Auf dieser Seite wird beschrieben, wie Sie die Echtzeitreplikation von Daten aus SAP-Anwendungen mithilfe von SAP Landscape Transformation (SLT) aktivieren. Google Cloud Die Inhalte beziehen sich auf die Plug-ins SAP SLT Replication und SAP SLT No RFC Replication, die im Cloud Data Fusion Hub verfügbar sind. Es zeigt die Konfigurationen für das SAP-Quellsystem, SLT, Cloud Storage und Cloud Data Fusion für Folgendes:
- SAP-Metadaten und -Tabellendaten mit SAP SLT an Google Cloud senden
- Erstellen Sie einen Cloud Data Fusion-Replikationsjob, der die Daten aus einem Cloud Storage-Bucket liest.
Mit der SAP SLT-Replikation können Sie Ihre Daten kontinuierlich und in Echtzeit aus SAP-Quellen in BigQuery replizieren. Sie können Datenübertragungen aus SAP-Systemen ohne Programmierung konfigurieren und ausführen.
So funktioniert die SLT-Replikation in Cloud Data Fusion:
- Die Daten stammen aus einem SAP-Quellsystem.
- SLT überwacht und liest die Daten und sendet sie an Cloud Storage.
- Cloud Data Fusion ruft Daten aus dem Speicher-Bucket ab und schreibt sie in BigQuery.
Sie können Daten aus unterstützten SAP-Systemen übertragen, einschließlich SAP-Systemen, die in Google Cloudgehostet werden.
Weitere Informationen finden Sie in der Übersicht über SAP in Google Cloud Google Cloud und in den Supportdetails.
Hinweis
Für die Verwendung dieses Plug-ins benötigen Sie Domainkenntnisse in folgenden Bereichen:
- Pipelines in Cloud Data Fusion erstellen
- Zugriffsverwaltung mit IAM
- SAP Cloud- und lokale ERP-Systeme (Enterprise Resource Planning) konfigurieren
Administratoren und Nutzer, die die Konfigurationen ausführen
Die Aufgaben auf dieser Seite werden von Personen mit den folgenden Rollen in Google Cloud oder in ihrem SAP-System ausgeführt:
| Nutzertyp | Beschreibung |
|---|---|
| Google Cloud-Administrator | Nutzer, denen diese Rolle zugewiesen wurde, sind Administratoren von Google Cloud-Konten. |
| Cloud Data Fusion-Nutzer | Nutzer, denen diese Rolle zugewiesen wurde, sind berechtigt, Datenpipelines zu entwerfen und auszuführen. Ihnen wird mindestens die Rolle „Data Fusion-Betrachter“ (
roles/datafusion.viewer) zugewiesen. Wenn Sie die rollenbasierte Zugriffssteuerung verwenden, benötigen Sie möglicherweise zusätzliche Rollen.
|
| SAP-Administrator | Nutzer, denen diese Rolle zugewiesen wurde, sind Administratoren des SAP-Systems. Sie haben Zugriff auf den Download von Software von der SAP-Dienstwebsite. Dies ist keine IAM-Rolle. |
| SAP-Nutzer | Nutzer, denen diese Rolle zugewiesen wurde, sind berechtigt, eine Verbindung zu einem SAP-System herzustellen. Dies ist keine IAM-Rolle. |
Unterstützte Replikationsvorgänge
Das SAP SLT-Replikations-Plug-in unterstützt die folgenden Vorgänge:
Datenmodellierung: Alle Vorgänge zur Datenmodellierung (insert, delete und update) werden von diesem Plug-in unterstützt.
Datendefinition: Wie im SAP-Hinweis 2055599 beschrieben (SAP-Supportanmeldung erforderlich), gibt es Einschränkungen bei den Änderungen an der Tabellenstruktur des Quellsystems, die von SLT automatisch repliziert werden. Einige Datendefinitionsvorgänge werden vom Plug-in nicht unterstützt. Sie müssen sie manuell weitergeben.
- Unterstützt:
- Nicht-Schlüsselfeld hinzufügen (nachdem Sie Änderungen in SE11 vorgenommen haben, aktivieren Sie die Tabelle mit SE14)
- Nicht unterstützt:
- Schlüsselfeld hinzufügen/entfernen
- Nicht-Schlüsselfeld löschen
- Datentypen ändern
SAP-Anforderungen
In Ihrem SAP-System sind die folgenden Elemente erforderlich:
- Sie haben SLT Server Version 2011 SP17 oder höher entweder auf dem SAP-Quellsystem (eingebettet) oder als dediziertes SLT-Hubsystem installiert.
- Ihr SAP-Quellsystem ist SAP ECC oder SAP S/4HANA, das DMIS 2011 SP17 oder höher unterstützt, z. B. DMIS 2018 oder DMIS 2020.
- Das SAP-Add-on für die Benutzeroberfläche muss mit Ihrer SAP NetWeaver-Version kompatibel sein.
Ihr Supportpaket unterstützt
/UI2/CL_JSON-KlassePL 12oder höher. Andernfalls implementieren Sie den neuesten SAP-Hinweis für die/UI2/CL_JSON-Klassecorrectionsgemäß der Version Ihres UI-Add-ons, z. B. SAP-Hinweis 2798102 fürPL12.Es gelten folgende Sicherheitsmaßnahmen:
Cloud Data Fusion-Anforderungen
- Sie benötigen eine Cloud Data Fusion-Instanz der Version 6.4.0 oder höher, beliebige Version.
- Dem Dienstkonto, das der Cloud Data Fusion-Instanz zugewiesen ist, werden die erforderlichen Rollen gewährt (siehe Dem Dienstkonto die Berechtigung „Service Account User“ zuweisen).
- Für private Cloud Data Fusion-Instanzen ist VPC-Peering erforderlich.
Google Cloud -Anforderungen
- Aktivieren Sie die Cloud Storage API in Ihrem Google Cloud Projekt.
- Dem Cloud Data Fusion-Nutzer muss die Berechtigung zum Erstellen von Ordnern im Cloud Storage-Bucket erteilt werden (siehe IAM-Rollen für Cloud Storage).
- Optional: Legen Sie die Aufbewahrungsrichtlinie fest, falls dies von Ihrer Organisation verlangt wird.
Storage-Bucket erstellen
Bevor Sie einen SLT-Replikationsjob erstellen, erstellen Sie den Cloud Storage-Bucket. Der Job überträgt Daten in den Bucket und aktualisiert den Staging-Bucket alle fünf Minuten. Wenn Sie den Job ausführen, liest Cloud Data Fusion die Daten im Speicher-Bucket und schreibt sie in BigQuery.
Wenn SLT auf Google Cloudinstalliert ist
Der SLT-Server muss die Berechtigung zum Erstellen und Ändern von Cloud Storage-Objekten im von Ihnen erstellten Bucket haben.
Weisen Sie dem Dienstkonto mindestens die folgenden Rollen zu:
- Ersteller von Dienstkonto-Token (
roles/iam.serviceAccountTokenCreator) - Service Usage-Nutzer (
roles/serviceusage.serviceUsageConsumer) - Storage-Objekt-Administrator (
roles/storage.objectAdmin)
Wenn SLT nicht auf Google Cloudinstalliert ist
Installieren Sie Cloud VPN oder Cloud Interconnect zwischen der SAP-VM undGoogle Cloud , um eine Verbindung zu einem internen Metadatenendpunkt zu ermöglichen. Weitere Informationen finden Sie unter Privaten Google-Zugriff für lokale Hosts konfigurieren.
Wenn interne Metadaten nicht zugeordnet werden können:
Installieren Sie die Google Cloud CLI entsprechend dem Betriebssystem der Infrastruktur, auf der SLT ausgeführt wird.
Erstellen Sie ein Dienstkonto im Google Cloud -Projekt, in dem Cloud Storage aktiviert ist.
Autorisieren Sie auf dem SLT-Betriebssystem den Zugriff auf Google Cloud mit einem Dienstkonto.
Erstellen Sie einen API-Schlüssel für das Dienstkonto und autorisieren Sie den Cloud Storage-bezogenen Umfang.
Importieren Sie den API-Schlüssel mithilfe der Befehlszeile in die zuvor installierte gcloud CLI.
Wenn Sie den gcloud-Befehl für die Befehlszeile aktivieren möchten, mit dem das Zugriffstoken ausgegeben wird, konfigurieren Sie den SAP-Betriebssystembefehl im SM69-Tool der Transaktion im SLT-System.
Zugriffstoken ausdrucken
Der SAP-Administrator konfiguriert den Betriebssystembefehl SM69, der ein Zugriffstoken von Google Cloudabruft.
Erstellen Sie ein Script, um ein Zugriffstoken auszugeben, und konfigurieren Sie einen SAP-Betriebssystembefehl, um das Script als Nutzer <sid>adm vom SAP LT Replication Server-Host aufzurufen.
Linux
So erstellen Sie einen Betriebssystembefehl:
Erstellen Sie auf dem SAP LT Replication Server-Host in einem Verzeichnis, auf das
<sid>admzugreifen kann, ein Bash-Script, das die folgenden Zeilen enthält:PATH_TO_GCLOUD_CLI/bin/gcloud auth print-access-token SERVICE_ACCOUNT_NAMEErstellen Sie mit der SAP-Benutzeroberfläche einen externen Betriebssystembefehl:
- Geben Sie die Transaktion
SM69ein. - Klicken Sie auf Erstellen.
- Geben Sie im Bereich Befehl des Bereichs Externer Befehl den Namen des Befehls ein, z. B.
ZGOOGLE_CDF_TOKEN. Im Abschnitt Definition:
- Geben Sie im Feld Betriebssystembefehl den Wert
shals Scriptdateiendung ein. Geben Sie im Feld Parameter für Betriebssystembefehl Folgendes ein:
/PATH_TO_SCRIPT/FILE_NAME.sh
- Geben Sie im Feld Betriebssystembefehl den Wert
Klicken Sie auf Speichern.
Klicken Sie auf Ausführen, um das Script zu testen.
Klicken Sie noch einmal auf Ausführen.
Ein Google Cloud -Token wird zurückgegeben und unten im Bereich der SAP-Benutzeroberfläche angezeigt.
- Geben Sie die Transaktion
Windows
Erstellen Sie mit der SAP-Benutzeroberfläche einen externen Betriebssystembefehl:
- Geben Sie die Transaktion
SM69ein. - Klicken Sie auf Erstellen.
- Geben Sie im Bereich Befehl des Bereichs Externer Befehl den Namen des Befehls ein, z. B.
ZGOOGLE_CDF_TOKEN. Im Abschnitt Definition:
- Geben Sie im Feld Betriebssystembefehl den Wert
cmd /cein. Geben Sie im Feld Parameter für Betriebssystembefehl Folgendes ein:
gcloud auth print-access-token SERVICE_ACCOUNT_NAME
- Geben Sie im Feld Betriebssystembefehl den Wert
Klicken Sie auf Speichern.
Klicken Sie auf Ausführen, um das Script zu testen.
Klicken Sie noch einmal auf Ausführen.
Ein Google Cloud -Token wird zurückgegeben und unten im Bereich der SAP-Benutzeroberfläche angezeigt.
Anforderungen an SLT
Der SLT-Connector muss folgendermaßen eingerichtet sein:
- Der Connector unterstützt SAP ECC NW 7.02, DMIS 2011 SP17 und höher.
- Konfigurieren Sie eine RFC- oder Datenbankverbindung zwischen SLT und dem Cloud Storage-System.
- Richten Sie die SSL-Zertifikate ein:
- Laden Sie die folgenden CA-Zertifikate aus dem Repository von Google Trust Services herunter:
- GTS Root R1
- GTS CA 1C3
- Verwenden Sie in der SAP-Benutzeroberfläche die Transaktion
STRUST, um sowohl das Root- als auch das untergeordnete Zertifikat in den OrdnerSSL Client (Standard) PSEzu importieren.
- Laden Sie die folgenden CA-Zertifikate aus dem Repository von Google Trust Services herunter:
- Der Internet Communication Manager (ICM) muss für HTTPS eingerichtet sein. Die HTTP- und HTTPS-Ports müssen im SAP SLT-System verwaltet und aktiviert sein.
Das lässt sich mit dem Transaktionscode
SMICM > Servicesprüfen. - Aktivieren Sie den Zugriff auf Google Cloud APIs auf der VM, auf der das SAP SLT-System gehostet wird. So ist eine private Kommunikation zwischen denGoogle Cloud Diensten möglich, ohne dass sie über das öffentliche Internet geleitet werden.
- Achten Sie darauf, dass das Netzwerk das erforderliche Volumen und die erforderliche Geschwindigkeit der Datenübertragung zwischen der SAP-Infrastruktur und Cloud Storage unterstützt. Für eine erfolgreiche Installation werden Cloud VPN und/oder Cloud Interconnect empfohlen. Der Durchsatz der Streaming API hängt von den Kontingenten ab, die Ihrem Cloud Storage-Projekt gewährt wurden.
SLT Replication Server konfigurieren
Der SAP-Nutzer führt die folgenden Schritte aus.
In den folgenden Schritten stellen Sie eine Verbindung zwischen dem SLT-Server und dem Quellsystem und dem Bucket in Cloud Storage her. Geben Sie dabei das Quellsystem, die zu replizierenden Datentabellen und den Zielspeicher-Bucket an.
Google ABAP SDK konfigurieren
So konfigurieren Sie SLT für die Datenreplizierung (einmal pro Cloud Data Fusion-Instanz):
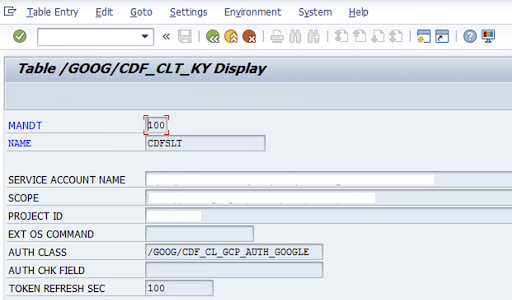
Zum Konfigurieren des SLT-Connectors gibt der SAP-Nutzer auf dem Konfigurationsbildschirm (SAP-Transaktion
/GOOG/CDF_SETTINGS) die folgenden Informationen zum Google Cloud Dienstkontoschlüssel für die Übertragung von Daten in Cloud Storage ein. Konfiguriere die folgenden Properties in der Tabelle /GOOG/CDF_CLT_KY mithilfe der Transaktion SE16 und notiere dir diesen Schlüssel:- NAME: Der Name Ihres Dienstkontoschlüssels (z. B.
CDFSLT) - SERVICE_ACCOUNT_NAME: Der Name des IAM-Dienstkontos
- SCOPE: Der Umfang des Dienstkontos
- PROJECT ID: Die ID Ihres Google Cloud Projekts
- Optional: EXT-Betriebssystembefehl: Verwenden Sie dieses Feld nur, wenn SLT nicht auf Google Cloudinstalliert ist.
AUTH CLASS: Wenn der Befehl des Betriebssystems in Tabelle
/GOOG/CDF_CLT_KYeingerichtet ist, verwenden Sie den festen Wert/GOOG/CDF_CL_GCP_AUTH.TOKEN REFRESH SEC: Dauer der Aktualisierung des Autorisierungstokens
- NAME: Der Name Ihres Dienstkontoschlüssels (z. B.
Replikationskonfiguration erstellen
Erstelle eine Replikationskonfiguration im Transaktionscode LTRC.
- Bevor Sie mit der LTRC-Konfiguration fortfahren, prüfen Sie, ob die RFC-Verbindung zwischen SLT und dem SAP-Quellsystem hergestellt ist.
- Einer SLT-Konfiguration können mehrere SAP-Tabellen für die Replikation zugewiesen sein.
Rufen Sie den Transaktionscode
LTRCauf und klicken Sie auf Neue Konfiguration.
Geben Sie den Konfigurationsnamen und die Beschreibung ein und klicken Sie auf Weiter.
Geben Sie die RFC-Verbindung des SAP-Quellsystems an und klicken Sie auf Weiter.
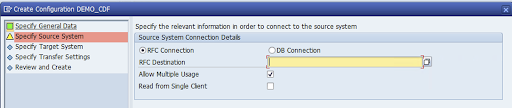
Wählen Sie unter „Zielsystem-Verbindungsdetails“ die Option Sonstiges aus.
Maximieren Sie das Feld Szenario für die RFC-Kommunikation, wählen Sie SLT SDK aus und klicken Sie auf Weiter.
Öffnen Sie das Fenster Übertragungseinstellungen angeben und geben Sie den Namen der Anwendung ein:
ZGOOGLE_CDF.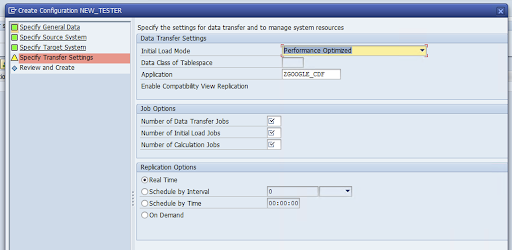
Geben Sie die Anzahl der Datenübertragungsjobs, die Anzahl der anfänglichen Ladejobs und die Anzahl der Berechnungsjobs ein. Weitere Informationen zur Leistung finden Sie im Leitfaden zur Leistungsoptimierung von SAP LT Replication Server.
Klicken Sie auf Echtzeit > Weiter.
Überprüfen Sie die Konfiguration und klicken Sie auf Speichern. Notieren Sie sich die ID der Bulk-Übertragung für die folgenden Schritte.
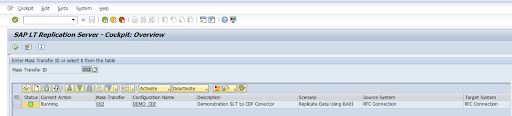
Führen Sie die SAP-Transaktion
/GOOG/CDF_SETTINGSaus, um die ID der Massenübertragung und die Details der SAP-Tabelle beizubehalten.Klicken Sie auf Ausführen oder drücken Sie
F8.Klicken Sie auf das Symbol „Zeile anhängen“, um einen neuen Eintrag zu erstellen.
Geben Sie die Massenübertragungs-ID, den Massenübertragungsschlüssel, den GCP-Schlüsselnamen und den Ziel-GCS-Bucket ein. Klicken Sie das Kästchen Ist aktiv an und speichern Sie die Änderungen.
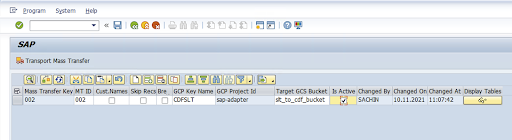
Wählen Sie in der Spalte Konfigurationsname die Konfiguration aus und klicken Sie auf Datenbereitstellung.
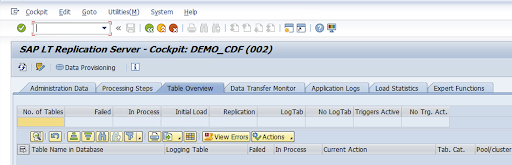
Optional: Passen Sie die Tabellen- und Feldnamen an.
Klicken Sie auf Benutzerdefinierte Namen und speichern Sie die Änderungen.
Klicken Sie auf Anzeige.
Klicken Sie auf die Schaltflächen Zeile anhängen oder Erstellen, um einen neuen Eintrag zu erstellen.
Geben Sie den Namen der SAP-Tabelle und den Namen der externen Tabelle ein, die in BigQuery verwendet werden sollen, und speichern Sie die Änderungen.
Klicken Sie in der Spalte Anzeigefelder auf die Schaltfläche Anzeigen, um die Zuordnung für Tabellenfelder beizubehalten.
Eine Seite mit vorgeschlagenen Zuordnungen wird geöffnet. Optional: Bearbeiten Sie den Namen des temporären Felds und die Feldbeschreibung und speichern Sie dann die Zuordnungen.
Rufen Sie die LTRC-Transaktion auf.
Wählen Sie den Wert in der Spalte Konfigurationsname aus und klicken Sie auf Datenbereitstellung.
Geben Sie den Tabellennamen in das Feld Tabellenname in Datenbank ein und wählen Sie das Replikationsszenario aus.
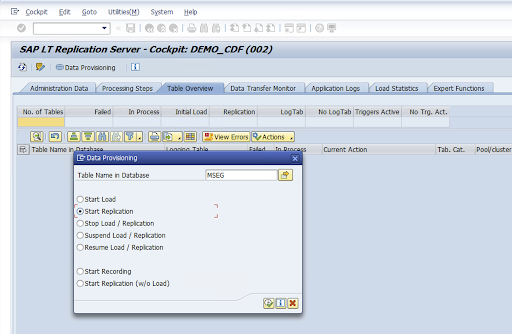
Klicken Sie auf Ausführen. Dadurch wird die SLT SDK-Implementierung ausgelöst und die Übertragung der Daten in den Ziel-Bucket in Cloud Storage gestartet.
SAP-Transportdateien installieren
Zum Entwerfen und Ausführen von Replikationsjobs in Cloud Data Fusion werden die SAP-Komponenten als SAP-Transportdateien bereitgestellt, die in einer ZIP-Datei archiviert werden. Der Download ist verfügbar, wenn Sie das Plug-in im Cloud Data Fusion Hub bereitstellen.
So installieren Sie die SAP-Transporte:
Schritt 1: Transportanfragedateien hochladen
- Melden Sie sich im Betriebssystem der SAP-Instanz an.
- Verwenden Sie den SAP-Transaktionscode
AL11, um den Pfad für den OrdnerDIR_TRANSabzurufen. Normalerweise ist der Pfad/usr/sap/trans/. - Kopieren Sie die Cofiles in den Ordner
DIR_TRANS/cofiles. - Kopieren Sie die Datendateien in den Ordner
DIR_TRANS/data. - Legen Sie für die Daten- und Cofile die Nutzer- und Gruppenzuordnung auf
<sid>admundsapsysfest.
Schritt 2: Transportanfragedateien importieren
Der SAP-Administrator kann die Transportanfragedateien mit dem SAP-Transport-Management-System oder dem Betriebssystem importieren:
SAP-Transportverwaltungssystem
- Melden Sie sich im SAP-System als SAP-Administrator an.
- Geben Sie die Transaktions-STMS ein.
- Klicken Sie auf Übersicht > Importe.
- Doppelklicken Sie in der Spalte „Warteschlange” auf die aktuelle SID.
- Klicken Sie auf Extras > Sonstige Anfragen > Hinzufügen.
- Wählen Sie die Transportanfrage-ID aus und klicken Sie auf Weiter.
- Wählen Sie die Transportanfrage in der Importwarteschlange aus und klicken Sie dann auf Anfrage > Importieren.
- Geben Sie die Clientnummer ein.
Wählen Sie auf dem Tab Optionen die Optionen Originale überschreiben und Ungültige Komponentenversion ignorieren aus (falls verfügbar).
Optional: Wenn Sie die Transports später noch einmal importieren möchten, klicken Sie auf Transportanfragen in der Warteschlange für einen späteren Import belassen und Transportanfragen noch einmal importieren. Dies ist nützlich für SAP-Systemupgrades und Sicherungswiederherstellungen.
Klicken Sie auf Weiter.
Prüfen Sie mit Transaktionen wie
SE80undPFCG, ob das Funktionsmodul und die Autorisierungsrollen erfolgreich importiert wurden.
Betriebssystem
- Melden Sie sich im SAP-System als SAP-Administrator an.
Fügen Sie dem Importpuffer Anfragen hinzu:
tp addtobuffer TRANSPORT_REQUEST_ID SIDBeispiel:
tp addtobuffer IB1K903958 DD1Importieren Sie die Transportanfragen:
tp import TRANSPORT_REQUEST_ID SID client=NNN U1238Ersetzen Sie
NNNdurch die Clientnummer. Beispiel:tp import IB1K903958 DD1 client=800 U1238Prüfen Sie mit den entsprechenden Transaktionen wie
SE80undPFCG, ob das Funktionsmodul und die Autorisierungsrollen erfolgreich importiert wurden.
Erforderliche SAP-Autorisierungen
Zum Ausführen einer Datenpipeline in Cloud Data Fusion benötigen Sie einen SAP-Nutzer. Der SAP-Nutzer muss vom Typ „Kommunikation“ oder „Dialog“ sein. Um die Verwendung von SAP-Dialogressourcen zu vermeiden, wird der Typ „Kommunikation“ empfohlen. Nutzer können vom SAP-Administrator mit dem SAP-Transaktionscode SU01 erstellt werden.
SAP-Autorisierungen sind erforderlich, um den Connector für SAP zu verwalten und zu konfigurieren. Dabei handelt es sich um eine Kombination aus SAP-Standard- und neuen Connector-Autorisierungsobjekten. Sie verwalten Autorisierungsobjekte gemäß den Sicherheitsrichtlinien Ihrer Organisation. In der folgenden Liste werden einige wichtige Autorisierungen beschrieben, die für den Connector erforderlich sind:
Autorisierungsobjekt: Das Autorisierungsobjekt
ZGOOGCDFMTwird als Teil der Rolle „Transportanfrage“ gesendet.Rollenerstellung: Erstelle eine Rolle mit dem Transaktionscode
PFCG.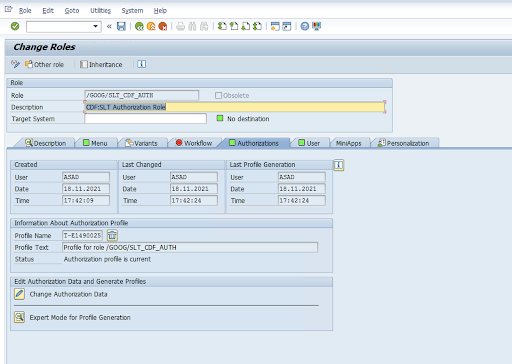
Bei standardmäßigen SAP-Autorisierungsobjekten verwaltet Ihre Organisation Berechtigungen mit einem eigenen Sicherheitsmechanismus.
Geben Sie für benutzerdefinierte Autorisierungsobjekte Werte in den Autorisierungsfeldern für Autorisierungsobjekte
ZGOOGCDFMTan.Für die detaillierte Zugriffssteuerung bietet
ZGOOGCDFMTeine autorisierungsgruppenbasierte Autorisierung. Nutzern mit vollständigem, teilweisem oder keinem Zugriff auf Autorisierungsgruppen wird der Zugriff basierend auf der Autorisierungsgruppe gewährt, die ihrer Rolle zugewiesen ist./GOOG/SLT_CDF_AUTH: Rolle mit Zugriff auf alle Autorisierungsgruppen. Wenn Sie den Zugriff auf eine bestimmte Autorisierungsgruppe beschränken möchten, müssen Sie die Autorisierungsgruppe FICDF in der Konfiguration beibehalten.
RFC-Ziel für die Quelle erstellen
Bevor Sie mit der Konfiguration beginnen, prüfen Sie, ob die RFC-Verbindung zwischen Quelle und Ziel hergestellt ist.
Rufen Sie den Transaktionscode
SM59auf.Klicken Sie auf Erstellen > Verbindungstyp 3 (ABAP-Verbindung).
Geben Sie im Fenster Technische Einstellungen die Details zur RFC-Zielanwendung ein.
Klicken Sie auf den Tab Anmeldung und Sicherheit, um RFC-Anmeldedaten (RFC-Nutzer und -Passwort) zu verwalten.
Klicken Sie auf Speichern.
Klicken Sie auf Verbindungstest. Nach einem erfolgreichen Test können Sie fortfahren.
Prüfen Sie, ob der RFC-Autorisierungstest erfolgreich war.
Klicken Sie auf Verwaltung > Test > Autorisierungstest.
Plug-in konfigurieren
Um das Plug-in zu konfigurieren, müssen Sie es über den Hub bereitstellen, einen Replikationsjob erstellen und die Quelle und das Ziel mit den folgenden Schritten konfigurieren.
Plug-in in Cloud Data Fusion bereitstellen
Der Cloud Data Fusion-Nutzer führt die folgenden Schritte aus.
Bevor Sie den Cloud Data Fusion-Replikationsjob ausführen können, müssen Sie das SAP SLT-Replikations-Plug-in bereitstellen:
Rufen Sie Ihre Instanz auf:
Rufen Sie in der Google Cloud Console die Seite Cloud Data Fusion-Instanzen auf.
So aktivieren Sie die Replikation in einer neuen oder vorhandenen Instanz:
- Klicken Sie für eine neue Instanz auf Instanz erstellen, geben Sie einen Instanznamen ein, klicken Sie auf Beschleuniger hinzufügen, setzen Sie ein Häkchen bei Replikation und klicken Sie auf Speichern.
- Informationen zu einer vorhandenen Instanz finden Sie unter Replikation für eine vorhandene Instanz aktivieren.
Klicken Sie auf Instanz aufrufen, um die Instanz in der Cloud Data Fusion-Weboberfläche zu öffnen.
Klicken Sie auf Hub.
Rufen Sie den Tab SAP auf, klicken Sie auf SAP SLT und dann auf SAP SLT-Replikations-Plug-in oder SAP SLT-Replikations-Plug-in ohne RFC.
Klicken Sie auf Bereitstellen.
Replikationsjob erstellen
Das SAP SLT-Replikations-Plug-in liest den Inhalt von SAP-Tabellen mithilfe eines Cloud Storage API-Staging-Buckets.
So erstellen Sie einen Replikationsjob für die Datenübertragung:
Klicken Sie in der geöffneten Cloud Data Fusion-Instanz auf Startseite > Replikation > Replikationsjob erstellen. Wenn die Option Replikation nicht angezeigt wird, aktivieren Sie die Replikation für die Instanz.
Geben Sie einen eindeutigen Namen und eine Beschreibung für den Replikationsjob ein.
Klicken Sie auf Weiter.
Quelle konfigurieren
Konfigurieren Sie die Quelle, indem Sie Werte in die folgenden Felder eingeben:
- Projekt-ID: Die ID Ihres Google Cloud Projekts (dieses Feld ist vorausgefüllt)
GCS-Pfad für die Datenreplikation: Der Cloud Storage-Pfad, der Daten für die Replikation enthält. Es muss derselbe Pfad sein, der in den SAP SLT-Jobs konfiguriert ist. Intern wird der angegebene Pfad mit
Mass Transfer IDundSource Table Namezusammengefügt:Format:
gs://<base-path>/<mass-transfer-id>/<source-table-name>Beispiel:
gs://slt_bucket/012/MARAGUID: Die SLT-GUID – eine eindeutige Kennung, die der SAP-SLT-Massenübertragungs-ID zugewiesen ist.
Massenübertragungs-ID: Die SLT-Massenübertragungs-ID ist eine eindeutige Kennung, die der Konfiguration in SAP SLT zugewiesen ist.
GCS-Pfad zur SAP JCo-Bibliothek: Der Speicherpfad, der die vom Nutzer hochgeladenen SAP JCo-Bibliotheksdateien enthält. SAP JCo-Bibliotheken können aus dem SAP Support Portal heruntergeladen werden. (In Plug-in-Version 0.10.0 entfernt)
SLT-Serverhost: Hostname oder IP-Adresse des SLT-Servers. (In Plugin-Version 0.10.0 entfernt)
SAP-Systemnummer: Vom Systemadministrator angegebene Installationssystemnummer (z. B.
00). (In Plug-in-Version 0.10.0 entfernt.)SAP-Client: Der zu verwendende SAP-Client (z. B.
100). (In Plug-in-Version 0.10.0 entfernt.)SAP-Sprache: SAP-Anmeldesprache (z. B.
EN). (In Plug-in-Version 0.10.0 entfernt.)Nutzername für SAP-Anmeldung: SAP-Nutzername. (In Plug-in-Version 0.10.0 entfernt)
- Empfohlen: Wenn sich der SAP-Anmeldename regelmäßig ändert, verwenden Sie ein Makro.
SAP-Anmeldepasswort (M): SAP-Nutzerpasswort für die Nutzerauthentifizierung.
- Empfohlen: Verwenden Sie sichere Makros für sensible Werte wie Passwörter. (In Plug-in-Version 0.10.0 entfernt)
SLT-Replikation anhalten, wenn CDF-Job beendet wird: Es wird versucht, den SLT-Replikationsjob (für die entsprechenden Tabellen) anzuhalten, wenn der Cloud Data Fusion-Replikationsjob beendet wird. Kann fehlschlagen, wenn der Job in Cloud Data Fusion unerwartet angehalten wird.
Vorhandene Daten replizieren: Gibt an, ob vorhandene Daten aus den Quelltabellen repliziert werden sollen. Standardmäßig replizieren die Jobs die vorhandenen Daten aus den Quelltabellen. Wenn
falsefestgelegt ist, werden alle vorhandenen Daten in den Quelltabellen ignoriert und nur die Änderungen nach dem Start des Jobs werden repliziert.Dienstkontoschlüssel: Der Schlüssel, der bei der Interaktion mit Cloud Storage verwendet wird. Das Dienstkonto muss die Schreibberechtigung für Cloud Storage haben. Wenn die Anwendung auf einer Google Cloud VM ausgeführt wird, sollte dieser Parameter auf
auto-detectfestgelegt sein, um das mit der VM verknüpfte Dienstkonto zu verwenden.
Klicken Sie auf Weiter.
Ziel konfigurieren
Damit das Plug-in Daten in BigQuery schreiben kann, benötigt es Schreibzugriff sowohl auf BigQuery als auch auf einen Staging-Bucket. Änderungsereignisse werden zuerst in Batches vom SLT in Cloud Storage geschrieben. Sie werden dann in Staging-Tabellen in BigQuery geladen. Änderungen aus der Staging-Tabelle werden mithilfe einer BigQuery-Merge-Abfrage in die endgültige Zieltabelle zusammengeführt.
Die endgültige Zieltabelle enthält alle ursprünglichen Spalten aus der Quelltabelle sowie eine zusätzliche Spalte vom Typ _sequence_num. Die Sequenznummer sorgt dafür, dass Daten bei Fehlern des Replikators nicht dupliziert oder übersehen werden.
Konfigurieren Sie die Quelle, indem Sie Werte in die folgenden Felder eingeben:
- Projekt-ID: Projekt des BigQuery-Datasets. Wenn die Ausführung in einem Dataproc-Cluster erfolgt, kann dieses Feld leer bleiben. In diesem Fall wird das Projekt des Clusters verwendet.
- Anmeldedaten: Siehe Anmeldedaten.
- Dienstkontoschlüssel: Der Inhalt des Dienstkontoschlüssels, der bei der Interaktion mit Cloud Storage und BigQuery verwendet werden soll. Wenn der Dienst in einem Dataproc-Cluster ausgeführt wird, sollte dieses Feld leer bleiben. In diesem Fall wird das Dienstkonto des Clusters verwendet.
- Dataset Name (Dataset-Name): Name des Datasets, das in BigQuery erstellt werden soll. Er ist optional. Standardmäßig entspricht der Name des Datasets dem Namen der Quelldatenbank. Ein gültiger Name darf nur Buchstaben, Ziffern und Unterstriche enthalten und darf maximal 1.024 Zeichen lang sein. Alle ungültigen Zeichen werden im endgültigen Dataset-Namen durch einen Unterstrich ersetzt und alle Zeichen, die das Längenlimit überschreiten, werden abgeschnitten.
- Name des Verschlüsselungsschlüssels: Der vom Kunden verwaltete Verschlüsselungsschlüssel (CMEK), mit dem die vom Ziel erstellten Ressourcen gesichert werden. Der Name des Verschlüsselungsschlüssels muss das Format
projects/<project-id>/locations/<key-location>/keyRings/<key-ring-name>/cryptoKeys/<key-name>haben. - Speicherort: Der Speicherort, an dem das BigQuery-Dataset und der Cloud Storage-Staging-Bucket erstellt werden. Beispiel:
us-east1für regionale Buckets,usfür multiregionale Buckets (siehe Standorte). Dieser Wert wird ignoriert, wenn ein vorhandener Bucket angegeben wird, da der Staging-Bucket und das BigQuery-Dataset am selben Speicherort wie dieser Bucket erstellt werden. Staging-Bucket: Der Bucket, in den Änderungsereignisse geschrieben werden, bevor sie in Staging-Tabellen geladen werden. Änderungen werden in ein Verzeichnis geschrieben, das den Namen und den Namespace des Replikators enthält. Sie können denselben Bucket für mehrere Replikatoren innerhalb derselben Instanz verwenden. Wenn er von mehreren Replikatoren für mehrere Instanzen freigegeben wird, müssen Namespace und Name eindeutig sein. Andernfalls ist das Verhalten nicht definiert. Der Bucket muss sich am selben Speicherort wie das BigQuery-Dataset befinden. Wenn Sie keinen angeben, wird für jeden Job ein neuer Bucket mit dem Namen
df-rbq-<namespace-name>-<job-name>-<deployment-timestamp>erstellt.Ladeintervall (Sekunden): Anzahl der Sekunden, die gewartet werden soll, bevor ein Datensatz in BigQuery geladen wird.
Präfix der Staging-Tabelle: Änderungen werden zuerst in eine Staging-Tabelle geschrieben, bevor sie mit der endgültigen Tabelle zusammengeführt werden. Die Namen der Staging-Tabellen werden generiert, indem dieses Präfix dem Namen der Zieltabelle vorangestellt wird.
Manuelles Löschen erforderlich: Gibt an, ob beim Auftreten eines Ereignisses vom Typ „Tabelle löschen“ oder „Datenbank löschen“ eine manuelle administrative Aktion zum Löschen von Tabellen und Datensätzen erforderlich ist. Wenn dieser Wert auf „true“ gesetzt ist, löscht der Replikator keine Tabelle oder kein Dataset. Stattdessen schlägt der Vorgang fehl und wird wiederholt, bis die Tabelle oder der Datensatz nicht mehr vorhanden ist. Wenn das Dataset oder die Tabelle nicht vorhanden ist, ist keine manuelle Aktion erforderlich. Das Ereignis wird wie gewohnt übersprungen.
Weichlöschungen aktivieren: Wenn diese Option aktiviert ist und das Ziel ein Löschereignis empfängt, wird die Spalte
_is_deletedfür den Datensatz auftruegesetzt. Andernfalls wird der Datensatz aus der BigQuery-Tabelle gelöscht. Diese Konfiguration ist für eine Quelle, die Ereignisse in ungeordneter Reihenfolge generiert, nicht sinnvoll. Datensätze werden immer aus der BigQuery-Tabelle weicher gelöscht.
Klicken Sie auf Weiter.
Anmeldedaten
Wenn das Plug-in in einem Dataproc-Cluster ausgeführt wird, sollte der Dienstkontoschlüssel auf „Automatische Erkennung“ gesetzt werden. Anmeldedaten werden automatisch aus der Clusterumgebung gelesen.
Wenn das Plug-in nicht auf einem Dataproc-Cluster ausgeführt wird, muss der Pfad zu einem Dienstkontoschlüssel angegeben werden. Den Dienstkontoschlüssel finden Sie in der Google Cloud Console auf der IAM-Seite. Der Kontoschlüssel muss Zugriff auf BigQuery haben. Die Schlüsseldatei des Dienstkontos muss auf jedem Knoten in Ihrem Cluster verfügbar und für alle Nutzer lesbar sein, die den Job ausführen.
Beschränkungen
- Tabellen müssen einen Primärschlüssel haben, um repliziert zu werden.
- Das Umbenennen von Tabellen wird nicht unterstützt.
- Änderungen an Tabellen werden teilweise unterstützt.
- Eine vorhandene Spalte ohne Nullwerte kann in eine Spalte mit Nullwerten umgewandelt werden.
- Einer vorhandenen Tabelle können neue Spalten mit dem Attribut „NULL zulässig“ hinzugefügt werden.
- Alle anderen Arten von Änderungen am Tabellenschema schlagen fehl.
- Änderungen am Primärschlüssel führen nicht zu Fehlern, aber vorhandene Daten werden nicht überschrieben, um die Eindeutigkeit des neuen Primärschlüssels zu gewährleisten.
Tabellen und Transformationen auswählen
Im Schritt Tabellen und Transformationen auswählen wird eine Liste der Tabellen angezeigt, die für die Replikation im SLT-System ausgewählt wurden.
- Wählen Sie die Tabellen aus, die Sie replizieren möchten.
- Optional: Wählen Sie zusätzliche Schemavorgänge aus, z. B. Inserts, Updates oder Deletes.
- Wenn Sie das Schema aufrufen möchten, klicken Sie bei einer Tabelle auf Spalten zum Replizieren.
Optional: So benennen Sie Spalten im Schema um:
- Klicken Sie im Schema auf Transformieren > Umbenennen.
- Geben Sie im Feld Umbenennen einen neuen Namen ein und klicken Sie auf Übernehmen.
- Klicken Sie auf Aktualisieren und dann auf Speichern, um den neuen Namen zu speichern.
Klicken Sie auf Weiter.
Optional: Erweiterte Properties konfigurieren
Wenn Sie wissen, wie viele Daten Sie in einer Stunde replizieren, können Sie die entsprechende Option auswählen.
Bewertung prüfen
Im Schritt Bewertung prüfen werden Schemaprobleme, fehlende Funktionen oder Verbindungsprobleme während der Replikation geprüft.
Klicken Sie auf der Seite Bewertung überprüfen auf Zuordnungen ansehen.
Wenn Probleme auftreten, müssen diese behoben werden, um fortfahren zu können.
Optional: Wenn Sie beim Auswählen der Tabellen und Transformationen Spalten umbenannt haben, prüfen Sie in diesem Schritt, ob die neuen Namen korrekt sind.
Klicken Sie auf Weiter.
Zusammenfassung ansehen und Replikationsjob bereitstellen
Prüfen Sie auf der Seite Replikationsjobdetails überprüfen die Einstellungen und klicken Sie auf Replikationsjob bereitstellen.
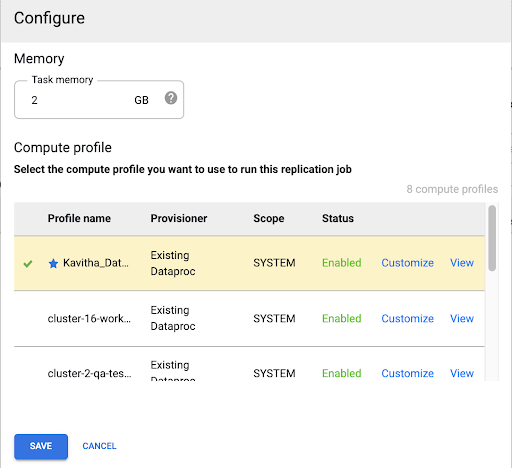
Compute Engine-Profil auswählen
Nachdem Sie den Replikationsjob bereitgestellt haben, klicken Sie auf einer beliebigen Seite in der Cloud Data Fusion-Weboberfläche auf Konfigurieren.
Wählen Sie das Compute Engine-Profil aus, das Sie für die Ausführung dieses Replikationsjobs verwenden möchten.
Klicken Sie auf Speichern.
Replikationsjob starten
- Klicken Sie auf Starten, um den Replikationsjob auszuführen.
Optional: Leistung optimieren
Standardmäßig ist das Plug-in für eine optimale Leistung konfiguriert. Weitere Optimierungen finden Sie unter Laufzeitargumente.
Die Leistung der Kommunikation zwischen SLT und Cloud Data Fusion hängt von den folgenden Faktoren ab:
- SLT im Quellsystem im Vergleich zu einem zentralen SLT-System (bevorzugte Option)
- Hintergrundjobverarbeitung im SLT-System
- Dialogarbeitsprozesse im SAP-Quellsystem
- Die Anzahl der Hintergrundjobprozesse, die jeder ID der Massenübertragung auf dem Tab LTRC-Verwaltung zugewiesen sind.
- LTRS-Einstellungen
- Hardware (CPU und Arbeitsspeicher) des SLT-Systems
- Die verwendete Datenbank (z. B. HANA, Sybase oder DB2)
- Internetbandbreite (Konnektivität zwischen dem SAP-System undGoogle Cloud über das Internet)
- Vorhandene Auslastung (Last) des Systems
- Die Anzahl der Spalten in der Tabelle. Bei mehr Spalten wird die Replikation langsamer und die Latenz kann steigen.
Für anfängliche Ladevorgänge werden die folgenden Lesetypen in den LTRS-Einstellungen empfohlen:
| SLT-System | Quellsystem | Tabellentyp | Empfohlener Lesetyp [initial load] |
|---|---|---|---|
| SLT 3.0 standalone [DMIS 2018_1_752 SP 2] |
S/4HANA 1909 | Transparent (klein/mittel) Transparent (groß) Clustertabelle |
1 Bereichsberechnung 1 Bereichsberechnung 4 Absenderwarteschlange |
| SLT embedded [S4CORE 104 HANA 1909] |
– | Transparent (klein/mittel) Transparent (groß) Clustertabelle |
1 Bereichsberechnung 1 Bereichsberechnung 4 Absenderwarteschlange |
| SLT 2.0 – eigenständige Version [DMIS 2011_1_731 SP 17] |
ECC NW 7.02 | Transparent (klein/mittel) Transparent (groß) Clustertabelle |
Warteschlange mit 5 Absendern 5-Absender-Warteschlange 4-Absender-Warteschlange |
| Eingebettetes SLT [DMIS 2011_1_700 SP 17] |
– | Transparent (klein/mittel) Transparent (groß) Clustertabelle |
Warteschlange mit 5 Absendern 5-Absender-Warteschlange 4-Absender-Warteschlange |
- Verwenden Sie für die Replikation „Kein Bereich“, um die Leistung zu verbessern:
- Bereiche sollten nur verwendet werden, wenn Backlogs in einer Protokolltabelle mit hoher Latenz generiert werden.
- Eine Bereichsberechnung verwenden: Der Lesetyp für das initiale Laden wird bei SLT 2.0- und Nicht-HANA-Systemen nicht empfohlen.
- Verwendung einer Bereichsberechnung: Der Lesetyp für das erste Laden kann zu doppelten Datensätzen in BigQuery führen.
- Die Leistung ist immer besser, wenn ein eigenständiges SLT-System verwendet wird.
- Ein eigenständiges SLT-System wird immer empfohlen, wenn die Ressourcennutzung des Quellsystems bereits hoch ist.
Laufzeitargumente
snapshot.thread.count: Übergibt die Anzahl der Threads, die gestartet werden sollen, um dieSNAPSHOT/INITIAL-Daten parallel zu laden. Standardmäßig wird die Anzahl der vCPUs verwendet, die im Dataproc-Cluster verfügbar sind, in dem der Replikationsjob ausgeführt wird.Empfohlen: Legen Sie diesen Parameter nur fest, wenn Sie die Anzahl der parallelen Threads genau steuern möchten (z. B. um die Auslastung des Clusters zu verringern).
poll.file.count: Übergibt die Anzahl der Dateien, die vom Cloud Storage-Pfad abgefragt werden sollen, der im Webinterface im Feld GCS-Pfad für die Datenreplikierung angegeben ist. Standardmäßig beträgt der Wert500pro Abfrage. Er kann jedoch je nach Clusterkonfiguration erhöht oder verringert werden.Empfohlen: Legen Sie diesen Parameter nur fest, wenn Sie strenge Anforderungen an die Replikationsverzögerung haben. Niedrigere Werte können die Verzögerung verringern. Sie können damit den Durchsatz verbessern. Wenn das Gerät nicht reagiert, verwenden Sie Werte, die über dem Standardwert liegen.
bad.files.base.path: Gibt den Cloud Storage-Basispfad an, in den alle fehlerhaften oder fehlerhaften Datendateien kopiert werden, die bei der Replikation gefunden wurden. Dies ist nützlich, wenn strenge Anforderungen an die Datenprüfung gelten und ein bestimmter Speicherort verwendet werden muss, um fehlgeschlagene Übertragungen zu erfassen.Standardmäßig werden alle fehlerhaften Dateien aus dem Cloud Storage-Pfad kopiert, der in der Weboberfläche im Feld Cloud Storage-Pfad für die Datenreplikation angegeben ist.
Muster für den endgültigen Pfad fehlerhafter Datendateien:
gs://BASE_FILE_PATH/MASS_TRANSFER_ID/SOURCE_TABLE_NAME/bad_files/REPLICATION_JOB_NAME/REPLICATION_JOB_ID/BAD_FILE_NAME
Beispiel:
gs://slt_to_cdf_bucket/001/MARA/bad_files/MaraRepl/05f97349-7398-11ec-9443-8 ac0640fc83c/20220205_1901205168830_DATA_INIT.xml
Die Kriterien für eine fehlerhafte Datei sind eine beschädigte oder ungültige XML-Datei, fehlende Primärschlüsselwerte oder ein Problem mit nicht übereinstimmenden Felddatentypen.
Supportdetails
Unterstützte SAP-Produkte und ‑Versionen
- SAP_BASIS 702-Release, SP-Level 0016 und höher.
- SAP_ABA 702-Release, SP-Level 0016 und höher.
- DMIS 2011_1_700-Release, SP-Level 0017 und höher
Unterstützte SLT-Versionen
SLT-Versionen 2 und 3 werden unterstützt.
Unterstützte SAP-Bereitstellungsmodelle
SLT als eigenständiges System oder im Quellsystem eingebettet.
SAP-Hinweise, die vor der Verwendung des SLT implementiert werden müssen
Wenn Ihr Supportpaket keine /UI2/CL_JSON-Klassenkorrekturen für PL 12 oder höher enthält, implementieren Sie den neuesten SAP-Hinweis für /UI2/CL_JSON-Klassenkorrekturen, z. B. den SAP-Hinweis 2798102 für PL 12.
Empfohlen: Implementieren Sie die im Bericht CNV_NOTE_ANALYZER_SLT empfohlenen SAP-Hinweise basierend auf der Bedingung „Zentrales System“ oder „Quellsystem“. Weitere Informationen finden Sie im SAP-Hinweis 3016862 (SAP-Anmeldung erforderlich).
Wenn SAP bereits eingerichtet ist, muss kein zusätzlicher Hinweis implementiert werden. Informationen zu bestimmten Fehlern oder Problemen finden Sie in der zentralen SAP-Notiz für Ihre SLT-Version.
Limits für das Datenvolumen oder die Datensatzbreite
Es gibt kein definiertes Limit für das extrahierte Datenvolumen und die Datensatzbreite.
Erwarteter Durchsatz für das SAP SLT Replication-Plug-in
Für eine Umgebung, die gemäß den Richtlinien im Abschnitt Leistung optimieren konfiguriert ist, kann das Plug-in ca. 13 GB pro Stunde für das Initial Load und 3 GB pro Stunde für die Replikation (CDC) extrahieren. Die tatsächliche Leistung kann je nach Cloud Data Fusion- und SAP-Systemlast oder Netzwerkverkehr variieren.
Unterstützung für die Extraktion von SAP-Deltas (geänderte Daten)
Die Deltaextraktion von SAP wird unterstützt.
Erforderlich: Tenant-Peering für Cloud Data Fusion-Instanzen
Das Tenant-Peering ist erforderlich, wenn die Cloud Data Fusion-Instanz mit einer internen IP-Adresse erstellt wird. Weitere Informationen zum Tenant-Peering finden Sie unter Private Instanz erstellen.
Fehlerbehebung
Replikationsjob wird immer wieder neu gestartet
Wenn der Replikationsjob immer wieder automatisch neu gestartet wird, erhöhen Sie den Clusterspeicher des Replikationsjobs und führen Sie den Replikationsjob noch einmal aus.
Duplikate in der BigQuery-Senke
Wenn Sie die Anzahl der parallelen Jobs in den erweiterten Einstellungen des SAP SLT-Replikations-Plug-ins festlegen, tritt bei großen Tabellen ein Fehler auf, der zu doppelten Spalten in der BigQuery-Senke führt.
Entfernen Sie zum Laden von Daten die parallelen Jobs, um das Problem zu vermeiden.
Fehlerszenarien
In der folgenden Tabelle sind einige häufig auftretende Fehlermeldungen aufgeführt (Text in Anführungszeichen wird zur Laufzeit durch tatsächliche Werte ersetzt):
| Nachrichten-ID | Nachricht | Empfohlene Maßnahmen |
|---|---|---|
CDF_SAP_SLT_01402 |
Service account type is not defined for
SERVICE_ACCT_NAME_FROM_UI. |
Prüfen Sie, ob der angegebene Cloud Storage-Pfad korrekt ist. |
CDF_SAP_SLT_01403 |
Service account key provided is not valid due to error:
ROOT_CAUSE. Please provide a valid service account key for
service account type : SERVICE_ACCT_NAME_FROM_UI. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
CDF_SAP_SLT_01404 |
Mass Transfer ID could not be found. Please ensure that it exists
in given GCS Bucket. |
Prüfen Sie, ob die angegebene ID für die Massenübertragung im richtigen Format ist. |
CDF_SAP_SLT_01502 |
The specified data replication GCS path 'slt_to_cdf_bucket_1' or
Mass Transfer ID '05C' could not be found. Please ensure that it exists in
GCS. |
Prüfen Sie, ob der angegebene Cloud Storage-Pfad korrekt ist. |
CDF_SAP_SLT_01400 |
Metadata file not found. The META_INIT.json file is not present or
file is present with invalid format. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
CDF_SAP_SLT_03408 |
Failed to start the event reader. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
CDF_SAP_SLT_03409 |
Error while processing TABLE_NAME file for source table
gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/TABLE_NAME
/FILE_NAME. Root cause: ROOT_CAUSE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
CDF_SAP_SLT_03410 |
Failed to replicate data for source table TABLE_NAME
from file: gs://CLOUD_STORAGE_BUCKET_NAME/MT_ID/
TABLE_NAME/FILE_NAME. Root cause:
ROOT_CAUSE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
CDF_SAP_SLT_03411 |
Failed data replication for source table TABLE_NAME.
Root cause: ROOT_CAUSE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
CDF_SAP_SLT_03412 |
Failed to create target table for source table
TABLE_NAME. Root cause: ROOT_CAUSE. |
Prüfen Sie die in der Nachricht angezeigte Ursache und ergreifen Sie entsprechende Maßnahmen. |
Datentypzuordnung
Die folgende Tabelle zeigt die Zuordnung zwischen Datentypen, die in SAP-Anwendungen verwendet werden, und Cloud Data Fusion.
| SAP-Datentyp | ABAP-Typ | Beschreibung (SAP) | Cloud Data Fusion-Datentyp |
|---|---|---|---|
| Numerisch | |||
| INT1 | b | 1-Byte-Ganzzahl | int |
| INT2 | s | 2-Byte-Ganzzahl | int |
| INT4 | i | 4-Byte-Ganzzahl | int |
| INT8 | 8 | 8-Byte-Ganzzahl | long |
| DEZ | p | Nummer des Pakets im BCD-Format (DEC) | decimal |
| DF16_DEC DF16_RAW |
a | Dezimales Gleitkomma 8 Byte IEEE 754r | decimal |
| DF34_DEC DF34_RAW |
e | Dezimales Gleitkomma 16 Byte IEEE 754r | decimal |
| FLTP | f | Binäre Gleitkommazahl | double |
| Zeichen | |||
| CHAR LCHR |
c | Zeichenstring | string |
| SSTRING GEOM_EWKB |
String | Zeichenstring | string |
| STRING GEOM_EWKB |
String | Zeichenstring CLOB | bytes |
| NUMC ACCP |
n | Numerischer Text | string |
| Byte | |||
| RAW LRAW |
x | Binärdaten | bytes |
| Rohstring | xstring | Bytestring BLOB | bytes |
| Datum/Uhrzeit | |||
| DATS | d | Datum | date |
| Tims | t | Zeit | time |
| TIMESTAMP | utcl | ( Utclong ) TimeStamp |
timestamp |
Nächste Schritte
- Weitere Informationen zu Cloud Data Fusion
- Weitere Informationen zu SAP auf Google Cloud