Ce document explique comment configurer un environnement combinant des collecteurs autodéployés avec des collecteurs gérés, sur différents projets et clustersGoogle Cloud .
Nous vous recommandons vivement d'utiliser la collecte gérée pour tous les environnements Kubernetes. Cela permet d'éliminer pratiquement les frais généraux liés à l'exécution des collecteurs Prometheus dans votre cluster. Vous pouvez exécuter des collecteurs gérés et auto-déployés dans le même cluster. Nous vous recommandons d'adopter une approche cohérente pour la surveillance, mais vous pouvez choisir de combiner des méthodes de déploiement pour certains cas d'utilisation spécifiques, tels que l'hébergement d'une passerelle d'envoi, comme illustré dans ce document.
Le schéma suivant illustre une configuration qui utilise deux projetsGoogle Cloud , trois clusters et un mélange de collection gérée et auto-déployée. Si vous n'utilisez que des collections gérées ou auto-déployées, le schéma reste applicable : Il vous suffit d'ignorer le style de collection que vous n'utilisez pas :
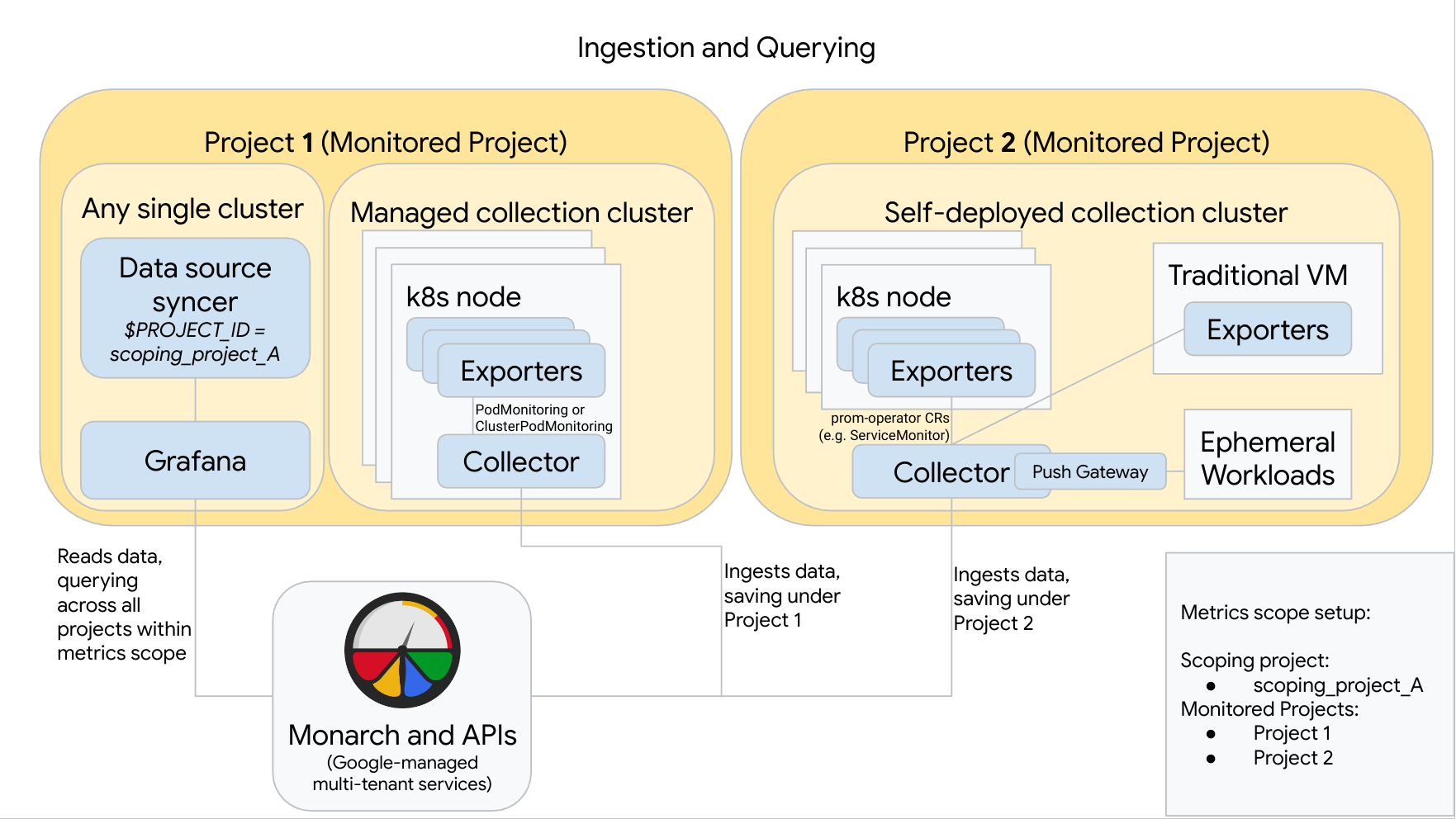
Pour réaliser et utiliser une configuration comme celle du diagramme, notez les points suivants :
Vous devez installer les exportateurs nécessaires dans vos clusters. Le service géré Google Cloud pour Prometheus n'installe aucun exportateur en votre nom.
Le projet 1 possède un cluster exécutant la collection gérée, qui s'exécute en tant qu'agent de nœud. Les collecteurs sont configurés avec des ressources PodMonitoring pour scraper des cibles dans un espace de noms et avec des ressources ClusterPodMonitoring pour scraper des cibles dans un cluster. Les éléments PodMonitorings doivent être appliqués dans chaque espace de noms dans lequel vous souhaitez collecter des métriques. Les ClusterPodMonitorings sont appliqués une fois par cluster.
Toutes les données collectées dans le projet 1 sont enregistrées dans Monarch sous le projet 1. Ces données sont stockées par défaut dans la région Google Cloud à partir de laquelle elles ont été émises.
Le projet 2 comporte un cluster exécutant une collection auto-déployée à l'aide de l'opérateur Prometheus et s'exécutant en tant que service autonome. Ce cluster est configuré pour utiliser des PodMonitors ou des ServiceMonitors de Prometheus-opérateur pour scraper des exportateurs sur des pods ou des VM.
Le projet 2 héberge également une passerelle side-car push pour collecter des métriques de charges de travail éphémères.
Toutes les données collectées dans le projet 2 sont enregistrées dans Monarch sous le projet 2. Ces données sont stockées par défaut dans la région Google Cloud à partir de laquelle elles ont été émises.
Le projet 1 contient également un cluster exécutant Grafana et le synchronisateur de sources de données. Dans cet exemple, ces composants sont hébergés dans un cluster autonome, mais ils peuvent être hébergés dans n'importe quel cluster.
Le synchronisateur de sources de données est configuré pour utiliser scoping_project_A, et son compte de service sous-jacent dispose des autorisations du rôle Lecteur Monitoring pour scoping_project_A.
Lorsqu'un utilisateur émet des requêtes depuis Grafana, Monarch développe le projet scoping_project_A dans ses projets surveillés constitutifs et renvoie les résultats du projet 1 et du projet 2 dans toutes les régions Google Cloud . Toutes les métriques conservent leurs libellés
project_idetlocationd'origine (régionGoogle Cloud ) à des fins de regroupement et de filtrage.
Si votre cluster ne s'exécute pas dans Google Cloud, vous devez configurer manuellement les libellés project_id et location. Pour en savoir plus sur la définition de ces valeurs, consultez la page Exécuter le service géré pour Prometheus en dehors deGoogle Cloud.
Ne fédérez pas lorsque vous utilisez le service géré pour Prometheus. Pour réduire la cardinalité et les coûts en "consolidant" des données avant de les envoyer à Monarch, utilisez plutôt l'agrégation locale. Pour en savoir plus, consultez la section Configurer l'agrégation locale.