Ce document présente les services fournis par Cloud Monitoring. Ces services peuvent vous aider à comprendre le comportement, l'état et les performances de vos applications et d'autres services Google Cloud . Cloud Monitoring collecte et stocke automatiquement les informations sur les performances de la plupart des services Google Cloud . Vous pouvez collecter des métriques Prometheus à l'aide de Google Cloud Managed Service pour Prometheus. Si vous installez l'agent Ops sur vos machines virtuelles (VM) Compute Engine, vous pouvez collecter des métriques et des journaux à partir de vos applications et d'applications tierces.
Les services d'alerte, de test et de visualisation fournis par Cloud Monitoring vous aident à répondre à des questions importantes, telles que les suivantes :
- Quelle est la charge sur mon service ?
- Mon site Web répond-il correctement ?
- Mon service est-il performant ?
- Quel est l'état de mon application App Hub ?
Cloud Monitoring est compatible avec la console Google Cloud et l'API pour la plupart de ses services. Certains services sont également compatibles avec Google Cloud CLI ou Terraform. Les pages de référence de l'API Cloud Monitoring, telles que alertPolicies.list, vous permettent de tester les appels d'API directement à partir de la page de référence.
Services Cloud Monitoring
Cloud Monitoring propose différents services que vous pouvez utiliser pour comprendre l'état et les performances de vos applications, ainsi que des autres services Google Cloud que vous utilisez.
Incidents et notifications
Pour recevoir une notification lorsque la valeur d'une métrique de performances répond aux critères que vous avez définis, créez une règle d'alerte. La règle d'alerte inclut la liste des personnes ou des groupes qui doivent recevoir des notifications. Monitoring est compatible avec les canaux de notification courants, y compris les e-mails, Cloud Mobile App et des services tels que PagerDuty ou Slack. Par exemple, vous pouvez créer une règle d'alerte pour être averti lorsque l'utilisation du processeur d'une VM dépasse 80 %.
Chaque notification inclut des informations pertinentes sur un échec et un lien vers un incident. Un incident est un enregistrement persistant qui stocke des informations que vous pouvez utiliser pour résoudre le problème. En général, un enregistrement liste l'état de l'incident, des liens vers les journaux, un graphique des données de métriques enregistrées, des libellés et la durée.
Le service d'alerte est intégré à de nombreux services Google Cloud . Lorsque ces intégrations existent, un panneau peut s'afficher et lister les alertes recommandées. Vous pouvez également voir un bouton sur un graphique qui vous permet de créer une règle d'alerte. Dans les deux cas, les règles d'alerte sont préconfigurées. Il vous suffit de spécifier la liste des personnes ou des groupes à avertir.
Vous pouvez créer et gérer des règles d'alerte à l'aide de la console Google Cloud , de l'API Cloud Monitoring, de Google Cloud CLI ou de Terraform.
Surveillance et validation proactives
Pour tester la disponibilité, la cohérence et les performances de vos services, applications, pages Web et API, créez des surveillances synthétiques. Par exemple, vous pouvez tester la réactivité des points de terminaison HTTP, HTTPS et TCP avec des tests de disponibilité, puis recevoir une notification lorsqu'un point de terminaison ne répond pas. Vous pouvez également créer un vérificateur de liens brisés pour explorer une page Web et vous avertir en cas de détection de liens brisés.
Vous pouvez créer et gérer des synthétiques à l'aide de la console Google Cloud , de l'API Cloud Monitoring, de la Google Cloud CLI ou de Terraform.
Visualisation des données
Lorsque vous instanciez des ressources Google Cloud ou enregistrez des applications avec App Hub, le service de tableau de bord crée automatiquement des tableaux de bord gérés parGoogle Cloud. Ces tableaux de bord affichent des informations sélectionnées qui vous aident à comprendre l'état de vos ressources et applications. Par exemple, pour une application App Hub, des tableaux de bord sont créés pour l'application et pour chacun de ses services et charges de travail. Ces tableaux de bord affichent des informations telles que les données de journaux ou de métriques d'une application, ainsi que le nombre d'alertes ouvertes.
Les tableaux de bord créés par Google Cloud peuvent vous fournir suffisamment d'informations pour mener à bien une investigation. Toutefois, ils ne fournissent peut-être pas les données exactes dont vous avez besoin pour identifier les tendances, les valeurs aberrantes ou d'autres détails sur vos données. Pour effectuer ces tâches, vous pouvez utiliser les services dashboard et charting :
Pour contrôler les données que vous affichez et leur format, créez un tableau de bord personnalisé. Par exemple, vous pouvez importer un tableau de bord Grafana ou installer un tableau de bord à partir d'un modèle.
Vos tableaux de bord personnalisés peuvent afficher les éléments suivants.
- Graphiques et tableaux affichant des données de métriques
- Données de journaux et groupes d'erreurs
- Graphiques pour les règles d'alerte
- Informations sur les alertes
- Texte
- Événements, tels qu'un redémarrage ou un plantage, qui affectent le fonctionnement d'un système.
Vous pouvez créer et gérer des tableaux de bord à l'aide de la consoleGoogle Cloud ou de l'API.
Le service de création de graphiques, Explorateur de métriques, vous permet de visualiser et d'explorer rapidement les données de séries temporelles. Les paramètres de graphique vous permettent de comparer des données actuelles à des données précédentes, d'afficher les valeurs aberrantes et les centiles, et d'afficher plusieurs métriques. Vous pouvez également enregistrer des graphiques dans un tableau de bord personnalisé.
Collecte et stockage des données
Cloud Monitoring collecte et stocke les types de données de métriques suivants :
- Métriques système générées par les services Google Cloud . Ces métriques fournissent des informations sur le fonctionnement d'un service.
- Métriques système et d'application collectées par l'agent Ops sur les ressources système et les applications s'exécutant sur les instances Compute Engine. Vous pouvez configurer l'agent Ops pour collecter des métriques à partir de plug-ins tiers tels que des serveurs Web Apache ou Nginx, ou des bases de données MongoDB ou PostgreSQL.
Des métriques définies par l'utilisateur créées à l'aide de l'API Cloud Monitoring ou d'une bibliothèque telle qu'OpenTelemetry.
Métriques externes définies par certaines bibliothèques Open Source ou certains fournisseurs tiers.
Métriques Prometheus collectées par Google Cloud Managed Service pour Prometheus, ou à l'aide de l'agent Ops et du récepteur Prometheus ou du récepteur OTLP.
- Les métriques basées sur les journaux, qui enregistrent des informations numériques sur les journaux écrits dans Cloud Logging. Les métriques basées sur les journaux définies par Google incluent le nombre d'erreurs détectées par votre service et le nombre total d'entrées de journal reçues par votre projet Google Cloud . Vous pouvez également définir des métriques basées sur les journaux.
Langages de requête
Lorsque vous créez une règle d'alerte ou un graphique, vous devez fournir une requête qui décrit les données que vous souhaitez surveiller ou représenter sous forme de graphique :
Google Cloud console : vous pouvez créer votre requête en effectuant des sélections dans les menus ou en rédigeant une requête. Des éditeurs de requêtes sont disponibles pour le langage de requête Prometheus (PromQL). L'éditeur de requête fournit des vérifications de syntaxe et des suggestions. Vous pouvez également écrire une expression de filtre Monitoring.
API Cloud Monitoring : l'API est compatible avec le langage de requête Prometheus (PromQL) et les expressions de filtre Monitoring.
Surveiller des systèmes volumineux
Cette section explique comment gérer les ressources en tant que collection et comment surveiller les métriques stockées dans plusieurs projets Google Cloud .
Gérer les ressources en tant que collection
Pour gérer vos ressources en tant que collection plutôt qu'individuellement, créez un groupe de ressources. Un groupe de ressources est une collection dynamique de ressources qui répond à certains critères que vous fournissez. Lorsque vous ajoutez et supprimez des ressources, par exemple en ajoutant des instances de VM Compute Engine à votre projetGoogle Cloud , l'appartenance au groupe change automatiquement. Voici des exemples de groupes de ressources:
- Instances Compute Engine dont le nom commence par la chaîne
prod-. - Ressources comportant le tag
test-cluster. - Instances Amazon EC2 dans la région A ou la région B.
Après avoir défini un groupe de ressources, vous pouvez le surveiller comme s'il s'agissait d'une seule ressource. Par exemple, vous pouvez configurer un test de disponibilité pour surveiller un groupe de ressources. Pour les graphiques et les règles d'alerte, vous pouvez également filtrer par nom de groupe.
Pour en savoir plus, consultez Configurer des groupes de ressources.
Surveiller les métriques de plusieurs projets Google Cloud
Pour afficher et surveiller les données de séries temporelles de plusieurs projetsGoogle Cloud et comptes AWS via une seule interface, configurez un champ d'application des métriques multiprojet.
Par défaut, les pages Cloud Monitoring de la console Google Cloud ne permettent d'accéder qu'aux séries temporelles stockées dans le projet de champ d'application. Le projet de champ d'application est le projet que vous avez sélectionné à l'aide de l'outil de sélection de projets de la consoleGoogle Cloud . Le projet de champ d'application stocke les alertes, les surveillances synthétiques, les tableaux de bord et les groupes de surveillance que vous configurez.
Le projet de champ d'application héberge également un champ d'application des métriques. Le champ d'application des métriques définit les projets et les comptes dont les métriques sont visibles par le projet de champ d'application. Vous pouvez configurer le champ d'application des métriques pour inclure des données de séries temporelles provenant d'autres projets Google Cloud et de comptes AWS. Pour savoir comment modifier un champ d'application des métriques, consultez Configurer un champ d'application des métriques pour plusieurs projets.
Modèle de données Cloud Monitoring
Cette section présente le modèle de données Cloud Monitoring :
Un type de métrique décrit un élément mesuré. L'utilisation du processeur d'une VM et le pourcentage d'un disque utilisé sont des exemples de types de métriques.
Une série temporelle est une structure de données qui contient les mesures horodatées d'une métrique ainsi que des informations sur la source et la signification de ces mesures.
Voici quelques détails sur le contenu d'une série temporelle:
Le tableau
pointscontient les mesures horodatées.Voici un exemple de tableau
pointsavec deux valeurs :"points": [ { "interval": { "startTime": "2020-07-27T20:20:21.597143Z", "endTime": "2020-07-27T20:20:21.597143Z" }, "value": { "doubleValue": 0.473005 } }, { "interval": { "startTime": "2020-07-27T20:19:21.597239Z", "endTime": "2020-07-27T20:19:21.597239Z" }, "value": { "doubleValue": 0.473025 } }, ],Pour comprendre la signification d'une valeur, vous devez vous référer aux autres données incluses dans la série temporelle et aux définitions de ces données.
Le champ
resourcedécrit le composant matériel ou logiciel surveillé. Dans Cloud Monitoring, le composant matériel ou logiciel est appelé ressource surveillée. Les instances Compute Engine et les applications App Engine sont des exemples de ressources surveillées. Pour obtenir la liste des ressources surveillées, consultez la liste des ressources surveillées.Voici un exemple de champ
resource:"resource": { "type": "gce_instance", "labels": { "instance_id": "2708613220420473591", "zone": "us-east1-b", "project_id": "sampleproject" } }Le champ
typeprésente la ressource surveillée en tant quegce_instance, ce qui indique que ces mesures sont effectuées sur une instance de VM Compute Engine.Le sous-champ
labelscontient des paires clé/valeur qui fournissent des informations supplémentaires sur la ressource surveillée. Pour un typegce_instance, les libellés identifient l'instance de VM surveillée.
Le champ
metricdécrit l'élément qui est mesuré.Voici un exemple de champ
metric:"metric": { "labels": { "instance_name": "test" }, "type": "compute.googleapis.com/instance/cpu/utilization" },- Pour les services Google Cloud , le champ
typespécifie le service et les éléments surveillés. Dans cet exemple, le service Compute Engine mesure l'utilisation du processeur. Lorsque le champtypecommence parcustomouexternal, la métrique est soit une métrique personnalisée, soit une métrique définie par un tiers.
- Le champ
labelscontient des paires clé/valeur qui fournissent des informations supplémentaires sur la mesure. Ces libellés sont définis dans leMetricDescriptor, qui est une structure de données qui définit les attributs des données mesurées. L'élémentMetricDescriptorde la métriquecompute.googleapis.com/instance/cpu/utilizationinclut le libelléinstance_name.
- Pour les services Google Cloud , le champ
Le champ
metricKinddécrit la relation entre les mesures adjacentes au sein d'une série temporelle:Les métriques
GAUGEstockent la valeur de l'élément mesuré à un moment donné, par exemple un enregistrement de température horaire.Les métriques
CUMULATIVEstockent la valeur accumulée de l'élément mesuré à un moment donné, par exemple un kilométrage dans un véhicule.Les métriques
DELTAstockent le changement dans la valeur de l'élément mesuré sur une période spécifiée, par exemple un résumé des actions qui montre les gains ou les pertes de l'action.
Le champ
valueTypedécrit le type de données pour la mesure:INT64,DOUBLE,BOOL,STRINGouDISTRIBUTION
- Vous pouvez afficher l'utilisation du processeur de chaque instance de VM.
- Vous pouvez afficher l'utilisation du processeur pour une instance de VM spécifique en filtrant les séries temporelles pour une seule valeur du libellé
instance_id. Vous pouvez regrouper les instances de VM selon le libellé
machine_type, puis afficher l'utilisation moyenne du processeur. La capture d'écran suivante illustre un graphique avec cette configuration: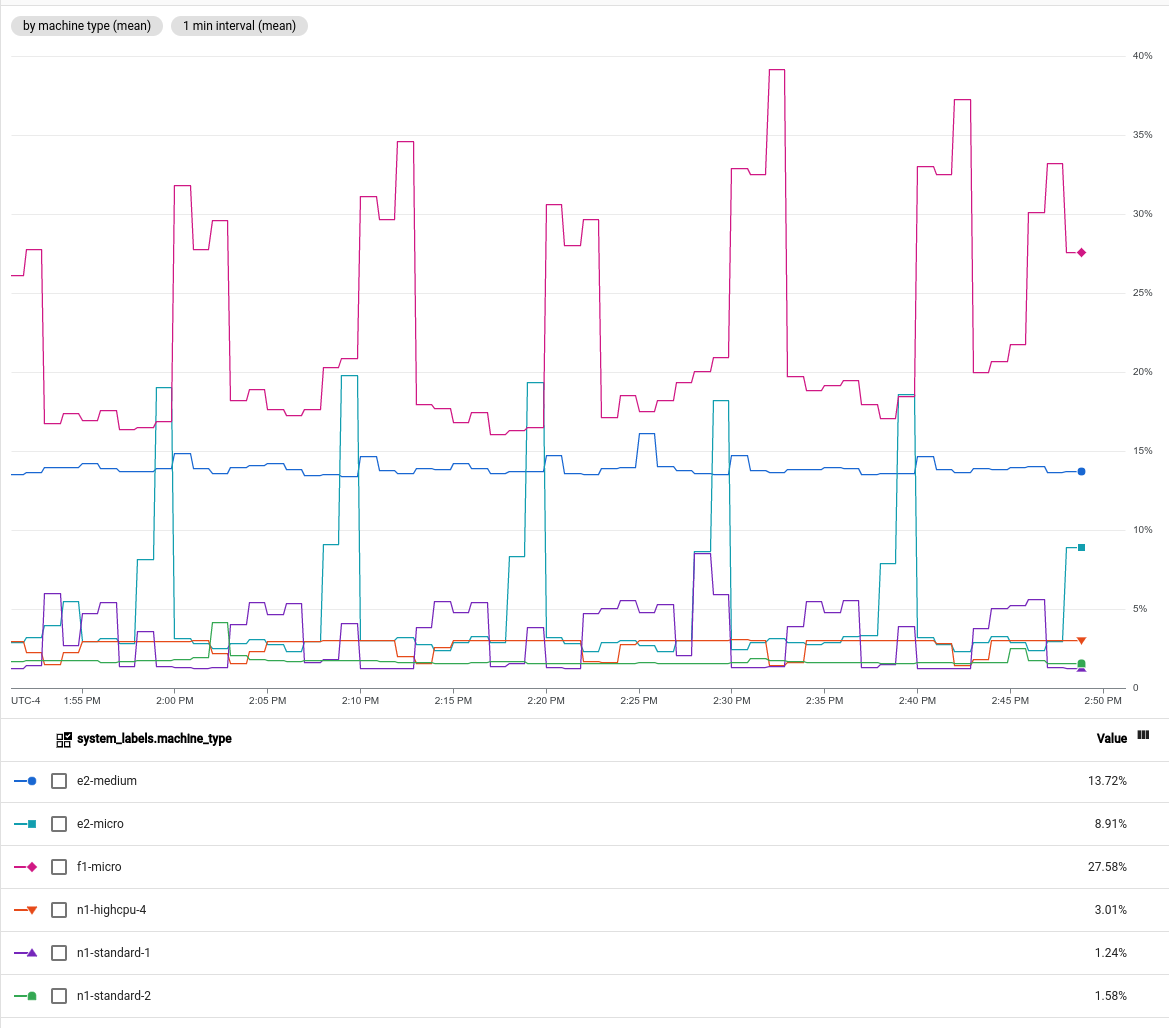
Tarifs
En général, les métriques système Cloud Monitoring sont gratuites, contrairement à celles provenant de systèmes, d'agents ou d'applications externes. Les métriques facturables sont facturées en fonction du nombre d'octets ou d'échantillons ingérés.
Pour en savoir plus, consultez les sections Cloud Monitoring de la page Tarifs de Google Cloud Observability.
Étapes suivantes
- Pour explorer Cloud Monitoring, essayez le guide de démarrage rapide pour surveiller une instance Compute Engine.
- Pour savoir comment configurer notre projet Google Cloud afin d'afficher les métriques de plusieurs projets Google Cloud et comptes AWS, consultez Présentation des champs d'application des métriques.
Pour en savoir plus sur le modèle de données Cloud Monitoring, consultez Métriques, séries temporelles et ressources.
Pour plus d'informations sur l'API Cloud Monitoring, consultez la page API et documentation de référence.
Pour obtenir des listes de métriques et de ressources surveillées, consultez les pages Liste des métriques et Liste des ressources surveillées.