Si vous disposez de l'autorisation de créer des champs personnalisés, vous pouvez créer des groupes personnalisés ad hoc pour les dimensions sans utiliser de fonctions logiques dans les expressions Looker ni développer de logiqueCASE WHENdans les paramètressqlou les champstype: case.
Vous pouvez également créer des bins personnalisés ad hoc pour les dimensions de type numérique sans avoir à utiliser de fonctions logiques dans les expressions Looker ni à développer des champs LookML type: tier lorsque vous êtes autorisé à créer des champs personnalisés.
Le bucketing peut être très utile pour créer des dimensions de regroupement personnalisées dans Looker.
Il existe trois façons de créer des buckets dans Looker:
- Utiliser le type
dimensiontier - Utiliser le paramètre
case - Utiliser une instruction
CASE WHENSQL dans le paramètreSQLd'un champ LookML
Utiliser tier pour le bucketing
Pour créer des buckets d'entiers, nous pouvons simplement définir le type dimension comme tier:
dimension: users_lifetime_orders_tier {
type: tier
tiers: [0,1,2,5,10]
sql: ${users_lifetime_orders} ;;
}
Vous pouvez utiliser le paramètre style pour personnaliser l'affichage de vos niveaux lors de l'exploration. Les quatre options possibles pour style sont les suivantes:
Exemple :
dimension: age_tier {
type: tier
tiers: [0,10,20,30,40,50,60,70,80]
style: integer
sql: ${age} ;;
}
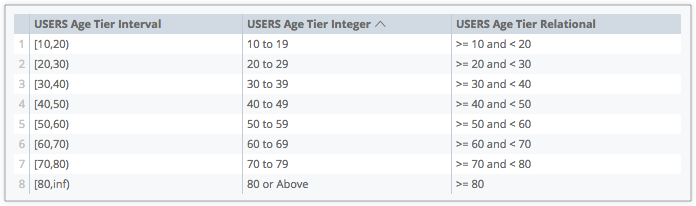
Le paramètre style classic est défini par défaut et utilise le format Tx[x,x], avec Tx indiquant le numéro de niveau et [x,x] indiquant la plage. L'image suivante est un tableau de données Explorer dans lequel le nombre d'utilisateurs est regroupé par âge des utilisateurs:
![Le niveau d'âge des utilisateurs le plus élevé disponible dans le tableau de données est T02[10,20], qui indique 808 utilisateurs âgés de 10 à 20 ans.](https://cloud.google.com/static/looker/docs/images/bucketing-in-looker-1-2210.png?hl=fr)
L'image suivante montre des exemples des autres options de paramètre style:
-
interval: au format[x,x], qui indique la valeur la plus basse et la valeur la plus élevée d'un niveau -
integer: au formatx to x, qui indique la valeur la plus basse et la valeur la plus élevée d'un niveau -
relational: au format>= x and <x, ce qui indique qu'une valeur est supérieure ou égale à la valeur du niveau le plus bas et inférieure à la valeur du niveau le plus élevé
Éléments à prendre en compte
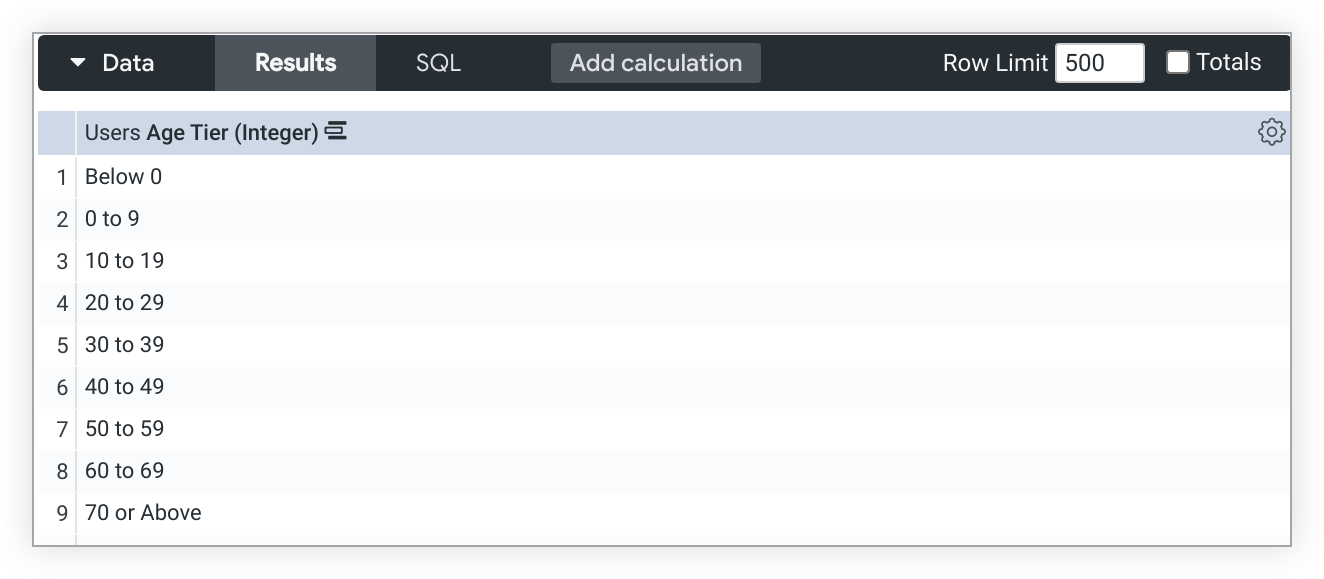
L'utilisation de tier avec le remplissage de dimension peut entraîner des buckets de niveau inattendus.
Par exemple, une dimension type: tier, Tranche d'âge, affiche des buckets de tranche pour Moins de 0 et 0 à 9 lorsque le remplissage de la dimension est activé, même si les données n'incluent pas de valeurs d'âge pour ces buckets:
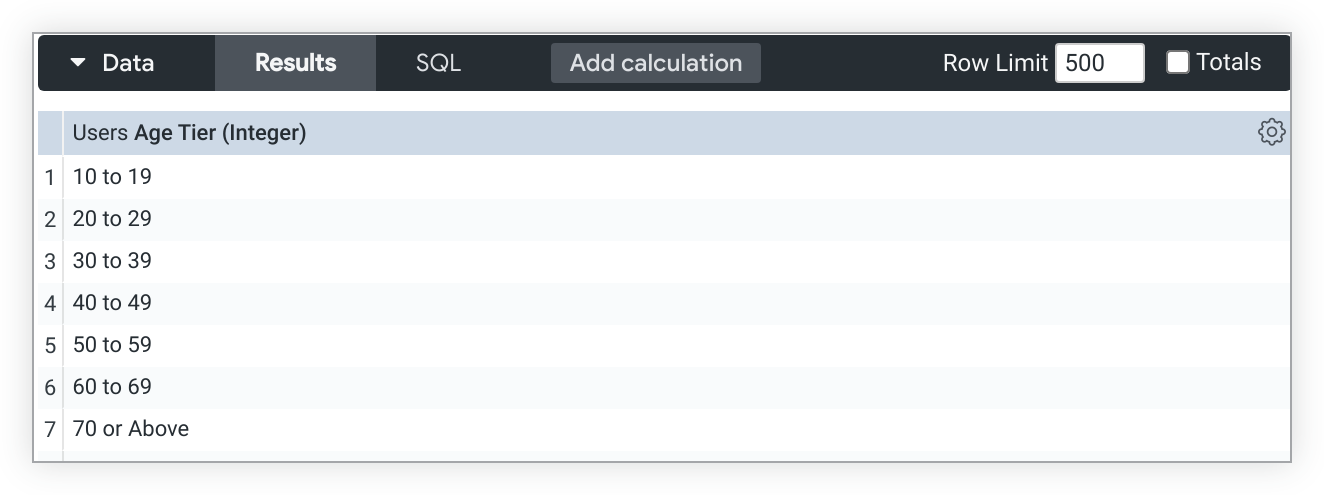
Lorsque le remplissage de la dimension est désactivé pour Catégorie d'âge, les buckets reflètent plus précisément les valeurs d'âge disponibles dans les données, à commencer par le bucket 10 à 19:
Pour activer ou désactiver le remplissage des dimensions, pointez sur le nom de la dimension dans l'exploration, cliquez sur l'icône en forme de roue dentée au niveau du champ, puis sélectionnez Supprimer les valeurs de niveau remplies pour désactiver la fonctionnalité ou Remplir les valeurs de niveau manquantes pour l'activer.
Pour en savoir plus sur tiers dans Looker, consultez la page de documentation Types de dimensions, de filtres et de paramètres.
Utiliser case pour le bucketing
Vous pouvez utiliser le paramètre case pour créer des buckets nommés de manière personnalisée avec un tri personnalisé. Le paramètre case est recommandé pour un ensemble fixe de buckets, car il peut aider à contrôler la façon dont les valeurs sont présentées, triées et utilisées dans les filtres et les visualisations de l'UI. Par exemple, avec case, un utilisateur ne peut sélectionner que les valeurs de bucket définies dans un filtre.
Pour créer des buckets avec case, vous pouvez définir une dimension, comme un bucket pour les montants des commandes:
dimension: order_amount_bucket {
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
En règle générale, le paramètre case trie les valeurs dans l'ordre dans lequel les buckets sont listés. Pour la dimension order_amount_bucket, l'ordre des buckets est Petit, Moyen et Grand:

Si vous souhaitez trier alphanumériquement, ajoutez le paramètre alpha_sort à la dimension, comme suit:
dimension: order_amount_bucket {
alpha_sort: yes
case: {
when: {
sql: ${order_amount} <= 50;;
label: "Small"
}
when: {
sql: ${order_amount} > 50 AND ${order_amount} <= 150;;
label: "Medium"
}
when: {
sql: ${order_amount} > 150;;
label: "Large"
}
else:"Unknown"
}
}
Pour les dimensions pour lesquelles vous souhaitez obtenir de nombreuses valeurs distinctes dans la sortie (ce qui vous obligerait à définir chaque sortie avec une instruction WHEN ou ELSE), ou lorsque vous souhaitez implémenter une instruction ELSE plus complexe, nous vous recommandons d'utiliser une CASE WHEN SQL, qui sera abordée dans la section suivante.
Pour en savoir plus sur le paramètre case, consultez la page de documentation Paramètres de champ.
Utiliser SQL CASE WHEN pour le bucketing
Une instruction SQL CASE WHEN est recommandée pour un bucketing plus complexe ou pour implémenter une instruction ELSE plus nuancée.
Par exemple, vous pouvez utiliser différentes méthodes de regroupement en fonction de la destination d'une commande. Vous pouvez utiliser une instruction SQL CASE WHEN pour créer une dimension de bucket composée, où l'instruction THEN renvoie des dimensions plutôt que des chaînes:
dimension: compound_buckets {
sql:
CASE
WHEN ${orders.destination} = 'US' THEN ${us_buckets}
WHEN ${orders.destination} = 'CA' THEN ${canada_buckets}
ELSE ${intl_buckets}
END ;;
}