En este documento, se proporciona una descripción general de los servicios que ofrece Cloud Monitoring. Estos servicios pueden ayudarte a comprender el comportamiento, el estado y el rendimiento de tus aplicaciones y de otros servicios de Google Cloud . Cloud Monitoring recopila y almacena automáticamente información de rendimiento para la mayoría de los Google Cloud servicios. Puedes recopilar métricas de Prometheus con Google Cloud Managed Service para Prometheus. Si instalas el Agente de operaciones en tus máquinas virtuales (VM) de Compute Engine, puedes recopilar métricas y registros de tus aplicaciones y de aplicaciones de terceros.
Los servicios de alertas, pruebas y visualización que proporciona Cloud Monitoring te ayudan a responder preguntas importantes, como las siguientes:
- ¿Cuál es la carga de mi servicio?
- ¿Mi sitio web responde correctamente?
- ¿Mi servicio tiene un buen rendimiento?
- ¿Cuál es el estado de mi aplicación de App Hub?
Cloud Monitoring proporciona asistencia para la Google Cloud consola y la API para la mayoría de sus servicios. Algunos servicios también admiten Google Cloud CLI o Terraform. Las páginas de referencia de la API de Cloud Monitoring, como la página alertPolicies.list, te permiten experimentar con llamadas a la API directamente desde la página de referencia.
Servicios de Cloud Monitoring
Cloud Monitoring proporciona diferentes servicios que puedes usar para comprender el estado y el rendimiento de tus aplicaciones, y de los otros Google Cloud servicios que usas.
Incidentes y notificaciones
Para recibir notificaciones cuando el valor de una métrica de rendimiento cumpla con los criterios que definiste, crea una política de alertas. La política de alertas incluye la lista de personas o grupos que recibirán notificaciones. Monitoring admite canales de notificación comunes, incluidos correos electrónicos, Cloud Mobile App y servicios como PagerDuty o Slack. Por ejemplo, puedes crear una política de alertas para que se te notifique cuando el uso de CPU de una VM supere el 80%.
Cada notificación incluye información pertinente sobre una falla y un vínculo a un incidente. Un incidente es un registro persistente que almacena información que puedes usar para solucionar el error. Por lo general, un registro enumera el estado del incidente, vínculos a los registros, un gráfico de los datos de métricas registrados, etiquetas y duración.
El servicio de alertas está integrado en muchos servicios de Google Cloud . Cuando existen estas integraciones, es posible que veas un panel que enumera las alertas recomendadas o un botón en un gráfico que te permita crear una política de alertas. En ambos casos, las políticas de alertas están preconfiguradas, y solo debes especificar la lista de personas o grupos que recibirán notificaciones.
Puedes crear y administrar políticas de alertas con la Google Cloud consola, la API de Cloud Monitoring, Google Cloud CLI o Terraform.
Supervisión y validación proactivas
Para probar la disponibilidad, la coherencia y el rendimiento de tus servicios, aplicaciones, páginas web y APIs, crea monitores sintéticos. Por ejemplo, puedes sondear la capacidad de respuesta de los extremos HTTP, HTTPS y TCP con verificaciones de tiempo de actividad y, luego, recibir notificaciones cuando un extremo no responda. También puedes crear un verificador de vínculos rotos para rastrear una página web y, luego, notificarte cuando se detecten vínculos rotos.
Puedes crear y administrar monitores sintéticos con la Google Cloud consola, la API de Cloud Monitoring, Google Cloud CLI o Terraform.
Visualización de datos
A medida que creas instancias de recursos Google Cloud o registras aplicaciones con App Hub, el servicio de paneles crea automáticamente paneles administrados porGoogle Cloud. Estos paneles muestran información seleccionada que te ayuda a comprender el estado de tus recursos y aplicaciones. Por ejemplo, para una aplicación de App Hub, se crean paneles para la aplicación y para cada uno de sus servicios y cargas de trabajo. En estos paneles, se muestra información como los datos de registro o de métricas de una aplicación, y la cantidad de alertas abiertas.
Los paneles creados por Google Cloud podrían proporcionarte suficiente información para completar una investigación. Sin embargo, es posible que no proporcionen los datos exactos que necesitas para ver tendencias, identificar valores atípicos o ver otros detalles sobre tus datos. Para completar estas tareas, puedes usar los servicios de panel y gráficos:
Para controlar qué datos ves y el formato de visualización de esos datos, crea un panel personalizado. Por ejemplo, puedes importar un panel de Grafana o instalar un panel desde una plantilla.
Tus paneles personalizados pueden mostrar lo siguiente:
- Gráficos y tablas que muestran datos de métricas
- Registra datos y grupos de errores
- Gráficos para políticas de alertas
- Información sobre las alertas
- Texto
- Eventos, como un reinicio o una falla, que afectan el funcionamiento de un sistema
Puedes crear y administrar paneles con la consola deGoogle Cloud o la API.
El servicio de gráficos, Explorador de métricas, te permite visualizar y explorar rápidamente los datos de series temporales. La configuración del gráfico te permite comparar los datos actuales con los anteriores, mostrar valores atípicos y percentiles, y mostrar varias métricas. También puedes guardar gráficos en un panel personalizado.
Recopilación y almacenamiento de datos
Cloud Monitoring recopila y almacena los siguientes tipos de datos de métricas:
- Métricas del sistema generadas por los servicios de Google Cloud Estas métricas proporcionan información sobre cómo opera un servicio.
- Métricas del sistema y de las aplicaciones que el agente de operaciones recopila sobre los recursos del sistema y las aplicaciones que se ejecutan en instancias de Compute Engine. Puedes configurar el Agente de operaciones para recopilar métricas de complementos de terceros, como servidores web de Apache o Nginx, o bases de datos de MongoDB o PostgreSQL.
Métricas definidas por el usuario que se crean con la API de Cloud Monitoring o con una biblioteca como OpenTelemetry
Métricas externas definidas por algunas bibliotecas de código abierto o proveedores externos.
Métricas de Prometheus recopiladas por Google Cloud Managed Service para Prometheus o con el agente de operaciones y el receptor de Prometheus o el receptor de OTLP.
- Métricas basadas en registros que registran información numérica sobre los registros escritos en Cloud Logging. Las métricas basadas en registros definidas por Google incluyen los recuentos de los errores que detecta tu servicio y la cantidad total de entradas de registro que recibe tu proyecto de Google Cloud . También puedes definir métricas basadas en registros.
Lenguajes de consulta
Cuando creas una política de alertas o un gráfico, debes proporcionar una consulta que describa los datos que deseas supervisar o graficar:
Consola deGoogle Cloud : Puedes compilar tu consulta seleccionando opciones de los menús o escribir una consulta. Los editores de consultas están disponibles para el lenguaje de consulta de Prometheus (PromQL). El editor de consultas proporciona verificaciones y sugerencias de sintaxis. También puedes escribir una expresión de filtro de supervisión.
API de Cloud Monitoring: La API admite el lenguaje de consultas de Prometheus (PromQL) y las expresiones de filtro de Monitoring.
Supervisa sistemas grandes
En esta sección, se describe cómo puedes administrar los recursos como una colección y cómo puedes supervisar las métricas que se almacenan en varios proyectos de Google Cloud .
Administra recursos como una colección
Para administrar tus recursos como una colección en lugar de hacerlo de forma individual, crea un grupo de recursos. Un grupo de recursos es una colección dinámica de recursos que satisfacen algunos criterios que proporcionas. A medida que agregas y quitas recursos, por ejemplo, instancias de VM de Compute Engine a tu proyectoGoogle Cloud , la membresía del grupo cambia automáticamente. A continuación, se incluyen ejemplos de grupos de recursos:
- Instancias de Compute Engine cuyos nombres comienzan con la cadena
prod-. - Recursos con la etiqueta
test-cluster. - Instancias de Amazon EC2 en la región A o la región B
Después de definir un grupo de recursos, puedes supervisarlo como si fuera un solo recurso. Por ejemplo, puedes configurar una verificación de tiempo de actividad para supervisar un grupo de recursos. En el caso de los gráficos y las políticas de alertas, también puedes filtrar por nombre de grupo.
Para obtener más información, consulta Configura grupos de recursos.
Supervisa las métricas de varios proyectos Google Cloud
Para ver y supervisar los datos de series temporales de variosGoogle Cloud proyectos y cuentas de AWS a través de una sola interfaz, configura un permiso de métricas de varios proyectos.
De forma predeterminada, las páginas de Cloud Monitoring en la consola de Google Cloud solo proporcionan acceso a las series temporales almacenadas en el proyecto de alcance. El proyecto de permisos es el que seleccionaste con el selector de proyectos de la consola deGoogle Cloud . El proyecto de permiso almacena las alertas, los monitores sintéticos, los paneles y los grupos de supervisión que configures.
El proyecto de permisos también aloja un permiso de métricas. El permiso de métricas define los proyectos y las cuentas cuyas métricas son visibles para el proyecto de permisos. Puedes configurar el permiso de métricas para incluir datos de series temporales de otros proyectos Google Cloud y de cuentas de AWS. Si deseas obtener información para modificar un permiso de métricas, consulta Configura un permiso de métricas para varios proyectos.
Modelo de datos de Cloud Monitoring
En esta sección, se presenta el modelo de datos de Cloud Monitoring:
Un tipo de métrica describe algo que se mide. Entre los ejemplos de tipos de métricas, se incluyen el uso de CPU de una VM y el porcentaje de un disco que se usa.
Una serie temporal es una estructura de datos que contiene mediciones de una métrica con marca de tiempo, así como información sobre la fuente y el significado de esas mediciones.
Estos son algunos detalles sobre lo que contiene una serie temporal:
El array
pointscontiene las mediciones con marca de tiempo.A continuación, se muestra un ejemplo de un array
pointscon dos valores:"points": [ { "interval": { "startTime": "2020-07-27T20:20:21.597143Z", "endTime": "2020-07-27T20:20:21.597143Z" }, "value": { "doubleValue": 0.473005 } }, { "interval": { "startTime": "2020-07-27T20:19:21.597239Z", "endTime": "2020-07-27T20:19:21.597239Z" }, "value": { "doubleValue": 0.473025 } }, ],Para comprender el significado de un valor, debes consultar los otros datos incluidos en la serie temporal y las definiciones de esos datos.
El campo
resourcedescribe el componente de hardware o software que se supervisa. En Cloud Monitoring, el componente de hardware o software se denomina recurso supervisado. Algunos ejemplos de recursos supervisados son las instancias de Compute Engine y las aplicaciones de App Engine. Para obtener una lista de los recursos supervisados, consulta la Lista de recursos supervisados.A continuación, se muestra un ejemplo de un campo
resource:"resource": { "type": "gce_instance", "labels": { "instance_id": "2708613220420473591", "zone": "us-east1-b", "project_id": "sampleproject" } }El campo
typeenumera el recurso supervisado como ungce_instance, lo que indica que estas mediciones se toman en una instancia de VM de Compute Engine.El campo
labelscontiene pares clave-valor que proporcionan información adicional sobre el recurso supervisado. Para un tipogce_instance, las etiquetas identifican la instancia de VM que se supervisa.
El campo
metricdescribe lo que se mide.A continuación, se muestra un ejemplo de un campo
metric:"metric": { "labels": { "instance_name": "test" }, "type": "compute.googleapis.com/instance/cpu/utilization" },- Para los servicios de Google Cloud , el campo
typeespecifica el servicio y lo que se supervisa. En este ejemplo, el servicio de Compute Engine mide el uso de CPU. Cuando el campotypecomienza concustomoexternal, la métrica es personalizada o está definida por un tercero.
- El campo
labelscontiene pares clave-valor que proporcionan información adicional sobre la medición. Estas etiquetas se definen como parte deMetricDescriptor, que es una estructura de datos que define los atributos de los datos medidos. ElMetricDescriptorde la métricacompute.googleapis.com/instance/cpu/utilizationincluye la etiquetainstance_name.
- Para los servicios de Google Cloud , el campo
El campo
metricKinddescribe la relación entre las mediciones adyacentes dentro de una serie temporal:Las métricas
GAUGEalmacenan el valor de lo que se mide en un momento determinado, por ejemplo, un registro de temperatura por hora.Las métricas
CUMULATIVEalmacenan el valor acumulado de lo que se mide en un momento determinado, por ejemplo, un odómetro en un vehículo.Las métricas
DELTAalmacenan el cambio en el valor de lo que se mide durante un período específico, por ejemplo, un resumen de acciones que muestra las ganancias o pérdidas de las acciones.
El campo
valueTypedescribe el tipo de datos para la medición:INT64,DOUBLE,BOOL,STRING, oDISTRIBUTION.
- Puedes mostrar el uso de CPU de cada instancia de VM.
- Puedes mostrar el uso de CPU de una instancia de VM específica si filtras la serie temporal para un solo valor de la etiqueta
instance_id. Puedes agrupar las instancias de VM por la etiqueta
machine_typey, luego, mostrar el uso promedio de CPU. En la siguiente captura de pantalla, se muestra un gráfico con esta configuración: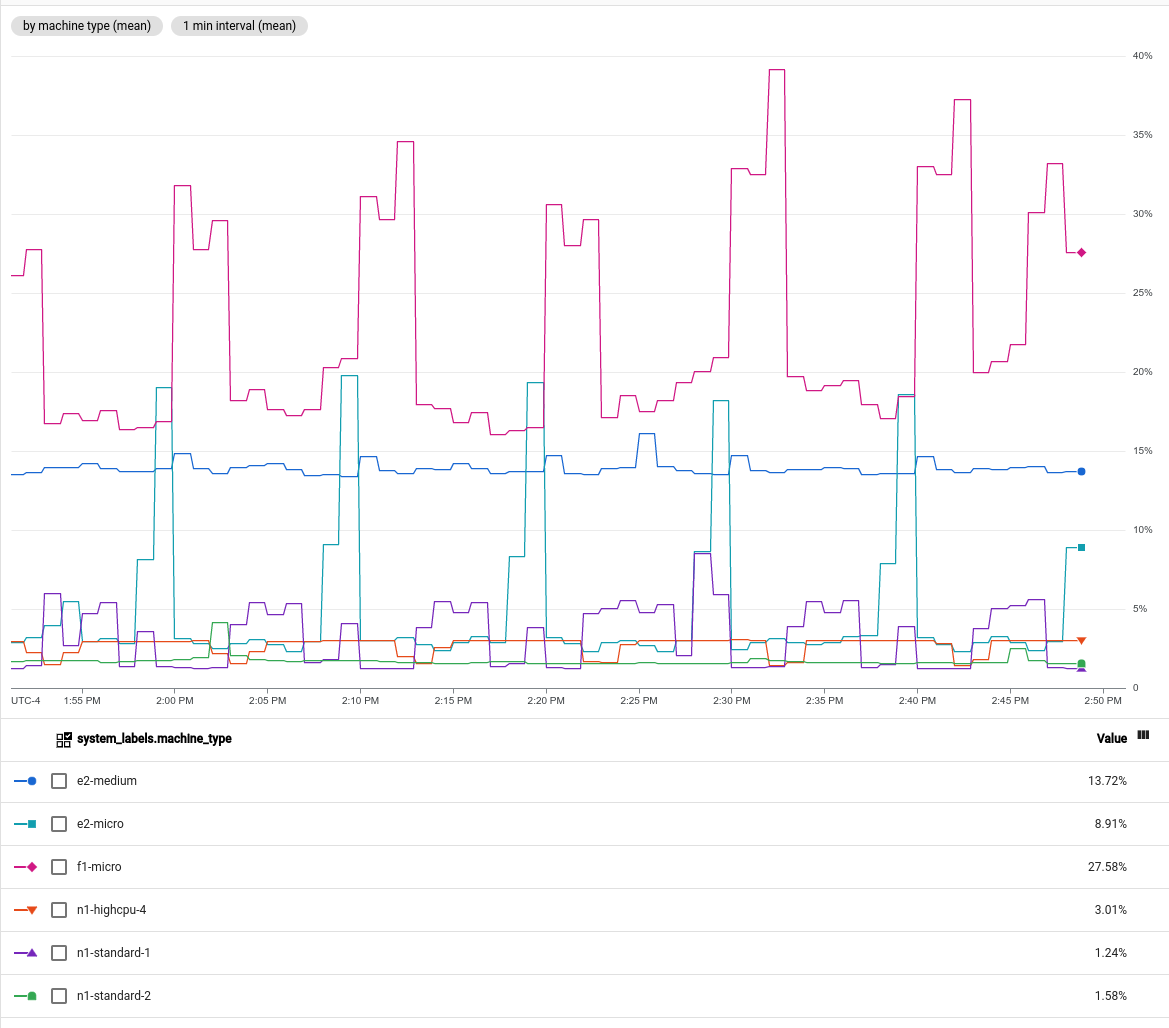
Precios
En general, las métricas del sistema de Cloud Monitoring son gratuitas, y las métricas de sistemas, agentes o aplicaciones externos no lo son. Las métricas facturables se cobran según la cantidad de bytes o la cantidad de muestras transferidas.
Para obtener más información, consulta las secciones de Cloud Monitoring en la página de precios de Google Cloud Observability.
¿Qué sigue?
- Para explorar Cloud Monitoring, prueba la Guía de inicio rápido para supervisar una instancia de Compute Engine.
- Si deseas obtener información para configurar nuestro proyecto Google Cloud para ver métricas de varios proyectos Google Cloud y cuentas de AWS, consulta la Descripción general de los permisos de métricas.
Para obtener información sobre el modelo de datos de Cloud Monitoring, consulta Métricas, series temporales y recursos.
Para obtener información sobre la API de Cloud Monitoring, consulta APIs y referencia.
Para obtener listas de métricas y recursos supervisados, consulta la lista de métricas y la lista de recursos supervisados.