このページでは、Google Kubernetes Engine(GKE)ワークロードと基盤となるクラスタノードの起動レイテンシのモニタリングに使用できる指標とダッシュボードについて説明します。この指標を使用して、起動レイテンシの追跡、トラブルシューティング、削減を行うことができます。
このページは、ワークロードの起動レイテンシをモニタリングして最適化する必要があるプラットフォーム管理者とオペレーターを対象としています。 Google Cloud のコンテンツで参照されている一般的なロールの詳細については、一般的な GKE ユーザーロールとタスクをご覧ください。
概要
起動レイテンシは、アプリケーションがトラフィックの急増にどのように対応するか、レプリカが停止からどのくらいの速さで復元するか、クラスタとワークロードの運用コストをどの程度効率化できるかに大きな影響を与えます。ワークロードの起動レイテンシをモニタリングすると、レイテンシの悪化を検出し、ワークロードとインフラストラクチャの更新が起動レイテンシに与える影響を追跡する際に役に立ちます。
ワークロードの起動レイテンシを最適化すると、次のようなメリットがあります。
- トラフィックの急増時にユーザーに対するサービスのレスポンス レイテンシを短縮します。
- 新しいレプリカの作成中に需要の急増に対応するために必要な過剰なサービング容量を削減します。
- バッチ コンピューティング中に、すでにデプロイされていて残りのリソースの起動を待機しているリソースのアイドル時間を短縮します。
始める前に
作業を始める前に、次のタスクが完了していることを確認してください。
- Google Kubernetes Engine API を有効にする。 Google Kubernetes Engine API の有効化
- このタスクに Google Cloud CLI を使用する場合は、gcloud CLI をインストールして初期化する。すでに gcloud CLI をインストールしている場合は、
gcloud components updateコマンドを実行して最新のバージョンを取得します。以前のバージョンの gcloud CLI では、このドキュメントのコマンドを実行できない場合があります。
Cloud Logging API と Cloud Monitoring API を有効にします。
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
要件
ワークロードの起動レイテンシの指標とダッシュボードを表示するには、GKE クラスタが次の要件を満たしている必要があります。
- GKE バージョン 1.31.1-gke.1678000 以降が必要です。
- システム指標の収集を構成する必要があります。
- システムログの収集を構成する必要があります。
- クラスタの
PODコンポーネントで Kube 状態指標を有効にして、Pod とコンテナの指標を表示します。
必要なロールと権限
ログの生成を有効にしてログにアクセスして処理するために必要な権限を取得するには、次の IAM ロールを付与するよう管理者に依頼してください。
-
GKE クラスタ、ノード、ワークロードを表示する: プロジェクトに対する Kubernetes Engine 閲覧者(
roles/container.viewer) -
起動レイテンシ指標にアクセスしてダッシュボードを表示する: プロジェクトに対するモニタリング閲覧者(
roles/monitoring.viewer) -
Kubelet イメージ pull イベントなどのレイテンシ情報を含むログにアクセスし、ログ エクスプローラとログ分析で表示する: プロジェクトに対するログビューア(
roles/logging.viewer)
ロールの付与については、プロジェクト、フォルダ、組織に対するアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
起動レイテンシの指標
起動レイテンシ指標は GKE システム指標に含まれており、GKE クラスタと同じプロジェクトの Cloud Monitoring にエクスポートされます。
この表の Cloud Monitoring の指標名には、kubernetes.io/ という接頭辞を付ける必要があります。この接頭辞は、表中の項目では省略されています。
| 指標タイプ(リソース階層レベル) 表示名 |
|
|---|---|
|
種類、タイプ、単位 モニタリング対象リソース |
説明 ラベル |
pod/latencies/pod_first_ready
(プロジェクト)
Pod の最初の準備完了までのレイテンシ |
|
GAUGE、Double、s
k8s_pod |
イメージの pull を含む、Pod のエンドツーエンドの起動レイテンシ(Pod Created から Ready まで)。60 秒ごとにサンプリングされます。 |
node/latencies/startup
(プロジェクト)
ノード起動レイテンシ |
|
GAUGE、INT64、s
k8s_node |
ノードの起動レイテンシの合計。GCE インスタンスの CreationTimestamp から Kubernetes node ready までの初回起動時間。60 秒ごとにサンプリングされます。accelerator_family: ハードウェア アクセラレータに基づくノードの分類: gpu、tpu、cpu。kube_control_plane_available: KCP(kube コントロール プレーン)が使用可能なときにノード作成リクエストが受信されたかどうか。 |
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(プロジェクト)
HPA の推奨事項あたりのスケール レイテンシ |
|
GAUGE、DOUBLE、s
k8s_scale |
HPA ターゲットの Horizontal Pod Autoscaler(HPA)スケーリングの推奨事項のレイテンシ(指標が作成されてから、対応するスケーリングの推奨事項が apiserver に適用されるまでの時間)。60 秒ごとにサンプリングされます。サンプリング後、データは最長 20 秒間表示されません。metric_type: 指標ソースのタイプ。"ContainerResource"、"External"、"Object"、"Pods"、"Resource" のいずれかにする必要があります。 |
ワークロードの起動レイテンシ ダッシュボードを表示する
ワークロードの [起動レイテンシ] ダッシュボードは、Deployment でのみ使用できます。Deployment の起動レイテンシ指標を表示するには、 Google Cloud コンソールで次の操作を行います。
[ワークロード] ページに移動します。
[デプロイの詳細] ビューを開くには、検査するワークロードの名前をクリックします。
[オブザーバビリティ] タブをクリックします。
左側のメニューから [起動レイテンシ] を選択します。
Pod の起動レイテンシの分布を表示する
Pod の起動レイテンシは、イメージ pull を含む起動レイテンシ合計を指します。これは、Pod の Created ステータスから Ready ステータスまでの時間を測定します。Pod の起動レイテンシは、次の 2 つのグラフを使用して評価できます。
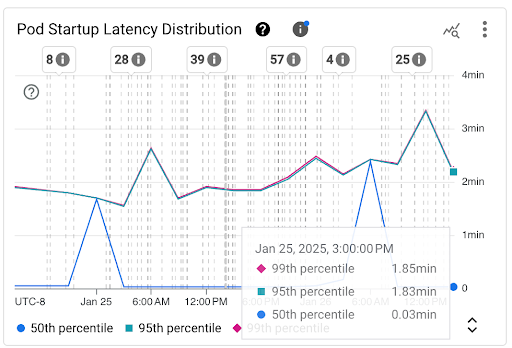
[Pod の起動レイテンシの分布] グラフ: このグラフは、固定の 3 時間間隔(午前 0 時~午前 3 時、午前 3 時~午前 6 時など)での Pod 起動イベントの観測に基づいて計算された Pod の起動レイテンシのパーセンタイル(50 パーセンタイル、95 パーセンタイル、99 パーセンタイル)を示します。このグラフは、次の目的で使用できます。
- ベースラインの Pod 起動レイテンシを把握します。
- Pod 起動レイテンシの経時的な変化を特定します。
- Pod の起動レイテンシの変化を、ワークロード デプロイやクラスタ オートスケーラー イベントなどの最近のイベントと関連付けます。ダッシュボードの上部にある [アノテーション] リストでイベントを選択できます。
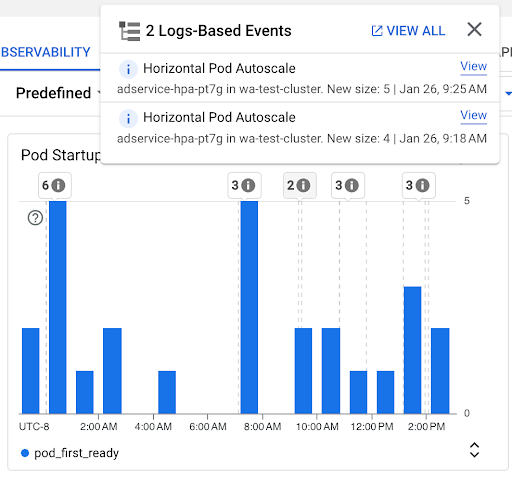
[Pod の起動数] グラフ: 選択した期間に起動された Pod の数を示します。このグラフは次の目的で使用できます。
- 特定の時間間隔で Pod 起動レイテンシ分布のパーセンタイルの計算に使用される Pod のサンプルサイズを把握する。
- ワークロードのデプロイや Horizontal Pod Autoscaler イベントなど、Pod の起動の原因を把握する。ダッシュボードの上部にある [アノテーション] リストでイベントを選択できます。
個々の Pod の起動レイテンシを表示する
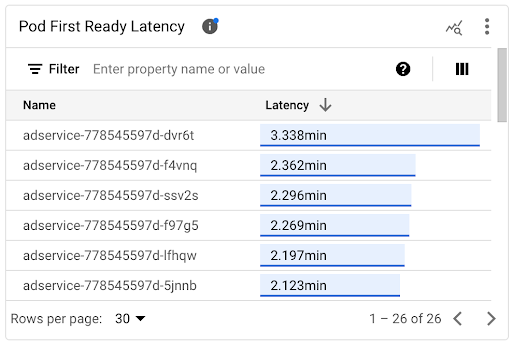
個々の Pod の起動レイテンシは、[Pod の最初の準備完了までのレイテンシ] タイムライン グラフと関連するリストで確認できます。
- [Pod の最初の準備完了までのレイテンシ] タイムライン グラフを使用して、個々の Pod の起動を、HorizontalPodAutoscaler イベントやクラスタ オートスケーラー イベントなどの最近のイベントと関連付けます。これらのイベントは、ダッシュボードの上部にある [アノテーション] リストで選択できます。このグラフは、他の Pod と比較して起動レイテンシが変化した潜在的原因を特定するのに役立ちます。
- [Pod の最初の準備完了までのレイテンシ] リストを使用して、起動にかかった時間が最も長い Pod や最も短い Pod を特定します。このリストは [レイテンシ] 列で並べ替えることができます。起動レイテンシが最も大きい Pod を特定したら、Pod の起動イベントを他の最近のイベントと関連付けて、レイテンシの悪化をトラブルシューティングできます。
個々の Pod が作成された日時を確認するには、対応する Pod 作成イベントの timestamp フィールドの値を確認します。timestamp フィールドを表示するには、ログ エクスプローラで次のクエリを実行します。
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
ワークロードのすべての Pod 作成イベントを一覧表示するには、前のクエリで次のフィルタを使用します。protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
個々の Pod のレイテンシを比較すると、さまざまな構成が Pod の起動レイテンシに与える影響をテストし、要件に基づいて最適な構成を特定できます。
Pod のスケジューリング レイテンシを特定する
Pod スケジューリング レイテンシは、Pod が作成されてからノードでスケジュールされるまでの時間です。Pod のスケジューリング レイテンシは、Pod のエンドツーエンドの起動時間に影響します。これは、Pod のスケジューリング イベントのタイムスタンプから Pod の作成リクエストのタイムスタンプを減算して計算されます。
個々の Pod スケジューリング イベントのタイムスタンプは、対応する Pod スケジューリング イベントの jsonPayload.eventTime フィールドで確認できます。jsonPayload.eventTime フィールドを表示するには、ログ エクスプローラで次のクエリを実行します。
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
ワークロードのすべての Pod スケジューリング イベントを一覧表示するには、前のクエリで次のフィルタを使用します。resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
イメージ pull のレイテンシを表示する
コンテナ イメージがノードでまだ使用できない場合や、このイメージを更新する必要がある場合、コンテナ イメージの pull レイテンシは Pod の起動レイテンシに影響します。イメージ pull レイテンシを最適化すると、クラスタのスケールアウト イベント中のワークロードの起動レイテンシが短縮されます。
[Kubelet イメージ pull イベント] テーブルで、ワークロード コンテナ イメージが pull された日時と、その処理にかかった時間を確認できます。
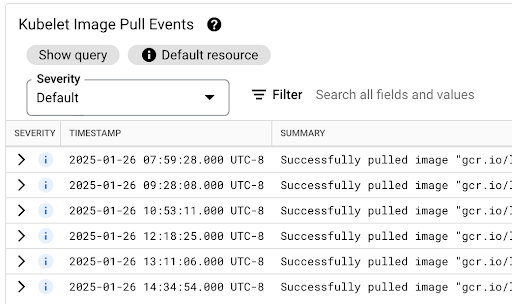
イメージの pull レイテンシは jsonPayload.message フィールドに表示されます。このフィールドには、次のようなメッセージが含まれています。
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
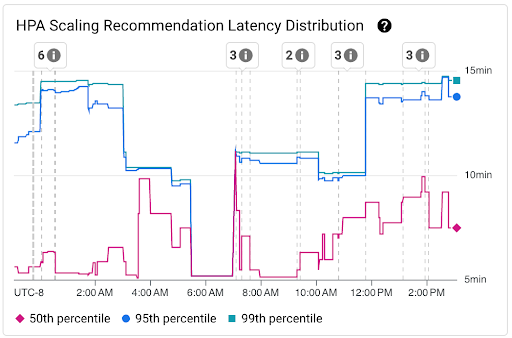
HPA スケーリングの推奨事項のレイテンシ分布を表示する
HPA ターゲットの HorizontalPodAutoscaler(HPA)スケーリングの推奨事項のレイテンシは、指標が作成されてから、対応するスケーリングの推奨事項が API サーバーに適用されるまでの時間です。HPA スケーリングの推奨事項のレイテンシを最適化すると、スケールアウト イベント中のワークロードの起動レイテンシが短縮されます。
HPA スケーリングは、次の 2 つのグラフで確認できます。
[HPA スケーリングの推奨のレイテンシ分布] グラフ: このグラフには、過去 3 時間の間隔で HPA スケーリングの推奨事項のモニタリングに基づいて計算された HPA スケーリングの推奨事項のレイテンシのパーセンタイル(50 パーセンタイル、95 パーセンタイル、99 パーセンタイル)が表示されます。このグラフは次の目的で使用できます。
- ベースラインの HPA スケーリングの推奨事項のレイテンシを把握する。
- HPA スケーリングの推奨事項のレイテンシの経時的な変化を特定する。
- HPA スケーリングの推奨事項のレイテンシの変化を最近のイベントと関連付ける。ダッシュボードの上部にある [アノテーション] リストでイベントを選択できます。
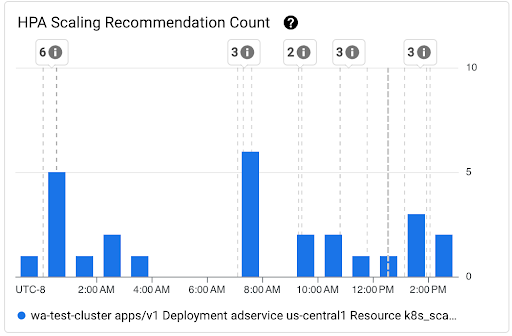
[HPA スケーリングの推奨事項の数] グラフ: 選択した期間に観測された HPA スケーリングの推奨事項の数を示すグラフ。このグラフは、次のタスクに使用します。
- HPA スケーリングの推奨事項のサンプルサイズを把握する。サンプルは、特定の期間の HPA スケーリングの推奨事項のレイテンシ分布のパーセンタイルを計算するために使用されます。
- HPA スケーリングの推奨事項を新しい Pod 起動イベントおよび HorizontalPodAutoscaler イベントと関連付ける。ダッシュボードの上部にある [アノテーション] リストでイベントを選択できます。
Pod のスケジューリングの問題を表示する
Pod のスケジューリングの問題は、ワークロードのエンドツーエンドの起動レイテンシに影響する可能性があります。ワークロードのエンドツーエンドの起動レイテンシを短縮するには、これらの問題のトラブルシューティングを行い、問題の数を減らします。
このような問題を追跡するために使用できるグラフは次の 2 つです。
- [Unschedulable/Pending/Failed Pods] グラフには、スケジュール不可、保留中、失敗した Pod の数が経時的に表示されます。
- [バックオフ / 待機中 / Readiness に失敗したコンテナ] グラフには、これらの状態のコンテナ数が経時的に表示されます。
ノードの起動レイテンシ ダッシュボードを表示する
ノードの起動レイテンシ指標を表示するには、Google Cloud コンソールで次の操作を行います。
[Kubernetes クラスタ] ページに移動します。
[クラスタの詳細] ビューを開くには、検査するクラスタの名前をクリックします。
[オブザーバビリティ] タブをクリックします。
左側のメニューで [起動レイテンシ] を選択します。
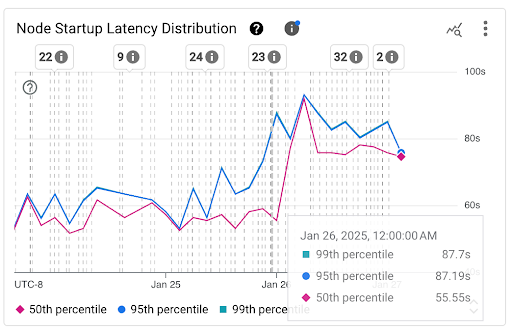
ノードの起動レイテンシの分布を表示する
ノードの起動レイテンシは、ノードの CreationTimestamp から Kubernetes node ready ステータスまでの時間を測定する起動レイテンシ合計を指します。ノードの起動レイテンシは、次の 2 つのグラフで確認できます。
[ノード起動レイテンシの分布] グラフ: このグラフには、固定の 3 時間間隔(午前 0 時~午前 3 時、午前 3 時~午前 6 時など)でノード起動イベントの観測に基づいて計算されたノード起動レイテンシのパーセンタイル(50 パーセンタイル、95 パーセンタイル、99 パーセンタイル)が表示されます。このグラフは、次の目的で使用できます。
- ベースライン ノードの起動レイテンシを把握する。
- ノード起動レイテンシの経時的な変化を特定する。
- ノードの起動レイテンシの変化を、クラスタの更新やノードプールの更新などの最近のイベントと関連付ける。ダッシュボードの上部にある [アノテーション] リストでイベントを選択できます。
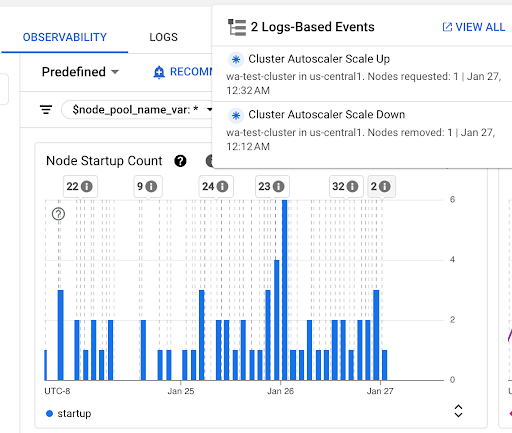
[ノード起動数] グラフ: 選択した期間に起動したノードの数を示します。このグラフは、次の目的で使用できます。
- 特定の時間間隔のノード起動レイテンシ分布のパーセンタイルを計算するために使用されるノードのサンプルサイズを把握する。
- ノードプールの更新やクラスタ オートスケーラー イベントなど、ノードの起動の原因を把握する。ダッシュボードの上部にある [アノテーション] リストでイベントを選択できます。
個々のノードの起動レイテンシを表示する
個々のノードのレイテンシを比較すると、さまざまなノード構成がノードの起動レイテンシに与える影響をテストし、要件に基づいて最適な構成を特定できます。個々のノードの起動レイテンシは、[ノード起動レイテンシ] タイムライン グラフと関連するリストで確認できます。
[ノード起動レイテンシ] タイムライン グラフを使用して、個々のノードの起動をクラスタの更新やノードプールの更新などの最近のイベントと関連付けます。他のノードと比較して起動レイテンシが変化した潜在的原因を特定できます。ダッシュボードの上部にある [アノテーション] リストでイベントを選択できます。
[ノード起動レイテンシ] リストを使用して、起動に最も時間がかかったノードと最も時間がかからなかったノードを特定します。このリストは [レイテンシ] 列で並べ替えることができます。起動レイテンシが最も大きいノードを特定したら、ノードの起動イベントを他の最近のイベントと関連付けて、レイテンシの悪化をトラブルシューティングできます。
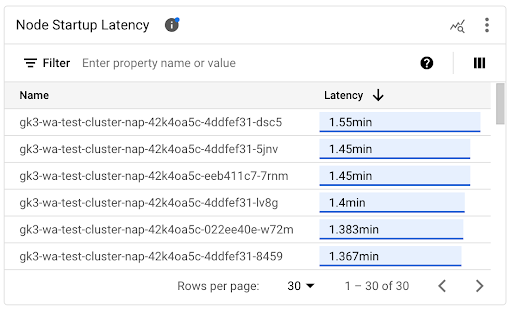
個々のノードが作成された日時を確認するには、対応するノード作成イベントの protoPayload.metadata.creationTimestamp フィールドの値を確認します。protoPayload.metadata.creationTimestamp フィールドを表示するには、ログ エクスプローラで次のクエリを実行します。
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
ノードプールの起動レイテンシを表示する
ノードプールに異なる構成(異なるワークロードを実行するなど)がある場合は、ノードプールごとにノードの起動レイテンシを個別にモニタリングする必要がある場合があります。ノードプール間でノードの起動レイテンシを比較すると、ノード構成がノードの起動レイテンシにどのように影響するかを把握し、レイテンシを最適化できます。
デフォルトでは、[ノード起動レイテンシ] ダッシュボードには、クラスタ内のすべてのノードプールにおける起動レイテンシ分布の集計と個々のノードの起動レイテンシが表示されます。特定のノードプールのノード起動レイテンシを表示するには、ダッシュボードの上部にある $node_pool_name_var フィルタを使用してノードプールの名前を選択します。
次のステップ
- 指標に基づいて Pod の自動スケーリングを最適化する方法を確認する。
- GKE でコールド スタート レイテンシを短縮する方法の詳細を確認する。
- イメージ ストリーミングを使用してイメージの pull レイテンシを短縮する方法を確認する。
- 水平 Pod 自動スケーリングのチューニングの驚くべき経済性を確認する。
- 自動アプリケーション モニタリングでワークロードをモニタリングする。