Google Cloud Managed Service pour Prometheus est la solution multicloud et multiprojet entièrement gérée de Google Cloudpour les métriques Prometheus et OpenTelemetry. Il vous permet de surveiller vos charges de travail et d'envoyer des alertes à l'échelle mondiale à l'aide de Prometheus et d'OpenTelemetry, sans avoir à gérer et exploiter manuellement Prometheus à grande échelle.
Managed Service pour Prometheus collecte les métriques des exportateurs Prometheus et vous permet d'interroger les données à l'échelle mondiale à l'aide de PromQL, ce qui signifie que vous pouvez continuer à utiliser tous les tableaux de bord Grafana existants, les alertes basées sur PromQL et les workflows. Cet environnement est compatible avec le cloud hybride et le multicloud. Il peut surveiller Kubernetes, les VM et les charges de travail sans serveur sur Cloud Run, conserver les données pendant 24 mois et assurer la portabilité en restant compatible avec les services Prometheus en amont. Vous pouvez également compléter votre surveillance Prometheus en interrogeant plus de 6 500 métriques gratuites dans Cloud Monitoring, y compris des métriques système gratuites GKE, à l'aide de PromQL.
Ce document fournit une présentation du service géré. Des documents supplémentaires décrivent la configuration et l'exécution du service. Pour recevoir régulièrement des informations sur les nouvelles fonctionnalités et les nouvelles versions, envoyez le formulaire d'inscription facultatif.
Découvrez comment The Home Depot utilise Managed Service pour Prometheus pour obtenir une observabilité unifiée dans 2 200 magasins exécutant des clusters Kubernetes sur site :
Présentation du système
Google Cloud Managed Service pour Prometheus vous offre la familiarité de Prometheus avec l'infrastructure globale, multicloud et multiprojet de Cloud Monitoring.
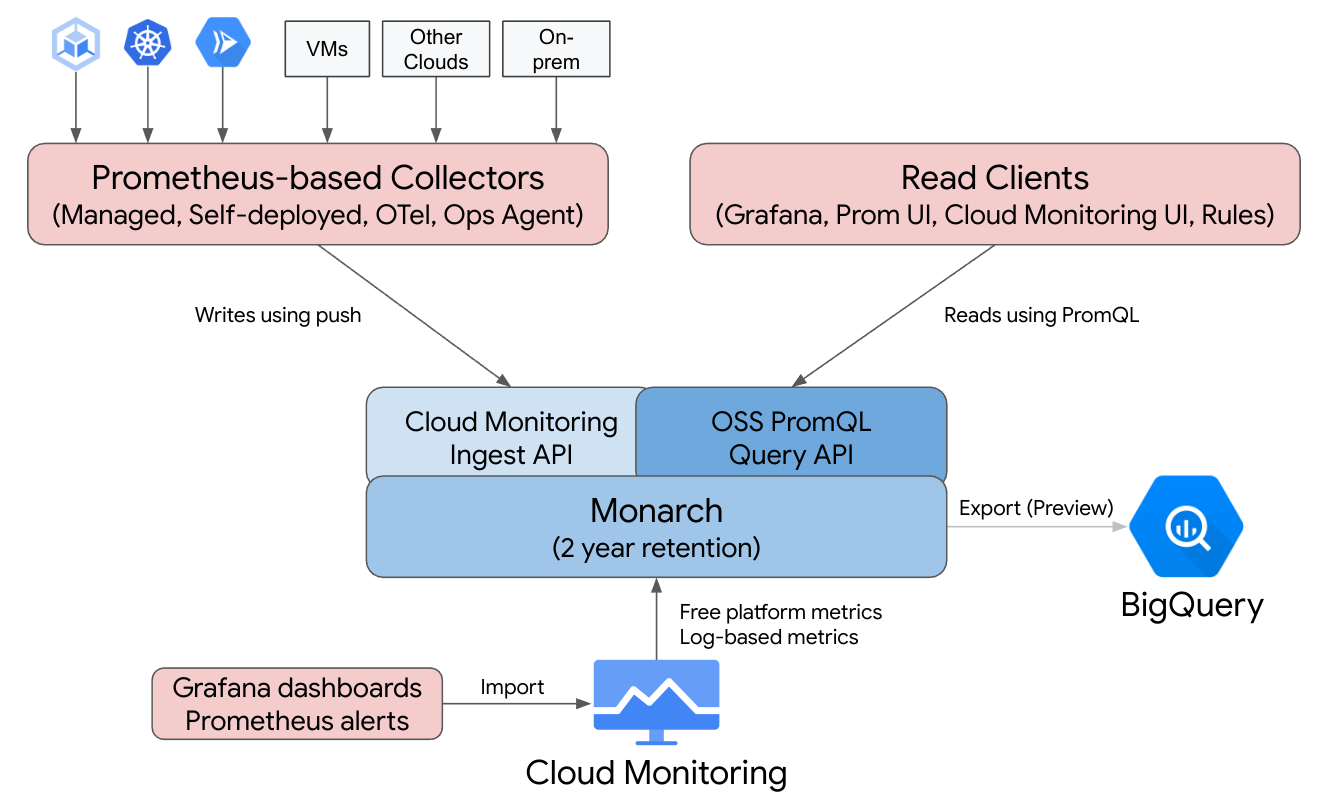
Managed Service pour Prometheus est basé sur Monarch, le même datastore évolutif à l'échelle mondiale que celui utilisé pour la surveillance de Google. Comme Managed Service pour Prometheus utilise le même backend et les mêmes API que Cloud Monitoring, les métriques Cloud Monitoring et les métriques ingérées par Managed Service pour Prometheus peuvent être interrogées à l'aide de PromQL dans Cloud Monitoring, Grafana ou tout autre outil pouvant lire l'API Prometheus
Dans un déploiement Prometheus standard, la collecte de données, l'évaluation des requêtes, l'évaluation des règles et des alertes, et le stockage des données sont tous gérés sur un même serveur Prometheus. Managed Service pour Prometheus répartit les responsabilités de ces différentes fonctions sur plusieurs composants :
- La collecte des données est gérée par des collecteurs gérés, des collecteurs auto-déployés, le collecteur OpenTelemetry ou l'agent Ops, qui effectuent le scraping des exportateurs locaux et transfèrent les données collectées dans Monarch. Ces collecteurs peuvent être utilisés pour Kubernetes, les charges de travail sans serveur et les charges de travail de VM traditionnelles. Ils peuvent être exécutés partout, y compris dans d'autres clouds et des déploiements sur site.
- L'évaluation des requêtes est gérée par Monarch, qui exécute les résultats des requêtes et des unions dans toutes les régions Google Cloudet sur jusqu'à 3 500 projetsGoogle Cloud .
- L'évaluation des règles et des alertes est gérée soit en écrivant des alertes PromQL dans Cloud Monitoring qui s'exécutent entièrement dans le cloud, soit en utilisant des composants d'évaluateur de règles exécutés et configurés localement, qui exécutent des règles et des alertes sur le data store Monarch global et transfèrent les alertes déclenchées vers Prometheus AlertManager.
- Le stockage des données est géré par Monarch, qui stocke toutes les données Prometheus pendant 24 mois sans frais supplémentaires.
Grafana se connecte au data store global Monarch au lieu de se connecter à des serveurs Prometheus individuels. Si les collecteurs de Managed Service pour Prometheus sont configurés dans tous vos déploiements, cette instance Grafana unique vous offre une vue unifiée de toutes vos métriques pour l'ensemble de vos clouds.
Collecte des données
Managed Service pour Prometheus offre quatre modes d'utilisation : collecte des données gérée, collecte des données auto-déployée, collecteur OpenTelemetry ou agent Ops.
Managed Service pour Prometheus propose un opérateur pour la collecte des données gérée dans les environnements Kubernetes. Nous vous recommandons d'utiliser la collecte gérée : Cela élimine la complexité au niveau du déploiement, du scaling, de la segmentation, de la configuration et de la maintenance des serveurs Prometheus. La collecte gérée est compatible avec les environnements Kubernetes GKE et non-GKE.
La collecte des données auto-déployée vous permet de gérer votre installation Prometheus comme vous l'avez toujours fait. La seule différence par rapport à Prometheus en amont est que vous exécutez le binaire de remplacement de Managed Service pour Prometheus au lieu du binaire Prometheus en amont.
Le collecteur OpenTelemetry permet de récupérer des exportateurs Prometheus et d'envoyer des données à Managed Service pour Prometheus. OpenTelemetry est compatible avec une stratégie à agent unique pour tous les signaux, où un collecteur peut être utilisé pour les métriques (y compris les métriques Prometheus), les journaux et les traces dans n'importe quel environnement.
Vous pouvez configurer l'agent Ops sur n'importe quelle instance Compute Engine pour extraire et envoyer des métriques Prometheus au datastore global. L'utilisation d'un agent simplifie considérablement la découverte des VM et élimine le besoin d'installer, de déployer ou de configurer Prometheus dans des environnements de VM.
Si vous disposez d'un service Cloud Run qui écrit des métriques Prometheus ou des métriques OTLP, vous pouvez utiliser un side-car et Managed Service pour Prometheus pour envoyer les métriques à Cloud Monitoring.
- Pour collecter des métriques Prometheus à partir de Cloud Run, utilisez le side-car Prometheus.
- Pour collecter des métriques OTLP à partir de Cloud Run, utilisez le side-car OpenTelemetry.
Vous pouvez exécuter des collecteurs gérés, auto-déployés et OpenTelemetry dans des déploiements sur site et dans n'importe quel cloud. Les collecteurs exécutés en dehors de Google Cloudenvoient des données à Monarch pour le stockage à long terme et les requêtes globales.
Lorsque vous choisissez entre les options de collecte, tenez compte des points suivants :
Collecte gérée :
- L'approche recommandée par Google pour tous les environnements Kubernetes.
- Elle est déployée à l'aide de l'UI GKE, de gcloud CLI, de la CLI
kubectlou de Terraform. - Le mode opératoire de Prometheus (génération des configurations de scraping, scaling et ingestion, règles de champ d'application sur les bonnes données, etc.) est entièrement géré par l'opérateur Kubernetes.
- Le scraping et les règles sont configurés à l'aide de ressources personnalisées légères.
- Convient à ceux qui souhaitent bénéficier d'une expérience plus automatisée et entièrement gérée.
- Migration intuitive à partir des configurations prometheus-operator.
- Compatibilité avec la plupart des cas d'utilisation Prometheus actuels.
- Assistance complète de l'assistance technique Google Cloud .
Collecte auto-déployée :
- Une solution de remplacement prête à l'emploi pour le binaire Prometheus en amont.
- Vous pouvez utiliser le mécanisme de déploiement de votre choix, tel que prometheus-operator ou le déploiement manuel.
- Le scraping est configuré à l'aide des méthodes de votre choix, telles que les annotations ou prometheus-operator.
- Le scaling et la segmentation fonctionnelle sont effectués manuellement.
- Idéal pour une intégration rapide dans des configurations existantes plus complexes. Vous pouvez réutiliser vos configurations existantes et exécuter côte à côte Prometheus en amont et Managed Service pour Prometheus.
- Les règles et les alertes s'exécutent généralement sur des serveurs Prometheus individuels, ce qui peut être préférable pour les déploiements en périphérie, car l'évaluation des règles locales n'entraîne aucun trafic réseau.
- Il est possible que les cas d'utilisation de longue traîne ne soient pas encore compatibles avec la collecte gérée, tels que les agrégations locales pour réduire la cardinalité.
- Assistance limitée de l'assistance technique Google Cloud .
Le collecteur OpenTelemetry présente les caractéristiques suivantes :
- Un collecteur unique capable de collecter des métriques (y compris des métriques Prometheus) à partir de n'importe quel environnement et les envoyer à n'importe quel backend compatible. Peut également servir à collecter les journaux et les traces, et les envoyer à n'importe quel backend compatible, y compris Cloud Logging et Cloud Trace.
- Est déployé dans n'importe quel environnement de calcul ou Kubernetes manuellement ou à l'aide de Terraform. Peut permettre d'envoyer des métriques depuis des environnements sans état, tels que Cloud Run.
- Le scraping est configuré à l'aide des configurations de type Prometheus dans le récepteur Prometheus du collecteur.
- Compatible avec les modèles Push de collecte de métriques.
- Les métadonnées sont injectées dans n'importe quel cloud à l'aide de processeurs de détection de ressources.
- Les règles et les alertes peuvent être exécutées à l'aide d'une règle d'alerte Cloud Monitoring ou de l'évaluateur de règle autonome.
- Idéal pour les workflows et les fonctionnalités de signaux multiples comme les exemples.
- Assistance limitée de l'assistance technique Google Cloud .
Agent Ops :
- Le moyen le plus simple de collecter et d'envoyer des données de métrique Prometheus à partir d'environnements Compute Engine, y compris des distributions Linux et Windows.
- Il est déployé à l'aide de gcloud CLI, de l'UI Compute Engine ou de Terraform.
- Le scraping est configuré grâce à des configurations de type Prometheus dans le récepteur Prometheus de l'agent, qui repose sur OpenTelemetry.
- Les règles et les alertes peuvent être exécutées à l'aide de Cloud Monitoring ou de l'évaluateur de règle autonome.
- Il est fourni avec des agents Logging facultatifs et des métriques de processus.
- Assistance complète de l'assistance technique Google Cloud .
Pour commencer, consultez les pages Premiers pas avec la collecte gérée, Premiers pas avec la collecte auto-déployée, Premiers pas avec le collecteur OpenTelemetry ou Premiers pas avec l'agent Ops.
Si vous utilisez le service géré en dehors de Google Kubernetes Engine ou de Google Cloud, une configuration supplémentaire peut être nécessaire. Consultez la section Exécuter une collecte gérée en dehors de Google Cloud, Exécuter une collecte autodéployée en dehors deGoogle Cloud ou Ajouter des processeurs OpenTelemetry.
Évaluation des requêtes
Managed Service pour Prometheus est compatible avec toute interface utilisateur de requête pouvant appeler l'API de requête Prometheus, y compris Grafana et l'interface utilisateur Cloud Monitoring. Les tableaux de bord Grafana existants continuent de fonctionner lorsque vous passez du service Prometheus local à Managed Service pour Prometheus. Vous pouvez continuer à utiliser PromQL dans les dépôts Open Source populaires et sur les forums communautaires.
Vous pouvez utiliser PromQL pour interroger plus de 6 500 métriques gratuites dans Cloud Monitoring, même sans envoyer de données à Managed Service pour Prometheus. Vous pouvez également utiliser PromQL pour interroger des métriques Kubernetes gratuites, des métriques personnalisées et des métriques basées sur les journaux.
Pour savoir comment configurer Grafana pour interroger des données de Managed Service pour Prometheus, consultez la section Interroger à l'aide de Grafana.
Pour en savoir plus sur l'interrogation de métriques Cloud Monitoring à l'aide de PromQL, consultez la page PromQL dans Cloud Monitoring.
Évaluation des règles et des alertes
Managed Service pour Prometheus fournit à la fois un pipeline d'alerte entièrement basé sur le cloud et un évaluateur de règle autonome, qui évaluent tous deux les règles par rapport à toutes les données Monarch accessibles dans un champ d'application des métriques. En évaluant les règles par rapport à un champ d'application de métriques multiprojets, vous n'avez plus besoin de colocaliser toutes les données qui vous intéressent sur un seul serveur Prometheus ou dans un seul projet Google Cloud . Vous pouvez également définir des autorisations IAM sur des groupes de projets.
Étant donné que toutes les options d'évaluation des règles acceptent le format rule_files Prometheus standard, vous pouvez facilement migrer vers Managed Service pour Prometheus en collant des règles existantes ou en copiant les règles trouvées dans les dépôts Open Source couramment utilisés. Si vous utilisez des collecteurs auto-déployés, vous pouvez continuer à évaluer les règles d'enregistrement en local dans vos collecteurs. Les résultats des règles d'enregistrement et d'alerte sont stockés dans Monarch, comme les données de métrique collectées directement. Vous pouvez également migrer vos règles d'alerte Prometheus vers les règles d'alerte basées sur PromQL dans Cloud Monitoring.
Pour évaluer les alertes avec Cloud Monitoring, consultez la page Alertes PromQL dans Cloud Monitoring.
Pour évaluer des règles avec une collecte gérée, consultez la section Évaluation et alertes des règles gérées.
Pour évaluer des règles avec une collecte auto-déployée, le collecteur OpenTelemetry et l'agent Ops, consultez la section Évaluations et alertes des règles auto-déployées.
Pour en savoir plus sur la réduction de la cardinalité à l'aide de règles d'enregistrement sur les collecteurs auto-déployés, consultez la page Contrôle et attribution des coûts.
Stockage de données
Toutes les données de Managed Service pour Prometheus sont conservées pendant 24 mois, sans frais supplémentaires.
Managed Service pour Prometheus accepte un intervalle de scrape minimal de 5 secondes. Les données sont stockées avec une précision totale pendant une semaine, sous-échantillonnées à des points d'une minute pendant les cinq semaines suivantes, puis sous-échantillonnées en 10 minutes et stockées pendant le reste de la durée de conservation.
Managed Service pour Prometheus n'a pas de limite au nombre de séries temporelles ou de séries temporelles actives.
Pour en savoir plus, consultez la page Quotas et limites de la documentation Cloud Monitoring.
Facturation et quotas
Managed Service pour Prometheus est un produit Google Cloud . Des quotas de facturation et d'utilisation s'appliquent.
Facturation
La facturation du service est principalement basée sur le nombre d'échantillons de métriques ingérés dans l'espace de stockage. Les appels en lecture de l'API entraînent également des frais minimes. Managed Service pour Prometheus ne facture pas le stockage ni la conservation des données de métriques.
- Pour connaître les tarifs actuels, consultez les sections Cloud Monitoring de la page Tarifs de Google Cloud Observability.
- Pour estimer votre facture en fonction du nombre de séries temporelles attendu ou du nombre d'échantillons attendu par seconde, consultez l'onglet "Cloud Operations" du simulateur de coûtGoogle Cloud .
- Pour obtenir des conseils permettant de réduire le montant de votre facture ou de déterminer les sources de coûts élevés, consultez la page Contrôle et attribution des coûts.
- Pour en savoir plus sur la logique du modèle de tarification, consultez Optimiser les coûts pour Google Cloud Managed Service pour Prometheus.
- Pour obtenir des exemples de tarification, consultez Données de métriques facturées par échantillons ingérés.
Quotas
Managed Service pour Prometheus partage les quotas d'ingestion et de lecture avec Cloud Monitoring. Le quota d'ingestion par défaut est de 500 RPS par projet, avec jusqu'à 200 échantillons dans un seul appel, ce qui équivaut à 100 000 échantillons par seconde. Le quota de lectures par défaut est de 100 RPS par champ d'application des métriques.
Vous pouvez augmenter ces quotas pour prendre en charge vos volumes de métriques et de requêtes. Pour en savoir plus sur la gestion des quotas et demander une augmentation de quota, consultez la page Utiliser des quotas.
Conditions d'utilisation et conformité
Le service géré pour Prometheus fait partie de Cloud Monitoring et hérite donc de certains contrats et certifications de Cloud Monitoring, y compris (sans s'y limiter):
- Les conditions d'utilisation deGoogle Cloud
- Contrat de niveau de service d'Operations
- Niveaux de conformité US DISA et FedRAMP
- Compatibilité avec VPC-SC (VPC Service Controls)
Étapes suivantes
- Familiarisez-vous avec la collecte gérée.
- Familiarisez-vous avec la collecte auto-déployée.
- Familiarisez-vous avec le collecteur OpenTelemetry
- Familiarisez-vous avec l'agent Ops.
- Utilisez PromQL dans Cloud Monitoring pour interroger les métriques Prometheus.
- Utilisez Grafana pour interroger les métriques Prometheus.
- Interroger des métriques Cloud Monitoring à l'aide de PromQL.
- Consultez les bonnes pratiques et des schémas d'architecture.