本页面介绍用于处理时间序列数据的技术。本内容以指标、时间序列和资源中的概念和讨论为基础。
原始时间序列数据必须经过处理才能进行分析,而分析通常涉及过滤一些数据并将一些数据聚合在一起。本页面介绍两种主要的原始数据优化方法:
- 过滤,可从数据中移除某些数据。
- 聚合:根据您指定的维度将多段数据合并成一组较小的数据。
过滤和聚合是强大的工具,有助于识别有趣的模式,并突出显示数据中的趋势或离群值等。
本页面介绍过滤和聚合的概念。本指南不涉及如何直接应用它们。如需对时序数据应用过滤或聚合,请使用 Cloud Monitoring API 或 Google Cloud 控制台中的图表和提醒工具。如需查看示例,请参阅 API 示例政策和 Monitoring Query Language 示例。原始时间序列数据
单个时间序列中的原始指标数据量可能非常大,并且通常有许多时间序列与指标类型相关联。要分析整个数据集的共性、趋势或离群值,您必须对数据集中的时间序列进行一些处理。否则,需要考虑的数据过多。
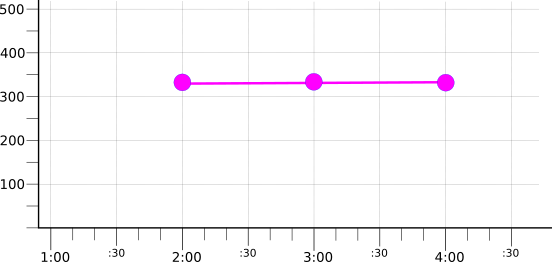
为了引入过滤和聚合,此页面上的示例使用少量虚构的时序。例如,下图显示了三个时间序列中几个小时的原始数据:
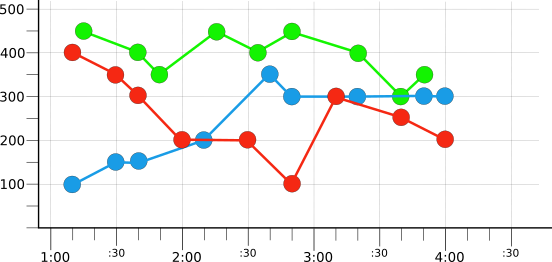
每个时间序列采用彩色,即红色、蓝色或绿色,以反映虚拟 color 标签的值。标签的每个值都有一个时间序列。请注意,这些值并没有整齐地排列,因为它们是在不同的时间记录的。
过滤
其中一项最强大的分析工具是过滤,可让您隐藏当前不感兴趣的数据。
您可以根据以下条件过滤时间序列数据:
- 时间。
- 一个或多个标签的值。
下图显示了仅显示原始时间系列的原始结果集(如图 1 所示)中的红色时间序列的过滤结果:
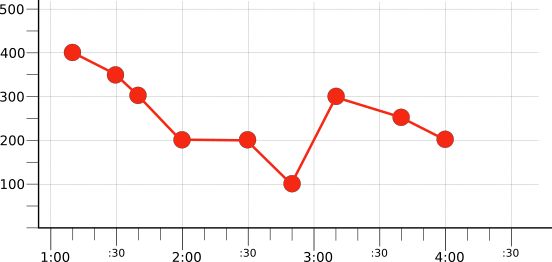
此时间序列(通过过滤选择)将在下一部分中用于演示校准。
聚合
减少数据量的另一种方法是汇总或聚合数据。 聚合有两个方面:
- 校准,或对单个时间序列中的数据进行正则化。
- 缩减或合并多个时间序列。
您必须先校准时间序列,然后才能缩减时间序列。接下来的几个部分将介绍如何使用存储整数值的时间序列来描述对齐和缩减。当时间序列具有 Distribution 值类型时,这些一般概念同样适用;不过,本例中还有其他条件限制。如需了解详情,请参阅分布值指标简介。
校准:序列内正则化
聚合时间序列数据的第一步是校准。校准会创建一个新的时间序列,其中原始数据会按时间进行正则化,以便可将其与其他时间序列合并。校准生成具有常规间隔数据的时间序列。
校准包含两个步骤:
将时间序列划分为固定的时间间隔,也称为数据分桶。该间隔称为时间段、校准时间段或校准窗口。
计算校准时间段内点的单个值。您可以选择单点的计算方式;您可以对所有值求和,计算均值或使用最大值。
由于通过校准创建的新时间序列表示原始时间序列中属于单个校准时间段的所有值,因此它也称为系列内缩减或系列内聚合。
正则化时间间隔
分析时间序列数据要求数据点在等间隔时间范围内可用。校准是实现此操作的过程。
校准会在数据点之间创建一个新的时间序列,其中包含一个固定间隔(即校准时间段)。校准通常应用于多个时间序列,以备进一步操纵。
本部分将校准步骤应用于单个时间序列,藉此说明校准步骤。在此示例中,图 2 中所示的示例时间序列应用了一小时的校准时间段。时间序列显示的是三个小时内捕获的数据。将数据点拆分为一小时的时间段会在每个时间段内产生以下点:
| 时段 | 值 |
|---|---|
| 1:01–2:00 | 400, 350, 300, 200 |
| 2:01–3:00 | 200, 100 |
| 3:01–4:00 | 300, 250, 200 |
选择校准时间段
校准时间段的时长取决于两个因素:
- 您在数据中尝试查找内容的粒度。
- 数据的采样周期;也就是报告的频率
以下几个部分详细地讨论这些因素。
此外,Cloud Monitoring 还会在有限的时间段内保留指标数据。该时间段因指标类型而异;如需了解详情,请参阅数据保留。保留期限是最有意义的校准时间段。
细化程度
如果您知道在几小时内发生了某事,并且希望深入分析,则可能需要使用一小时或一定分钟数的校准时间段。
如果您希望了解较长时间段内的趋势,则较长的校准时间段可能更合适。大型校准时间段通常不适用于了解短期异常情况。例如,如果您使用多周校准时间段,则该时间段内仍可能检测到异常,但校准数据可能过于粗略,无法提供帮助。
采样率
数据的写入频率(采样率)也会影响校准时间段的选择。如需了解内置指标的采样率,请参阅指标列表。考虑下图,其中说明了采样率为每分钟一个点的时间序列:
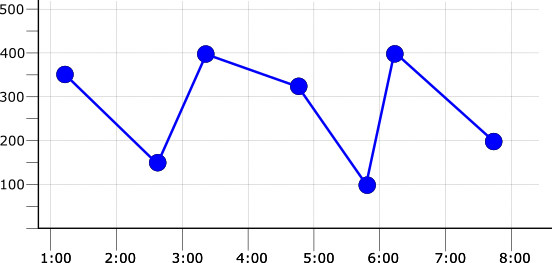
如果校准时间段与采样时间段相同,则每个校准时间段都有一个数据点。这意味着,如果应用 max、mean 或 min 校准器中的任一个,将得到相同的校准时间序列。下图显示了此结果,以及原始时间序列(表示为虚线):
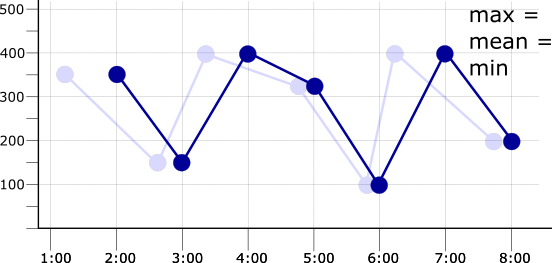
如需详细了解校准器函数的工作原理,请参阅校准器。
如果将校准时间段设置为两分钟,或是将采样时间段翻倍,则每个时间段将有两个数据点。如果将 max、mean 或 min 校准器应用于两分钟校准时间段内的点,则产生的时间序列会不同。下图显示了这些结果,以及原始时间序列(表示为虚线):
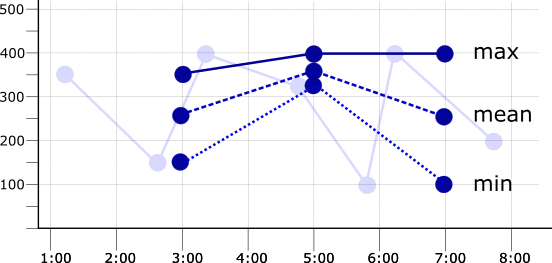
在选择校准时间段时,请使其比采样时间段长,但要足够短,以显示相关趋势。您可能需要通过实验来确定有用的校准时间段。例如,如果数据的收集速率为每天 1 个点,则一小时的校准时间段太短,不实用:对于大多数小时,将没有数据。
校准器
将数据拆分为校准时间段后,您可以选择一个函数(即校准器),以将其应用于该时间段内的数据点。校准器会在每个校准时间段结束时生成一个值。
校准选项包括对值求和,查找值的最大值、最小值或均值,找到所选的百分位值,对值进行计数,等等。Cloud Monitoring API 支持大量的校准函数,远多于此处所示的函数集;如需查看完整列表,请参阅 Aligner。如需了解转换时间序列数据的速率和增量校准器,请参阅种类、类型和转换。
例如,从原始时间序列中提取分桶数据(如图 1 中所示),请选择一个校准器并将其应用于每个分桶中的数据。下表显示了三个不同的校准器 max、mean 和 min 的原始值和结果:
| 时段 | 值 | 校准器:max | 校准器:mean | 校准器:min |
|---|---|---|---|---|
| 1:01–2:00 | 400, 350, 300, 200 | 400 | 312.5 | 200 |
| 2:01–3:00 | 200, 100 | 200 | 150 | 100 |
| 3:01–4:00 | 300, 250, 200 | 300 | 250 | 200 |
下图显示了将使用 1 小时校准时间段的 max、mean 或 min 校准器应用于原始红色时间序列的结果(以插图中的虚线表示):

其他一些校准器
下表显示了相同的原始值和其他三个校准器的结果:
- count 对校准时间段内的值数量进行计数。
- sum 会将校准时间段内的所有值相加。
- next older 使用该时间段内的最新值作为校准值。
| 时段 | 值 | 校准器:count | 校准器:sum | 校准器:next older |
|---|---|---|---|---|
| 1:01–2:00 | 400, 350, 300, 200 | 4 | 1250 | 200 |
| 2:01–3:00 | 200, 100 | 2 | 300 | 100 |
| 3:01–4:00 | 300, 250, 200 | 3 | 750 | 200 |
这些结果未显示在图表中。
缩减:合并时间序列
流程中的下一步是缩减,即将多个校准时间序列组合到新时间序列中的过程。此步骤将校准时间段范围上的所有值替换为一个值。由于它适用于不同的时间序列,因此缩减也称为跨系列聚合。
缩减器
缩减器是应用于一组时间序列中的值的函数,将生成单个值。
缩减器选项包括对已校准值求和,或查找值的最大值、最小值或均值。Cloud Monitoring API 支持大量缩减函数;如需查看完整列表,请参阅 Reducer。缩减器列表与校准器列表类似。
时间序列必须先校准,然后才能缩减。下图显示了使用 mean 校准器将所有三个原始时间序列(来自图 1)校准为 1 小时时间段的结果:
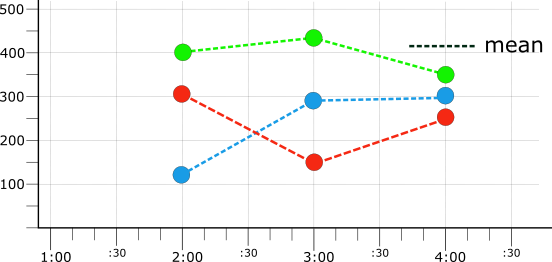
下表显示三个进行 mean 校准的时间序列的值(如图 4 中所示):
| 校准范围 | 红色 | 蓝色 | 绿色 |
|---|---|---|---|
| 2:00 | 312.5 | 133.3 | 400 |
| 3:00 | 150 | 283.3 | 433.3 |
| 4:00 | 250 | 300 | 350 |
使用上表中的校准数据,选择一个缩减器,并将其应用于这些值。下表显示了将不同的缩减器应用于 mean 校准数据的结果:
| 校准范围 | 缩减器:max | 缩减器:mean | 缩减器:min | 缩减器:sum |
|---|---|---|---|---|
| 2:00 | 400 | 281.9 | 133.3 | 845.8 |
| 3:00 | 433.3 | 288.9 | 150 | 866.7 |
| 4:00 | 350 | 300 | 250 | 900 |
默认情况下,缩减会应用到所有时间序列,从而形成单个时间序列。下图显示了将三个 mean 校准时间序列使用 max 缩减器进行聚合的结果,该缩减器将生成时间序列中的最高均值:
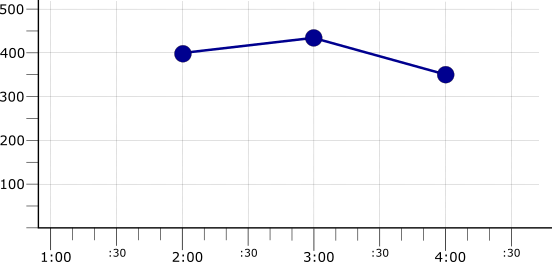
缩减还可以与分组结合,其中时间序列按类别进行组织,并且将缩减器应用于每个组中的时间序列。
分组
分组让您可将缩减器应用于时间序列的子集,而不是整个时间序列集。要对时间序列进行分组,请选择一个或多个标签。然后,系统会根据所选标签的时间序列值对时间序列进行分组。 分组将为每个组生成一个时序。
如果某个指标类型记录了 zone 和 color 标签的值,您可以按其中任一标签对时间序列进行分组。当您应用缩减器时,每个组都将缩减为单个时间序列。如果按颜色分组,则您将获得数据中表示的每种颜色的一个时间序列。如果按区域分组,您将获得数据中显示的每个区域的时间序列。如果按这两者分组,您将获得每个颜色和区域组合的时间序列。
例如,假设您使用 color 标签的“red”、“blue”和“green”值捕获了许多时间序列。校准所有时间序列后,可以按 color 值分组,然后按组进行缩减。这将生成三个特定颜色的时间序列:
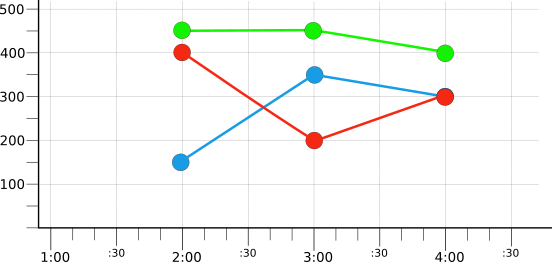
该示例未指定所用的校准器或缩减器;此处的要点是,分组让您可将大量时间序列缩减为较小的集,其中每个时间序列都表示一个共享公共属性的组:在此示例中,为 color 标签的值。
二次聚合
Cloud Monitoring 会执行两个聚合步骤。
主要聚合会先将测量数据正则化,然后使用缩减器合并正则化后的时序。使用分组时,在此步骤中执行的缩减可能会产生多个时序。
次要聚合适用于主要聚合步骤的结果,可让您使用第二个缩减器将分组的时序合并为一个结果。
下表显示了分组时间序列的值(如图 6 中所示):
| 校准范围 | 红色组 | 蓝色组 | 绿色组 |
|---|---|---|---|
| 2:00 | 400 | 150 | 450 |
| 3:00 | 200 | 350 | 450 |
| 4:00 | 300 | 300 | 400 |
然后,可以通过应用二次聚合进一步缩减这三个已缩减的时间序列。下表显示了应用所选缩减器的结果:
| 校准范围 | 缩减器:max | 缩减器:mean | 缩减器:min | 缩减器:sum |
|---|---|---|---|---|
| 2:00 | 450 | 333.3 | 150 | 1000 |
| 3:00 | 450 | 333.3 | 200 | 1000 |
| 4:00 | 400 | 333.3 | 300 | 1000 |
下图显示了将三个分组系列使用 mean 缩减器进行聚合的结果:
种类、类型和转换
回想一下,时序中的数据点以指标种类和值类型为特征;如需回顾,请参阅值类型和指标种类。适合一组数据的校准器和缩减器可能不适合另一组数据。例如,计算假值数量的校准器或缩减器适用于布尔值数据,但不适用于数字数据。同样,计算均值的校准器或缩减器适用于数字数据,但不适用于布尔值数据。
某些校准器和缩减器还可以用于显式更改时间序列中数据的指标种类或值类型。还有一些方法(如 ALIGN_COUNT)会产生负面影响。
指标种类:累积指标是每个值都表示从开始收集值以来的总计的指标。您不能直接在图表中使用累积指标,但可以使用增量指标,其中每个值代表自上次测量以来的变化。
您还可以将累积指标和增量指标转换为采样平均值指标。 例如,假设一个时间序列的增量指标如下所示:
(开始时间、结束时间](分钟) 值 (MiB) (0, 2] 8 (2, 5] 6 (6, 9] 9 假设您选择了一个
ALIGN_DELTA校准器和 3 分钟的校准时间段。由于校准时间段与每个样本(开始时间、结束时间] 都不匹配,因此系统会创建一个带内插值的时间序列。在此示例中,内插时间序列为:(开始时间、结束时间](分钟) 内插值 (MiB) (0, 1] 4 (1, 2] 4 (2, 3] 2 (3, 4] 2 (4, 5] 2 (5, 6] 0 (6, 7] 3 (7, 8] 3 (8, 9] 3 接下来,对三分钟校准时间段中的所有点进行求和,以生成校准值:
(开始时间、结束时间](分钟) 校准值 (MiB) (0, 3] 10 (3, 6] 4 (6, 9] 9 如果选择了
ALIGN_RATE,除了校准值除以校准周期外,该过程都是相同的。在此示例中,校准时间段为三分钟,因此校准的时间序列具有以下值:(开始时间、结束时间](分钟) 校准值(MiB / 秒) (0, 3] 0.056 (3, 6] 0.022 (6, 9] 0.050 如要绘制累积指标图表,必须将其转换为增量指标或费率指标。累积指标的过程类似与之前的讨论。您可以通过计算相邻字词的差值从累积时间序列计算增量时间序列。
值类型:某些校准器和缩减器会将输入数据的值类型保持不变;例如,整数数据在校准后仍为整数数据。其他校准器和缩减器会将数据从一种类型转换为另一种类型,这意味着可能会以不适合原始值类型的方式分析信息。
例如,可以将
REDUCE_COUNT缩减器应用于数字、布尔值、字符串和分布数据,但其生成的结果是 64 位整数,用于计算周期内的值数量。REDUCE_COUNT只能应用于仪表盘指标和增量指标,并且指标类型保持不变。
Aligner 和 Reducer 的参考表说明了各自适合哪些类型的数据以及产生的所有转换。 例如,以下内容显示了 ALIGN_DELTA 的条目:
