Ce document explique comment configurer Google Cloud Managed Service pour Prometheus avec la collecte gérée. La configuration est un exemple minimal d'ingestion fonctionnelle utilisant un déploiement Prometheus qui surveille un exemple d'application et stocke les métriques collectées dans Monarch.
Ce document vous explique comment :
- Configurer votre environnement et vos outils de ligne de commande
- Configurer la collecte gérée pour votre cluster.
- Configurer une ressource pour le scraping et l'ingestion de métriques cibles.
- Migrer les ressources personnalisées prometheus-operator existantes.
Nous vous recommandons d'utiliser la collecte gérée qui réduit la complexité du déploiement, du scaling, de la segmentation, de la configuration et de la maintenance des collecteurs. La collecte gérée est compatible avec GKE et tous les autres environnements Kubernetes.
La collection gérée exécute les collecteurs basés sur Prometheus en tant que Daemonset et assure l'évolutivité en ne scrapant que les cibles sur des nœuds colocalisés. Vous configurez les collecteurs avec des ressources personnalisées légères afin de scraper les exportateurs à l'aide de la collection pull, puis les collecteurs transfèrent les données ainsi récupérées vers le datastore central Monarch. Google Cloud n'accède jamais directement à votre cluster pour extraire ou récupérer des données de métriques. vos collecteurs envoient des données àGoogle Cloud. Pour en savoir plus sur la collecte de données gérée et auto-déployée, consultez les pages Collecte des données avec Managed Service pour Prometheus et Ingestion et interrogation avec une collection gérée et auto-déployée.
Avant de commencer
Cette section décrit la configuration nécessaire pour les tâches décrites dans ce document.
Configurer des projets et des outils
Pour utiliser Google Cloud Managed Service pour Prometheus, vous avez besoin des ressources suivantes :
Un projet Google Cloud avec l'API Cloud Monitoring activée.
Si vous n'avez pas de projet Google Cloud , procédez comme suit :
Dans la console Google Cloud , accédez à Nouveau projet :
Dans le champ Nom du projet, saisissez un nom pour votre projet, puis cliquez sur Créer.
Accéder à la page Facturation :
Sélectionnez le projet que vous venez de créer s'il n'est pas déjà sélectionné en haut de la page.
Vous êtes invité à choisir un profil de paiement existant ou à en créer un.
L'API Monitoring est activée par défaut pour les nouveaux projets.
Si vous disposez déjà d'un projet Google Cloud , assurez-vous que l'API Monitoring est activée :
Accédez à la page API et services :
Sélectionnez votre projet.
Cliquez sur Enable APIs and Services (Activer les API et les services).
Recherchez "Monitoring".
Dans les résultats de recherche, cliquez sur "API Cloud Monitoring".
Si l'option "API activée" ne s'affiche pas, cliquez sur le bouton Activer.
Un cluster Kubernetes. Si vous ne disposez pas de cluster Kubernetes, suivez les instructions du guide de démarrage rapide pour GKE.
Vous avez également besoin des outils de ligne de commande suivants :
gcloudkubectl
Les outils gcloud et kubectl font partie de Google Cloud CLI. Pour en savoir plus sur leur installation, consultez la page Gérer les composants de Google Cloud CLI. Pour afficher les composants de la CLI gcloud que vous avez installés, exécutez la commande suivante :
gcloud components list
Configurer votre environnement
Pour éviter de saisir à plusieurs reprises l'ID de votre projet ou le nom de votre cluster, effectuez la configuration suivante :
Configurez les outils de ligne de commande comme suit :
Configurez la gcloud CLI pour faire référence à l'ID de votre projetGoogle Cloud :
gcloud config set project PROJECT_ID
Configurez la CLI
kubectlpour utiliser votre cluster :kubectl config set-cluster CLUSTER_NAME
Pour en savoir plus sur ces outils, consultez les articles suivants :
Configurer un espace de noms
Créez l'espace de noms Kubernetes NAMESPACE_NAME pour les ressources que vous créez dans le cadre de l'exemple d'application :
kubectl create ns NAMESPACE_NAME
Configurer la collecte gérée
Vous pouvez utiliser la collecte gérée sur les clusters Kubernetes GKE et non-GKE.
Une fois la collecte gérée activée, les composants intégrés au cluster s'exécutent, mais aucune métrique n'est encore générée. Les ressources PodMonitoring ou ClusterPodMonitoring sont nécessaires à ces composants afin de scraper correctement les points de terminaison des métriques. Vous devez déployer ces ressources avec des points de terminaison de métriques valides, ou activer l'un des packages de métriques gérés intégrés à GKE, comme par exemple Kube State Metrics. Pour en savoir plus, consultez la section Problèmes côté ingestion.
L'activation de la collecte gérée installe les composants suivants dans votre cluster :
- Le déploiement
gmp-operator, qui déploie l'opérateur Kubernetes de Managed Service pour Prometheus. - Le déploiement
rule-evaluator, qui permet de configurer et d'exécuter des règles d'alerte et d'enregistrement. - Le DaemonSet
collector, qui effectue un scaling horizontal de la collecte en récupérant les métriques uniquement à partir des pods exécutés sur le même nœud que chaque collecteur. - Le StatefulSet
alertmanagerconfiguré pour envoyer des alertes déclenchées vers vos canaux de notification préférés.
Pour obtenir une documentation de référence sur l'opérateur du service géré pour Prometheus, consultez la page des fichiers manifestes.
Activer la collecte gérée : GKE
La collecte gérée est activée par défaut pour les éléments suivants :
Clusters GKE Autopilot exécutant GKE version 1.25 ou ultérieure.
Clusters GKE Standard exécutant GKE version 1.27 ou ultérieure. Vous pouvez remplacer cette valeur par défaut lors de la création du cluster. Consultez la section Désactiver la collecte gérée.
Si vous exécutez dans un environnement GKE qui n'active pas la collecte gérée par défaut, vous pouvez activer la collecte gérée manuellement.
La collecte gérée sur GKE est automatiquement mise à niveau lorsque de nouvelles versions des composants au sein du cluster sont disponibles.
La collecte gérée sur GKE utilise des autorisations accordées au compte de service Compute Engine par défaut. Si vous disposez d'une règle qui modifie les autorisations standards sur le compte de service de nœud par défaut, vous devrez peut-être ajouter le rôle Monitoring Metric Writer pour continuer.
Activer manuellement la collecte gérée
Si vous exécutez dans un environnement GKE qui n'active pas la collecte gérée par défaut, vous pouvez activer la collecte gérée en procédant comme suit :
- Tableau de bord Activation groupée de clusters Prometheus géré dans Cloud Monitoring.
- La page Kubernetes Engine dans la console Google Cloud .
- Google Cloud CLI Pour utiliser gcloud CLI, vous devez exécuter GKE version 1.21.4-gke.300 ou ultérieure.
Terraform pour Google Kubernetes Engine Pour utiliser Terraform afin d'activer le service géré pour Prometheus, vous devez exécuter GKE version 1.21.4-gke.300 ou ultérieure.
Tableau de bord "Activation groupée de clusters Prometheus géré"
Vous pouvez effectuer les opérations suivantes à l'aide du tableau de bord Activation groupée de clusters Prometheus géré dans Cloud Monitoring.
- Déterminez si Managed Service for Prometheus est activé sur vos clusters et si vous utilisez une collection gérée ou auto-déployée.
- Activez la collecte gérée sur les clusters dans votre projet.
- Affichez d'autres informations sur vos clusters.
Pour afficher le tableau de bord Activation groupée de clusters Prometheus géré :
-
Dans la console Google Cloud , accédez à la page
 Tableaux de bord :
Tableaux de bord :
Accéder à la page Tableaux de bord
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Monitoring.
Utilisez la barre de filtres pour rechercher l'entrée Activation groupée de clusters Prometheus géré, puis sélectionnez-la.
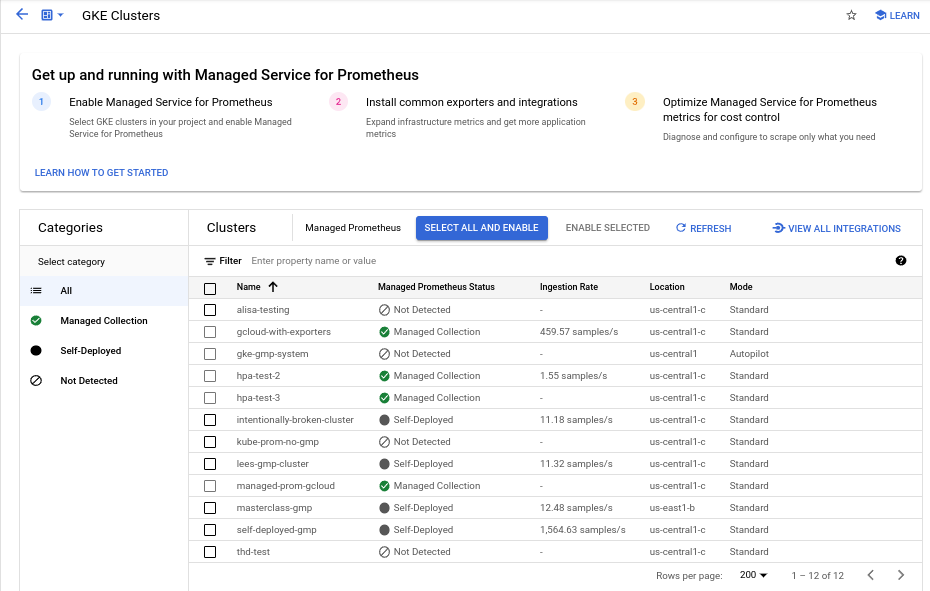
Pour activer la collecte gérée sur un ou plusieurs clusters GKE à l'aide du tableau de bord Activation groupée de clusters Prometheus géré, procédez comme suit :
Cochez la case associée à chaque cluster GKE sur lequel vous souhaitez activer la collecte gérée.
Sélectionnez Activer la sélection.
Interface utilisateur de Kubernetes Engine
Vous pouvez effectuer les opérations suivantes à l'aide de la console Google Cloud :
- Activer la collecte gérée sur un cluster GKE existant
- Créer un cluster GKE avec la collecte gérée activée
Pour mettre à jour un cluster existant, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page Clusters Kubernetes :
Accéder à la page Clusters Kubernetes
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Kubernetes Engine.
Cliquez sur le nom du cluster.
Dans la liste Fonctionnalités, recherchez l'option Service géré pour Prometheus. Si elle est désactivée, cliquez sur edit Modifier, puis sélectionnez Activer le service géré pour Prometheus.
Cliquez sur Enregistrer les modifications.
Pour créer un cluster avec la collecte gérée activée, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page Clusters Kubernetes :
Accéder à la page Clusters Kubernetes
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Kubernetes Engine.
Cliquez sur Créer.
Cliquez sur Configurer pour l'option Standard.
Dans le panneau de navigation, cliquez sur Fonctionnalités.
Dans la section Opérations, sélectionnez Activer le service géré pour Prometheus.
Cliquez sur Enregistrer.
CLI gcloud
Vous pouvez effectuer les opérations suivantes en utilisant la CLI gcloud :
- Activer la collecte gérée sur un cluster GKE existant
- Créer un cluster GKE avec la collecte gérée activée
L'exécution de ces commandes peut prendre jusqu'à cinq minutes.
Tout d'abord, définissez votre projet :
gcloud config set project PROJECT_ID
Pour mettre à jour un cluster existant, exécutez l'une des commandes update suivantes, selon que votre cluster est zonal ou régional :
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --region REGION
Pour créer un cluster avec la collecte gérée activée, exécutez la commande suivante :
gcloud container clusters create CLUSTER_NAME --zone ZONE --enable-managed-prometheus
GKE Autopilot
La collecte gérée est activée par défaut dans les clusters GKE Autopilot exécutant GKE version 1.25 ou ultérieure. Vous ne pouvez pas désactiver la collecte gérée.
Si votre cluster ne parvient pas à activer automatiquement la collecte gérée lors de la mise à niveau vers la version 1.25, vous pouvez l'activer manuellement en exécutant la commande "update" dans la section de la gcloud CLI.
Terraform
Pour obtenir des instructions sur la configuration de la collecte gérée à l'aide de Terraform, consultez le registre Terraform pour google_container_cluster.
Pour obtenir des informations générales sur l'utilisation de Google Cloud avec Terraform, consultez Terraform avec Google Cloud.
Désactiver la collecte gérée
Si vous souhaitez désactiver la collecte gérée sur vos clusters, vous pouvez utiliser l'une des méthodes suivantes :
Interface utilisateur de Kubernetes Engine
Vous pouvez effectuer les opérations suivantes à l'aide de la console Google Cloud :
- Désactiver la collecte gérée sur un cluster GKE existant
- Ignorer l'activation automatique de la collecte gérée lors de la création d'un cluster GKE Standard exécutant GKE version 1.27 ou ultérieure.
Pour mettre à jour un cluster existant, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page Clusters Kubernetes :
Accéder à la page Clusters Kubernetes
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Kubernetes Engine.
Cliquez sur le nom du cluster.
Dans la section Fonctionnalités, recherchez l'option Service géré pour Prometheus. Cliquez sur edit Modifier et décochez Activer Managed Service pour Prometheus.
Cliquez sur Enregistrer les modifications.
Pour ignorer l'activation automatique de la collecte gérée lors de la création d'un cluster GKE Standard (version 1.27 ou ultérieure), procédez comme suit :
-
Dans la console Google Cloud , accédez à la page Clusters Kubernetes :
Accéder à la page Clusters Kubernetes
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Kubernetes Engine.
Cliquez sur Créer.
Cliquez sur Configurer pour l'option Standard.
Dans le panneau de navigation, cliquez sur Fonctionnalités.
Dans la section Opérations, effacez Activer le service géré pour Prometheus.
Cliquez sur Enregistrer.
CLI gcloud
Vous pouvez effectuer les opérations suivantes en utilisant la CLI gcloud :
- Désactiver la collecte gérée sur un cluster GKE existant
- Ignorer l'activation automatique de la collecte gérée lors de la création d'un cluster GKE Standard exécutant GKE version 1.27 ou ultérieure.
L'exécution de ces commandes peut prendre jusqu'à cinq minutes.
Tout d'abord, définissez votre projet :
gcloud config set project PROJECT_ID
Pour désactiver la collecte gérée sur un cluster existant, exécutez l'une des commandes update suivantes, selon que votre cluster est zonal ou régional :
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --region REGION
Pour ignorer l'activation automatique de la collecte gérée lors de la création d'un cluster GKE Standard (version 1.27 ou ultérieure), exécutez la commande suivante :
gcloud container clusters create CLUSTER_NAME --zone ZONE --no-enable-managed-prometheus
GKE Autopilot
Vous ne pouvez pas désactiver la collecte gérée dans les clusters GKE Autopilot exécutant GKE version 1.25 ou ultérieure.
Terraform
Pour désactiver la collecte gérée, définissez l'attribut enabled du bloc de configuration managed_prometheus sur false. Pour en savoir plus sur ce bloc de configuration, consultez le registre Terraform pour google_container_cluster.
Pour obtenir des informations générales sur l'utilisation de Google Cloud avec Terraform, consultez Terraform avec Google Cloud.
Activer la collecte gérée : Kubernetes hors GKE
Si vous exécutez dans un environnement autre que GKE, vous pouvez activer la collecte gérée à l'aide des éléments suivants :
- La CLI
kubectl. Déploiements VMware ou bare metal sur site exécutant la version 1.12 ou ultérieure.
CLI kubectl
Pour installer des collecteurs gérés lorsque vous utilisez un cluster Kubernetes hors GKE, exécutez les commandes suivantes pour installer les fichiers manifestes d'installation et d'opérateur :
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/setup.yaml kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
Sur site
Pour en savoir plus sur la configuration de la collecte gérée pour les clusters sur site, consultez la documentation concernant votre distribution :
Déployer l'exemple d'application
L'exemple d'application émet la métrique de compteur example_requests_total et la métrique d'histogramme example_random_numbers (entre autres) sur son port metrics. Le fichier manifeste de l'application définit trois instances répliquées.
Pour déployer l'exemple d'application, exécutez la commande suivante :
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Configurer une ressource PodMonitoring
Pour ingérer les données de métriques émises par l'exemple d'application, Managed Service pour Prometheus utilise le scraping cible. Le scraping et l'ingestion des métriques cibles sont configurées à l'aide des ressources personnalisées Kubernetes. Le service géré utilise des ressources personnalisées PodMonitoring.
Une RS PodMonitoring ne scrape les cibles que dans l'espace de noms dans lequel la RS est déployée.
Pour scraper des cibles dans plusieurs espaces de noms, déployez la même RS PodMonitoring dans chaque espace de noms. Vous pouvez vérifier que la ressource PodMonitoring est installée dans l'espace de noms prévu en exécutant la commande kubectl get podmonitoring -A.
Pour obtenir une documentation de référence sur toutes les ressources personnalisées Managed Service pour Prometheus, consultez la documentation prometheus-engine/doc/api reference.
Le fichier manifeste suivant définit une ressource PodMonitoring, prom-example, dans l'espace de noms NAMESPACE_NAME. La ressource utilise un sélecteur de libellés Kubernetes pour rechercher tous les pods de l'espace de noms portant le libellé app.kubernetes.io/name avec la valeur prom-example.
Les pods correspondants sont récupérés sur un port nommé metrics, toutes les 30 secondes, sur le chemin HTTP /metrics.
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app.kubernetes.io/name: prom-example
endpoints:
- port: metrics
interval: 30s
Pour appliquer cette ressource, exécutez la commande suivante :
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/pod-monitoring.yaml
Votre collecteur géré scrape désormais les pods correspondants. Vous pouvez afficher l'état de votre cible de scraping en activant la fonctionnalité d'état cible.
Pour configurer la collecte horizontale qui s'applique à une plage de pods sur tous les espaces de noms, utilisez la ressource ClusterPodMonitoring. La ressource ClusterPodMonitoring fournit la même interface que la ressource PodMonitoring, mais ne limite pas les pods détectés à un espace de noms donné.
Si vous utilisez GKE, vous pouvez procéder comme suit :
- Pour interroger les métriques ingérées par l'exemple d'application à l'aide de PromQL dans Cloud Monitoring, consultez la page Interroger à l'aide de Cloud Monitoring.
- Pour interroger les métriques ingérées par l'exemple d'application à l'aide de Grafana, consultez la section Interroger à l'aide de Grafana ou de n'importe quel utilisateur de l'API Prometheus.
- Pour en savoir plus sur le filtrage des métriques exportées et l'adaptation de vos ressources prom-operator, consultez la section Autres sujets sur la collecte gérée.
Si vous procédez à l'exécution en dehors de GKE, vous devez créer un compte de service et l'autoriser à écrire vos données de métrique, comme décrit dans la section suivante.
Fournir des identifiants de manière explicite
Lors de l'exécution sur GKE, le serveur Prometheus de collecte récupère automatiquement les identifiants de l'environnement en fonction du compte de service du nœud. Dans les clusters Kubernetes non GKE, les identifiants doivent être explicitement fournis via la ressource OperatorConfig dans l'espace de noms gmp-public.
Définissez le contexte de votre projet cible :
gcloud config set project PROJECT_ID
Créez un compte de service :
gcloud iam service-accounts create gmp-test-sa
Accordez les autorisations requises au compte de service :
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Créez et téléchargez une clé pour le compte de service :
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Ajoutez le fichier de clé en tant que secret à votre cluster non-GKE :
kubectl -n gmp-public create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Ouvrez la ressource OperatorConfig pour la modifier :
kubectl -n gmp-public edit operatorconfig config
Ajoutez le texte affiché en gras à la ressource :
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.jsonrulespour que l'évaluation des règles gérées fonctionne.Enregistrez le fichier et fermez l'éditeur. Une fois la modification appliquée, les pods sont recréés et commencent à s'authentifier auprès du backend de métrique avec le compte de service donné.
Autres sujets sur la collecte gérée
Cette page explique comment effectuer les opérations suivantes :
- Activer la fonctionnalité d'état cible pour faciliter le débogage.
- Configurer le scraping cible à l'aide de Terraform.
- Filtrer les données que vous exportez vers le service géré.
- Récupérer les métriques Kubelet et cAdvisor.
- Convertir vos ressources prom-operator existantes pour les utiliser avec le service géré.
- Exécuter une collecte gérée en dehors de GKE.
Activer la fonctionnalité d'état cible
Managed Service pour Prometheus vous permet de vérifier si vos cibles sont correctement découvertes et scrapées par les collecteurs. Ce rapport sur l'état des cibles est un outil de débogage des problèmes ponctuels. Nous vous recommandons vivement de n'activer cette fonctionnalité que pour examiner les problèmes immédiats. Si vous laissez le reporting de l'état cible activé dans les grands clusters, l'opérateur risque de manquer de mémoire et de se retrouver dans une boucle de plantage.
Vous pouvez vérifier l'état de vos cibles dans vos ressources PodMonitoring ou ClusterPodMonitoring en définissant la valeur
features.targetStatus.enableddans la ressource OperatorConfig surtrue, comme indiqué ci-dessous :apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: targetStatus: enabled: trueAprès quelques secondes, le champ
Status.Endpoint Statusess'affiche sur chaque ressource PodMonitoring ou ClusterPodMonitoring valide, lorsqu'il est configuré.Si vous disposez d'une ressource PodMonitoring nommée
prom-exampledans l'espace de nomsNAMESPACE_NAME, vous pouvez vérifier l'état en exécutant la commande suivante :kubectl -n NAMESPACE_NAME describe podmonitorings/prom-example
La sortie ressemble à ceci :
API Version: monitoring.googleapis.com/v1 Kind: PodMonitoring ... Status: Conditions: ... Status: True Type: ConfigurationCreateSuccess Endpoint Statuses: Active Targets: 3 Collectors Fraction: 1 Last Update Time: 2023-08-02T12:24:26Z Name: PodMonitoring/custom/prom-example/metrics Sample Groups: Count: 3 Sample Targets: Health: up Labels: Cluster: CLUSTER_NAME Container: prom-example Instance: prom-example-589ddf7f7f-hcnpt:metrics Job: prom-example Location: REGION Namespace: NAMESPACE_NAME Pod: prom-example-589ddf7f7f-hcnpt project_id: PROJECT_ID Last Scrape Duration Seconds: 0.020206416 Health: up Labels: ... Last Scrape Duration Seconds: 0.054189485 Health: up Labels: ... Last Scrape Duration Seconds: 0.006224887Le résultat inclut les champs d'état suivants :
Status.Conditions.Statusest défini lorsque Managed Service pour Prometheus accuse réception et traite PodPodMonitoring.Status.Endpoint Statuses.Active Targetsindique le nombre de cibles de scrape que Managed Service pour Prometheus compte sur tous les collecteurs de cette ressource PodMonitoring. Dans l'exemple d'application, le déploiementprom-examplepossède trois instances répliquées avec une seule cible de métrique. La valeur est donc3. En cas de cibles non opérationnelles, le champStatus.Endpoint Statuses.Unhealthy Targetss'affiche.Status.Endpoint Statuses.Collectors Fractionaffiche la valeur1(100%) si tous les collecteurs gérés sont accessibles à Managed Service pour Prometheus.Status.Endpoint Statuses.Last Update Timeindique la date et l'heure de la dernière mise à jour. Lorsque l'heure de la dernière mise à jour est beaucoup plus longue que l'intervalle de scraping souhaité, la différence peut indiquer des problèmes liés à votre cible ou à votre cluster.- Le champ
Status.Endpoint Statuses.Sample Groupsprésente des exemples de cibles regroupées par étiquettes cibles courantes injectées par le collecteur. Cette valeur est utile pour déboguer les situations dans lesquelles vos cibles ne sont pas découvertes. Si toutes les cibles sont opérationnelles et collectées, la valeur attendue du champHealthestupet la valeur du champLast Scrape Duration Secondsest la durée habituelle d'une cible type.
Pour en savoir plus sur ces champs, consultez le document de l'API Managed Service pour Prometheus.
L'un des éléments suivants peut indiquer un problème avec votre configuration :
- Le champ
Status.Endpoint Statusesest absent de votre ressource PodMonitoring. - La valeur du champ
Last Scrape Duration Secondsest trop ancienne. - Trop peu de cibles sont visibles.
- La valeur du champ
Healthindique que la cible estdown.
Pour en savoir plus sur le débogage des problèmes de découverte des cibles, consultez la section Problèmes côté ingestion dans la documentation de dépannage.
Configurer un point de terminaison de récupération autorisé
Si votre cible de scraping nécessite une autorisation, vous pouvez configurer le collecteur pour qu'il utilise le type d'autorisation approprié et fournisse les secrets pertinents.
Google Cloud Managed Service pour Prometheus est compatible avec les types d'autorisations suivants :
mTLS
La mTLS est généralement configurée dans des environnements zéro confiance, tels que le maillage de services Istio ou Cloud Service Mesh.
Pour activer le scraping des points de terminaison sécurisés à l'aide de mTLS, définissez le champ
Spec.Endpoints[].Schemede votre ressource PodMonitoring surhttps. Bien que cela ne soit pas recommandé, vous pouvez définir le champSpec.Endpoints[].tls.insecureSkipVerifyde votre ressource PodMonitoring surtruepour ignorer la vérification de l'autorité de certification. Vous pouvez également configurer Managed Service pour Prometheus afin de charger des certificats et des clés à partir de ressources de secret.Par exemple, la ressource Secret suivante contient des clés pour les certificats client (
cert), de clé privée (key) et d'autorité de certification (ca) :kind: Secret metadata: name: secret-example stringData: cert: ******** key: ******** ca: ********
Accordez au collecteur Managed Service pour Prometheus l'autorisation d'accéder à cette ressource Secret :
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
Sur les clusters GKE Autopilot, cela se présente comme suit :
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Pour configurer une ressource PodMonitoring utilisant la ressource Secret précédente, modifiez-la pour ajouter une section
schemeettls:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s scheme: https tls: ca: secret: name: secret-example key: ca cert: secret: name: secret-example key: cert key: secret: name: secret-example key: keyPour obtenir une documentation de référence sur toutes les options mTLS Managed Service pour Prometheus, consultez la documentation de référence de l'API.
BasicAuth
Pour activer le scraping des points de terminaison sécurisés à l'aide de BasicAuth, définissez le champ
Spec.Endpoints[].BasicAuthde votre ressource PodMonitoring avec votre nom d'utilisateur et votre mot de passe. Pour les autres types d'en-têtes d'autorisation HTTP, consultez En-tête d'autorisation HTTP.Par exemple, la ressource Secret suivante contient une clé permettant de stocker le mot de passe :
kind: Secret metadata: name: secret-example stringData: password: ********
Accordez au collecteur Managed Service pour Prometheus l'autorisation d'accéder à cette ressource Secret :
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
Sur les clusters GKE Autopilot, cela se présente comme suit :
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Pour configurer une ressource PodMonitoring qui utilise la ressource Secret précédente et le nom d'utilisateur
foo, modifiez votre ressource pour ajouter une sectionbasicAuth:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s basicAuth: username: foo password: secret: name: secret-example key: passwordPour obtenir une documentation de référence sur toutes les options BasicAuth Managed Service pour Prometheus, consultez la documentation de référence de l'API.
En-tête de l'autorisation HTTP
Pour activer le scraping des points de terminaison sécurisés à l'aide d'en-têtes d'autorisation HTTP, définissez le champ
Spec.Endpoints[].Authorizationde votre ressource PodMonitoring avec le type et les identifiants. Pour les points de terminaison BasicAuth, utilisez plutôt la configuration BasicAuth.Par exemple, la ressource Secret suivante contient une clé permettant de stocker les identifiants :
kind: Secret metadata: name: secret-example stringData: credentials: ********
Accordez au collecteur Managed Service pour Prometheus l'autorisation d'accéder à cette ressource Secret :
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
Sur les clusters GKE Autopilot, cela se présente comme suit :
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Pour configurer une ressource PodMonitoring qui utilise la ressource Secret précédente et un type de
Bearer, modifiez votre ressource pour ajouter une sectionauthorization:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s authorization: type: Bearer credentials: secret: name: secret-example key: credentialsPour obtenir une documentation de référence sur toutes les options d'en-tête d'autorisation HTTP Managed Service pour Prometheus, consultez la documentation de référence de l'API.
OAuth 2
Pour activer le scraping des points de terminaison sécurisés à l'aide d'OAuth 2, vous devez définir le champ
Spec.Endpoints[].OAuth2dans votre ressource PodMonitoring.Par exemple, la ressource Secret suivante contient une clé permettant de stocker le code secret du client :
kind: Secret metadata: name: secret-example stringData: clientSecret: ********
Accordez au collecteur Managed Service pour Prometheus l'autorisation d'accéder à cette ressource Secret :
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
Sur les clusters GKE Autopilot, cela se présente comme suit :
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
Pour configurer une ressource PodMonitoring qui utilise la ressource Secret précédente avec un ID client de
fooet une URL de jeton deexample.com/token, modifiez votre ressource pour ajouter une sectionoauth2:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s oauth2: clientID: foo clientSecret: secret: name: secret-example key: password tokenURL: example.com/tokenPour obtenir une documentation de référence sur toutes les options OAuth 2 Managed Service pour Prometheus, consultez la documentation de référence de l'API.
Configurer le scraping cible à l'aide de Terraform
Vous pouvez automatiser la création et la gestion de ressources PodMonitoring et ClusterPodMonitoring à l'aide du type de ressource Terraform
kubernetes_manifestou du type de ressource Terraformkubectl_manifest, qui vous permettent de spécifier des ressources personnalisées arbitraires.Pour obtenir des informations générales sur l'utilisation de Google Cloud avec Terraform, consultez Terraform avec Google Cloud.
Filtrer les métriques exportées
Si vous collectez une grande quantité de données, vous pouvez empêcher l'envoi de certaines séries temporelles au service géré pour Prometheus afin de limiter les coûts. Vous pouvez pour cela utiliser les règles de réécriture de libellés Prometheus avec une action
keeppour une liste d'autorisation ou une actiondroppour une liste de blocage. Pour la collecte gérée, cette règle se trouve dans la sectionmetricRelabelingde votre ressource PodMonitoring ou ClusterPodMonitoring.Par exemple, la règle de réécriture de libellés de métrique suivante filtre toutes les métriques commençant par
foo_bar_,foo_baz_oufoo_qux_:metricRelabeling: - action: drop regex: foo_(bar|baz|qux)_.+ sourceLabels: [__name__]La page Gestion des métriques de Cloud Monitoring fournit des informations qui peuvent vous aider à contrôler les sommes que vous consacrez aux métriques facturables, sans affecter l'observabilité. La page Gestion des métriques fournit les informations suivantes :
- Les volumes d'ingestion pour la facturation à base d'octets et celle à base d'exemples, englobant les différents domaines de métriques et des métriques individuelles
- Les données sur les libellés et la cardinalité des métriques
- Nombre de lectures pour chaque métrique.
- L'utilisation de métriques dans les règles d'alerte et les tableaux de bord personnalisés
- Les taux d'erreurs d'écriture de métriques
Vous pouvez également utiliser la page Gestion des métriques pour exclure les métriques inutiles, ce qui élimine le coût de leur ingestion. Pour en savoir plus sur la Gestion des métriques, consultez la section Afficher et gérer l'utilisation des métriques.
Pour découvrir d'autres suggestions permettant de réduire vos coûts, consultez la section Contrôle et attribution des coûts.
Récupérer les métriques Kubelet et cAdvisor
Le Kubelet expose des métriques sur lui-même ainsi que des métriques cAdvisor sur les conteneurs s'exécutant sur son nœud. Vous pouvez configurer la collecte gérée pour récupérer les métriques Kubelet et cAdvisor en modifiant la ressource OperatorConfig. Pour obtenir des instructions, consultez la documentation de l'exportateur pour Kubelet et cAdvisor.
Convertir les ressources prometheus-operator existantes
Vous pouvez généralement convertir vos ressources d'opérateur Prometheus en ressources PodMonitoring et ClusterPodMonitoring de la collection gérée des services gérés pour Prometheus.
Par exemple, la ressource ServiceMonitor définit la surveillance d'un ensemble de services. La ressource PodMonitoring diffuse un sous-ensemble des champs diffusés par la ressource ServiceMonitor. Vous pouvez convertir une ressource personnalisée ServiceMonitor en ressource personnalisée PodMonitoring en mappant les champs comme décrit dans le tableau suivant :
monitoring.coreos.com/v1
ServiceMonitorCompatibilité
monitoring.googleapis.com/v1
PodMonitoring.ServiceMonitorSpec.SelectorIdentiques .PodMonitoringSpec.Selector.ServiceMonitorSpec.Endpoints[].TargetPortcorrespond à.Port
.Path: compatible
.Interval: compatible
.Timeout: compatible.PodMonitoringSpec.Endpoints[].ServiceMonitorSpec.TargetLabelsPodMonitor doit spécifier :
.FromPod[].Fromlibellé du pod
.FromPod[].Tolibellé cible.PodMonitoringSpec.TargetLabelsVoici un exemple de ressource personnalisée ServiceMonitor ; le contenu en gras est remplacé dans la conversion, et le contenu en italique est mappé directement :
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - targetPort: web path: /stats interval: 30s targetLabels: - fooVoici la ressource personnalisée PodMonitoring analogue, en supposant que votre service et ses pods possèdent le libellé
app=example-app. Si cette hypothèse ne s'applique pas, vous devez utiliser les sélecteurs de libellés de la ressource de service sous-jacente.Le contenu en gras a été remplacé dans la conversion :
apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - port: web path: /stats interval: 30s targetLabels: fromPod: - from: foo # pod label from example-app Service pods. to: fooVous pouvez toujours utiliser vos ressources d'opérateur et configurations de déploiement Prometheus existantes à l'aide de collecteurs auto-déployés plutôt que de collecteurs gérés. Vous pouvez interroger les métriques envoyées par les deux types de collecteurs. Il est donc préférable d'utiliser des collecteurs auto-déployés pour vos déploiements Prometheus existants tout en utilisant des collecteurs gérés pour les nouveaux déploiements Prometheus.
Libellés réservés
Managed Service pour Prometheus ajoute automatiquement les libellés suivants à toutes les métriques collectées. Ces libellés permettent d'identifier de manière unique une ressource dans Monarch :
project_id: identifiant du projet Google Cloud associé à votre métrique.location: emplacement physique (régionGoogle Cloud ) dans lequel les données sont stockées. Cette valeur correspond généralement à la région de votre cluster GKE. Si les données sont collectées à partir d'un déploiement AWS ou sur site, la valeur peut être la région Google Cloud la plus proche.cluster: nom du cluster Kubernetes associé à la métrique.namespace: nom de l'espace de noms Kubernetes associé à la métrique.job: libellé de la tâche de la cible Prometheus, si elle est connue. Il peut être vide pour les résultats d'évaluation de règles.instance: libellé d'instance de la cible Prometheus, si elle est connue. Il peut être vide pour les résultats d'évaluation de règles.
Bien que cela ne soit pas recommandé lors de l'exécution sur Google Kubernetes Engine, vous pouvez ignorer les libellés
project_id,locationetclusteren les ajoutant en tant qu'argsà la ressource de déploiement dansoperator.yaml. Si vous utilisez des libellés réservés en tant que libellés de métriques, Managed Service pour Prometheus les réécrit automatiquement en ajoutant le préfixeexported_. Ce comportement correspond à la manière dont Prometheus gère en amont les conflits avec les libellés réservés.Configurations de compression
Si vous disposez de nombreuses ressources PodMonitoring, vous risquez de manquer d'espace ConfigMap. Pour résoudre ce problème, activez la compression
gzipdans votre ressource OperatorConfig :apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: config: compression: gzipActiver l'autoscaling vertical des pods (VPA) pour la collection gérée
Si vous rencontrez des erreurs de mémoire insuffisante (OOM) pour les pods de collecteur de votre cluster ou si les demandes et les limites de ressources par défaut des collecteurs ne répondent pas à vos besoins, vous pouvez utiliser l'autoscaling vertical des pods pour allouer des ressources de manière dynamique.
Lorsque vous définissez le champ
scaling.vpa.enabled: truesur la ressourceOperatorConfig, l'opérateur déploie un fichier manifesteVerticalPodAutoscalerdans le cluster, ce qui permet de définir automatiquement les demandes et limites de ressources des pods du collecteur en fonction de l'utilisation.Pour activer le VPA pour les pods de collecteur dans Managed Service pour Prometheus, exécutez la commande suivante :
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=mergeSi la commande aboutit, l'opérateur configure l'auto-scaling vertical des pods de collecteur. Les erreurs de mémoire insuffisante entraînent une augmentation immédiate des limites de ressources. S'il n'y a pas d'erreurs OOM, le premier ajustement des demandes de ressources et des limites des pods de collecteurs a généralement lieu sous 24 heures.
Vous pouvez recevoir ce message d'erreur lorsque vous essayez d'activer le VPA :
vertical pod autoscaling is not available - install vpa support and restart the operatorPour résoudre cette erreur, vous devez d'abord activer l'autoscaling vertical des pods au niveau du cluster :
Accédez à la page Kubernetes Engine : clusters dans la consoleGoogle Cloud .
Dans la console Google Cloud , accédez à la page Clusters Kubernetes :
Accéder à la page Clusters Kubernetes
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Kubernetes Engine.
Sélectionnez le cluster que vous souhaitez modifier.
Dans la section Automatisation, modifiez la valeur de l'option Autoscaling vertical des pods.
Cochez la case Activer l'autoscaling vertical des pods, puis cliquez sur Enregistrer les modifications. Cette modification redémarre votre cluster. L'opérateur redémarre dans le cadre de ce processus.
Réessayez la commande suivante :
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=mergepour activer le VPA pour Managed Service pour Prometheus.
Pour vérifier que la ressource
OperatorConfiga bien été modifiée, ouvrez-la à l'aide de la commandekubectl -n gmp-public edit operatorconfig config. Si l'opération réussit, votreOperatorConfiginclut la section suivante en gras :apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config scaling: vpa: enabled: trueSi vous avez déjà activé l'autoscaling vertical des pods au niveau du cluster et que l'erreur
vertical pod autoscaling is not available - install vpa support and restart the operators'affiche toujours, il est possible que le podgmp-operatordoive réévaluer la configuration du cluster. Si vous exécutez un cluster Standard, exécutez la commande suivante pour recréer le pod :kubectl -n gmp-system rollout restart deployment/gmp-operator
Une fois le pod
gmp-operatorredémarré, suivez les étapes ci-dessus pour corriger à nouveau leOperatorConfig.Si vous exécutez un cluster Autopilot, contactez l'assistance pour obtenir de l'aide afin de redémarrer le cluster.
L'autoscaling vertical des pods fonctionne mieux lorsque vous ingérez un nombre constant d'échantillons, répartis de manière égale sur les nœuds. Si la charge des métriques est irrégulière ou présente des pics, ou si la charge des métriques varie considérablement entre les nœuds, le VPA peut ne pas être une solution efficace.
Pour en savoir plus, consultez la section Autoscaling vertical des pods dans GKE.
Configurer statsd_exporter et d'autres exportateurs qui génèrent des rapports sur les métriques de manière centralisée
Si vous utilisez statsd_exporter pour Prometheus, Envoy pour Istio, l'exportateur SNMP, Prometheus Pushgateway, kube-state-metrics ou tout autre exportateur similaire qui sert d'intermédiaire et signale les métriques au nom d'autres ressources s'exécutant dans votre environnement, vous devez apporter quelques modifications mineures pour que votre exportateur fonctionne avec Managed Service pour Prometheus.
Pour obtenir des instructions sur la configuration de ces exportateurs, consultez cette note dans la section "Dépannage".
Suppression
Pour désactiver la collecte gérée déployée à l'aide de
gcloudou de l'interface utilisateur de GKE, vous pouvez effectuer l'une des opérations suivantes :Exécutez la commande suivante :
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus
Utilisez l'interface utilisateur GKE :
Dans la console Google Cloud , sélectionnez Kubernetes Engine, puis Clusters.
Recherchez le cluster pour lequel vous souhaitez désactiver la collecte gérée et cliquez sur son nom.
Dans l'onglet Détails, faites défiler la page jusqu'à Fonctionnalités, puis définissez l'état sur Désactivé à l'aide du bouton de modification.
Pour désactiver la collecte gérée déployée à l'aide de Terraform, spécifiez
enabled = falsedans la sectionmanaged_prometheusde la ressourcegoogle_container_cluster.Pour désactiver la collecte gérée déployée à l'aide de
kubectl, exécutez la commande suivante :kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
La désactivation de la collecte gérée empêche votre cluster d'envoyer de nouvelles données à Managed Service pour Prometheus. Cette action ne supprime pas les données de métriques existantes déjà stockées dans le système.
La désactivation de la collecte gérée supprime également l'espace de noms
gmp-publicet toutes les ressources qu'il contient, y compris les exportateurs installés dans cet espace de noms.Exécuter une collecte gérée en dehors de GKE
Dans les environnements GKE, vous pouvez exécuter la collecte gérée sans configuration supplémentaire. Dans d'autres environnements Kubernetes, vous devez fournir explicitement les identifiants, une valeur
project-idpour contenir vos métriques, une valeurlocation(régionGoogle Cloud ) où vos métriques seront stockées et une valeurclusterpour enregistrer le nom du cluster dans lequel le collecteur s'exécute.Comme
gcloudne fonctionne pas en dehors des environnements Google Cloud , vous devez déployer à l'aide de kubectl. Contrairement àgcloud, le déploiement d'une collecte gérée à l'aide dekubectlne met pas automatiquement à niveau votre cluster lorsqu'une nouvelle version est disponible. N'oubliez pas de consulter la page des versions pour connaître les nouvelles versions, et effectuez une mise à niveau manuelle en exécutant à nouveau les commandeskubectlavec la nouvelle version.Vous pouvez fournir une clé de compte de service en modifiant la ressource OperatorConfig dans
operator.yaml, comme décrit dans la section Fournir des identifiants explicitement. Vous pouvez fournir les valeursproject-id,locationetclusteren les ajoutant en tant queargsà la ressource Deployment dansoperator.yaml.Nous vous recommandons de choisir
project-iden fonction de votre modèle de location planifié pour les lectures. Choisissez un projet dans lequel stocker les métriques en fonction de la manière dont vous envisagez d'organiser les lectures par la suite via des champs d'application de métriques. Si cela n'a aucune importance pour vous, vous pouvez tout regrouper dans un même projet.Pour
location, nous vous recommandons de choisir la région Google Cloud la plus proche de votre déploiement. Plus la région Google Cloud choisie est éloignée de votre déploiement, plus la latence d'écriture sera importante, et plus vous risquez d'être affecté par d'éventuels problèmes de réseau. Vous pouvez consulter cette liste des régions couvrant plusieurs clouds. Si cela n'a pas d'importance à vos yeux, vous pouvez tout déployer dans une seule région Google Cloud . Vous ne pouvez pas utiliserglobalcomme emplacement.Pour
cluster, nous vous recommandons de choisir le nom du cluster dans lequel l'opérateur est déployé.Lorsqu'elle est correctement configurée, votre ressource OperatorConfig doit ressembler à ceci :
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.json rules: credentials: name: gmp-test-sa key: key.jsonVotre ressource Deployment doit ressembler à ceci :
apiVersion: apps/v1 kind: Deployment ... spec: ... template: ... spec: ... containers: - name: operator ... args: - ... - "--project-id=PROJECT_ID" - "--cluster=CLUSTER_NAME" - "--location=REGION"Cet exemple suppose que vous avez défini la variable
REGIONsur une valeur telle queus-central1.L'exécution de Managed Service pour Prometheus en dehors de Google Cloud entraîne des frais de transfert de données. Le transfert de données vers Google Cloudest payant, et des frais peuvent vous être facturés depuis un autre cloud. Vous pouvez réduire ces coûts en activant la compression gzip sur le réseau via la ressource OperatorConfig. Ajoutez le texte affiché en gras à la ressource :
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: compression: gzip ...Documentation complémentaire sur les ressources personnalisées des collections gérées
Pour obtenir une documentation de référence sur toutes les ressources personnalisées Managed Service pour Prometheus, consultez la documentation prometheus-engine/doc/api reference.
Étapes suivantes