Arsitektur referensi ini memberi Anda metode dan infrastruktur awal untuk mem-build sistem continuous integration/continuous delivery (CI/CD) modern menggunakan alat seperti Google Kubernetes Engine, Cloud Build, Skaffold, kustomize, Config Sync, Policy Controller, Artifact Registry, dan Cloud Deploy.
Dokumen ini adalah bagian dari rangkaian:
- CI/CD modern dengan GKE: Framework distribusi software
- CI/CD modern dengan GKE: Membuat sistem CI/CD (dokumen ini)
- CI/CD modern dengan GKE: Menerapkan alur kerja developer
Dokumen ini ditujukan untuk arsitek perusahaan dan developer aplikasi, serta tim keamanan IT, DevOps, dan Site Reliability Engineering. Beberapa pengalaman dengan alat dan proses deployment otomatis berguna untuk memahami konsep dalam dokumen ini.
Alur kerja CI/CD
Untuk membuat sistem CI/CD modern, Anda harus memilih alat dan layanan yang menjalankan fungsi utama sistem terlebih dahulu. Arsitektur referensi ini berfokus pada penerapan fungsi inti sistem CI/CD yang ditampilkan dalam diagram berikut:

Implementasi referensi ini menggunakan alat berikut untuk setiap komponen:
- Untuk pengelolaan kode sumber: GitHub
- Menyimpan kode aplikasi dan konfigurasi.
- Memungkinkan Anda meninjau perubahan.
- Untuk pengelolaan konfigurasi aplikasi:
kustomize- Menentukan konfigurasi aplikasi yang diinginkan.
- Memungkinkan Anda menggunakan kembali dan memperluas primitif atau blueprint konfigurasi.
- Untuk continuous integration: Cloud Build
- Menguji dan memvalidasi kode sumber.
- Mem-build artefak yang digunakan lingkungan deployment.
- Untuk continuous delivery: Cloud Deploy
- Menentukan proses peluncuran kode di seluruh lingkungan.
- Memberikan rollback untuk perubahan yang gagal.
- Untuk konfigurasi infrastruktur: Config Sync
- Menerapkan konfigurasi cluster dan kebijakan secara konsisten.
- Untuk penerapan kebijakan: Pengontrol Kebijakan
- Memberikan mekanisme yang dapat Anda gunakan untuk menentukan apa yang diizinkan untuk dijalankan di lingkungan tertentu berdasarkan kebijakan organisasi.
- Untuk orkestrasi penampung: Google Kubernetes Engine
- Menjalankan artefak yang dibuat selama CI.
- Memberikan metodologi penskalaan, pemeriksaan kondisi, dan peluncuran untuk beban kerja.
- Untuk artefak penampung: Artifact Registry
- Menyimpan artefak (image container) yang di-build selama CI.
Arsitektur
Bagian ini menjelaskan komponen CI/CD yang Anda terapkan menggunakan arsitektur referensi ini: infrastruktur, pipeline, repositori kode, dan zona landing.
Untuk diskusi umum tentang aspek-aspek sistem CI/CD ini, lihat CI/CD modern dengan GKE: Framework pengiriman software.
Varian Arsitektur Referensi
Arsitektur referensi memiliki dua model deployment:
- Varian multi-project yang lebih mirip dengan deployment produksi dengan batas isolasi yang lebih baik
- Varian satu project, yang berguna untuk demonstrasi
Arsitektur referensi multi-project
Arsitektur referensi versi multi-project menyimulasikan skenario seperti produksi. Dalam skenario ini, persona yang berbeda membuat infrastruktur, pipeline CI/CD, dan aplikasi dengan batas isolasi yang tepat. Persona atau tim ini hanya dapat mengakses resource yang diperlukan.
Untuk informasi selengkapnya, lihat CI/CD modern dengan GKE: Framework pengiriman software.
Untuk mengetahui detail tentang cara menginstal dan menerapkan versi arsitektur referensi ini, lihat blueprint pengiriman software
Arsitektur referensi satu project
Arsitektur referensi versi single-project menunjukkan cara menyiapkan seluruh platform pengiriman software dalam satu project Google Cloud . Versi ini dapat membantu pengguna yang tidak memiliki peran IAM yang ditingkatkan untuk menginstal dan mencoba arsitektur referensi hanya dengan peran pemilik di project. Dokumen ini menunjukkan versi satu project dari arsitektur referensi.
Infrastruktur platform
Infrastruktur untuk arsitektur referensi ini terdiri dari cluster Kubernetes untuk mendukung lingkungan aplikasi pengembangan, staging, dan produksi. Diagram berikut menunjukkan tata letak logis cluster:

Repositori kode
Dengan menggunakan arsitektur referensi ini, Anda menyiapkan repositori untuk operator, developer, engineer platform, dan keamanan.
Diagram berikut menunjukkan implementasi arsitektur referensi dari berbagai repositori kode dan cara tim operasi, pengembangan, dan keamanan berinteraksi dengan repositori:

Dalam alur kerja ini, operator Anda dapat mengelola praktik terbaik untuk CI/CD dan konfigurasi aplikasi di repositori operator. Saat developer Anda melakukan aktivasi aplikasi di repositori pengembangan, mereka akan otomatis mendapatkan praktik terbaik, logika bisnis untuk aplikasi, dan konfigurasi khusus yang diperlukan agar aplikasi mereka dapat beroperasi dengan benar. Sementara itu, tim operasi dan keamanan Anda dapat mengelola konsistensi dan keamanan platform di repositori konfigurasi dan kebijakan.
Zona landing aplikasi
Dalam arsitektur referensi ini, zona landing untuk aplikasi dibuat saat aplikasi disediakan. Dalam dokumen berikutnya dalam seri ini, Modern CI/CD dengan GKE: Menerapkan alur kerja developer, Anda akan menyediakan aplikasi baru yang membuat zona landing-nya sendiri. Diagram berikut mengilustrasikan komponen penting zona landing yang digunakan dalam arsitektur referensi ini:

Setiap namespace menyertakan akun layanan yang digunakan untuk Workload Identity Federation untuk GKE guna mengakses layanan di luar penampung Kubernetes, seperti Cloud Storage atau Spanner. Namespace juga mencakup resource lain seperti kebijakan jaringan untuk mengisolasi atau berbagi batas dengan namespace atau aplikasi lain.
Namespace dibuat oleh akun layanan eksekusi CD. Sebaiknya tim mengikuti prinsip hak istimewa terendah untuk membantu memastikan bahwa akun layanan eksekusi CD hanya dapat mengakses namespace yang diperlukan.
Anda dapat menentukan akses akun layanan di Config Sync dan menerapkannya menggunakan peran dan binding peran kontrol akses berbasis peran (RBAC) Kubernetes. Dengan model ini, tim dapat men-deploy resource apa pun langsung ke namespace yang mereka kelola, tetapi dicegah untuk menimpa atau menghapus resource dari namespace lain.
Tujuan
- Deploy arsitektur referensi satu project.
- Jelajahi repositori kode.
- Pelajari pipeline dan infrastruktur.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
- Google Kubernetes Engine (GKE)
- Google Kubernetes Engine (GKE) Enterprise edition for Config Sync and Policy Controller
- Cloud Build
- Artifact Registry
- Cloud Deploy
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Setelah menyelesaikan tugas yang dijelaskan dalam dokumen ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, lihat Pembersihan.
Sebelum memulai
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
Men-deploy arsitektur referensi
Di Cloud Shell, tetapkan project:
gcloud config set core/project PROJECT_ID
Ganti
PROJECT_IDdengan ID project Google Cloud Anda.Di Cloud Shell, clone repositori Git:
git clone https://github.com/GoogleCloudPlatform/software-delivery-blueprint.git cd software-delivery-blueprint/launch-scripts git checkout single-project-blueprintBuat token akses pribadi di GitHub dengan cakupan berikut:
repodelete_repoadmin:orgadmin:repo_hook
Ada file kosong bernama
vars.shdi foldersoftware-delivery-bluprint/launch-scripts. Tambahkan teks berikut ke file:cat << EOF >vars.sh export INFRA_SETUP_REPO="gke-infrastructure-repo" export APP_SETUP_REPO="application-factory-repo" export GITHUB_USER=GITHUB_USER export TOKEN=TOKEN export GITHUB_ORG=GITHUB_ORG export REGION="us-central1" export SEC_REGION="us-west1" export TRIGGER_TYPE="webhook" EOF
Ganti
GITHUB_USERdengan nama pengguna GitHub.Ganti
TOKENdengan token akses pribadi GitHub.Ganti
GITHUB_ORGdengan nama organisasi GitHub.Jalankan skrip
bootstrap.sh. Jika Cloud Shell meminta otorisasi, klik Authorize:./bootstrap.shSkrip ini mem-bootstrap platform pengiriman software.
Menjelajahi repositori kode
Di bagian ini, Anda akan mempelajari repositori kode.
Login ke GitHub
- Di browser web, buka github.com dan login ke akun Anda.
- Klik ikon gambar di bagian atas antarmuka.
- Klik Organisasi Anda.
- Pilih organisasi yang Anda berikan sebagai input dalam file
vars.sh. - Klik tab Repositori.
Menjelajahi repositori awal, operator, konfigurasi, dan infrastruktur
Repositori awal, operator, konfigurasi, dan infrastruktur adalah tempat operator dan administrator platform menentukan praktik terbaik umum untuk mem-build dan mengoperasikan platform. Repositori ini dibuat di organisasi GitHub Anda saat arsitektur referensi di-bootstrap.
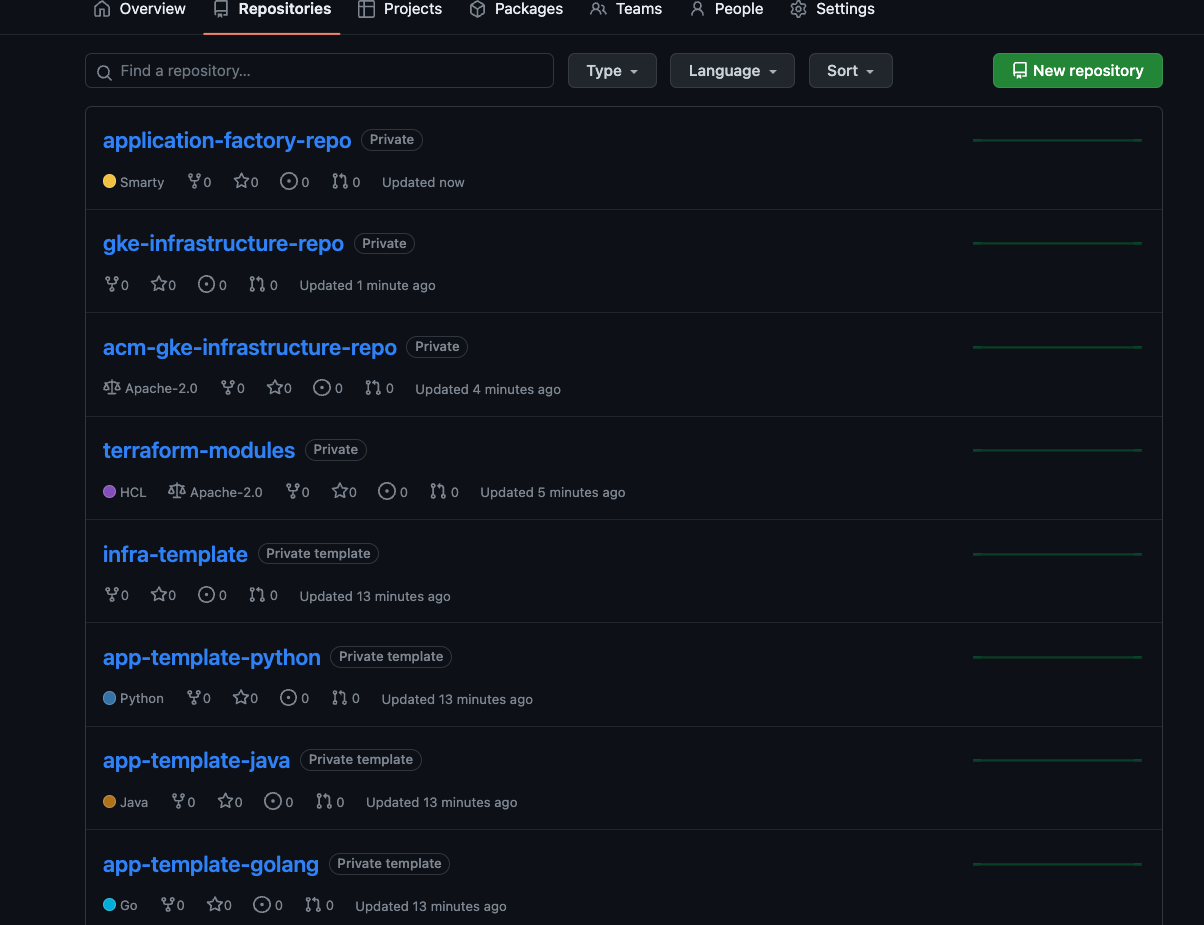
Repositori awal
Repositori awal membantu penerapan praktik terbaik CI/CD, infrastruktur, dan pengembangan di seluruh platform. Untuk mengetahui informasi selengkapnya, lihat CI/CD modern dengan GKE: Framework pengiriman software
Repositori awal aplikasi
Di repositori pemicu aplikasi, operator Anda dapat mengenkode dan mendokumentasikan praktik terbaik seperti CI/CD, pengumpulan metrik, logging, langkah penampung, dan keamanan untuk aplikasi. Termasuk dalam arsitektur referensi adalah contoh repositori awal untuk aplikasi Go, Python, dan Java.
Repositori awal aplikasi app-template-python, app-template-java, dan
app-template-golang berisi
kode boilerplate
yang dapat Anda gunakan untuk membuat aplikasi baru. Selain membuat aplikasi baru, Anda dapat membuat template baru berdasarkan persyaratan aplikasi. Repositori pemicu aplikasi yang disediakan oleh arsitektur referensi berisi:
Dasar dan patch
kustomizedi folderk8s.Kode sumber aplikasi.
Dockerfileyang menjelaskan cara mem-build dan menjalankan aplikasi.File
cloudbuild.yamlyang menjelaskan praktik terbaik untuk langkah-langkah CI.File
skaffold.yamlyang menjelaskan langkah-langkah deployment.
Dalam dokumen berikutnya dalam seri ini,
CI/CD Modern dengan GKE: Menerapkan alur kerja developer,
Anda akan menggunakan repositori app-template-python untuk membuat
aplikasi baru.
Repositori pemicu infrastruktur
Di repositori awal infrastruktur, operator dan administrator infrastruktur Anda dapat membuat kode dan mendokumentasikan praktik terbaik seperti pipeline CI/CD, IaC, pengumpulan metrik, logging, dan keamanan untuk infrastruktur. Termasuk dalam arsitektur referensi adalah contoh repositori awal infrastruktur yang menggunakan Terraform. Repositori awal infrastruktur infra-template berisi kode boilerplate untuk Terraform yang dapat Anda gunakan untuk membuat resource infrastruktur yang diperlukan aplikasi, seperti bucket Cloud Storage, atau database Spanner, atau lainnya.
Repositori template bersama
Di repositori template bersama, administrator dan operator infrastruktur menyediakan template standar untuk melakukan tugas. Ada repositori bernama terraform-modules yang disediakan dengan arsitektur referensi. Repositori ini menyertakan kode Terraform dengan template untuk membuat berbagai resource infrastruktur.
Repositori operator
Dalam arsitektur referensi, repositori operator sama dengan repositori pemicu aplikasi. Operator mengelola file yang diperlukan untuk CI dan CD di repositori pemicu aplikasi.
Arsitektur referensi mencakup repositori app-template-python, app-template-java, dan
app-template-golang.
- Ini adalah template awal dan berisi manifes Kubernetes dasar untuk aplikasi yang berjalan di Kubernetes di platform. Operator dapat memperbarui manifes di template awal sesuai kebutuhan. Update diambil saat aplikasi dibuat.
- File
cloudbuild.yamldanskaffold.yamldi repositori ini menyimpan praktik terbaik untuk menjalankan CI dan CD di platform. Serupa dengan konfigurasi aplikasi, operator dapat memperbarui dan menambahkan langkah-langkah ke praktik terbaik. Setiap pipeline aplikasi dibuat menggunakan langkah-langkah terbaru.
Dalam implementasi referensi ini, operator menggunakan
kustomize
untuk mengelola konfigurasi dasar di folder k8s dari repositori awal.
Kemudian, developer bebas memperluas manifes dengan perubahan khusus
aplikasi seperti nama resource dan file konfigurasi. Alat kustomize mendukung konfigurasi sebagai data. Dengan
metodologi ini, input dan output kustomize adalah resource Kubernetes. Anda dapat
menggunakan output dari satu modifikasi manifes untuk modifikasi lain.
Diagram berikut mengilustrasikan konfigurasi dasar untuk aplikasi Spring Boot:

Konfigurasi sebagai model data di kustomize memiliki manfaat utama: saat
operator mengupdate konfigurasi dasar, update tersebut akan otomatis digunakan
oleh pipeline deployment developer pada operasi berikutnya tanpa perubahan apa pun di
sisi developer.
Untuk informasi selengkapnya tentang cara menggunakan kustomize untuk mengelola manifes Kubernetes,
lihat
dokumentasi kustomize.
Repositori konfigurasi dan kebijakan
Yang disertakan dalam arsitektur referensi adalah implementasi repositori konfigurasi dan kebijakan
yang menggunakan Config Sync dan Policy Controller. Repositori
acm-gke-infrastructure-repo berisi konfigurasi dan kebijakan
yang Anda deploy di seluruh cluster lingkungan aplikasi. Konfigurasi
yang ditentukan dan disimpan oleh admin platform di repositori ini penting untuk
memastikan platform memiliki tampilan dan nuansa yang konsisten bagi tim operasi dan
pengembangan.
Bagian berikut membahas cara arsitektur referensi menerapkan repositori konfigurasi dan kebijakan secara lebih mendetail.
Konfigurasi
Dalam implementasi referensi ini, Anda akan menggunakan Config Sync untuk mengelola konfigurasi cluster secara terpusat di platform dan menerapkan kebijakan. Manajemen terpusat memungkinkan Anda menyebarkan perubahan konfigurasi di seluruh sistem.
Dengan Config Sync, organisasi Anda dapat mendaftarkan cluster untuk menyinkronkan konfigurasinya dari repositori Git, proses yang dikenal sebagai GitOps. Saat Anda menambahkan cluster baru, cluster tersebut akan otomatis disinkronkan ke konfigurasi terbaru dan terus merekonsiliasi status cluster dengan konfigurasi jika ada yang melakukan perubahan di luar band.
Untuk informasi selengkapnya tentang Config Sync, lihat dokumentasinya.
Kebijakan
Dalam implementasi referensi ini, Anda menggunakan Pengontrol Kebijakan, yang didasarkan pada Open Policy Agent, untuk mencegat dan memvalidasi setiap permintaan ke cluster Kubernetes di platform. Anda dapat membuat kebijakan menggunakan bahasa kebijakan Rego, yang memungkinkan Anda mengontrol sepenuhnya tidak hanya jenis resource yang dikirim ke cluster, tetapi juga konfigurasinya.
Arsitektur dalam diagram berikut menunjukkan alur permintaan untuk menggunakan Policy Controller guna membuat resource:

Anda membuat dan menentukan aturan di repositori Config Sync, dan perubahan ini diterapkan ke cluster. Setelah itu, permintaan resource baru dari klien CLI atau API divalidasi terhadap batasan oleh Policy Controller.
Untuk mengetahui informasi selengkapnya tentang mengelola kebijakan, lihat ringkasan Pengontrol Kebijakan.
Repositori infrastruktur
Referensi ini mencakup implementasi repositori infrastruktur menggunakan Terraform. Repositori gke-infrastructure-repo berisi infrastruktur sebagai kode untuk membuat cluster GKE untuk lingkungan pengembangan, staging, dan produksi, serta mengonfigurasi Config Sync di dalamnya menggunakan repositori acm-gke-infrastructure-repo. gke-infrastructure-repo berisi tiga cabang, satu untuk setiap lingkungan pengembangan, staging, dan produksi. Folder ini juga berisi folder pengembangan, staging, dan produksi di setiap cabang.
Mempelajari pipeline dan infrastruktur
Arsitektur referensi membuat pipeline di project Google Cloud. Pipeline ini bertanggung jawab untuk membuat infrastruktur bersama.
Pipeline
Di bagian ini, Anda akan mempelajari pipeline infrastruktur sebagai kode dan menjalankannya untuk membuat infrastruktur bersama, termasuk cluster GKE. Pipeline adalah pemicu Cloud Build bernama create-infra di project Google Cloud yang ditautkan ke repositori infrastruktur gke-infrastructure-repo. Anda mengikuti metodologi GitOps untuk membuat infrastruktur seperti yang dijelaskan dalam video Repeatable GCP Environments at Scale With Cloud Build Infra-As-Code Pipelines.
gke-infrastructure-repo memiliki cabang pengembangan, staging, dan produksi. Di repositori, ada juga folder dev, staging, dan produksi yang sesuai dengan cabang ini. Ada aturan perlindungan cabang di repositori yang memastikan bahwa kode hanya dapat di-push ke cabang dev. Untuk mendorong kode ke cabang staging dan produksi, Anda harus membuat permintaan pull.
Biasanya, seseorang yang memiliki akses ke repositori akan meninjau perubahan, lalu menggabungkan permintaan pull untuk memastikan hanya perubahan yang diinginkan yang dipromosikan ke cabang yang lebih tinggi. Agar individu dapat mencoba blueprint, aturan perlindungan cabang telah dilonggarkan di arsitektur referensi sehingga administrator repositori dapat mengabaikan peninjauan dan menggabungkan permintaan pull.
Saat push dilakukan ke gke-infrastructure-repo, push akan memanggil pemicu create-infra. Pemicu tersebut mengidentifikasi cabang tempat push terjadi dan membuka folder yang sesuai di repositori pada cabang tersebut. Setelah menemukan folder yang sesuai, Terraform akan dijalankan menggunakan file yang ada dalam folder tersebut. Misalnya, jika kode di-push ke cabang dev, pemicu akan menjalankan Terraform di folder dev cabang dev untuk membuat cluster GKE dev. Demikian pula, saat push terjadi ke cabang staging, pemicu akan menjalankan Terraform di folder staging cabang staging untuk membuat cluster GKE staging.
Jalankan pipeline untuk membuat cluster GKE:
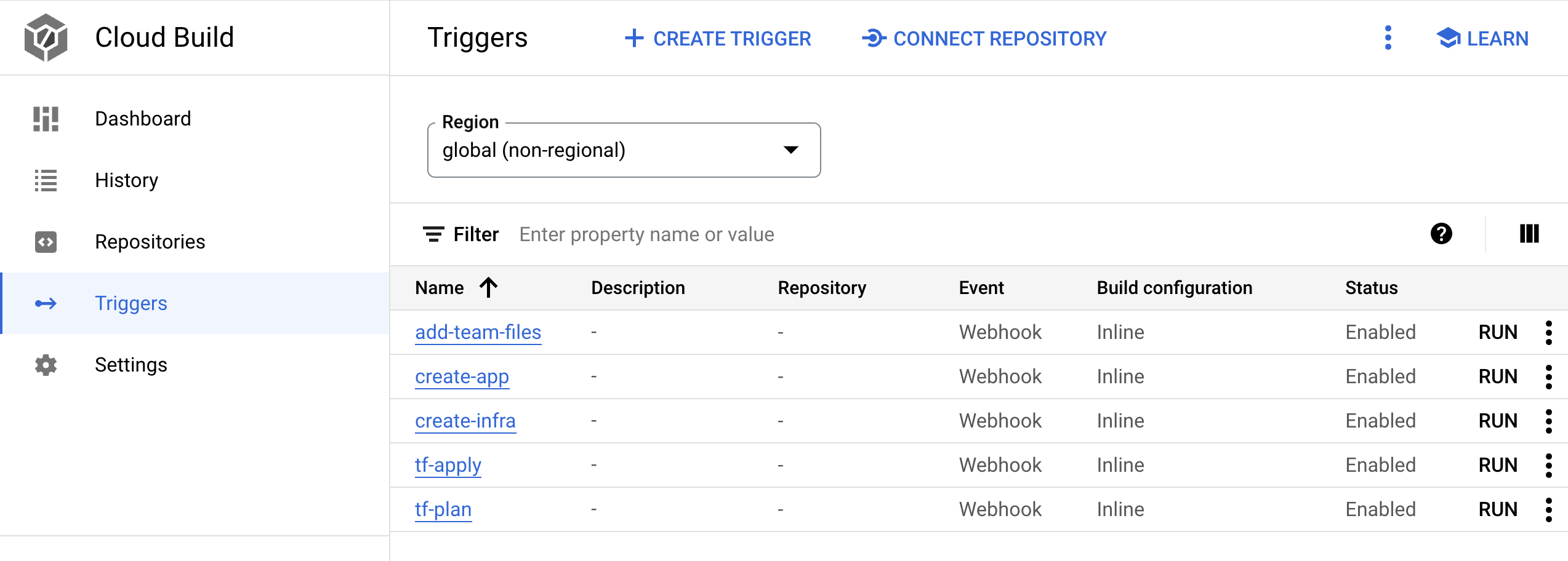
Di konsol Google Cloud, buka halaman Cloud Build.
- Ada lima pemicu webhook Cloud Build. Cari pemicu dengan nama
create-infra. Pemicu ini membuat infrastruktur bersama termasuk cluster GKE.
- Ada lima pemicu webhook Cloud Build. Cari pemicu dengan nama
Klik nama pemicu. Definisi pemicu akan terbuka.
Klik BUKA EDITOR untuk melihat langkah-langkah yang dijalankan pemicu.
Pemicu lainnya digunakan saat Anda melakukan aktivasi aplikasi di CI/CD Modern dengan GKE: Menerapkan alur kerja developer
Di konsol Google Cloud, buka halaman Cloud Build.
Buka halaman histori Cloud Build
Tinjau pipeline yang ada di halaman histori. Saat Anda men-deploy platform pengiriman software menggunakan
bootstrap.sh, skrip akan mendorong kode ke cabang dev repositorigke-infrastructure-repoyang memulai pipeline ini dan membuat cluster GKE dev.Untuk membuat cluster GKE staging, kirim permintaan pull dari cabang dev ke cabang staging:
Buka GitHub dan buka repositori
gke-infrastructure-repo.Klik Pull request, lalu New pull request.
Di menu Base, pilih staging dan di menu Compare, pilih dev.
Klik Create pull request.
Jika Anda adalah administrator di repositori, gabungkan permintaan pull. Jika tidak, minta administrator untuk menggabungkan permintaan pull.
Di konsol Google Cloud, buka halaman histori Cloud Build.
Buka halaman histori Cloud Build
Pipeline Cloud Build kedua dimulai di project. Pipeline ini membuat cluster GKE staging.
Untuk membuat cluster GKE produksi, kirim
pull requestdari staging ke cabang produksi:Buka GitHub dan buka repositori
gke-infrastructure-repo.Klik Pull request, lalu New pull request.
Di menu Base, pilih prod dan di menu Compare, pilih staging.
Klik Create pull request.
Jika Anda adalah administrator di repositori, gabungkan permintaan pull. Jika tidak, minta administrator untuk menggabungkan permintaan pull.
Di konsol Google Cloud, buka halaman histori Cloud Build.
Buka halaman histori Cloud Build
Pipeline Cloud Build ketiga dimulai di project. Pipeline ini membuat cluster GKE produksi.
Infrastruktur
Di bagian ini, Anda akan mempelajari infrastruktur yang dibuat oleh pipeline.
Di konsol Google Cloud, buka halaman Kubernetes clusters.
Buka halaman cluster Kubernetes
Halaman ini mencantumkan cluster yang digunakan untuk pengembangan (
gke-dev-us-central1), staging (gke-staging-us-central1), dan produksi (gke-prod-us-central1,gke-prod-us-west1):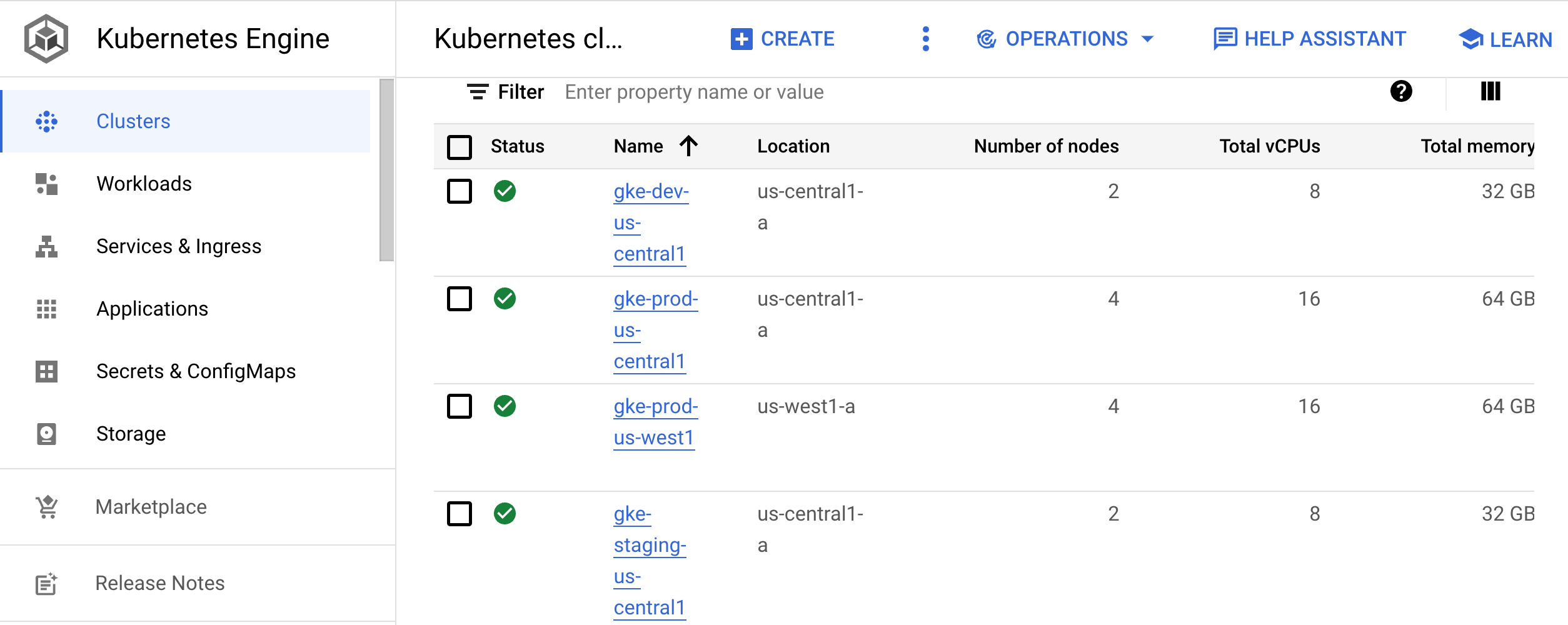
Cluster pengembangan
Cluster pengembangan (gke-dev-us-central1) memberi developer Anda akses ke
namespace yang dapat mereka gunakan untuk melakukan iterasi pada aplikasi mereka. Sebaiknya
tim menggunakan alat seperti
Skaffold
yang menyediakan alur kerja iteratif dengan memantau kode secara aktif dalam
pengembangan dan menerapkannya kembali ke lingkungan pengembangan saat perubahan
dilakukan. Loop iterasi ini mirip dengan
hot reload.
Namun, loop ini tidak khusus bahasa pemrograman, tetapi berfungsi dengan
aplikasi apa pun yang dapat Anda build dengan image Docker. Anda dapat menjalankan loop di dalam cluster Kubernetes.
Atau, developer Anda dapat mengikuti loop CI/CD untuk lingkungan pengembangan. Loop tersebut membuat perubahan kode siap dipromosikan ke lingkungan yang lebih tinggi.
Dalam dokumen berikutnya dalam seri ini, CI/CD Modern dengan GKE: Menerapkan alur kerja developer, Anda akan menggunakan Skaffold dan CI/CD untuk membuat loop pengembangan.
Cluster staging
Cluster ini menjalankan lingkungan staging aplikasi Anda. Dalam arsitektur referensi ini, Anda akan membuat satu cluster GKE untuk staging. Biasanya, lingkungan staging adalah replika persis dari lingkungan produksi.
Cluster produksi
Dalam arsitektur referensi, Anda memiliki dua cluster GKE untuk lingkungan produksi. Untuk redundansi geografis atau sistem ketersediaan tinggi (HA), sebaiknya tambahkan beberapa cluster ke setiap lingkungan. Untuk semua cluster tempat aplikasi di-deploy, sebaiknya gunakan cluster regional. Pendekatan ini melindungi aplikasi Anda dari kegagalan tingkat zona dan gangguan apa pun yang disebabkan oleh upgrade cluster atau node pool.
Untuk menyinkronkan konfigurasi resource cluster, seperti namespace, kuota, dan RBAC, sebaiknya gunakan Config Sync. Untuk mengetahui informasi selengkapnya tentang cara mengelola resource tersebut, lihat Repositori konfigurasi dan kebijakan.
Menerapkan arsitektur referensi
Setelah mempelajari arsitektur referensi, Anda dapat mempelajari alur kerja developer yang didasarkan pada implementasi ini. Dalam dokumen berikutnya dalam seri ini, Modern CI/CD dengan GKE: Menerapkan alur kerja developer, Anda akan membuat aplikasi baru, menambahkan fitur, lalu men-deploy aplikasi ke lingkungan staging dan produksi.
Pembersihan
Jika Anda ingin mencoba dokumen berikutnya dalam rangkaian ini, CI/CD Modern dengan GKE: Menerapkan alur kerja developer, jangan hapus project atau resource yang terkait dengan arsitektur referensi ini. Atau, agar tidak dikenai biaya pada akun Google Cloud untuk resource yang Anda gunakan dalam arsitektur referensi, Anda dapat menghapus project atau menghapus resource secara manual.
Menghapus project
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Menghapus resource secara manual
Di Cloud Shell, hapus infrastruktur:
gcloud container clusters delete gke-dev-us-central1 gcloud container clusters delete gke-staging-us-central1 gcloud container clusters delete gke-prod-us-central1 gcloud container clusters delete gke-prod-us-west1 gcloud beta builds triggers delete create-infra gcloud beta builds triggers delete add-team-files gcloud beta builds triggers delete create-app gcloud beta builds triggers delete tf-plan gcloud beta builds triggers delete tf-apply
Langkah berikutnya
- Buat aplikasi baru dengan mengikuti langkah-langkah dalam CI/CD Modern dengan GKE: Menerapkan alur kerja developer.
- Pelajari praktik terbaik untuk menyiapkan federasi identitas.
Baca Kubernetes dan tantangan deployment software berkelanjutan.
Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.