Cette page explore les modèles d'architecture les plus courants pour un déploiement hébergé par le client et décrit les bonnes pratiques pour les implémenter. Pour utiliser efficacement cette page, vous devez connaître les concepts et les pratiques liés à l'architecture système.
Stratégie de workflow
Une fois que vous avez identifié l'auto-hébergement comme une option viable pour votre implémentation de Looker, l'étape suivante consiste à élaborer la stratégie à suivre pour le déploiement.
- Effectuez une évaluation. Identifiez une liste de workflows planifiés et existants.
- Listez les modèles d'architecture applicables. En commençant par les workflows candidats identifiés, identifiez les modèles d'architecture applicables.
- Priorisez et sélectionnez le modèle d'architecture optimal. Alignez le modèle d'architecture sur les tâches et les résultats les plus importants.
- Configurez les composants architecturaux et déployez l'application Looker. Implémentez l'hôte, les dépendances tierces et la topologie du réseau nécessaires pour établir des connexions client sécurisées.
Options d'architecture
Machine virtuelle dédiée
Une option consiste à exécuter Looker en tant qu'instance unique dans une machine virtuelle (VM) dédiée. Une même instance peut gérer des charges de travail exigeantes en effectuant un scaling vertical de l'hôte et en augmentant les pools de threads par défaut. Toutefois, la surcharge de traitement liée à la gestion d'un grand tas Java soumet le scaling vertical à la loi des rendements décroissants. Elle est généralement acceptable pour les charges de travail de petite à moyenne taille. Le schéma suivant illustre les configurations par défaut et facultatives entre une instance Looker exécutée dans une VM dédiée, les dépôts locaux et distants, les serveurs SMTP et les sources de données qui sont mis en évidence dans les sections Avantages et Bonnes pratiques pour cette option.
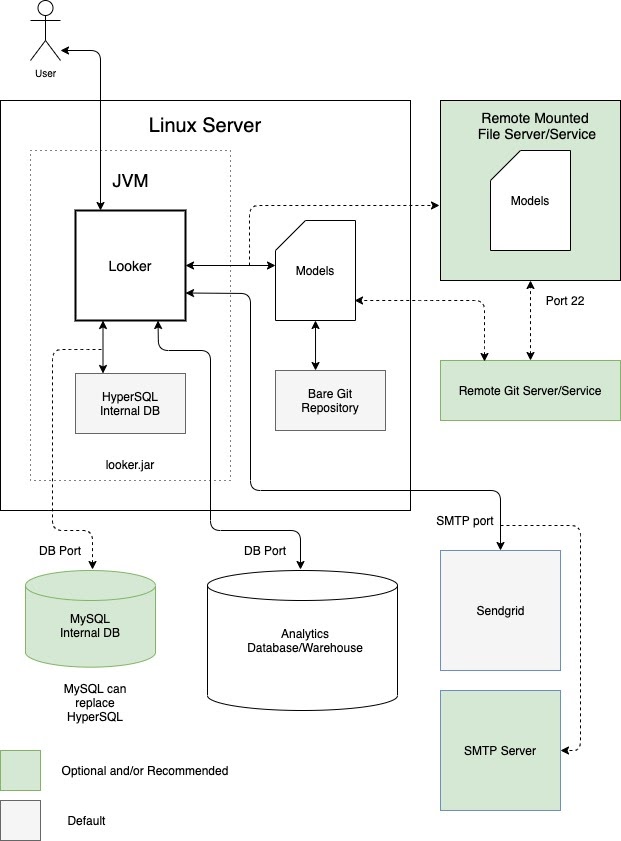
Avantages
- Une VM dédiée est facile à déployer et à gérer.
- La base de données interne est hébergée dans l'application Looker.
- Les composants des modèles Looker, du dépôt Git, du serveur SMTP et de la base de données backend peuvent être configurés localement ou à distance.
- Vous pouvez remplacer le serveur SMTP par défaut de Looker par le vôtre pour les notifications par e-mail et les tâches planifiées.
Bonnes pratiques
- Par défaut, Looker peut générer des dépôts Git nus pour un projet. Nous vous recommandons de configurer un dépôt Git distant pour la redondance.
-
Par défaut, Looker démarre avec une base de données HyperSQL en mémoire. Cette base de données est pratique et légère, mais peut rencontrer des problèmes de performances en cas d'utilisation intensive. Nous recommandons l'utilisation d'une base de données MySQL pour les déploiements plus importants. Nous vous recommandons de migrer vers une base de données MySQL distante une fois que le fichier
~/looker/.db/looker.scriptatteint 600 Mo. - Votre déploiement Looker devra être validé par le service de gestion des licences Looker. Le trafic sortant sur le port 443 est requis.
- Un déploiement de VM dédié peut être mis à l'échelle verticalement en augmentant les ressources disponibles et les pools de threads Looker. Toutefois, l'augmentation de la RAM est soumise à la loi des rendements décroissants une fois qu'elle atteint 64 Go, car les événements de récupération de mémoire sont monothread et interrompent tous les autres threads pour s'exécuter. Les nœuds dotés de 16 processeurs et de 64 Go de RAM offrent un bon équilibre entre prix et performances.
- Nous vous recommandons de déployer un stockage avec 2 opérations par seconde (IOPS) par Go.
Cluster de VM
L'exécution de Looker en tant que cluster d'instances sur plusieurs VM est un modèle flexible qui bénéficie du basculement et de la redondance des services. La scalabilité horizontale permet d'augmenter le débit sans entraîner de gonflement du tas ni de coûts excessifs de collecte des déchets. Les nœuds peuvent être dédiés à une charge de travail, ce qui permet d'adapter plusieurs options de déploiement à différents besoins commerciaux. Les déploiements de clusters nécessitent au moins un administrateur système connaissant les systèmes Linux et capable de gérer les composants.
Cluster standard
Pour la plupart des déploiements standards, un cluster de nœuds de service identiques est suffisant. Tous les nœuds du cluster sont configurés de la même manière et se trouvent dans le même pool d'équilibrage de charge. Dans cette configuration, aucun nœud n'est plus ou moins susceptible de répondre aux demandes des utilisateurs Looker, d'effectuer une tâche de rendu ou planifiée, de traiter une requête d'API, etc.
Ce type de configuration convient lorsque la majorité des requêtes proviennent directement d'un utilisateur Looker qui exécute des requêtes et interagit avec Looker. Il commence à se décomposer lorsqu'un grand nombre de requêtes proviennent d'un planificateur, d'un moteur de rendu ou d'une autre source. Dans ce cas, il est avantageux de désigner certains nœuds de service pour gérer des tâches telles que les plannings et le rendu.
Par exemple, les utilisateurs planifient souvent l'exécution des livraisons de données le lundi matin. Un utilisateur qui tente d'exécuter des requêtes Looker le lundi matin peut rencontrer des problèmes de performances pendant que Looker traite le backlog de requêtes planifiées. En augmentant le nombre de nœuds de service, le cluster fournit une augmentation proportionnelle du débit pour toutes les fonctionnalités de Looker.
Le schéma suivant montre comment les requêtes adressées à Looker par les utilisateurs, les applications et les scripts sont réparties sur une instance Looker en cluster.
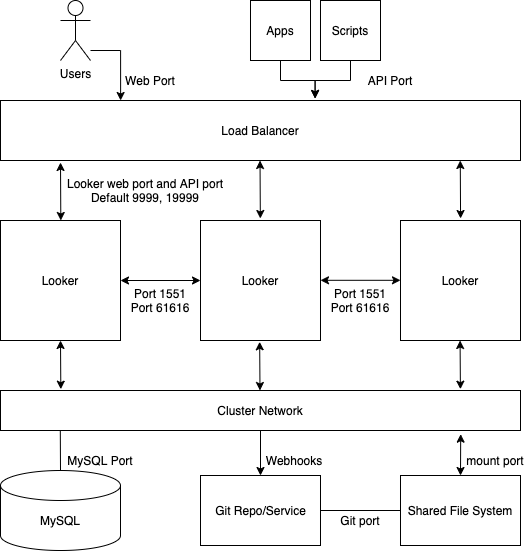
Avantages
- Un cluster standard maximise le débit général avec une configuration minimale de la topologie du cluster.
- Les performances de la JVM se dégradent au seuil de mémoire allouée de 64 Go. C'est pourquoi le scaling horizontal est plus intéressant que le scaling vertical.
- Une configuration de cluster assure la redondance et le basculement des services.
Bonnes pratiques
- Chaque nœud Looker doit être hébergé dans sa propre VM dédiée.
- L'équilibreur de charge, qui est le point d'entrée du cluster, doit être un équilibreur de charge de couche 4. Il doit disposer d'un délai d'attente long (3 600 secondes), être équipé d'un certificat SSL signé et être configuré pour transférer le port 443 (https) vers le port 9999 (port sur lequel le serveur Looker écoute).
- Nous vous recommandons de prévoir un espace de stockage de 2 IOPS par Go pour votre déploiement.
Développement/Préproduction/Production
Pour les cas d'utilisation qui privilégient la disponibilité maximale du contenu pour les utilisateurs finaux, nous recommandons des environnements Looker distincts pour compartimenter le travail de développement et le travail analytique. En limitant les modifications de l'environnement de production derrière des environnements de développement et de test isolés, cette architecture maintient un environnement de production aussi stable que possible.
Pour bénéficier de ces avantages, vous devez configurer les environnements interconnectés et adopter un cycle de publication robuste. Un déploiement Dev/Staging/Prod nécessite également une équipe de développeurs connaissant l'API Looker et Git pour l'administration des workflows.
Le schéma suivant illustre le flux de contenu entre les développeurs LookML qui développent du contenu sur l'instance de développement, les testeurs d'assurance qualité (QA) qui testent le contenu sur l'instance QA, et les utilisateurs, applications et scripts qui consomment le contenu sur l'instance de production.
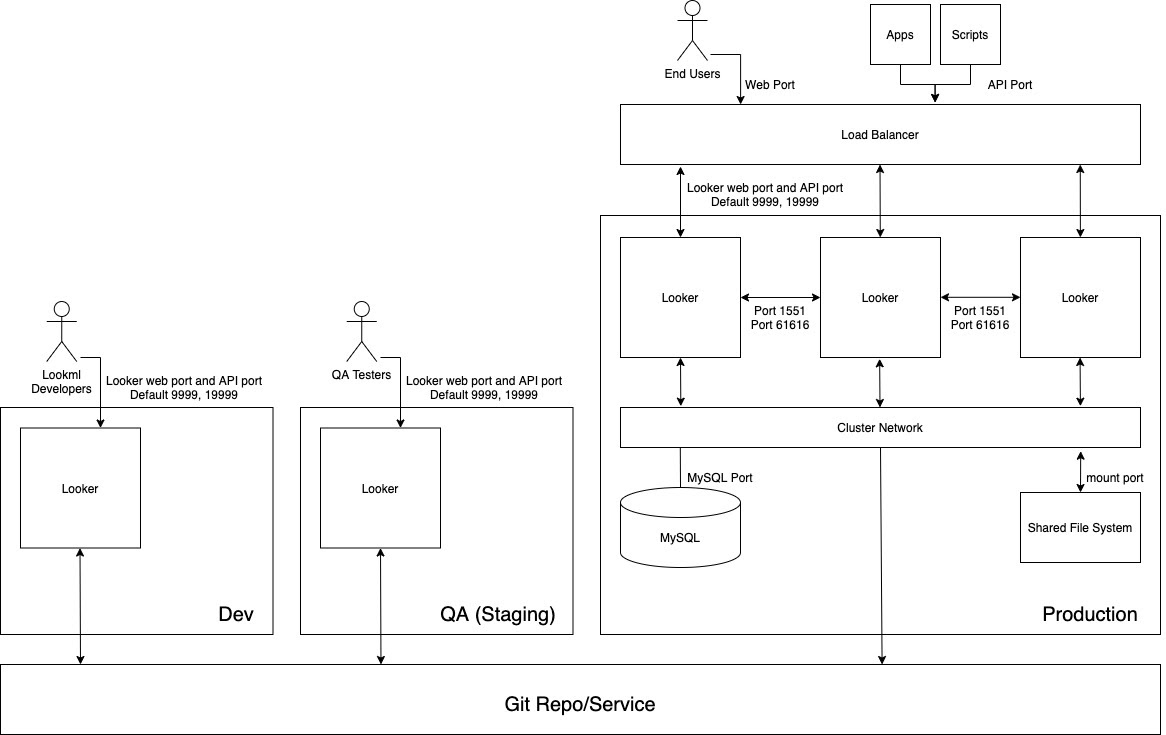
Avantages
- La validation du code LookML et du contenu s'effectue dans un environnement hors production, ce qui permet de vérifier minutieusement toute modification apportée à la logique du modèle avant qu'elle ne soit accessible aux utilisateurs en production.
- Les fonctionnalités à l'échelle de l'instance, telles que les fonctionnalités Labs ou les protocoles d'authentification, peuvent être testées de manière isolée avant d'être activées dans l'environnement de production.
- Les groupes de données et les règles de mise en cache peuvent être testés dans un environnement hors production.
- Les tests du mode Production de Looker sont dissociés des environnements de production chargés de fournir des services aux utilisateurs finaux.
- Vous pouvez tester les versions de Looker dans un environnement hors production. Vous disposez ainsi de suffisamment de temps pour tester les nouvelles fonctionnalités, les modifications de workflow et les problèmes avant de mettre à jour l'environnement de production.
Bonnes pratiques
- Isolez les différentes activités qui se déroulent simultanément dans au moins trois instances distinctes :
- Instance de développement : les développeurs utilisent l'environnement de développement pour valider le code, effectuer des tests, corriger des bugs et faire des erreurs sans risque.
- Instance QA : également appelée environnement de test ou de préproduction, elle permet aux développeurs d'exécuter des tests manuels et automatisés. L'environnement de QA est complexe et peut consommer beaucoup de ressources.
- Instance de production : c'est là que la valeur est créée pour les clients et/ou l'entreprise. L'environnement de production est très visible et ne doit comporter aucune erreur.
- Maintenez un workflow de cycle de publication documenté et reproductible.
- Si vous devez servir un grand nombre de développeurs et de testeurs QA, les instances de développement et/ou de QA peuvent être regroupées. Qu'elles soient laissées en tant que VM autonome ou en tant que cluster de VM, les instances de développement et de QA sont soumises aux mêmes considérations architecturales que celles présentées précédemment dans les sections respectives.
Débit de planification élevé
Pour les cas d'utilisation nécessitant un débit élevé de livraison de données planifiée et des livraisons fiables et rapides, nous vous recommandons d'inclure dans la configuration un cluster avec un pool de nœuds dédiés à la planification. Cette configuration permet de garantir la rapidité et la réactivité des applications Web et intégrées. Pour bénéficier de ces avantages, vous devez configurer des nœuds avec des options de démarrage personnalisées et des règles d'équilibrage de charge appropriées, comme illustré dans le schéma suivant et décrit dans les sections Avantages et Bonnes pratiques pour cette option.
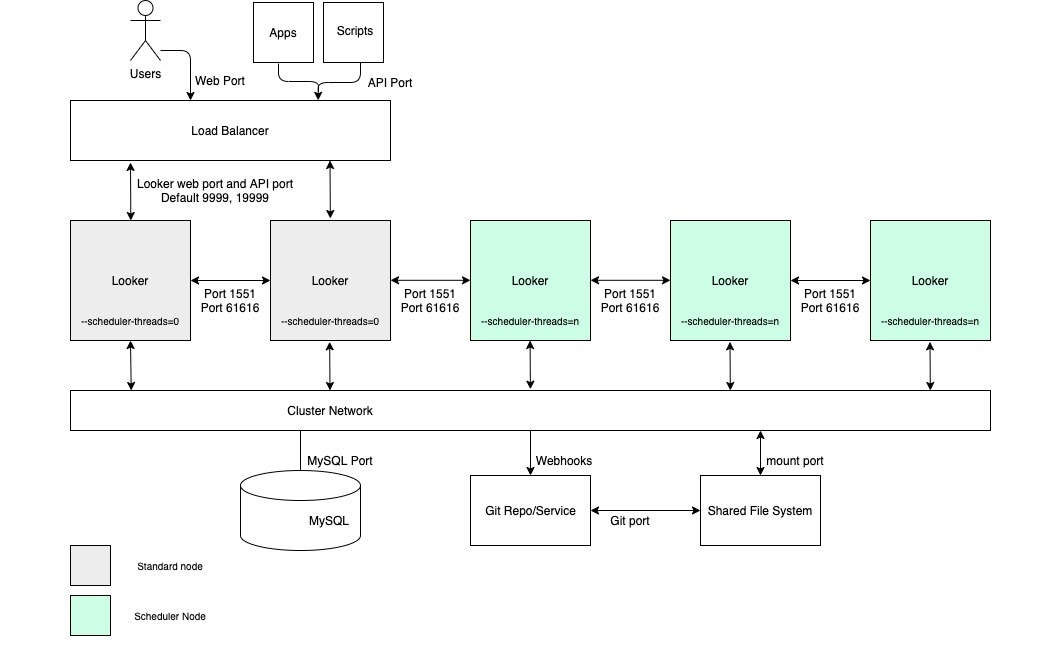
Avantages
- En dédiant des nœuds à une fonction spécifique, vous compartimentez les ressources pour la planification à partir des fonctions de développement et d'analyse ad hoc.
- Les utilisateurs peuvent développer du code LookML et explorer du contenu sans consommer de cycles à partir des nœuds responsables de la diffusion des données planifiée.
- Un trafic utilisateur élevé redirigé vers les nœuds standards n'empêche pas les charges de travail planifiées desservies par les nœuds de planification.
Bonnes pratiques
- Chaque nœud Looker doit être hébergé dans sa propre VM dédiée.
- L'équilibreur de charge, qui est le point d'entrée du cluster, doit être un équilibreur de charge de couche 4. Il doit disposer d'un délai d'attente long (3 600 secondes), être équipé d'un certificat SSL signé et être configuré pour transférer le port 443 (https) vers le port 9999 (port sur lequel le serveur Looker écoute).
- Omettez les nœuds du planificateur des règles d'équilibrage de charge afin qu'ils ne traitent pas le trafic des utilisateurs finaux ni les requêtes d'API internes.
- Nous vous recommandons de prévoir un espace de stockage de 2 IOPS par Go pour votre déploiement.
Haut débit de rendu
Pour les cas d'utilisation nécessitant un débit de rendu élevé, nous vous recommandons de configurer un cluster avec un pool de nœuds dédiés au rendu. L'affichage d'un fichier PDF ou d'une image PNG/JPEG est une opération relativement coûteuse en ressources dans Looker. Le rendu peut être gourmand en mémoire et en processeur. Lorsque Linux est sous pression de mémoire, il peut arrêter un processus en cours d'exécution. Étant donné que l'utilisation de la mémoire d'un job de rendu ne peut pas être déterminée à l'avance, le lancement d'un job de rendu peut entraîner l'arrêt du processus Looker. La configuration de nœuds de rendu dédiés permet d'optimiser les jobs de rendu tout en préservant la réactivité de l'application interactive et intégrée.
Pour bénéficier de ces avantages, vous devez configurer des nœuds avec des options de démarrage personnalisées et des règles d'équilibrage de charge appropriées, comme illustré dans le schéma suivant et expliqué dans les sections Avantages et Bonnes pratiques pour cette option. De plus, les nœuds de rendu peuvent nécessiter plus de ressources hôtes que les nœuds standards, car le service de rendu de Looker dépend de processus Chromium tiers qui partagent le temps CPU et la mémoire.
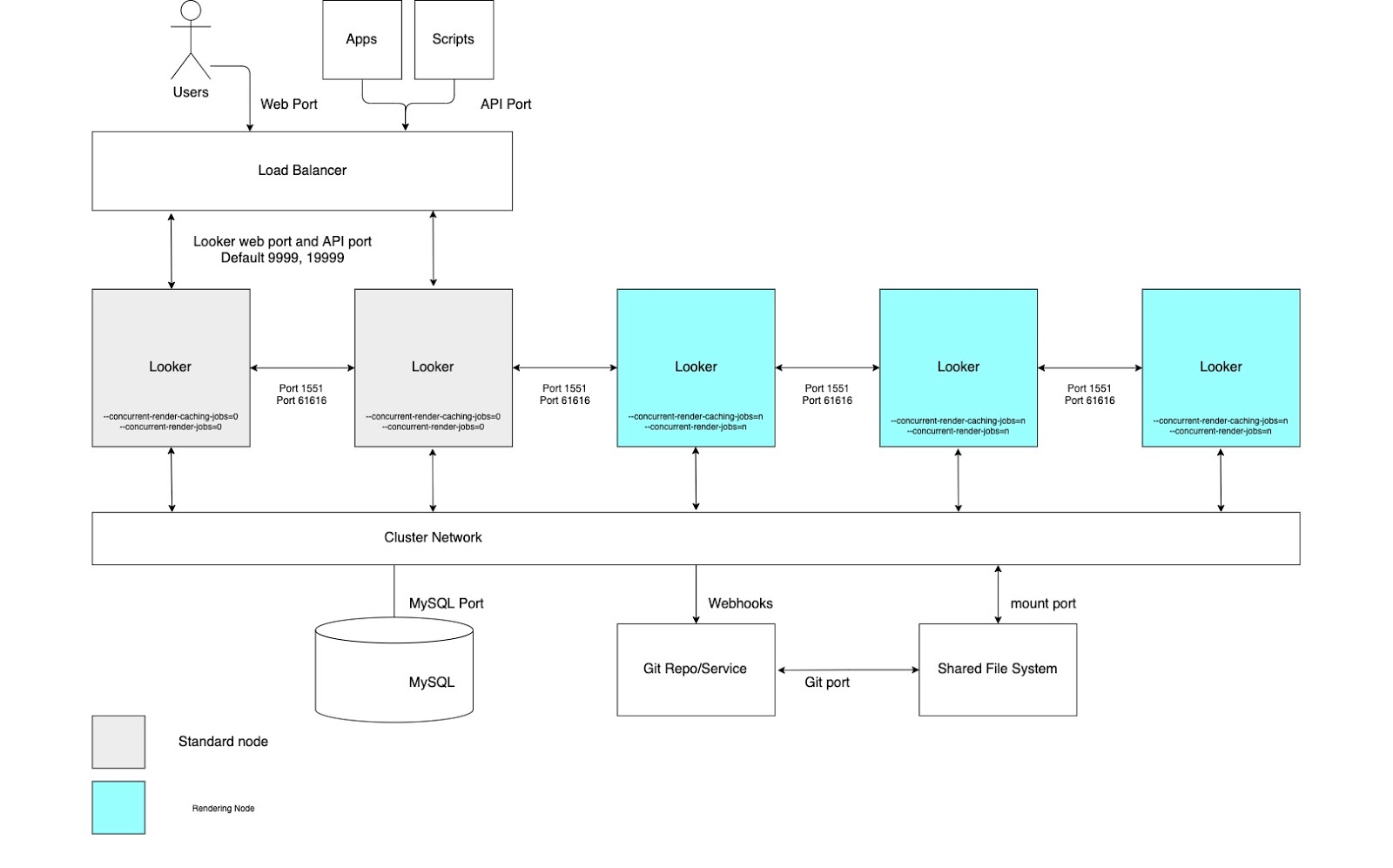
Avantages
- En dédiant des nœuds à une fonction spécifique, vous compartimentez les ressources de rendu des fonctions de développement et d'analyse ad hoc.
- Les utilisateurs peuvent développer du code LookML et explorer du contenu sans consommer de cycles sur les nœuds responsables du rendu des fichiers PNG et PDF.
- Un trafic utilisateur élevé redirigé vers les nœuds standards n'empêche pas les charges de travail de rendu traitées par les nœuds de rendu.
Bonnes pratiques
- Chaque nœud Looker doit être hébergé dans sa propre VM dédiée.
- L'équilibreur de charge, qui est le point d'entrée du cluster, doit être un équilibreur de charge de couche 4. Il doit disposer d'un délai d'attente long (3 600 secondes), être équipé d'un certificat SSL signé et être configuré pour transférer le port 443 (https) vers le port 9999 (port sur lequel le serveur Looker écoute).
- Omettez les nœuds de rendu des règles d'équilibrage de charge afin qu'ils ne traitent pas le trafic des utilisateurs finaux ni les requêtes d'API internes.
- Allouez relativement moins de mémoire à Java dans les nœuds de rendu pour donner aux processus de Chromium une plus grande mémoire tampon. Au lieu d'allouer 60 % de la mémoire à Java, allouez-en 40 à 50 %.
- Le risque de saturation de la mémoire a été réduit sur les nœuds non liés au rendu. La quantité de mémoire dédiée à Looker peut donc être augmentée. Au lieu de la valeur par défaut de 60 %, envisagez d'utiliser une valeur plus élevée, comme 80 %.
- Nous vous recommandons de prévoir un espace de stockage de 2 IOPS par Go pour votre déploiement.