス SingersByFirstLastName を定義する方法は次のとおりです。
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
(SingerId, AlbumId, SongName) に Songs のインデックスを作成する場合は、次のようにします。
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
または、次のように Songs の祖先とインターリーブされたインデックスを作成することもできます。
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
さらに、(PublisherId, SingerId, AlbumId, SongName) に Songs のインデックスを作成し、Songs の祖先ではないテーブル(Publishers など)とインターリーブすることもできます。Publishers テーブルの主キー(id)は、次の例のインデックス付き列の接頭辞ではありません。Publishers.Id と Songs.PublisherId は同じ型、並べ替え順序、null 可能性を共有するため、これは引き続き許可されます。
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
インデックスのバックフィルの進行状況を確認する
コンソール
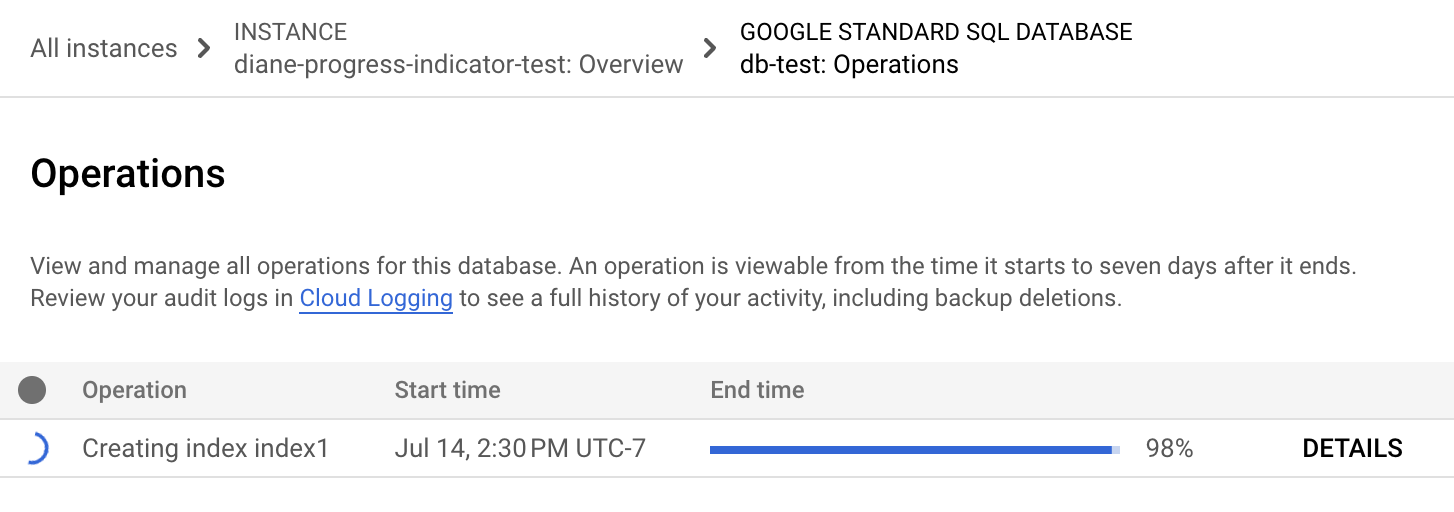
Spanner のナビゲーション メニューで [オペレーション] タブをクリックします。[オペレーション] ページに、現在実行中のオペレーションのリストが表示されます。
リストからバックフィル オペレーションを見つけます。まだ実行中の場合、次の画像のように、完了しているオペレーションの割合が [終了時刻] 列の進行状況インジケーターに表示されます。
gcloud
gcloud spanner operations describe を使用してオペレーションの進行状況を確認します。
オペレーション ID を取得します。
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
次のように置き換えます。
- INSTANCE-NAME は、Spanner インスタンス名に置き換えます。
- DATABASE-NAME は、データベースの名前に置き換えます。
使用上の注意:
表示内容を限定するには、
--filterフラグを指定します。次に例を示します。--filter="metadata.name:example-db"には、特定のデータベースのオペレーションのみが一覧表示されます。--filter="error:*"は、失敗したバックアップ オペレーションのみを一覧表示します。
フィルタ構文については、gcloud topic filters をご覧ください。バックアップ オペレーションのフィルタリングについては、ListBackupOperationsRequest の
filterフィールドをご覧ください。--typeフラグでは大文字と小文字は区別されません。
出力は次のようになります。
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadatagcloud spanner operations describeを実行します。gcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
次のように置き換えます。
- INSTANCE-NAME: Spanner インスタンス名。
- DATABASE-NAME: Spanner データベース名。
- PROJECT-NAME: プロジェクト名
- OPERATION-ID: 確認するオペレーションのオペレーション ID。
出力の
progressセクションに、完了したオペレーションの割合が表示されます。出力は次のようになります。done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST v1
オペレーション ID を取得します。
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
次のように置き換えます。
- INSTANCE-NAME は、Spanner インスタンス名に置き換えます。
- DATABASE-NAME は、データベースの名前に置き換えます。
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT-ID: プロジェクト ID。
- INSTANCE-ID: インスタンス ID。
- DATABASE-ID: データベース ID。
- OPERATION-ID: オペレーション ID。
HTTP メソッドと URL:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
gcloud と REST の場合、各インデックスのバックフィル ステートメントの進行状況は、progress セクションで確認できます。ステートメント配列内のステートメントごとに、進行状況配列に対応するフィールドが表示されます。進行状況の配列の順序は、ステートメントの配列の順序に対応しています。利用可能になると、startTime、progressPercent、endTime の各フィールドに適宜値が入力されます。出力には、バックフィルの進行が完了するまでの推定時間は表示されません。
オペレーションに時間がかかりすぎる場合はキャンセルできます。詳細については、インデックス作成のキャンセルをご覧ください。
インデックスのバックフィルの進捗状況を表示する場合のシナリオ
インデックスのバックフィルの進捗状況を確認しようとすると、さまざまなシナリオの可能性があります。インデックスのバックフィルを必要とするインデックス作成ステートメントは、スキーマ更新オペレーションの一部です。いくつかのステートメントをスキーマ更新オペレーションの構成要素にできます。
最初のシナリオが最も簡単で、インデックス作成ステートメントがスキーマ更新オペレーションの最初のステートメントである場合です。インデックス作成ステートメントは最初のステートメントであるため、実行の順序によって最初に処理され、実行されます。すぐに、インデックス作成ステートメントの startTime フィールドにスキーマ更新オペレーションの開始時刻が入力されます。次に、インデックスのバックフィルの進行状況が 0% を超えると、インデックス作成ステートメントの progressPercent フィールドに値が入力されます。最後に、ステートメントが commit されると endTime フィールドに入力されます。
2 番目のシナリオは、インデックス作成ステートメントがスキーマ更新オペレーションの最初のステートメントではない場合です。実行の順序によって、前のステートメントが commit されるまで、インデックス作成ステートメントに関連するフィールドは入力されません。前述のシナリオと同様に、前のステートメントが commit されると、最初にインデックス作成ステートメントの startTime フィールドに入力され、次に progressPercent フィールドに入力されます。最後に、ステートメントの commit が終了すると、endTime フィールドに値が入力されます。
インデックス作成をキャンセルする
Google Cloud CLI を使用してインデックスの作成をキャンセルできます。Spanner データベースのスキーマ更新オペレーションのリストを取得するには、gcloud spanner operations list コマンドを使用して --filter オプションを含めます。
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
キャンセルするオペレーションの OPERATION_ID を検索してから、gcloud spanner operations cancel コマンドを使用してキャンセルします。
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
既存のインデックスを確認する
データベース内の既存のインデックスに関する情報を確認するには、Google Cloud コンソールまたは Google Cloud CLI を使用できます。
コンソール
Google Cloud コンソールの [Spanner インスタンス] ページに移動します。
確認するインスタンスの名前をクリックします。
左側のペインで、表示するデータベースをクリックし、表示するテーブルをクリックします。
[インデックス] タブをクリックします。 Google Cloud コンソールにインデックスのリストが表示されます。
省略可: インデックスに含まれる列など、インデックスの詳細を取得するには、インデックスの名前をクリックします。
gcloud
gcloud spanner databases ddl describe コマンドを使用します。
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
gcloud CLI により、データベースのテーブルとインデックスを作成するためのデータ定義言語(DDL)ステートメントが出力されます。CREATE
INDEX ステートメントは、既存のインデックスを記述します。次に例を示します。
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
特定のインデックスを使用してクエリする
以降のセクションでは、SQL ステートメントでインデックスを指定する方法と Spanner の読み取りインターフェースを使用する方法について説明します。これらのセクションの例では、MarketingBudget 列を Albums テーブルに追加し、AlbumsByAlbumTitle というインデックスを作成したと想定しています。
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
SQL ステートメントでインデックスを指定する
SQL を使用して Spanner テーブルに対してクエリを実行する場合、Spanner では、クエリを効率化する可能性のあるインデックスが自動的に使用されます。そのため、通常は SQL クエリにインデックスを指定する必要はありません。しかし、ワークロードに重要なクエリについては、より安定したパフォーマンスのため、SQL ステートメントで FORCE_INDEX ディレクティブを使用することをおすすめします。
まれに、Spanner がクエリのレイテンシを増加させるインデックスを選択することがあります。パフォーマンス低下のトラブルシューティングの手順に沿って、クエリに別のインデックスを試すことが理にかなっていると判断した場合、クエリの一部としてインデックスを指定できます。
SQL ステートメントでインデックスを指定するには、FORCE_INDEX ヒントを使用してインデックス ディレクティブを指定します。インデックス ディレクティブでは、次の構文を使用します。
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
インデックスを使用せずにベーステーブルをスキャンするよう Spanner に指示するためには、インデックス ディレクティブも使用できます。
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
インデックス ディレクティブを使用して、名前付きスキーマを持つテーブルのインデックスをスキャンするよう Spanner に指示できます。
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
次の例は、インデックスを指定する SQL クエリを示しています。
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
インデックス ディレクティブは、クエリで必要とされるもののインデックスに格納されていない追加の列お読み取りを Spanner のクエリ プロセッサに対して強制する場合があります。クエリ プロセッサは、インデックスとベーステーブルを結合して、これらの列を取得します。この余分な結合を回避するには、STORING 句(GoogleSQL 言語データベース)または INCLUDE 句(PostgreSQL 言語データベース)を使用して、追加の列をインデックスに保存します。
上の例では、MarketingBudget 列はインデックスに格納されませんが、SQL クエリではこの列が選択されます。そのため、Spanner では、ベーステーブルで MarketingBudget 列を検索してからインデックスのデータと結合し、クエリ結果を返す必要があります。
インデックス ディレクティブに次のいずれかの問題がある場合、Spanner でエラーが返されます。
- インデックスが存在しない。
- インデックスが別のベーステーブルに作成されている。
NULL_FILTEREDインデックスに必要なNULLフィルタリング式がクエリにない。
次の例は、インデックス AlbumsByAlbumTitle を使用して AlbumId、AlbumTitle、MarketingBudget の値をフェッチするクエリを作成して実行する方法を示しています。
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
読み取りインターフェースでのインデックスを指定する
Spanner に対して読み取りインターフェースを使用し、Spanner でインデックスを使用する場合、インデックスを指定する必要があります。読み取りインターフェースでインデックスが自動的に選択されることはありません。
また、インデックスには、主キーの一部である列を除いて、クエリ結果に表示されるすべてのデータを含める必要があります。この制限は、読み取りインターフェースでインデックスとベーステーブル間の結合がサポートされていないために存在します。クエリ結果に他の列を含める必要がある場合は、いくつかのオプションがあります。
STORING句またはINCLUDE句を使用して、追加の列をインデックスに格納します。- 追加の列を含めずにクエリを実行してから、主キーを使用して、追加の列を読み取る別のクエリを送信します。
Spanner では、インデックスの値はインデックス キーの昇順で返されます。値を降順で取得するには、次の手順で操作します。
インデックス キーに
DESCというアノテーションを付けます。次に例を示します。CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);DESCアノテーションは、単一のインデックス キーに適用されます。インデックスに複数のキーが含まれ、クエリ結果をすべてのキーに基づいて降順で表示する必要がある場合は、各キーについてDESCアノテーションを追加します。読み取りでキー範囲が指定されている場合は、キー範囲も降順であることを確認します。つまり、開始キーの値は終了キーの値より大きい必要があります。
次の例は、インデックス AlbumsByAlbumTitle を使用して、AlbumId と AlbumTitle の値を取得する方法を示しています。
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
インデックスのみをスキャンするインデックスを作成する
必要に応じて、STORING 句(GoogleSQL 言語データベースの場合)または INCLUDE 句(PostgreSQL 言語データベースの場合)を使用してインデックスに列のコピーを保存できます。このタイプのインデックスを使用すると、クエリと読み取り呼び出しを実行する際に、次のメリットがあります(追加ストレージを使用する費用がかります)。
- インデックスを使用し、
STORINGまたはINCLUDE句に保存された列を選択する SQL クエリでは、ベーステーブルへの余分な結合が不要になります。 - インデックスを使用する
read()呼び出しで、STORING/INCLUDE句で保存された列を読み取ることができます。
たとえば、MarketingBudget 列のコピーをインデックスに保存する AlbumsByAlbumTitle の代替バージョンを作成したとします(STORING 句または INCLUDE 句は太字になっています)。
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
古い AlbumsByAlbumTitle インデックスを使用する場合、Spanner はインデックスをベーステーブルと結合した後にベーステーブルからその列を取得する必要があります。新しい AlbumsByAlbumTitle2 インデックスを使用する場合、Spanner はインデックスから直接列を読み取るため、より効率的です。
SQL の代わりに読み取りインターフェースを使用する場合、新しい AlbumsByAlbumTitle2 インデックスを使用すると、MarketingBudget 列を直接読み取ることもできます。
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
インデックスを変更する
ALTER INDEX ステートメントを使用して、既存のインデックスまたはドロップ列に列を追加できます。インデックスを作成する場合は、STORING 句(GoogleSQL 言語データベース)または INCLUDE 句(PostgreSQL 言語データベース)によって定義された列リストを更新できます。このステートメントを使用して、インデックス キーに対して列の追加または削除を行うことはできません。たとえば、次の例に示すように、新しいインデックス AlbumsByAlbumTitle2 を作成せずに、ALTER INDEX を使用して、列を AlbumsByAlbumTitle に追加します。
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
既存のインデックスに新しい列を追加すると、Spanner はバックグラウンドのバックフィル プロセスを使用します。バックフィルの進行中はインデックス内の列が読み取れないため、期待されるパフォーマンスの向上が得られない可能性があります。gcloud spanner operations コマンドを使用すると、長時間実行オペレーションを一覧表示してステータスを確認できます。詳細については、オペレーションの説明をご覧ください。
オペレーションをキャンセルを使用して、実行中のオペレーションをキャンセルすることもできます。
バックフィルが完了すると、Spanner は列をインデックスに追加します。インデックスが大きくなると、インデックスを使用するクエリの速度が低下する可能性があります。
次の例は、インデックスから列を削除する方法を示しています。
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
NULL 値のインデックス
デフォルトでは、Spanner は NULL 値をインデックスに登録します。たとえば、テーブル Singers のインデックス SingersByFirstLastName の定義を思い出してください。
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
FirstName または LastName のいずれか、あるいは両方が NULL でも、Singers のすべての行がインデックスに登録されます。

NULL 値がインデックスに登録されている場合、NULL 値を含むデータ全体に対して効率的な SQL クエリと読み取りを実行できます。たとえば、NULL FirstName を含むすべての Singers を検索するには、次の SQL クエリ文を使用します。
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
NULL 値の並べ替え順
Spanner では、指定された型で NULL を最小値として並べ替えを行います。昇順(ASC)の列の場合、NULL 値が最初になります。降順(DESC)の列の場合、NULL 値が最後になります。
NULL 値のインデックス登録を無効にする
GoogleSQL
Null のインデックス登録を無効にするには、インデックスの定義に NULL_FILTERED キーワードを追加します。NULL_FILTERED インデックスは、大半の行に NULL 値が含まれるスパース列をインデックスに登録する場合に特に便利です。この場合、NULL_FILTERED インデックスは NULL を含む通常のインデックスよりもかなりサイズが小さくなり、効率的に維持できます。
NULL 値をインデックスに登録しない SingersByFirstLastName の代替定義は次のとおりです。
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
NULL_FILTERED キーワードは、すべてのインデックス キー列に適用されます。列単位で NULL フィルタリングを指定することはできません。
PostgreSQL
1 つ以上のインデックスに登録された列の null 値を持つ行を除外するには、述語 WHERE COLUMN IS NOT NULL を使用します。null-filtered インデックスは、大半の行に NULL 値が含まれるスパース列をインデックスに登録する場合に特に便利です。この場合、null-filtered インデックスは NULL を含む通常のインデックスよりもかなりサイズが小さくなり、効率的に維持できます。
NULL 値をインデックスに登録しない SingersByFirstLastName の代替定義は次のとおりです。
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
NULL 値を除外すると、Spanner では一部のクエリでその値を使用できなくなります。たとえば、Spanner では、次のクエリに対してこのインデックスは使用されません。これは、LastName が NULL であるすべての Singers 行がこのインデックスで省略されるため、このインデックスを使用すると、クエリで正しい行を返すことができなくなるためです。
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
Spanner でインデックスを使用できるようにするには、インデックスから除外される行をクエリからも除外するようにクエリを書き直す必要があります。
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
proto フィールドのインデックス
インデックスに登録されているフィールドでプリミティブ データ型または ENUM データ型が使用される場合は、生成列を使用して、PROTO 列に保存されているプロトコル バッファのフィールドをインデックスに登録します。
プロトコル メッセージ フィールドにインデックスを定義した場合、そのフィールドを変更または proto スキーマから削除することはできません。詳細については、proto フィールドのインデックスを含むスキーマの更新をご覧ください。
以下に、SingerInfo proto メッセージ列を含む Singers テーブルの例を示します。PROTO の nationality フィールドにインデックスを定義するには、格納されている生成列を作成する必要があります。
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
googlesql.example.SingerInfo proto 型の次の定義があります。
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
次に、proto の nationality フィールドにインデックスを定義します。
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
次の SQL クエリは、前のインデックスを使用してデータを読み取ります。
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
注:
- プロトコル バッファ列のフィールドのインデックスにアクセスするには、インデックス ディレクティブを使用します。
- プロトコル バッファの繰り返しフィールドにはインデックスを作成できません。
proto フィールドのインデックスを含むスキーマの更新
プロトコル メッセージ フィールドにインデックスを定義した場合、そのフィールドを変更または proto スキーマから削除することはできません。これは、インデックスを定義すると、スキーマが更新されるたびに型チェックが実行されるためです。Spanner は、インデックス定義で使用されるパスのすべてのフィールドの型情報を取得します。
一意のインデックス
インデックスは、UNIQUE として宣言できます。UNIQUE インデックスを使用すると、インデックスに登録するデータに制約が追加され、指定したインデックス キーでの重複が禁止されます。この制約は、トランザクションの commit 時に Spanner により適用されます。同じキーに複数のインデックス エントリが存在するトランザクションは commit に失敗します。
テーブルの先頭に UNIQUE 以外のデータが存在する場合、UNIQUE インデックスを作成しようとすると失敗します。
UNIQUE NULL_FILTERED インデックスに関する注意事項
インデックスのキー部分の 1 つ以上が NULL の場合、UNIQUE NULL_FILTERED インデックスでインデックス キーの一意性は維持されません。
たとえば、次のテーブルとインデックスを作成したとします。
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
ExampleTable の次の 2 行では、セカンダリ インデックス キー Key1、Key2、Col1 に同じ値が設定されています。
1, NULL, 1, 1
1, NULL, 2, 1
Key2 が NULL でインデックスが null-filtered であるため、インデックス ExampleIndex には行がありません。これらはインデックスに挿入されないため、(Key1, Key2,
Col1) の一意性に違反していても、インデックスはこれらの値を拒否しません。
インデックスでタプル(Key1、Key2、Col1)の値の一意性を適用するには、テーブル定義で Key2 に NOT NULL というアノテーションを付けるか、null をフィルタしないインデックスを作成する必要があります。
インデックスを削除する
スキーマからセカンダリ インデックスを削除するには、DROP INDEX ステートメントを使用します。
SingersByFirstLastName という名前のインデックスを削除するには、次のようにします。
DROP INDEX SingersByFirstLastName;
迅速なスキャンのためのインデックス
Spanner で 1 つ以上の列から値をフェッチするために、(インデックス付きルックアップではなく)テーブル スキャンを実行する必要がある場合、その列にインデックスがあり、クエリで指定された順序になっていれば、よりすばやく結果を得られます。スキャンが必要なクエリを頻繁に実行する場合は、セカンダリ インデックスを作成することをおすすめします。これは、スキャンを効率的に実行するのに役立ちます。
特に、テーブルの主キーやその他のインデックスを逆順で頻繁に Spanner がスキャンする必要がある場合は、目的の順序を明確にするセカンダリ インデックスを使用することで、効率を高めることができます。
たとえば、次のクエリでは、Spanner が SongId の最小値を見つけるために Songs をスキャンする必要がありますが、常にすばやく結果が返されます。
SELECT SongId FROM Songs LIMIT 1;
SongId は、テーブルの主キーであり、すべての主キーと同様に昇順で保存されます。Spanner では、そのキーのインデックスをスキャンして最初の結果をすばやく取得できます。
ただし、特に Songs が大量のデータを保持している場合には、セカンダリ インデックスを使用しないと、次のクエリはすばやく結果を返しません。
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
SongId はテーブルの主キーですが、Spanner では、テーブル全体をスキャンしないと、列の最大値をフェッチすることができません。
次のインデックスを追加すると、このクエリの結果がすばやく返されるようになります。
CREATE INDEX SongIdDesc On Songs(SongId DESC);
適宜このインデックスを使用すると、Spanner は 2 番目のクエリの結果をより迅速に返します。
次のステップ
- Spanner に関する SQL のベスト プラクティスについて確認する。
- Spanner のクエリ実行プランを理解する。
- SQL クエリで発生するパフォーマンス低下のトラブルシューティング方法を確認する。