커스텀 필드를 만들 수 있는 권한이 있으면, Looker 표현식에서 논리 함수를 사용하거나sql파라미터 또는type: case필드에CASE WHEN논리를 개발하지 않고도 측정기준에 대해 임시 커스텀 그룹을 만들 수 있습니다.
또한 커스텀 필드를 만들 수 있는 권한이 있는 경우 Looker 표현식에서 논리 함수를 사용하거나 type: tier LookML 필드를 개발할 필요 없이 숫자 유형 측정기준에 대해 임시 커스텀 구간을 만들 수도 있습니다.
버킷팅은 Looker에서 커스텀 그룹화 측정기준을 만드는 데 매우 유용할 수 있습니다.
Looker에서 버킷을 만드는 방법에는 세 가지가 있습니다.
버케팅에 tier 사용
정수 버킷을 만들려면 dimension 유형을 tier로 정의하면 됩니다.
dimension: users_lifetime_orders_tier {
type: tier
tiers: [0,1,2,5,10]
sql: ${users_lifetime_orders} ;;
}
style 파라미터를 사용하여 탐색 시 등급이 표시되는 방식을 맞춤설정할 수 있습니다. style의 네 가지 옵션은 다음과 같습니다.
예를 들면 다음과 같습니다.
dimension: age_tier {
type: tier
tiers: [0,10,20,30,40,50,60,70,80]
style: integer
sql: ${age} ;;
}
style 매개변수 classic이 기본값이며 Tx[x,x] 형식을 사용합니다. Tx는 등급 번호, [x,x]는 범위를 나타냅니다. 다음 이미지는 사용자 연령별로 그룹화된 사용자 수가 있는 Explore 데이터 테이블입니다.
![데이터 테이블에서 최상위 사용자 연령 등급은 T02[10,20] 이며, 10~20세의 사용자 808명을 나타냅니다.](https://cloud.google.com/static/looker/docs/images/bucketing-in-looker-1-2210.png?hl=ko)
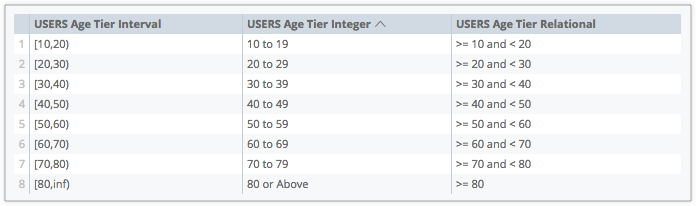
다음 이미지는 다른 style 파라미터 옵션의 예시를 보여줍니다.
-
interval- 등급의 최솟값 및 최댓값을 나타내는[x,x]형식 사용 -
integer- 등급의 최솟값 및 최댓값을 나타내는x to x형식 사용 -
relational- 값이 가장 낮은 등급 값보다 크거나 같고 가장 높은 등급 값보다 작음을 나타내는>= x and <x형식 사용
고려사항
tier를 측정기준 채우기와 함께 사용하면 예기치 않은 등급 버킷이 생성될 수 있습니다.
예를 들어 type: tier 측정기준인 연령 등급은 측정기준 채우기가 사용 설정된 경우 해당 버킷의 연령 값이 데이터에 포함되지 않더라도 0 미만 및 0~9에 대한 등급 버킷을 표시합니다.

연령 등급에 측정기준 채우기가 사용 중지되면 10~19 버킷부터 시작하여 버킷에 사용 가능한 연령 값이 더 정확하게 데이터에 반영됩니다.

측정기준 채우기를 사용 설정하거나 사용 중지할 수 있는데, 사용 중지하려면 Explore에서 측정기준 이름 위로 마우스를 가져가서 필드 수준의 톱니바퀴 아이콘을 클릭한 다음 채워진 등급 값 삭제를 선택하고, 사용 설정하려면 누락된 등급 값 채우기를 선택합니다.
측정기준, 필터, 파라미터 유형 문서 페이지에서 Looker tiers에 대해 자세히 알아보세요.
버케팅에 case 사용
case 매개변수를 사용하여 커스텀 정렬된 커스텀 이름의 버킷을 만들 수 있습니다. case 매개변수는 UI 필터 및 시각화에서 값의 표시, 정렬, 사용 방법을 제어하는 데 도움이 되므로 고정된 버킷 집합에 사용하는 것이 좋습니다. 예를 들어 case를 사용하면 사용자는 필터에서 정의된 버킷 값만 선택할 수 있습니다.
case로 버킷을 만들려면 주문 금액의 버킷과 같은 측정기준을 정의하면 됩니다.
dimension: order_amount_bucket {
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
case 파라미터는 일반적으로 버킷이 나열된 순서대로 값을 정렬합니다. order_amount_bucket 측정기준에서 버킷 순서는 Small, Medium, Large입니다.

영숫자로 정렬하려면 다음과 같이 측정기준에 alpha_sort 파라미터를 추가합니다.
dimension: order_amount_bucket {
alpha_sort: yes
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
출력에서 고유한 값이 많이 필요한 측정기준의 경우(WHEN 또는 ELSE 문으로 각 출력을 정의해야 함) 또는 더 복잡한 ELSE 문을 구현하려는 경우 다음 섹션에서 설명된 SQL CASE WHEN를 사용하는 것이 좋습니다.
필드 파라미터 문서 페이지에서 case 파라미터에 대해 자세히 알아보세요.
버킷팅에 SQL CASE WHEN 사용
더 복잡한 버킷팅이나 더 미묘한 ELSE 문을 구현하는 경우 SQL CASE WHEN 문을 사용하는 것이 좋습니다.
예를 들어 주문 목적지에 따라 다른 버케팅 방법을 사용할 수 있습니다. 복합 버킷 측정기준을 만들려면 SQL CASE WHEN 문을 사용할 수 있으며 여기서 THEN 문은 문자열이 아닌 측정기준을 반환합니다.
dimension: compound_buckets {
sql:
CASE
WHEN ${orders.destination} = 'US' THEN ${us_buckets}
WHEN ${orders.destination} = 'CA' THEN ${canada_buckets}
ELSE ${intl_buckets}
END ;;
}