En esta página se analizan los patrones de arquitectura más habituales de una implementación alojada por el cliente y se describen las prácticas recomendadas para implementarlos. Para usar esta página de forma eficaz, debes conocer los conceptos y las prácticas de la arquitectura de sistemas.
Estrategia de flujo de trabajo
Una vez que hayas determinado que el alojamiento propio es una opción viable para tu implementación de Looker, el siguiente paso es definir la estrategia que se va a usar en la implementación.
- Realiza una evaluación. Identifica una lista de candidatos de flujos de trabajo planificados y actuales.
- Enumera los patrones de arquitectura aplicables. A partir de los flujos de trabajo candidatos identificados, identifica los patrones de arquitectura aplicables.
- Prioriza y selecciona el patrón de arquitectura óptimo. Alinea el patrón de arquitectura con las tareas y los resultados más importantes.
- Configura los componentes de la arquitectura y despliega la aplicación Looker. Implementa el host, las dependencias de terceros y la topología de red necesarios para establecer conexiones de cliente seguras.
Opciones de arquitectura
Máquina virtual dedicada
Una opción es ejecutar Looker como una sola instancia en una máquina virtual (VM) dedicada. Una sola instancia puede dar servicio a cargas de trabajo exigentes escalando verticalmente el host y aumentando los grupos de subprocesos predeterminados. Sin embargo, la sobrecarga de procesamiento que supone gestionar un montón de Java grande hace que el escalado vertical esté sujeto a la ley de rendimientos decrecientes. Por lo general, es aceptable para cargas de trabajo pequeñas y medianas. En el siguiente diagrama se muestran las configuraciones predeterminadas y opcionales entre una instancia de Looker que se ejecuta en una máquina virtual dedicada, los repositorios locales y remotos, los servidores SMTP y las fuentes de datos que se destacan en las secciones Ventajas y Prácticas recomendadas de esta opción.
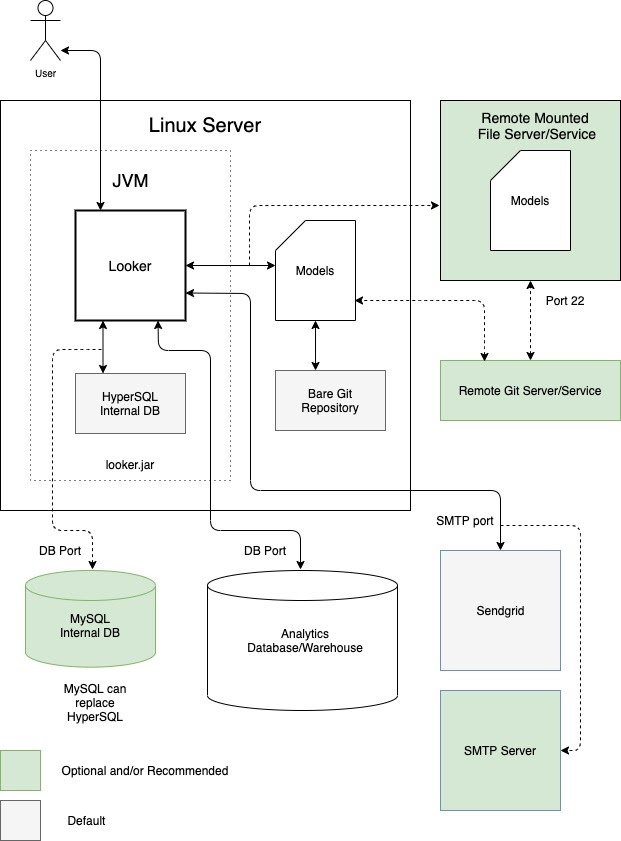
Ventajas
- Una VM dedicada es fácil de implementar y mantener.
- La base de datos interna está alojada en la aplicación Looker.
- Los componentes de modelos de Looker, repositorio de Git, servidor SMTP y base de datos backend se pueden configurar de forma local o remota.
- Puedes sustituir el servidor SMTP predeterminado de Looker por el tuyo para las notificaciones por correo electrónico y las tareas programadas.
Prácticas recomendadas
- De forma predeterminada, Looker puede generar repositorios de Git sin contenido para un proyecto. Recomendamos configurar un repositorio Git remoto para que haya redundancia.
-
De forma predeterminada, Looker empieza con una base de datos HyperSQL en memoria. Esta base de datos es cómoda y ligera, pero puede tener problemas de rendimiento si se usa mucho. Recomendamos usar una base de datos MySQL en las implementaciones de mayor tamaño. Te recomendamos que migres a una base de datos MySQL remota cuando el archivo
~/looker/.db/looker.scriptalcance los 600 MB. - Tu implementación de Looker deberá validarse con el servicio de licencias de Looker. Se requiere tráfico saliente en el puerto 443.
- Una implementación de VM dedicada se puede escalar verticalmente aumentando los recursos disponibles y los grupos de subprocesos de Looker. Sin embargo, aumentar la RAM está sujeto a la ley de rendimientos decrecientes una vez que alcanza los 64 GB, ya que los eventos de recogida de elementos no utilizados son de un solo hilo y detienen todos los demás hilos para ejecutarse. Los nodos con 16 CPUs y 64 GB de RAM ofrecen un buen equilibrio entre precio y rendimiento.
- Te recomendamos que tu implementación tenga un almacenamiento con 2 operaciones por segundo (IOPS) por GB.
Clúster de VMs
Ejecutar Looker como un clúster de instancias en varias VMs es un patrón flexible que se beneficia de la conmutación por error y la redundancia de los servicios. La escalabilidad horizontal permite aumentar el rendimiento sin incurrir en una inflación del montículo y en costes excesivos de recogida de elementos no utilizados. Los nodos tienen la opción de dedicación de cargas de trabajo, lo que permite adaptar varias opciones de implementación a diferentes requisitos empresariales. Las implementaciones de clústeres requieren al menos un administrador del sistema que esté familiarizado con los sistemas Linux y que pueda gestionar los componentes.
Clúster estándar
En la mayoría de las implementaciones estándar, basta con un clúster de nodos de servicio idénticos. Todos los nodos del clúster están configurados de la misma forma y se encuentran en el mismo grupo de balanceadores de carga. Ninguno de los nodos de esta configuración tendría más o menos probabilidades de atender las solicitudes de los usuarios de Looker, una tarea de renderización, una tarea programada, una solicitud de API, etc.
Este tipo de configuración es adecuado cuando la mayoría de las solicitudes proceden directamente de un usuario de Looker que ejecuta consultas e interactúa con Looker. Empieza a fallar cuando un gran número de solicitudes proceden de un programador, un renderizador u otra fuente. En este caso, es conveniente designar determinados nodos de servicio para que se encarguen de tareas como la programación y el renderizado.
Por ejemplo, los usuarios suelen programar las entregas de datos para que se realicen los lunes por la mañana. Un usuario que intente ejecutar consultas de Looker el lunes por la mañana puede experimentar problemas de rendimiento mientras Looker trabaja en la lista de solicitudes programadas pendientes. Al aumentar el número de nodos de servicio, el clúster proporciona un aumento proporcional del rendimiento en todas las funciones de Looker.
En el siguiente diagrama se muestra cómo se equilibran las solicitudes a Looker que realizan los usuarios, las aplicaciones y las secuencias de comandos en una instancia de Looker agrupada en clústeres.
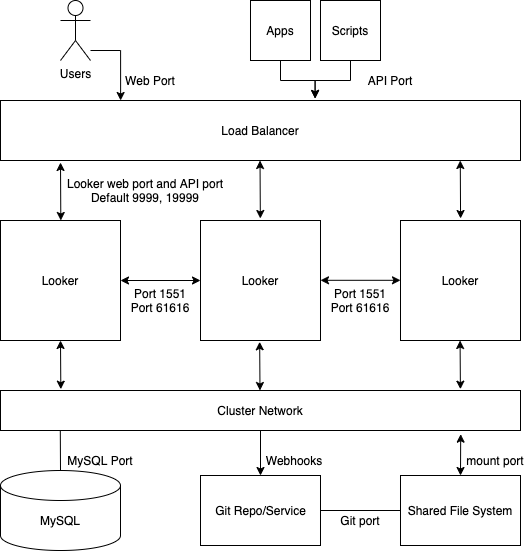
Ventajas
- Un clúster estándar maximiza el rendimiento general con una configuración mínima de la topología del clúster.
- La máquina virtual de Java sufre una degradación del rendimiento cuando se alcanza el umbral de 64 GB de memoria asignada. Por este motivo, el escalado horizontal ofrece mejores resultados que el vertical.
- Una configuración de clúster garantiza la redundancia y la conmutación por error del servicio.
Prácticas recomendadas
- Cada nodo de Looker debe alojarse en su propia máquina virtual dedicada.
- El balanceador de carga, que es el punto de entrada del clúster, debe ser un balanceador de carga de capa 4. Debe tener un tiempo de espera largo (3600 segundos), estar equipado con un certificado SSL firmado y configurarse para reenviar el puerto 443 (https) al 9999 (puerto en el que escucha el servidor de Looker).
- Te recomendamos que tu implementación tenga un almacenamiento con 2 IOPS por GB.
Desarrollo, preproducción y producción
En los casos prácticos en los que se prioriza el tiempo de actividad máximo del contenido para los usuarios finales, recomendamos usar entornos de Looker independientes para separar el trabajo de desarrollo del analítico. Al proteger los cambios del entorno de producción con entornos de desarrollo y de pruebas aislados, esta arquitectura mantiene un entorno de producción lo más estable posible.
Para disfrutar de estas ventajas, es necesario configurar los entornos interconectados y adoptar un ciclo de lanzamiento sólido. Una implementación de desarrollo, de staging o de producción también requiere un equipo de desarrolladores que conozcan la API de Looker y Git para la administración del flujo de trabajo.
En el siguiente diagrama se muestra el flujo de contenido entre los desarrolladores de LookML, que desarrollan contenido en la instancia de desarrollo; los testers de control de calidad, que prueban el contenido en la instancia de control de calidad; y los usuarios, las aplicaciones y las secuencias de comandos que consumen el contenido en la instancia de producción.
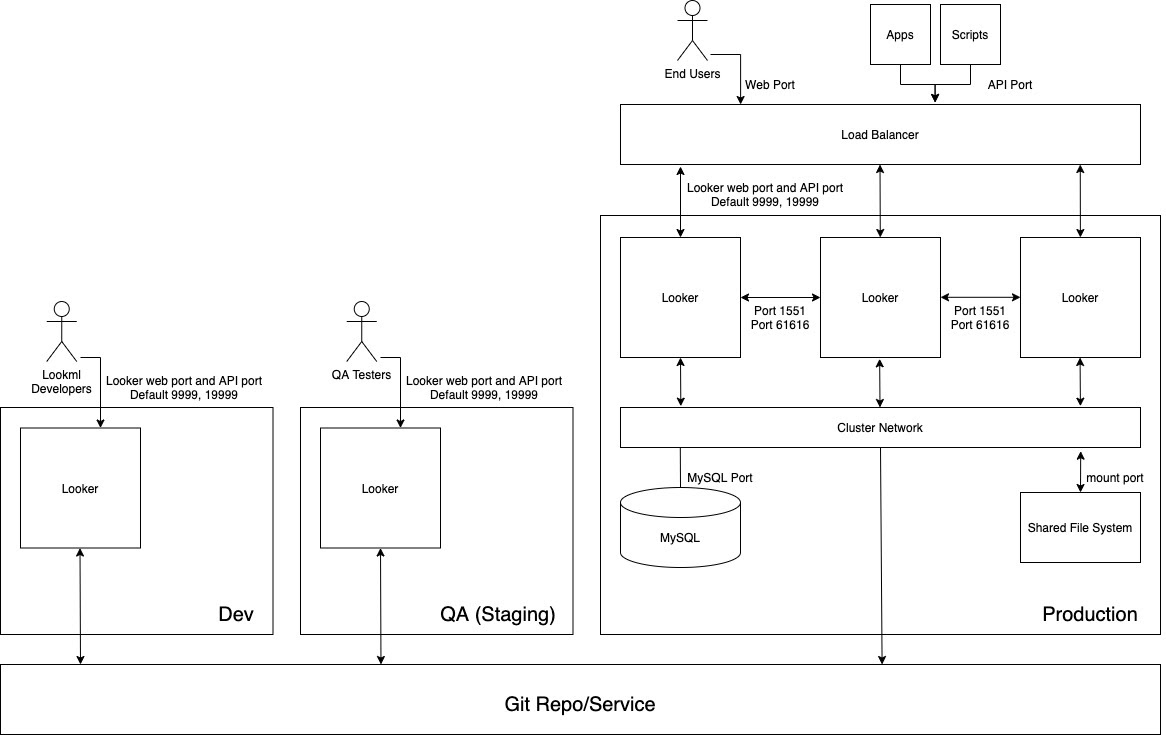
Ventajas
- La validación de LookML y de contenido se realiza en un entorno que no es de producción, lo que asegura que cualquier modificación de la lógica del modelo se pueda examinar a fondo antes de que llegue a los usuarios del entorno de producción.
- Las funciones de toda la instancia, como las funciones de Labs o los protocolos de autenticación, se pueden probar de forma aislada antes de habilitarse en el entorno de producción.
- Las políticas de grupos de datos y de almacenamiento en caché se pueden probar en un entorno que no sea de producción.
- Las pruebas del modo de producción de Looker están separadas de los entornos de producción responsables de ofrecer servicios a los usuarios finales.
- Las versiones de Looker se pueden probar en un entorno que no sea de producción, lo que da tiempo suficiente para probar nuevas funciones, cambios en el flujo de trabajo y problemas antes de actualizar el entorno de producción.
Prácticas recomendadas
- Aísla las distintas actividades que se producen simultáneamente en al menos tres instancias independientes:
- Instancia de desarrollo: los desarrolladores usan el entorno de desarrollo para confirmar código, llevar a cabo experimentos, corregir errores y equivocarse sin peligro.
- Instancia de control de calidad: también se conoce como entorno de prueba o de preproducción. Es donde los desarrolladores ejecutan pruebas manuales y automatizadas. El entorno de control de calidad es complejo y puede consumir muchos recursos.
- Instancia de producción: es donde se crea valor para los clientes o la empresa. El entorno de producción es muy visible y no debe tener errores.
- Mantener un flujo de trabajo de ciclo de lanzamiento documentado y repetible.
- Si es necesario atender a un gran volumen de desarrolladores y testers de control de calidad, las instancias de desarrollo o de control de calidad se pueden agrupar en clústeres. Tanto si se dejan como una VM independiente como si se agrupan en un clúster de VMs, las instancias de desarrollo y de control de calidad están sujetas a las mismas consideraciones de arquitectura que se han mostrado anteriormente en las secciones correspondientes.
Alto rendimiento de la programación
En los casos prácticos que requieren un alto rendimiento de entrega de datos programada y entregas fiables y oportunas, recomendamos que la configuración incluya un clúster con un grupo de nodos dedicados exclusivamente a la programación. Esta configuración ayudará a que las aplicaciones web y las aplicaciones insertadas funcionen de forma rápida y con buena respuesta. Para disfrutar de estas ventajas, es necesario configurar nodos con opciones de inicio personalizadas y reglas de equilibrio de carga adecuadas, tal como se muestra en el siguiente diagrama y se describe en las secciones Ventajas y Prácticas recomendadas de esta opción.
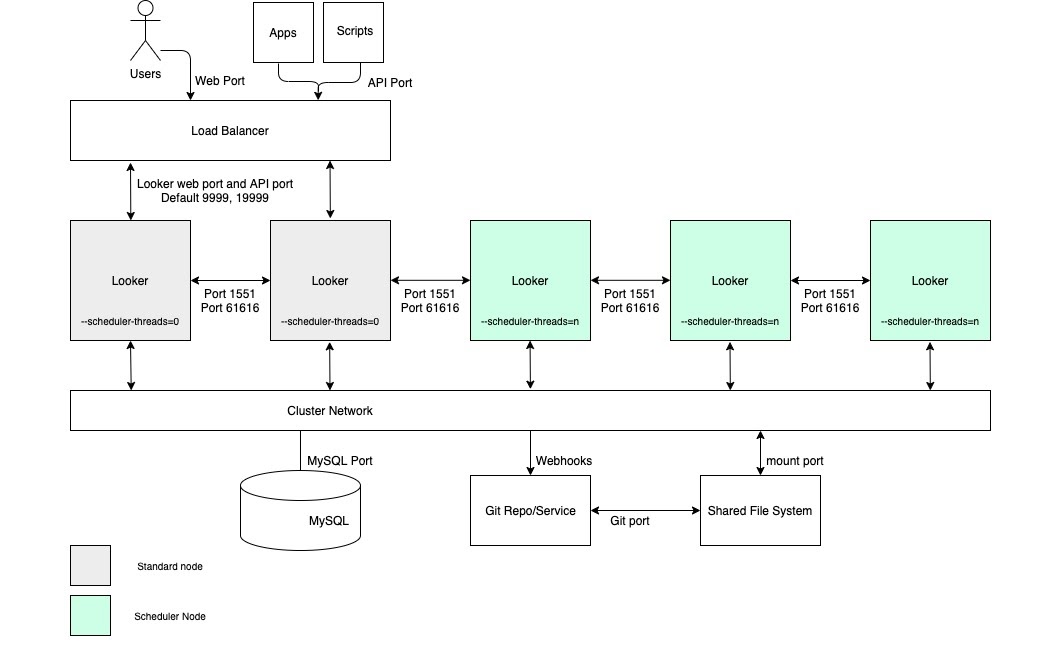
Ventajas
- Al dedicar nodos a una función específica, se compartimentan los recursos para la programación de las funciones de desarrollo y de analíticas ad hoc.
- Los usuarios pueden desarrollar LookML y explorar contenido sin consumir ciclos de los nodos responsables de proporcionar datos programados.
- El alto tráfico de usuarios canalizado a los nodos normales no impide que los nodos de programación atiendan las cargas de trabajo programadas.
Prácticas recomendadas
- Cada nodo de Looker debe alojarse en su propia máquina virtual dedicada.
- El balanceador de carga, que es el punto de entrada del clúster, debe ser un balanceador de carga de capa 4. Debe tener un tiempo de espera largo (3600 segundos), estar equipado con un certificado SSL firmado y configurarse para reenviar el puerto 443 (https) al 9999 (puerto en el que escucha el servidor de Looker).
- Omite los nodos del programador de las reglas de balanceo de carga para que no sirvan tráfico de usuarios finales ni solicitudes de API internas.
- Te recomendamos que tu implementación tenga un almacenamiento con 2 IOPS por GB.
Alto rendimiento de renderización
En los casos prácticos que requieren un alto rendimiento de los informes, recomendamos configurar un clúster con un grupo de nodos dedicados exclusivamente al renderizado. Renderizar un archivo PDF o una imagen PNG/JPEG es una operación que requiere muchos recursos en Looker. El renderizado puede requerir mucha memoria y CPU, y, cuando Linux tiene problemas de memoria, puede finalizar un proceso en ejecución. Como no se puede determinar de antemano el uso de memoria de un trabajo de renderizado, iniciar uno podría provocar que se cierre el proceso de Looker. Configurar nodos de renderizado dedicados permitirá optimizar los trabajos de renderizado y, al mismo tiempo, mantener la capacidad de respuesta de la aplicación interactiva e insertada.
Para disfrutar de estas ventajas, es necesario configurar nodos con opciones de inicio personalizadas y reglas de equilibrio de carga adecuadas, tal como se muestra en el siguiente diagrama y se explica en las secciones Ventajas y Prácticas recomendadas de esta opción. Además, los nodos de renderización pueden requerir más recursos de host que los nodos estándar, ya que el servicio de renderización de Looker depende de procesos de Chromium de terceros que comparten tiempo de CPU y memoria.
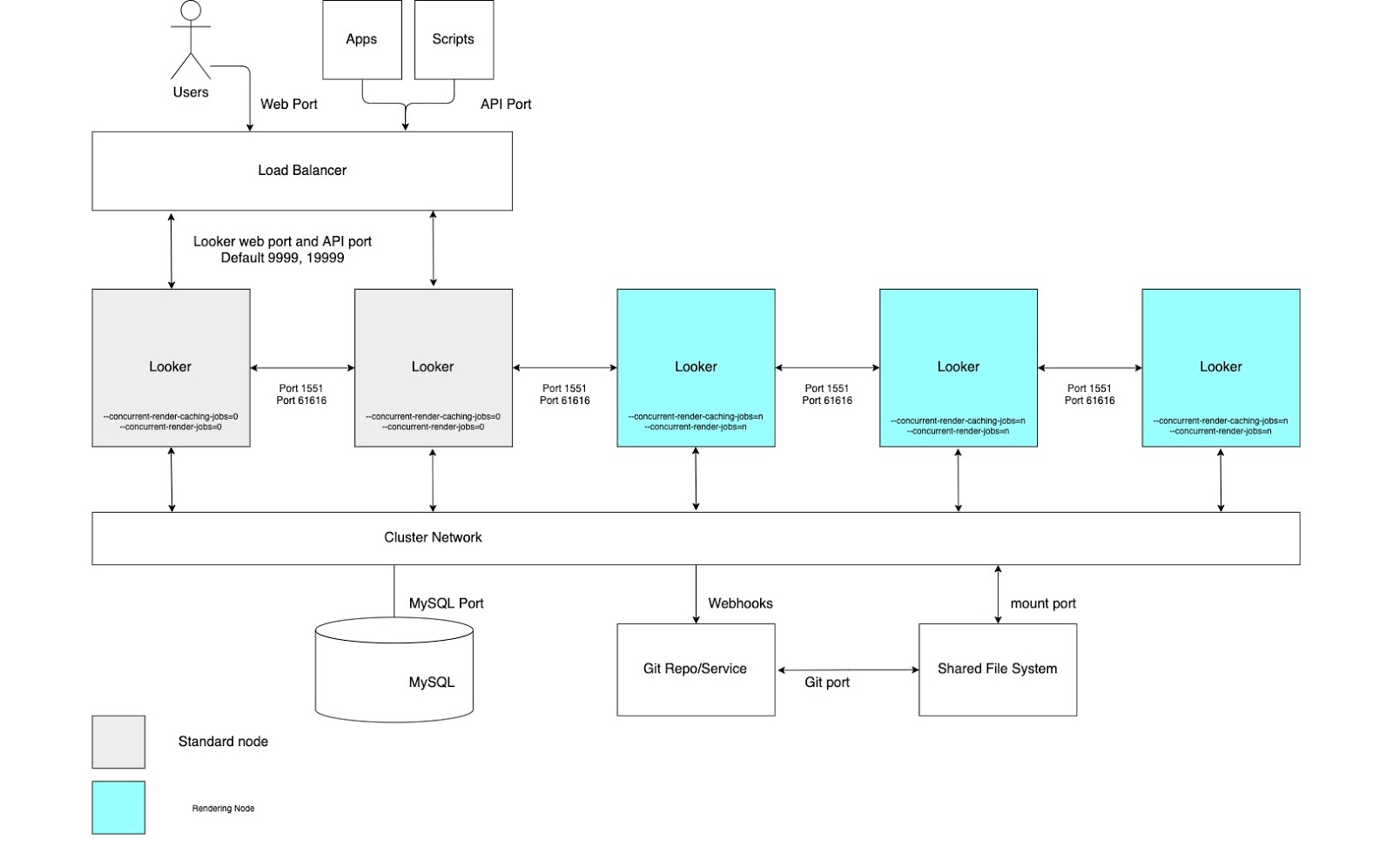
Ventajas
- Al dedicar nodos a una función específica, se compartimentan los recursos de renderización de las funciones de desarrollo y de analíticas ad hoc.
- Los usuarios pueden desarrollar LookML y explorar contenido sin consumir ciclos de los nodos responsables de renderizar PNGs y PDFs.
- El alto tráfico de usuarios canalizado a los nodos normales no impide las cargas de trabajo de renderizado que se atienden mediante nodos de renderizado.
Prácticas recomendadas
- Cada nodo de Looker debe alojarse en su propia máquina virtual dedicada.
- El balanceador de carga, que es el punto de entrada del clúster, debe ser un balanceador de carga de capa 4. Debe tener un tiempo de espera largo (3600 segundos), estar equipado con un certificado SSL firmado y configurarse para reenviar el puerto 443 (https) al 9999 (puerto en el que escucha el servidor de Looker).
- Omitir nodos de renderización de las reglas de balanceo de carga para que no sirvan tráfico de usuarios finales ni solicitudes de API internas.
- Asigna relativamente menos memoria a Java en los nodos de renderización para que los procesos de Chromium tengan un búfer de memoria más grande. En lugar de asignar el 60% de la memoria a Java, asigna entre el 40 y el 50%.
- Se ha reducido el riesgo de presión de memoria en los nodos que no son de renderizado, por lo que se puede aumentar la cantidad de memoria dedicada a Looker. En lugar del 60 % predeterminado, prueba con un número más alto, como el 80%.
- Te recomendamos que tu implementación tenga un almacenamiento con 2 IOPS por GB.