Se disponi dell'autorizzazione per creare campi personalizzati, puoi creare gruppi personalizzati ad hoc per le dimensioni senza utilizzare funzioni logiche nelle espressioni di Looker o sviluppare la logicaCASE WHENnei parametrisqlo nei campitype: case.
Se disponi dell'autorizzazione per creare campi personalizzati, puoi anche creare bin personalizzati ad hoc per le dimensioni di tipo numerico senza dover utilizzare funzioni logiche nelle espressioni di Looker o dover sviluppare campi type: tier di LookML.
La suddivisione in bucket può essere molto utile per creare dimensioni di raggruppamento personalizzate in Looker.
Esistono tre modi per creare bucket in Looker:
- Utilizzo del tipo
dimensiontier - Utilizzo del parametro
case - Utilizzo di un'istruzione
CASE WHENSQL nel parametroSQLdi un campo LookML
Utilizzo di tier per il bucketing
Per creare bucket di interi, possiamo semplicemente definire il tipo dimension come tier:
dimension: users_lifetime_orders_tier {
type: tier
tiers: [0,1,2,5,10]
sql: ${users_lifetime_orders} ;;
}
Puoi utilizzare il parametro style per personalizzare la visualizzazione dei livelli durante l'esplorazione. Le quattro opzioni per style sono le seguenti:
Ad esempio:
dimension: age_tier {
type: tier
tiers: [0,10,20,30,40,50,60,70,80]
style: integer
sql: ${age} ;;
}
Il parametro style classic è predefinito e ha il formato Tx[x,x], dove Tx indica il numero del livello e [x,x] indica l'intervallo. L'immagine seguente mostra una tabella di dati di esplorazione con Conteggio utenti raggruppato per Età utenti:
![Il livello di età degli utenti più alto disponibile nella tabella di dati è T02[10,20] e indica un conteggio di 808 utenti di età compresa tra 10 e 20 anni.](https://cloud.google.com/static/looker/docs/images/bucketing-in-looker-1-2210.png?hl=it)
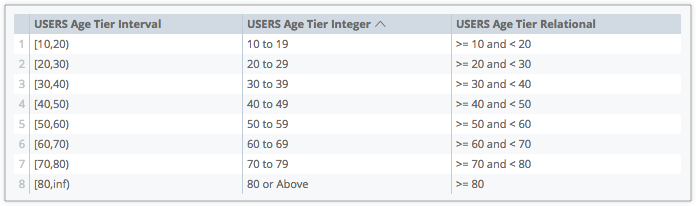
L'immagine seguente mostra esempi delle altre opzioni del parametro style:
-
interval: con il formato[x,x], che indica il valore più basso e il valore più alto di un livello -
integer: con il formatox to x, che indica il valore più basso e il valore più alto di un livello -
relational: con il formato>= x and <x, indica che un valore è maggiore o uguale al valore del livello più basso e minore del valore del livello più alto
Aspetti da considerare
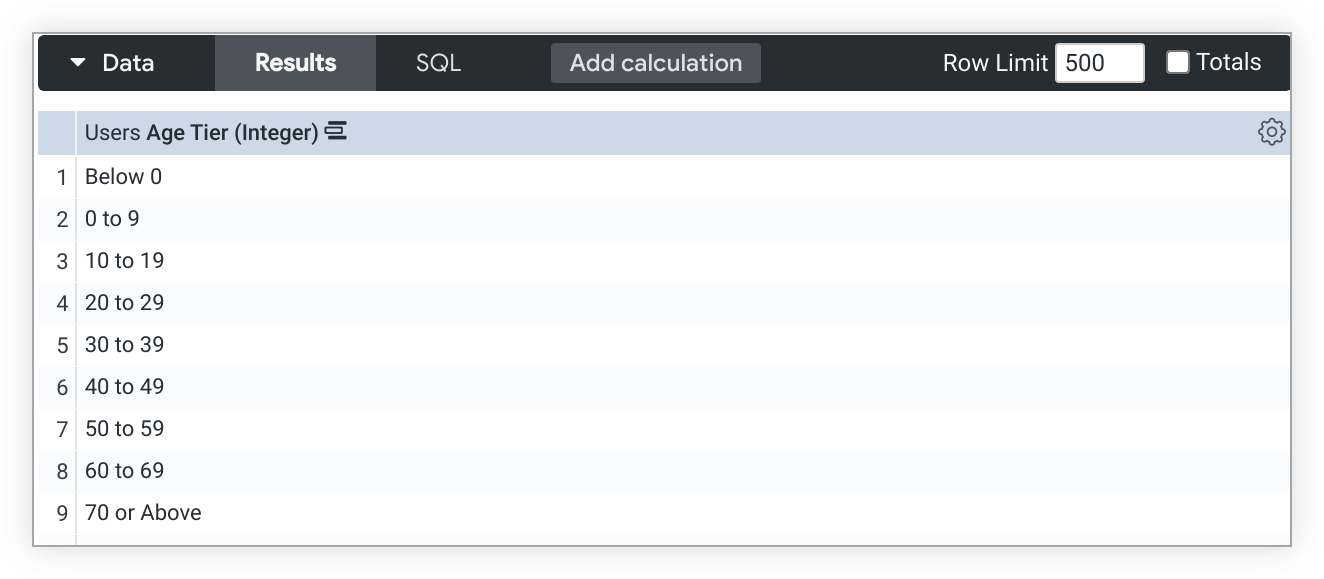
L'utilizzo di tier in combinazione con il riempimento delle dimensioni può comportare la creazione di bucket di livello imprevisti.
Ad esempio, una dimensione type: tier, Fascia d'età, mostrerà i bucket di fascia per Meno di 0 e 0-9 quando il completamento delle dimensioni è abilitato, anche se i dati non includono i valori di età per questi bucket:
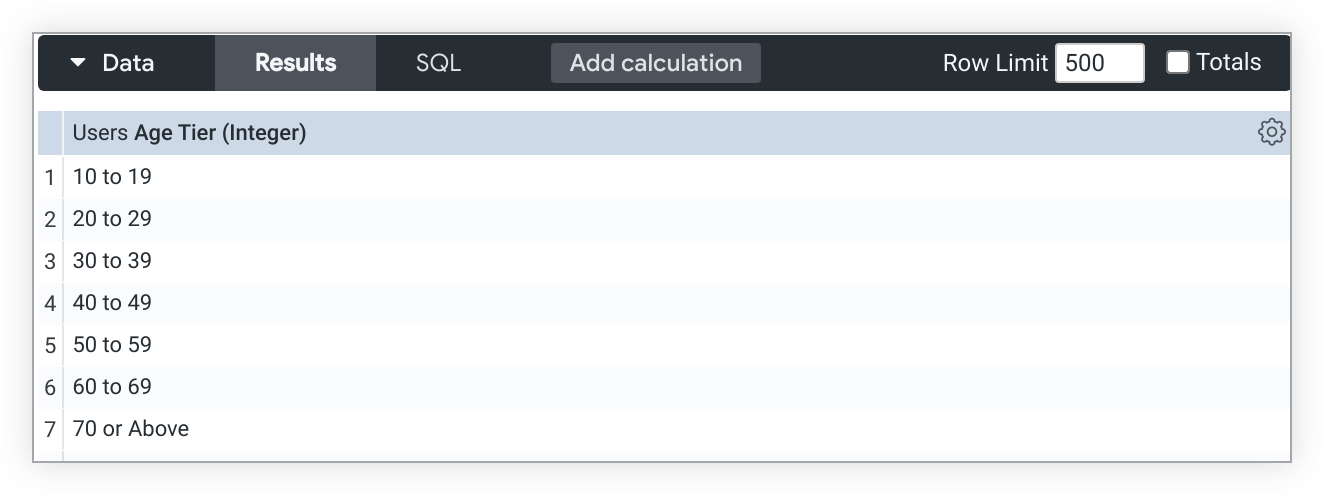
Quando il completamento delle dimensioni è disattivato per Fascia d'età, i bucket riflettono in modo più accurato i valori di età disponibili nei dati, a partire dal bucket 10-19:
Puoi attivare o disattivare il completamento delle dimensioni passando il mouse sopra il nome della dimensione nell'esplorazione, facendo clic sull'icona a forma di ingranaggio a livello di campo e selezionando Rimuovi valori di livello compilati per disattivare o Completa valori di livello mancanti per attivare.
Scopri di più su Looker tiers nella pagina della documentazione Tipi di dimensioni, filtri e parametri.
Utilizzo di case per il bucketing
Puoi utilizzare il parametro case per creare bucket con nomi personalizzati e ordinamento personalizzato. Il parametro case è consigliato per un insieme fisso di bucket, in quanto può aiutarti a controllare il modo in cui i valori vengono presentati, ordinati e utilizzati nei filtri e nelle visualizzazioni dell'interfaccia utente. Ad esempio, con case, un utente potrà selezionare solo i valori del bucket definiti in un filtro.
Per creare bucket con case, puoi definire una dimensione, ad esempio un bucket per gli importi degli ordini:
dimension: order_amount_bucket {
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
In genere, il parametro case ordina i valori nell'ordine in cui sono elencati i bucket. Per la dimensione order_amount_bucket, l'ordine dei bucket è Piccolo, Medio e Grande:

Se vuoi ordinare in ordine alfabetico, aggiungi il parametro alpha_sort alla dimensione, come segue:
dimension: order_amount_bucket {
alpha_sort: yes
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
Per le dimensioni in cui sono necessari molti valori distinti nell'output (questo richiederebbe di definire ogni output con un'istruzione WHEN o ELSE) o quando vuoi implementare un'istruzione ELSE più complessa, ti consigliamo di utilizzare un CASE WHEN SQL, descritto nella sezione successiva.
Scopri di più sul parametro case nella pagina della documentazione Parametri di campo.
Utilizzo di SQL CASE WHEN per il bucketing
Un'istruzione CASE WHEN SQL è consigliata per un raggruppamento più complesso o per l'implementazione di un'istruzione CASE WHEN più sfumata.ELSE
Ad esempio, potresti voler utilizzare metodi di raggruppamento diversi a seconda della destinazione di un ordine. Un'istruzione SQL CASE WHEN potrebbe essere utilizzata per creare una dimensione del bucket composta, in cui l'istruzione THEN restituisce dimensioni anziché stringhe:
dimension: compound_buckets {
sql:
CASE
WHEN ${orders.destination} = 'US' THEN ${us_buckets}
WHEN ${orders.destination} = 'CA' THEN ${canada_buckets}
ELSE ${intl_buckets}
END ;;
}