Cette page décrit les métriques et les tableaux de bord disponibles pour surveiller la latence de démarrage des charges de travail Google Kubernetes Engine (GKE) et des nœuds de cluster sous-jacents. Vous pouvez utiliser les métriques pour suivre, résoudre les problèmes et réduire la latence au démarrage.
Cette page s'adresse aux administrateurs et opérateurs de plate-forme qui doivent surveiller et optimiser la latence de démarrage de leurs charges de travail. Pour en savoir plus sur les rôles courants que nous citons dans le contenu Google Cloud , consultez Rôles utilisateur et tâches courantes de GKE.
Présentation
La latence au démarrage a un impact important sur la façon dont votre application répond aux pics de trafic, sur la rapidité avec laquelle ses répliques se remettent des perturbations et sur l'efficacité des coûts d'exploitation de vos clusters et charges de travail. La surveillance de la latence de démarrage de vos charges de travail peut vous aider à détecter les dégradations de latence et à suivre l'impact des mises à jour de charge de travail et d'infrastructure sur la latence de démarrage.
L'optimisation de la latence de démarrage des charges de travail présente les avantages suivants :
- Réduit la latence de réponse de votre service aux utilisateurs lors des pics de trafic.
- Réduit la capacité de diffusion excédentaire nécessaire pour absorber les pics de demande pendant la création de répliques.
- Réduit le temps d'inactivité des ressources déjà déployées et en attente du démarrage des ressources restantes lors des calculs par lot.
Avant de commencer
Avant de commencer, effectuez les tâches suivantes :
- Activez l'API Google Kubernetes Engine. Activer l'API Google Kubernetes Engine
- Si vous souhaitez utiliser Google Cloud CLI pour cette tâche, installez puis initialisez gcloud CLI. Si vous avez déjà installé la gcloud CLI, obtenez la dernière version en exécutant la commande
gcloud components update. Il est possible que les versions antérieures de gcloud CLI ne permettent pas d'exécuter les commandes de ce document.
Activez les API Cloud Logging et Cloud Monitoring.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Conditions requises
Pour afficher les métriques et les tableaux de bord concernant la latence de démarrage des charges de travail, votre cluster GKE doit répondre aux exigences suivantes :
- Vous devez disposer de GKE version 1.31.1-gke.1678000 ou ultérieure.
- Vous devez configurer la collecte des métriques système.
- Vous devez configurer la collecte des journaux système.
- Activez les métriques Kube State Metrics avec le composant
PODsur vos clusters pour afficher les métriques des pods et des conteneurs.
Rôles et autorisations requis
Pour obtenir les autorisations nécessaires pour activer la génération de journaux, et pour accéder aux journaux et les traiter, demandez à votre administrateur de vous accorder les rôles IAM suivants :
-
Affichez les clusters, les nœuds et les charges de travail GKE :
Lecteur Kubernetes Engine (
roles/container.viewer) dans votre projet. -
Accéder aux métriques de latence au démarrage et afficher les tableaux de bord :
Lecteur Monitoring (
roles/monitoring.viewer) sur votre projet -
Accédez aux journaux contenant des informations sur la latence, comme les événements d'extraction d'images Kubelet, et affichez-les dans l'explorateur de journaux et l'analyse de journaux :
Lecteur de journaux (
roles/logging.viewer) sur votre projet
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Vous pouvez également obtenir les autorisations requises avec des rôles personnalisés ou d'autres rôles prédéfinis.
Métriques de latence au démarrage
Les métriques de latence au démarrage sont incluses dans les métriques système GKE et sont exportées vers Cloud Monitoring dans le même projet que le cluster GKE.
Les noms des métriques Cloud Monitoring figurant dans ce tableau doivent être précédés du préfixe kubernetes.io/. Ce préfixe a été omis dans les entrées du tableau.
| Type de métrique (Niveaux de la hiérarchie des ressources) Nom à afficher |
|
|---|---|
|
Genre, Type, Unité
Ressources surveillées |
Description Libellés |
pod/latencies/pod_first_ready
(projet)
Latence du premier pod prêt |
|
GAUGE, Double, s
k8s_pod |
Latence de démarrage de bout en bout du pod (de Created à Ready), y compris les extractions d'images. Échantillonné toutes les 60 secondes. |
node/latencies/startup
(projet)
Latence de démarrage des nœuds |
|
GAUGE, INT64, s
k8s_node |
Latence de démarrage totale du nœud, de l'instance GCE CreationTimestamp à Kubernetes node ready pour la première fois. Échantillonné toutes les 60 secondes.accelerator_family : classification des nœuds en fonction des accélérateurs matériels : gpu, tpu, cpu.
kube_control_plane_available : indique si la demande de création de nœud a été reçue lorsque KCP (kube control plane) était disponible.
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(projet)
Latence de scaling par recommandation HPA |
|
GAUGE, DOUBLE, s
k8s_scale |
Latence de la recommandation de scaling de l'autoscaler horizontal de pods (AHP) (temps écoulé entre la création des métriques et l'application de la recommandation de scaling correspondante au serveur d'API) pour la cible AHP. Échantillonné toutes les 60 secondes. Après échantillonnage, les données ne sont pas visibles pendant un délai pouvant atteindre 20 secondes.metric_type : type de source de métrique. Il doit s'agir de l'une des valeurs suivantes : "ContainerResource", "External", "Object", "Pods" ou "Resource".
|
Afficher le tableau de bord "Latence de démarrage" pour les charges de travail
Le tableau de bord Latence de démarrage pour les charges de travail n'est disponible que pour les déploiements. Pour afficher les métriques de latence de démarrage des déploiements, procédez comme suit dans la console Google Cloud :
Accédez à la page "Charges de travail".
Pour ouvrir la vue Détails du déploiement, cliquez sur le nom de la charge de travail que vous souhaitez inspecter.
Cliquez sur l'onglet Observabilité.
Sélectionnez Latence au démarrage dans le menu de gauche.
Afficher la distribution de la latence de démarrage des pods
La latence de démarrage des pods fait référence à la latence de démarrage totale, y compris les extractions d'images, qui mesure le temps écoulé entre l'état Created du pod et l'état Ready. Vous pouvez évaluer la latence de démarrage des pods à l'aide des deux graphiques suivants :
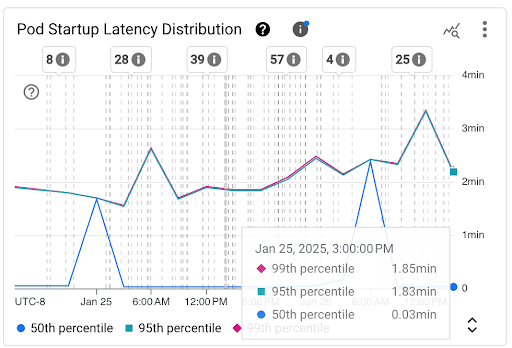
Graphique Distribution de la latence de démarrage des pods : ce graphique affiche les centiles de latence de démarrage des pods (50e, 95e et 99e centiles) calculés en fonction des observations des événements de démarrage des pods sur des intervalles de temps fixes de trois heures (par exemple, de 0h00 à 3h00 et de 3h00 à 6h00). Vous pouvez utiliser ce graphique pour les raisons suivantes :
- Comprenez la latence de démarrage de référence de votre pod.
- Identifier les changements de latence de démarrage des pods au fil du temps.
- Corrélez les modifications de la latence de démarrage des pods avec les événements récents, tels que les déploiements de charges de travail ou les événements de l'autoscaler de cluster. Vous pouvez sélectionner les événements dans la liste Annotations en haut du tableau de bord.
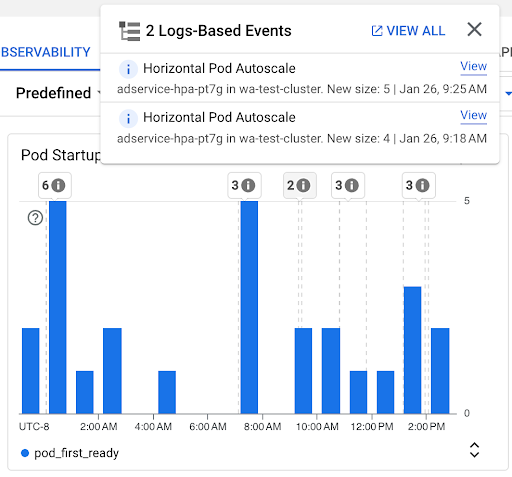
Graphique Nombre de démarrages de pods : ce graphique indique le nombre de pods qui ont été démarrés au cours des intervalles de temps sélectionnés. Vous pouvez utiliser ce tableau pour les objectifs suivants :
- Comprendre les tailles d'échantillon de pods utilisées pour calculer les centiles de la distribution de la latence de démarrage des pods pour un intervalle de temps donné.
- Comprendre les causes des démarrages de pods, comme les événements de déploiements de charges de travail ou d'autoscaler horizontal de pods. Vous pouvez sélectionner les événements dans la liste Annotations en haut du tableau de bord.
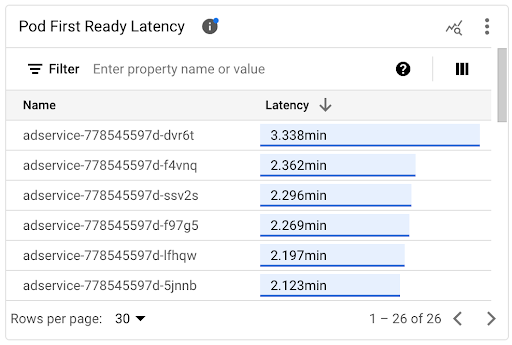
Afficher la latence de démarrage des pods individuels
Vous pouvez afficher la latence de démarrage des pods individuels dans le graphique chronologique Latence du premier prêt du pod et la liste associée.
- Utilisez le graphique chronologique Latence du premier pod prêt pour corréler les démarrages de pods individuels avec les événements récents, tels que les événements de l'autoscaler horizontal de pods ou de l'autoscaler de cluster. Vous pouvez sélectionner ces événements dans la liste Annotations en haut du tableau de bord. Ce graphique vous aide à déterminer les causes potentielles de toute modification de la latence de démarrage par rapport à d'autres pods.
- Utilisez la liste Latence de préparation du premier pod pour identifier les pods individuels qui ont mis le plus ou le moins de temps à démarrer. Vous pouvez trier la liste par la colonne Latence. Lorsque vous identifiez les pods dont la latence de démarrage est la plus élevée, vous pouvez résoudre les problèmes de dégradation de la latence en mettant en corrélation les événements de démarrage des pods avec d'autres événements récents.
Pour savoir quand un pod individuel a été créé, consultez la valeur du champ timestamp dans un événement de création de pod correspondant. Pour afficher le champ timestamp, exécutez la requête suivante dans l'explorateur de journaux :
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
Pour lister tous les événements de création de pods pour votre charge de travail, utilisez le filtre suivant dans la requête précédente :
protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Lorsque vous comparez les latences de différents pods, vous pouvez tester l'impact de diverses configurations sur la latence de démarrage des pods et identifier une configuration optimale en fonction de vos besoins.
Déterminer la latence de planification des pods
La latence de planification des pods correspond au temps écoulé entre la création d'un pod et sa planification sur un nœud. La latence de planification des pods contribue au temps de démarrage de bout en bout d'un pod. Elle est calculée en soustrayant les codes temporels d'un événement de planification de pod et d'une demande de création de pod.
Vous trouverez le code temporel d'un événement de programmation de pod individuel dans le champ jsonPayload.eventTime d'un événement de programmation de pod correspondant. Pour afficher le champ jsonPayload.eventTime, exécutez la requête suivante dans l'explorateur de journaux :
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
Pour lister tous les événements de planification des pods pour votre charge de travail, utilisez le filtre suivant dans la requête précédente :
resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Afficher la latence d'extraction d'image
La latence d'extraction des images de conteneur contribue à la latence de démarrage des pods dans les scénarios où l'image n'est pas encore disponible sur le nœud ou doit être actualisée. Lorsque vous optimisez la latence d'extraction d'images, vous réduisez la latence de démarrage de votre charge de travail lors des événements de scale-out du cluster.
Vous pouvez consulter le tableau Événements d'extraction d'images Kubelet pour savoir quand les images de conteneur de charge de travail ont été extraites et combien de temps le processus a duré.
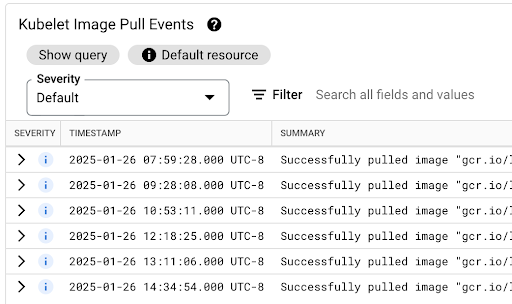
La latence d'extraction d'image est disponible dans le champ jsonPayload.message, qui contient un message semblable à ce qui suit :
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
Afficher la répartition de la latence des recommandations de scaling AHP
La latence des recommandations de scaling de l'autoscaler horizontal de pods (AHP) pour la cible AHP correspond au temps écoulé entre la création des métriques et l'application de la recommandation de scaling correspondante au serveur d'API. Lorsque vous optimisez la latence des recommandations de scaling AHP, vous réduisez la latence de démarrage de votre charge de travail lors des événements de scale-out.
Le scaling AHP peut être consulté dans les deux graphiques suivants :
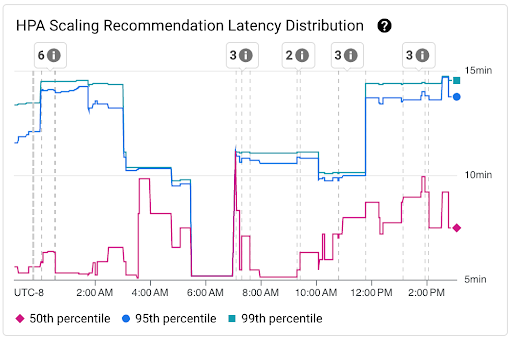
Graphique Répartition de la latence des recommandations de scaling HPA : ce graphique affiche les centiles de latence des recommandations de scaling AHP (50e, 95e et 99e centiles) calculés en fonction des observations des recommandations de scaling AHP sur des intervalles de temps de trois heures. Vous pouvez utiliser ce graphique aux fins suivantes :
- Comprendre la latence de référence des recommandations de scaling AHP
- Identifiez les fluctuations de la latence des recommandations de scaling AHP au fil du temps.
- Corrélez les variations de la latence des recommandations de scaling AHP avec les événements récents. Vous pouvez sélectionner les événements dans la liste Annotations en haut du tableau de bord.
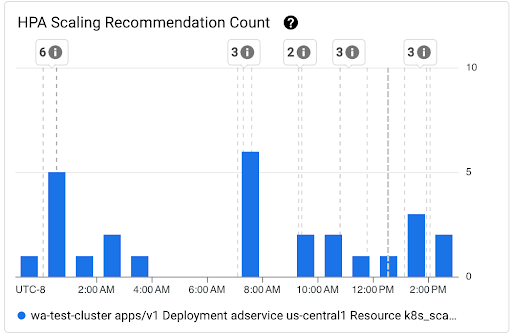
Graphique Nombre de recommandations de scaling HPA : ce graphique indique le nombre de recommandations de scaling AHP observées au cours de l'intervalle de temps sélectionné. Utilisez le graphique pour effectuer les tâches suivantes :
- Comprendre les tailles d'échantillon des recommandations de scaling AHP. Les échantillons sont utilisés pour calculer les centiles de la distribution de la latence des recommandations de scaling AHP pour un intervalle de temps donné.
- Établissez une corrélation entre les recommandations de scaling HPA et les nouveaux événements de démarrage de pod, ainsi qu'avec les événements de l'autoscaler horizontal de pods. Vous pouvez sélectionner les événements dans la liste Annotations en haut du tableau de bord.
Afficher les problèmes de planification pour les pods
Les problèmes de planification des pods peuvent avoir un impact sur la latence de démarrage de bout en bout de votre charge de travail. Pour réduire la latence de démarrage de bout en bout de votre charge de travail, identifiez et résolvez ces problèmes.
Voici les deux graphiques disponibles pour suivre ces problèmes :
- Le graphique Pods non programmables/en attente/en échec indique le nombre de pods non programmables, en attente et en échec au fil du temps.
- Le graphique Conteneurs Intervalle entre les tentatives/En attente/Échec aptitude indique le nombre de conteneurs dans ces états au fil du temps.
Afficher le tableau de bord de la latence de démarrage pour les nœuds
Pour afficher les métriques de latence de démarrage des nœuds, procédez comme suit dans la consoleGoogle Cloud :
Accédez à la page Clusters Kubernetes.
Pour ouvrir la vue Détails du cluster, cliquez sur le nom du cluster que vous souhaitez inspecter.
Cliquez sur l'onglet Observabilité.
Dans le menu de gauche, sélectionnez Latence au démarrage.
Afficher la distribution de la latence de démarrage des nœuds
La latence de démarrage d'un nœud fait référence à la latence de démarrage totale, qui mesure le temps écoulé entre le CreationTimestamp du nœud et l'état Kubernetes node ready. La latence de démarrage des nœuds peut être consultée dans les deux graphiques suivants :
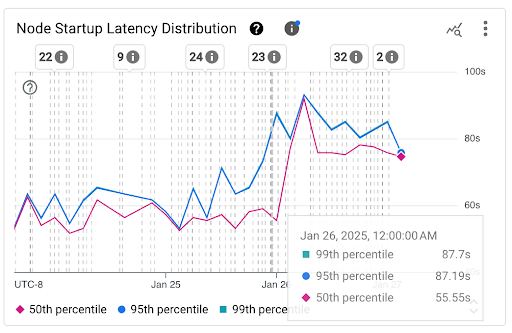
Graphique Distribution de la latence de démarrage des nœuds : ce graphique affiche les centiles de latence de démarrage des nœuds (50e, 95e et 99e centiles) calculés en fonction des observations des événements de démarrage des nœuds sur des intervalles de temps fixes de trois heures (par exemple, de 0h00 à 3h00 et de 3h00 à 6h00). Vous pouvez utiliser ce graphique pour les raisons suivantes :
- Comprenez la latence de démarrage de votre nœud de référence.
- Identifier les changements de latence de démarrage des nœuds au fil du temps.
- Établissez une corrélation entre les variations de la latence de démarrage des nœuds et les événements récents, tels que les mises à jour de clusters ou de pools de nœuds. Vous pouvez sélectionner les événements dans la liste Annotations en haut du tableau de bord.
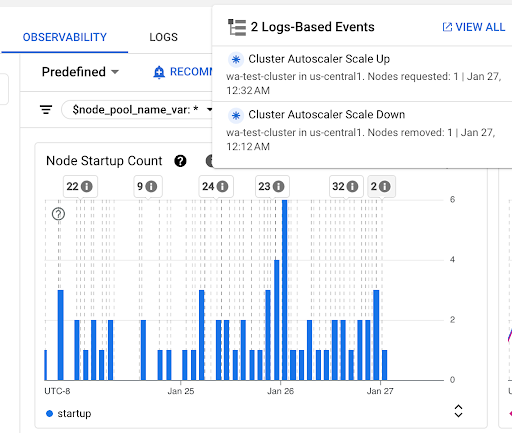
Graphique Nombre de démarrages de nœuds : ce graphique indique le nombre de nœuds démarrés au cours des intervalles de temps sélectionnés. Vous pouvez utiliser le graphique pour les objectifs suivants :
- Comprendre les tailles d'échantillon de nœuds utilisées pour calculer les centiles de distribution de la latence de démarrage des nœuds pour un intervalle de temps donné.
- Comprendre les causes du démarrage des nœuds, telles que les mises à jour du pool de nœuds ou les événements de l'autoscaler de cluster. Vous pouvez sélectionner les événements dans la liste Annotations en haut du tableau de bord.
Afficher la latence de démarrage des nœuds individuels
Lorsque vous comparez les latences de nœuds individuels, vous pouvez tester l'impact de différentes configurations de nœuds sur la latence de démarrage des nœuds et identifier une configuration optimale en fonction de vos besoins. Vous pouvez afficher la latence de démarrage des nœuds individuels dans le graphique chronologique Latence de démarrage des nœuds et dans la liste associée.
Utilisez le graphique chronologique Latence de démarrage des nœuds pour corréler les démarrages de nœuds individuels avec les événements récents, tels que les mises à jour de clusters ou de pools de nœuds. Vous pouvez identifier les causes potentielles des variations de la latence de démarrage par rapport aux autres nœuds. Vous pouvez sélectionner les événements dans la liste Annotations en haut du tableau de bord.
Utilisez la liste Latence de démarrage des nœuds pour identifier les nœuds individuels qui ont mis le plus ou le moins de temps à démarrer. Vous pouvez trier la liste par la colonne Latence. Lorsque vous identifiez les nœuds présentant la latence de démarrage la plus élevée, vous pouvez résoudre les problèmes de dégradation de la latence en corrélant les événements de démarrage des nœuds avec d'autres événements récents.
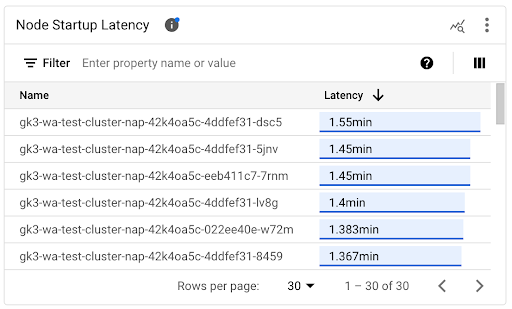
Pour savoir quand un nœud individuel a été créé, consultez la valeur du champ protoPayload.metadata.creationTimestamp dans un événement de création de nœud correspondant. Pour afficher le champ protoPayload.metadata.creationTimestamp, exécutez la requête suivante dans l'explorateur de journaux :
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
Afficher la latence de démarrage dans un pool de nœuds
Si vos pools de nœuds ont des configurations différentes (par exemple, pour exécuter différentes charges de travail), vous devrez peut-être surveiller la latence de démarrage des nœuds séparément par pool de nœuds. Lorsque vous comparez les latences de démarrage des nœuds dans vos pools de nœuds, vous pouvez obtenir des informations sur l'impact de la configuration des nœuds sur la latence de démarrage des nœuds et, par conséquent, optimiser la latence.
Par défaut, le tableau de bord Latence de démarrage des nœuds affiche la distribution agrégée de la latence de démarrage et les latences de démarrage individuelles des nœuds pour tous les pools de nœuds d'un cluster. Pour afficher la latence de démarrage des nœuds pour un pool de nœuds spécifique, sélectionnez le nom du pool de nœuds à l'aide du filtre $node_pool_name_var situé en haut du tableau de bord.
Étapes suivantes
- Découvrez comment optimiser l'autoscaling des pods en fonction des métriques.
- Découvrez comment réduire la latence de démarrage à froid sur GKE.
- Découvrez comment réduire la latence d'extraction des images avec le streaming d'images.
- Découvrez l'étonnante économie de l'ajustement de l'autoscaling horizontal des pods.
- Surveillez vos charges de travail grâce à la surveillance automatique des applications.