BigQuery accepte les enregistrements imbriqués dans les tables. Les enregistrements imbriqués peuvent être un seul enregistrement ou contenir des valeurs répétées. Cette page présente l'utilisation des données imbriquées BigQuery dans Looker.
Avantages des enregistrements imbriqués
L'utilisation d'enregistrements imbriqués présente plusieurs avantages lorsque vous analysez un ensemble de données distribué:
- Les enregistrements imbriqués ne nécessitent pas de jointures. Cela signifie que les calculs peuvent être plus rapides et analyser beaucoup moins de données que si vous deviez rejoindre les données supplémentaires chaque fois que vous les interrogez.
- Les structures imbriquées sont essentiellement des tables préjointes. La requête ne comporte aucune dépense supplémentaire si vous ne faites pas référence à la colonne imbriquée, car les données BigQuery sont stockées dans des colonnes. Si vous faites référence à la colonne imbriquée, la logique est identique à une jointure colocalisée.
- Les structures imbriquées évitent de répéter des données qui devraient l'être dans une table dénormalisée large. En d'autres termes, pour une personne ayant vécu dans cinq villes, une table dénormalisée large contiendrait toutes ses informations sur cinq lignes (une pour chacune des villes où elle a vécu). Dans une structure imbriquée, les informations répétées ne prennent qu'une seule ligne, car le tableau de cinq villes peut être contenu dans une seule ligne et démêlé si nécessaire.
Utiliser des enregistrements imbriqués dans LookML
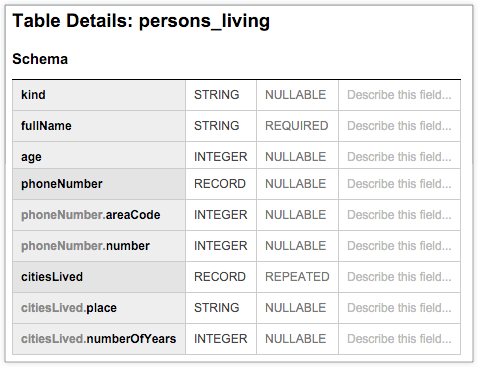
La table BigQuery suivante, persons_living, affiche un schéma type qui stocke des exemples de données utilisateur, y compris fullName, age, phoneNumber et citiesLived, ainsi que le type de données et le mode de chaque colonne. Le schéma montre que les valeurs de la colonne citiesLived sont répétées, ce qui indique que certains utilisateurs ont peut-être vécu dans plusieurs villes:
L'exemple suivant est le code LookML des explorations et des vues que vous pouvez créer à partir du schéma précédent. Il existe trois vues: persons, persons_cities_lived et persons_phone_number. L'exploration est identique à une exploration écrite avec des tables non imbriquées.
Remarque:Bien que tous les composants (vues et exploration) soient écrits dans un seul bloc de code dans l'exemple suivant, il est recommandé de placer les vues dans des fichiers de vue individuels et les explorations et la spécification connection: dans le fichier de modèle.
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Chaque composant permettant de travailler avec des données imbriquées dans LookML est décrit plus en détail dans les sections suivantes:
Vues
Chaque enregistrement imbriqué est écrit sous forme de vue. Par exemple, la vue phoneNumber déclare simplement les dimensions qui apparaissent dans l'enregistrement:
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
La vue persons_cities_lived est plus complexe. Comme indiqué dans l'exemple LookML, vous définissez les dimensions qui apparaissent dans l'enregistrement (numberOfYears et place), mais vous pouvez également définir des mesures. Les mesures et drill_fields sont définies comme d'habitude, comme si ces données se trouvaient dans leur propre table. La seule différence réelle est que vous déclarez id en tant que primary_key afin que les agrégats soient correctement calculés.
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
Enregistrer les déclarations
Dans la vue contenant les sous-enregistrements (persons dans ce cas), vous devez déclarer les enregistrements. Ils seront utilisés lorsque vous créerez les jointures. Vous pouvez masquer ces champs LookML avec le paramètre hidden, car vous n'en avez pas besoin lorsque vous explorez les données.
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
Jointures
Les enregistrements imbriqués dans BigQuery sont des tableaux d'éléments STRUCT. Au lieu de la jointure avec un paramètre sql_on, la relation de jointure est intégrée à la table. Dans ce cas, vous pouvez utiliser le paramètre de jointure sql: pour pouvoir utiliser l'opérateur UNNEST. En dehors de cette différence, le désimbrication d'un tableau d'éléments STRUCT est exactement comme la jointure d'une table.
Pour les enregistrements non répétés, vous pouvez simplement utiliser STRUCT. Vous pouvez le transformer en tableau d'éléments STRUCT en le plaçant entre crochets. Bien que cela puisse sembler étrange, il semble qu'il n'y ait pas de pénalité de performances, ce qui permet de garder les choses simples.
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
Jointures pour les tableaux sans clés uniques pour chaque ligne
Il est préférable d'utiliser des clés naturelles identifiables dans les données ou des clés fictives créées lors du processus ETL, mais ce n'est pas toujours possible. Par exemple, il se peut que certains tableaux ne disposent pas d'une clé unique relative pour la ligne. C'est là que WITH OFFSET peut s'avérer utile dans la syntaxe de jointure.
Par exemple, une colonne représentant une personne peut se charger plusieurs fois si cette personne a vécu dans plusieurs villes (Chicago, Denver, San Francisco, etc.). Il peut être difficile de créer une clé primaire sur la ligne non imbriquée si aucune date ou autre clé naturelle identifiable n'est fournie pour distinguer la durée de séjour de la personne dans chaque ville. C'est là que WITH OFFSET peut fournir un numéro de ligne relatif (0,1,2,3) pour chaque ligne non imbriquée. Cette approche garantit une clé unique sur la ligne non imbriquée:
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
Valeurs répétées simples
Les données imbriquées dans BigQuery peuvent également être des valeurs simples, telles que des nombres entiers ou des chaînes. Pour dissocier des tableaux de valeurs répétées simples, vous pouvez utiliser une approche similaire à celle présentée précédemment, à l'aide de l'opérateur UNNEST dans une jointure.
L'exemple suivant décompose un tableau d'entiers donné, "unresolved_skus" :
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
Le paramètre sql du tableau d'entiers, unresolved_skus, est représenté par ${TABLE}. Cela fait directement référence au tableau de valeurs lui-même, qui est ensuite désimbriqué dans explore.