Le service Google Cloud Managed Service for Prometheus facture le nombre d'échantillons ingérés dans Cloud Monitoring et les requêtes de lecture adressées à l'API Monitoring. Le nombre d'échantillons ingérés est le principal facteur de coût.
Ce document explique comment contrôler les coûts associés à l'ingestion de métriques et comment identifier les sources d'ingestion volumineuse.
Pour en savoir plus sur la tarification de Managed Service pour Prometheus, consultez les sections Cloud Monitoring de la page Tarifs de Google Cloud Observability.
Afficher une facture
Pour afficher votre facture Google Cloud , procédez comme suit :
Dans la console Google Cloud , accédez à la page Facturation.
Si vous disposez de plusieurs comptes de facturation, sélectionnez Accéder au compte de facturation associé pour voir le compte de facturation du projet en cours. Pour trouver un autre compte de facturation, sélectionnez Gérer les comptes de facturation, puis choisissez le compte pour lequel vous souhaitez récupérer les rapports d'utilisation.
Dans la section Gestion des coûts du menu de navigation "Facturation", sélectionnez Rapports.
Dans le menu Services, sélectionnez l'option Cloud Monitoring.
Dans le menu Codes SKU, sélectionnez les options suivantes :
- Échantillons Prometheus ingérés
- Surveiller les requêtes API
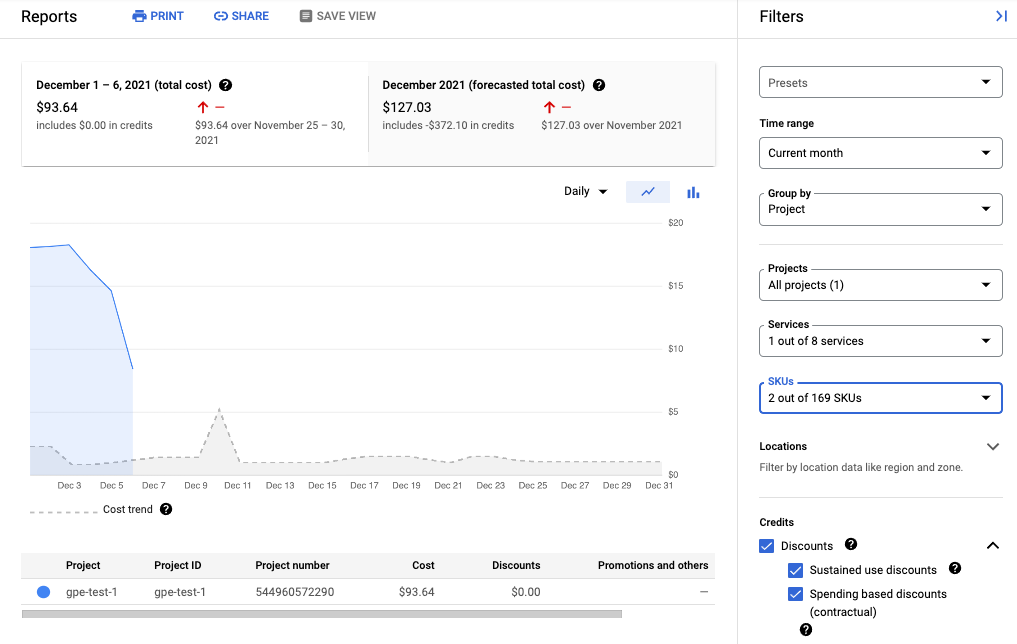
La capture d'écran suivante montre le rapport de facturation de Managed Service pour Prometheus d'un projet :
Réduire vos coûts
Pour réduire les coûts associés à l'utilisation de Managed Service pour Prometheus, vous pouvez effectuer les opérations suivantes :
- Réduisez le nombre de séries temporelles envoyées au service géré en filtrant les données de métriques que vous générez.
- Réduisez le nombre d'échantillons collectés en modifiant l'intervalle de scraping.
- Limitez le nombre d'échantillons de métriques à cardinalité élevée potentiellement mal configurées.
Réduire le nombre de séries temporelles
La documentation Open Source Prometheus recommande rarement de filtrer le volume de métriques, ce qui est raisonnable lorsque les coûts sont limités par les coûts des machines. Toutefois, lorsque vous payez un fournisseur de services gérés à l'unité, l'envoi de données illimitées peut entraîner des factures inutilement élevées.
Les exportateurs inclus dans le projet kube-prometheus, en particulier le service kube-state-metrics, peuvent émettre de nombreuses données de métriques.
Par exemple, le service kube-state-metrics émet des centaines de métriques, dont la plupart peuvent être sans valeur pour vous en tant que consommateur. Un nouveau cluster à trois nœuds utilisant le projet kube-prometheus envoie environ 900 échantillons par seconde à Managed Service pour Prometheus.
Le filtrage de ces métriques superflues peut suffire à maintenir votre facture à un niveau acceptable.
Pour réduire le nombre de métriques, vous pouvez effectuer les opérations suivantes :
- Modifiez vos configurations de scraping pour récupérer moins de cibles.
- Filtrez les métriques collectées, comme décrit ci-dessous :
- Filtrez les métriques exportées lors de l'utilisation d'une collecte gérée.
- Filtrez les métriques exportées lors de l'utilisation d'une collecte auto-déployée.
Si vous utilisez le service kube-state-metrics, vous pouvez ajouter une règle de réécriture de libellé Prometheus avec une action keep. Pour la collecte gérée, cette règle se trouve dans votre définition PodMonitoring ou ClusterPodMonitoring. Pour les collections auto-déployées, cette règle se trouve dans votre configuration scrape Prometheus ou dans votre définition ServiceMonitor (pour l'opérateur prometheus-operator).
Par exemple, l'utilisation du filtre suivant sur un nouveau cluster à trois nœuds réduit le volume d'échantillons d'environ 125 échantillons par seconde :
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
Le filtre précédent utilise une expression régulière pour spécifier les métriques à conserver en fonction de leur nom. Par exemple, les métriques dont le nom commence par kube_daemonset_ sont conservées.
Vous pouvez également spécifier une action drop, qui filtre les métriques correspondant à l'expression régulière.
Il peut arriver qu'un exportateur entier ne soit pas important. Par exemple, le package kube-prometheus installe par défaut les moniteurs de service suivants, dont la plupart sont inutiles dans un environnement géré :
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
Pour réduire le nombre de métriques que vous exportez, vous pouvez supprimer, désactiver ou arrêter les moniteurs de service dont vous n'avez pas besoin. Par exemple, la désactivation du moniteur de service kube-apiserver sur un nouveau cluster à trois nœuds réduit le volume d'échantillons d'environ 200 échantillons par seconde.
Réduire le nombre d'échantillons collectés
Managed Service pour Prometheus est facturé à l'échantillon. Vous pouvez réduire le nombre d'échantillons ingérés en augmentant la durée de la période d'échantillonnage. Exemple :
- Le remplacement d'une période d'échantillonnage de 10 secondes par une période d'échantillonnage de 30 secondes peut réduire le volume d'échantillons de 66 %, sans perte importante d'informations.
- Le remplacement d'une période d'échantillonnage de 10 secondes par une période d'échantillonnage de 60 secondes peut réduire le volume d'échantillons de 83 %.
Pour savoir comment les échantillons sont comptabilisés et l'incidence de la période d'échantillonnage sur le nombre d'échantillons, consultez Données de métriques facturées par échantillons ingérés.
Vous pouvez généralement définir l'intervalle de scraping par tâche ou par cible.
Pour la collecte gérée, vous définissez l'intervalle de scraping dans la ressource PodMonitoring à l'aide du champ interval.
Pour une collecte auto-déployée, vous définissez l'intervalle d'échantillonnage dans vos configurations de scraping, en définissant généralement un champ interval ou scrape_interval.
Configurer l'agrégation locale (collection auto-déployée uniquement)
Si vous configurez le service en utilisant une collection auto-déployée, par exemple avec kube-prometheus, prometheus-operator ou en déployant manuellement l'image, vous pouvez réduire vos exemples envoyés à Managed Service pour Prometheus en agrégeant localement des métriques à cardinalité élevée. Vous pouvez utiliser des règles d'enregistrement pour agréger des libellés tels que instance, et utiliser l'option --export.match ou la variable d'environnement EXTRA_ARGS pour envoyer uniquement des données agrégées à Monarch.
Par exemple, supposons que vous disposiez de trois métriques, high_cardinality_metric_1, high_cardinality_metric_2 et low_cardinality_metric. Vous souhaitez réduire les échantillons envoyés pour high_cardinality_metric_1 et éliminer tous les échantillons envoyés pour high_cardinality_metric_2, tout en conservant toutes les données brutes stockées localement (éventuellement à des fins d'alerte). Votre configuration devrait alors ressembler au tableau suivant :
- Déployez l'image de Managed Service pour Prometheus.
- Configurez vos configurations scrape pour scraper les données brutes dans le serveur local (en utilisant le moins de filtres possible).
Configurez vos règles d'enregistrement pour exécuter des agrégations locales sur
high_cardinality_metric_1ethigh_cardinality_metric_2, éventuellement en agrégeant le libelléinstanceou un nombre illimité de libellés de métriques, en fonction de ce qui fournit la meilleure réduction du nombre de séries temporelles inutiles. Vous pouvez exécuter une règle semblable à celle-ci, qui supprime le libelléinstanceet additionne les séries temporelles obtenues par rapport aux libellés restants :record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
Pour plus d'options d'agrégation, consultez la section Opérateurs d'agrégation dans la documentation Prometheus.
Déployez l'image de Managed Service pour Prometheus avec l'option de filtre suivante, qui empêche l'envoi des données brutes des métriques répertoriées à Monarch :
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'Cet exemple d'option
export.matchutilise des sélecteurs séparés par des virgules avec l'opérateur!=pour filtrer les données brutes indésirables. Si vous ajoutez des règles d'enregistrement supplémentaires pour agréger d'autres métriques à cardinalité élevée, vous devez également ajouter un nouveau sélecteur__name__au filtre afin que les données brutes soient supprimées. En utilisant un seul indicateur contenant plusieurs sélecteurs avec l'opérateur!=pour filtrer les données indésirables, vous ne devez modifier le filtre que lorsque vous créez une agrégation au lieu de chaque modification ou ajout d'une configuration scrape.Certaines méthodes de déploiement, telles que Prometheus-operator, peuvent vous obliger à omettre les guillemets simples autour des crochets.
Ce workflow peut entraîner des coûts opérationnels lors de la création et de la gestion des règles d'enregistrement et des options export.match, mais il est probable que vous puissiez réduire un volume important en vous concentrant uniquement sur les métriques à cardinalité exceptionnellement élevée. Pour savoir quelles métriques peuvent bénéficier le plus d'une pré-agrégation locale, consultez la section Identifier les métriques volumineuses.
Ne mettez pas en œuvre la fédération lorsque vous utilisez Managed Service pour Prometheus. Ce workflow rend obsolète l'utilisation de serveurs de fédération, car un seul serveur Prometheus autodéployé peut effectuer toutes les agrégations au niveau du cluster dont vous avez besoin. La fédération peut provoquer des effets inattendus, tels que des métriques de type "inconnu" et un doublement du volume d'ingestion.
Limiter les échantillons à partir des métriques à cardinalité élevée (collection auto-déployée uniquement)
Vous pouvez créer des métriques à cardinalité extrêmement élevée en ajoutant des libellés avec un grand nombre de valeurs potentielles, comme un ID utilisateur ou une adresse IP. Ces métriques peuvent générer un très grand nombre d'échantillons. L'utilisation de libellés comportant un grand nombre de valeurs est généralement considérée comme une configuration incorrecte. Vous pouvez éviter les métriques à cardinalité élevée dans vos collecteurs auto-déployés en définissant une valeur sample_limit dans vos configurations de scraping.
Si vous utilisez cette limite, nous vous recommandons de la définir sur une valeur très élevée afin qu'elle ne détecte que les métriques mal configurées. Tous les échantillons dépassant la limite sont supprimés. Il peut s'avérer très difficile de diagnostiquer les problèmes causés par le dépassement de la limite.
L'utilisation d'une limite d'échantillons n'est pas un bon moyen de gérer l'ingestion des échantillons, mais elle peut vous protéger contre une erreur de configuration accidentelle. Pour en savoir plus, consultez la page Utiliser sample_limit pour éviter la surcharge.
Identifier et attribuer les coûts
Vous pouvez utiliser Cloud Monitoring pour identifier les métriques Prometheus qui écrivent le plus grand nombre d'échantillons. Ces métriques représentent la part la plus importante des coûts. Après avoir identifié les métriques les plus coûteuses, vous pouvez modifier vos configurations de scraping pour filtrer ces métriques de manière appropriée.
La page Gestion des métriques de Cloud Monitoring fournit des informations qui peuvent vous aider à contrôler les sommes que vous consacrez aux métriques facturables, sans affecter l'observabilité. La page Gestion des métriques fournit les informations suivantes :
- Les volumes d'ingestion pour la facturation à base d'octets et celle à base d'exemples, englobant les différents domaines de métriques et des métriques individuelles
- Les données sur les libellés et la cardinalité des métriques
- Nombre de lectures pour chaque métrique.
- L'utilisation de métriques dans les règles d'alerte et les tableaux de bord personnalisés
- Les taux d'erreurs d'écriture de métriques
Vous pouvez également utiliser la page Gestion des métriques pour exclure les métriques inutiles, ce qui élimine le coût de leur ingestion.
Procédez comme suit pour afficher la page Gestion des métriques :
-
Dans la console Google Cloud , accédez à la page Gestion des métriques :
Accédez à la page Gestion des métriques
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Monitoring.
- Dans la barre d'outils, sélectionnez votre période. Par défaut, la page Gestion des métriques affiche des informations sur les métriques collectées au cours du jour précédent.
Pour en savoir plus sur la page Gestion des métriques, consultez la section Afficher et gérer l'utilisation des métriques.
Les sections suivantes décrivent comment analyser le nombre d'échantillons que vous envoyez à Managed Service pour Prometheus et attribuer un volume élevé à des métriques spécifiques, à des espaces de noms Kubernetes et à des régions Google Cloud .
Identifier les métriques à volume élevé
Pour identifier les métriques Prometheus avec les volumes d'ingestion les plus importants, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page Gestion des métriques :
Accédez à la page Gestion des métriques
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Monitoring.
- Dans le tableau de données Échantillons facturables ingérés, cliquez sur Afficher les graphiques.
- Recherchez le chart Ingestion de volumes d'espaces de noms, puis cliquez sur more_vert Autres options des graphiques.
- Sélectionnez l'option de chart Afficher dans l'explorateur de métriques.
- Dans le volet Compilateur de l'explorateur de métriques, modifiez les champs comme suit :
- Dans Métrique, vérifiez que la ressource et la métrique suivantes sont sélectionnées :
Metric Ingestion AttributionetSamples written by attribution id. - Dans le champ Agrégation, sélectionnez
sum. - Dans le champ par, sélectionnez les libellés suivants :
attribution_dimensionmetric_type
- Dans le champ Filtre, spécifiez
attribution_dimension = namespace. Vous devez effectuer cette opération après avoir défini une agrégation selon le libelléattribution_dimension.
Le graphique obtenu indique les volumes d'ingestion pour chaque type de métrique.
- Dans Métrique, vérifiez que la ressource et la métrique suivantes sont sélectionnées :
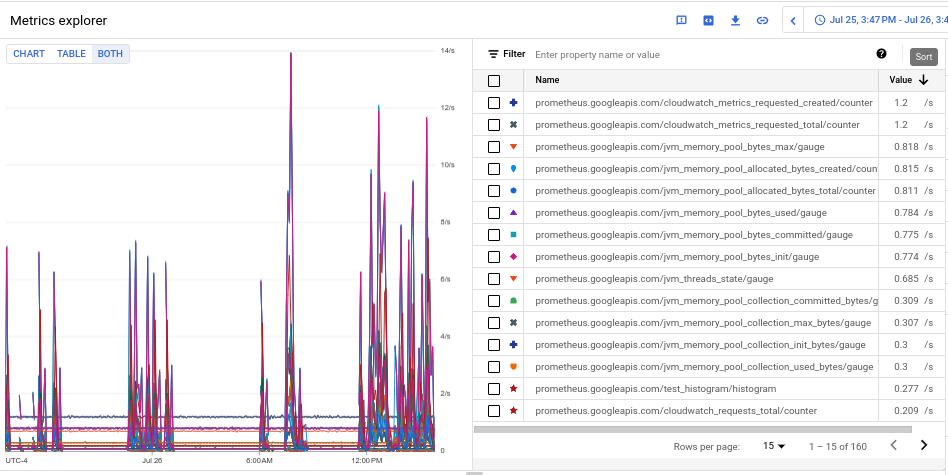
- Pour afficher le volume d'ingestion de chacune des métriques, sélectionnez Tout dans le bouton Graphique Table Tout. La table affiche le volume ingéré pour chaque métrique dans la colonne Valeur.
- Cliquez deux fois sur l'en-tête de colonne Valeur pour trier les métriques par ordre décroissant de volume d'ingestion.
Le graphique obtenu montre premières métriques par volume, classées par moyenne. Il ressemble à la capture d'écran suivante :
Identifier les espaces de noms à volume élevé
Pour attribuer un volume d'ingestion à des espaces de noms Kubernetes spécifiques, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page Gestion des métriques :
Accédez à la page Gestion des métriques
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Monitoring.
- Dans le tableau de données Échantillons facturables ingérés, cliquez sur Afficher les graphiques.
- Recherchez le chart Ingestion de volumes d'espaces de noms, puis cliquez sur more_vert Autres options des graphiques.
- Sélectionnez l'option de chart Afficher dans l'explorateur de métriques.
- Dans le volet Compilateur de l'explorateur de métriques, modifiez les champs comme suit :
- Dans Métrique, vérifiez que la ressource et la métrique suivantes sont sélectionnées :
Metric Ingestion AttributionetSamples written by attribution id. - Configurez les autres paramètres de requête selon vos besoins :
- Pour mettre en corrélation le volume d'ingestion global avec les espaces de noms :
- Dans le champ Agrégation, sélectionnez
sum. - Dans le champ par, sélectionnez les libellés suivants :
attribution_dimensionattribution_id
- Dans le champ Filtre, spécifiez
attribution_dimension = namespace.
- Dans le champ Agrégation, sélectionnez
- Pour mettre en corrélation le volume d'ingestion de métriques individuelles avec des espaces de noms :
- Dans le champ Agrégation, sélectionnez
sum. - Dans le champ par, sélectionnez les libellés suivants :
attribution_dimensionattribution_idmetric_type
- Dans le champ Filtre, spécifiez
attribution_dimension = namespace.
- Dans le champ Agrégation, sélectionnez
- Pour identifier les espaces de noms responsables d'une métrique à volume élevé spécifique, procédez comme suit :
- Identifiez le type de métrique à volume élevé à l'aide de l'un des autres exemples permettant de les identifier. Le type de métrique est la chaîne de la vue Tableau qui commence par
prometheus.googleapis.com/. Pour en savoir plus, consultez la section Identifier les métriques volumineuses. - Limitez les données du graphique au type de métrique identifié, en ajoutant un filtre pour le type de métrique dans le champ Filtre. Par exemple :
metric_type= prometheus.googleapis.com/container_tasks_state/gauge - Dans le champ Agrégation, sélectionnez
sum. - Dans le champ par, sélectionnez les libellés suivants :
attribution_dimensionattribution_id
- Dans le champ Filtre, spécifiez
attribution_dimension = namespace.
- Identifiez le type de métrique à volume élevé à l'aide de l'un des autres exemples permettant de les identifier. Le type de métrique est la chaîne de la vue Tableau qui commence par
- Pour afficher l'ingestion par région Google Cloud , ajoutez le libellé
locationau champ par. - Pour afficher l'ingestion par projet Google Cloud , ajoutez le libellé
resource_containerau champ par.
- Pour mettre en corrélation le volume d'ingestion global avec les espaces de noms :
- Dans Métrique, vérifiez que la ressource et la métrique suivantes sont sélectionnées :