本指南介绍了如何在 Google Kubernetes Engine (GKE) 集群中使用 GKE 数据缓存,来提升读取密集型有状态应用的性能。GKE 数据缓存是一种托管式块存储解决方案,可加快在 GKE 上运行的有状态应用(例如数据库)的读取操作。
您只能将数据缓存与 GKE Standard 集群搭配使用。本指南将引导您完成以下操作:在创建新的 GKE Standard 集群或节点池时启用 GKE 数据缓存,以及预配具有数据缓存加速功能的 GKE 挂接磁盘。
GKE 数据缓存简介
借助 GKE 数据缓存,您可以将 GKE 节点上的本地 SSD 用作永久性存储(例如永久性磁盘或 Hyperdisk)的缓存层。使用本地 SSD 可减少磁盘读取延迟时间,并提高有状态工作负载的每秒查询次数 (QPS),同时最大限度地减少内存要求。GKE 数据缓存支持将所有类型的永久性磁盘或 Hyperdisk 用作备份磁盘。
如需对应用使用 GKE 数据缓存,请配置挂接了本地 SSD 的 GKE 节点池。您可以将 GKE 数据缓存配置为使用所挂接本地 SSD 的全部或部分空间。GKE 数据缓存解决方案使用的本地 SSD 通过标准 Google Cloud 加密对静态数据进行加密。
优势
GKE 数据缓存具有以下优势:
- 传统数据库(如 MySQL 或 Postgres)和向量数据库每秒处理的查询速率有所提高。
- 通过最大限度缩短磁盘延迟时间,提高有状态应用的读取性能。
- 由于 SSD 位于节点本地,因此数据加载和重载速度更快。 数据加载是指将必要数据从永久性存储加载到本地 SSD 上的初始过程。数据重载是指在节点回收后恢复本地 SSD 上的数据的过程。
部署架构
下图显示了一个 GKE 数据缓存配置示例,其中包含两个各自运行一个应用的 Pod。这些 Pod 在同一 GKE 节点上运行。每个 Pod 使用单独的本地 SSD 和备份永久性磁盘。
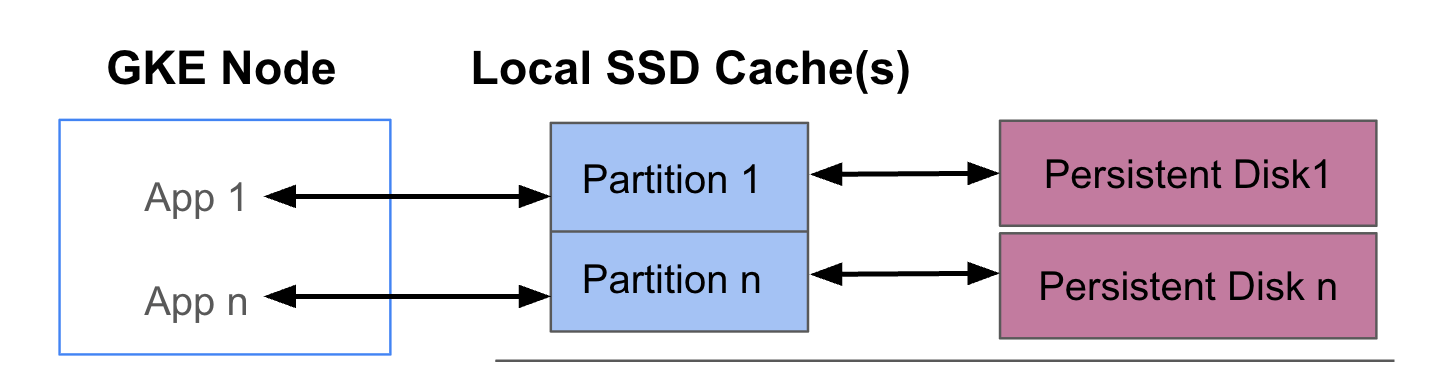
部署模式
您可以通过以下两种模式之一设置 GKE 数据缓存:
- 透写(推荐):当应用写入数据时,数据会同步写入缓存和底层永久性磁盘。
writethrough模式可防止数据丢失,适合大多数生产工作负载。 - 回写:当应用写入数据时,数据仅写入缓存。然后,数据会异步(在后台)写入永久性磁盘。
writeback模式可提高写入性能,适合依赖速度的工作负载。不过,此模式会影响可靠性。如果节点意外关闭,未刷新的缓存数据将丢失。
目标
在本指南中,您将学习如何:
- 创建底层 GKE 基础架构以使用 GKE 数据缓存。
- 创建挂接了本地 SSD 的专用节点池。
- 创建 StorageClass,以便在 Pod 通过 PersistentVolumeClaim (PVC) 请求 PersistentVolume (PV) 时动态预配 PV。
- 创建 PVC 以请求 PV。
- 创建使用 PVC 的 Deployment,以确保您的应用即使在 Pod 重启和重新调度期间也能访问永久性存储。
要求和规划
确保您满足以下使用 GKE 数据缓存的要求:
- 您的 GKE 集群必须运行 1.32.3-gke.1440000 版或更高版本。
- 您的节点池必须使用支持本地 SSD 的机器类型。如需了解详情,请参阅机器系列支持。
规划
在规划 GKE 数据缓存的存储容量时,请考虑以下方面:
- 将同时使用 GKE 数据缓存的每个节点的最大 Pod 数量。
- 将使用 GKE 数据缓存的 Pod 的预期缓存大小要求。
- GKE 节点上可用的本地 SSD 总容量。 如需了解哪些机器类型默认挂接了本地 SSD,以及哪些机器类型需要您挂接本地 SSD,请参阅选择有效的本地 SSD 磁盘数量。
- 对于第三代或更高代机器类型(默认情况下会挂接一定数量的本地 SSD),请注意,数据缓存的本地 SSD 是从该机器上的可用的本地 SSD 总数中预留的。
- 可能会减少本地 SSD 可用空间的文件系统开销。例如,即使您有一个节点具有两个本地 SSD,总原始容量为 750 GiB,但由于文件系统开销,所有数据缓存卷的可用空间可能较小。部分本地 SSD 容量已预留给系统使用。
价格
您需要支付本地 SSD 和所挂接的永久性磁盘的总预配容量的费用。您每月按 GiB 付费。
如需了解详情,请参阅 Compute Engine 文档中的磁盘价格。
准备工作
在开始之前,请确保您已执行以下任务:
- 启用 Google Kubernetes Engine API。 启用 Google Kubernetes Engine API
- 如果您要使用 Google Cloud CLI 执行此任务,请安装并初始化 gcloud CLI。 如果您之前安装了 gcloud CLI,请运行
gcloud components update以获取最新版本。
- 查看节点池的支持本地 SSD 的机器类型。
配置 GKE 节点以使用数据缓存
如需开始使用 GKE 数据缓存来加速存储,您的节点必须具有必要的本地 SSD 资源。本部分展示了在创建新的 GKE 集群或向现有集群添加新的节点池时,用于预配本地 SSD 和启用 GKE 数据缓存的命令。您无法更新现有节点池来使用数据缓存。如果您想在现有集群上使用数据缓存,请向该集群添加新的节点池。
在新集群上
如需创建配置了数据缓存的 GKE 集群,请使用以下命令:
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
替换以下内容:
CLUSTER_NAME:集群的名称。为要创建的 GKE 集群提供一个唯一的名称。LOCATION:新集群的 Google Cloud 区域或可用区。MACHINE_TYPE:要为集群使用的第 2 代、第 3 代或更高代机器系列中的机器类型,例如n2-standard-2或c3-standard-4-lssd。 此字段是必填字段,因为本地 SSD 不能与默认的e2-medium类型搭配使用。如需了解详情,请参阅可用的机器系列。DATA_CACHE_COUNT:默认节点池中每个节点上专门用于数据缓存的本地 SSD 卷的数量。每个本地 SSD 的容量为 375 GiB。卷的最大数量因机器类型和区域而异。 请注意,部分本地 SSD 容量已预留给系统使用。(可选)
LOCAL_SSD_COUNT:要预配的本地 SSD 卷的数量,以满足其他临时存储需求。如果您想预配未用于数据缓存的其他本地 SSD,请使用--ephemeral-storage-local-ssd count标志。对于第三代或更高代机器类型,请注意以下事项:
- 第三代或更高代机器类型默认挂接了特定数量的本地 SSD。挂接到每个节点的本地 SSD 的数量取决于您指定的机器类型。
- 如果您计划使用
--ephemeral-storage-local-ssd count标志来提供额外的临时存储空间,请务必将DATA_CACHE_COUNT的值设置为小于机器上可用的本地 SSD 磁盘总数的数字。可用的本地 SSD 总数包括默认挂接的磁盘以及您使用--ephemeral-storage-local-ssd count标志添加的任何新磁盘。
此命令会创建一个 GKE 集群,该集群的默认节点池在第二代、第三代或更高代机器类型上运行,为数据缓存预配本地 SSD,并根据需要为其他临时存储需求预配额外的本地 SSD。
这些设置仅适用于默认节点池。
在现有集群上
如需在现有集群上使用数据缓存,您必须创建配置了数据缓存的新节点池。
如需创建配置了数据缓存的 GKE 节点池,请使用以下命令:
gcloud container node-pool create NODE_POOL_NAME \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
替换以下内容:
NODE_POOL_NAME:节点池的名称。为您要创建的节点池提供唯一名称。CLUSTER_NAME:要创建节点池的现有 GKE 集群的名称。LOCATION:与您的集群相同的 Google Cloud 区域或可用区。MACHINE_TYPE:要为集群使用的第 2 代、第 3 代或更高代机器系列中的机器类型,例如n2-standard-2或c3-standard-4-lssd。 此字段是必填字段,因为本地 SSD 不能与默认的e2-medium类型搭配使用。如需了解详情,请参阅可用的机器系列。DATA_CACHE_COUNT:节点池中每个节点上专门用于数据缓存的本地 SSD 卷的数量。每个本地 SSD 的容量为 375 GiB。卷的最大数量因机器类型和区域而异。 请注意,部分本地 SSD 容量已预留给系统使用。(可选)
LOCAL_SSD_COUNT:要预配的本地 SSD 卷的数量,以满足其他临时存储需求。如果您想预配未用于数据缓存的其他本地 SSD,请使用--ephemeral-storage-local-ssd count标志。对于第三代或更高代机器类型,请注意以下事项:
- 第三代或更高代机器类型默认挂接了特定数量的本地 SSD。挂接到每个节点的本地 SSD 的数量取决于您指定的机器类型。
- 如果您计划使用
--ephemeral-storage-local-ssd count标志来添加临时存储空间,请务必将DATA_CACHE_COUNT设置为小于机器上可用的本地 SSD 磁盘总数。可用的本地 SSD 总数包括默认挂接的磁盘以及您使用--ephemeral-storage-local-ssd count标志添加的任何新磁盘。
此命令会创建一个在第二代、第三代或更高代机器类型上运行的 GKE 节点池,为数据缓存预配本地 SSD,并根据需要为其他临时存储需求预配额外的本地 SSD。
为 GKE 上的永久性存储空间预配数据缓存
本部分提供了一个示例,说明如何为有状态应用启用 GKE 数据缓存的性能优势。
创建具有本地 SSD 的节点池以用于数据缓存
首先,在 GKE 集群中创建一个挂接了本地 SSD 的新节点池。GKE 数据缓存使用本地 SSD 来提升所挂接的永久性磁盘的性能。
以下命令会创建一个使用第二代机器 n2-standard-2 的节点池:
gcloud container node-pools create datacache-node-pool \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--num-nodes=2 \
--data-cache-count=1 \
--machine-type=n2-standard-2
替换以下内容:
CLUSTER_NAME:集群的名称。指定要在其中创建新节点池的 GKE 集群。LOCATION:与您的集群相同的 Google Cloud 区域或可用区。
此命令会创建具有以下规范的节点池:
--num-nodes=2:将此池中的初始节点数设置为 2。--data-cache-count=1:指定每个节点上有一个本地 SSD 专用于 GKE 数据缓存。
为此节点池预配的本地 SSD 总数为 2,因为每个节点都预配了一个本地 SSD。
创建数据缓存 StorageClass
创建 Kubernetes StorageClass,告知 GKE 如何动态预配使用数据缓存的永久性卷。
使用以下清单创建并应用名为 pd-balanced-data-cache-sc 的 StorageClass:
kubectl apply -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pd-balanced-data-cache-sc
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-balanced
data-cache-mode: writethrough
data-cache-size: "100Gi"
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
数据缓存的 StorageClass 参数包括:
type:指定永久性卷的底层磁盘类型。如需了解更多选项,请参阅支持的永久性磁盘类型或 Hyperdisk 类型。data-cache-mode:使用推荐的writethrough模式。如需了解详情,请参阅部署模式。data-cache-size:将本地 SSD 容量设置为 100 GiB,用作每个 PVC 的读取缓存。
使用 PersistentVolumeClaim (PVC) 请求存储空间
创建一个引用您创建的 pd-balanced-data-cache-sc StorageClass 的 PVC。PVC 请求启用数据缓存的永久性卷。
使用以下清单创建一个名为 pvc-data-cache 的 PVC,该 PVC 请求一个具有 ReadWriteOnce 访问权限且容量至少为 300 GiB 的永久性卷。
kubectl apply -f - <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-data-cache
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: pd-balanced-data-cache-sc
EOF
创建使用 PVC 的 Deployment
创建名为 postgres-data-cache 的 Deployment,该 Deployment 运行一个使用您之前创建的 pvc-data-cache PVC 的 Pod。cloud.google.com/gke-data-cache-count 节点选择器可确保将 Pod 调度到具有使用 GKE 数据缓存所需的本地 SSD 资源的节点上。
创建并应用以下清单,以配置一个使用 PVC 部署 Postgres Web 服务器的 Pod:
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-data-cache
labels:
name: database
app: data-cache
spec:
replicas: 1
selector:
matchLabels:
service: postgres
app: data-cache
template:
metadata:
labels:
service: postgres
app: data-cache
spec:
nodeSelector:
cloud.google.com/gke-data-cache-disk: "1"
containers:
- name: postgres
image: postgres:14-alpine
volumeMounts:
- name: pvc-data-cache-vol
mountPath: /var/lib/postgresql/data2
subPath: postgres
env:
- name: POSTGRES_USER
value: admin
- name: POSTGRES_PASSWORD
value: password
restartPolicy: Always
volumes:
- name: pvc-data-cache-vol
persistentVolumeClaim:
claimName: pvc-data-cache
EOF
确认已成功创建 Deployment:
kubectl get deployment
Postgres 容器可能需要几分钟才能完成预配并显示 READY 状态。
验证数据缓存配置
创建部署后,确认已正确配置具有数据缓存的永久性存储空间。
如需验证您的
pvc-data-cache是否已成功绑定到永久性卷,请运行以下命令:kubectl get pvc pvc-data-cache输出类似于以下内容:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE pvc-data-cache Bound pvc-e9238a16-437e-45d7-ad41-410c400ae018 300Gi RWO pd-balanced-data-cache-sc <unset> 10m如需确认是否已在节点上创建数据缓存的逻辑卷管理器 (LVM) 组,请按照以下步骤操作:
获取相应节点上 PDCSI 驱动程序的 Pod 名称:
NODE_NAME=$(kubectl get pod --output json | jq '.items[0].spec.nodeName' | sed 's/\"//g') kubectl get po -n kube-system -o wide | grep ^pdcsi-node | grep $NODE_NAME从输出中复制
pdcsi-nodePod 的名称。查看 PDCSI 驱动程序日志,了解 LVM 组创建情况:
PDCSI_POD_NAME="PDCSI-NODE_POD_NAME" kubectl logs -n kube-system $PDCSI_POD_NAME gce-pd-driver | grep "Volume group creation"将
PDCSI-NODE_POD_NAME替换为您在上一步中复制的实际 Pod 名称。输出类似于以下内容:
Volume group creation succeeded for LVM_GROUP_NAME
此消息确认节点上已正确设置数据缓存的 LVM 配置。
清理
为避免系统向您的 Google Cloud 账号收取费用,请删除您在本指南中创建的存储资源。
删除部署
kubectl delete deployment postgres-data-cache删除 PersistentVolumeClaim。
kubectl delete pvc pvc-data-cache删除节点池。
gcloud container node-pools delete datacache-node-pool \ --cluster CLUSTER_NAME将
CLUSTER_NAME替换为您创建使用数据缓存的节点池的集群的名称。