This page describes how to set up your data pipeline to read data from a Microsoft SQL Server table.
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, BigQuery, Cloud Storage, and Dataproc APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Create a Cloud Data Fusion instance.
- Your SQL Server database must accept connections from Cloud Data Fusion. For security reasons, use a private Cloud Data Fusion instance.
Open your Cloud Data Fusion instance
In the Google Cloud console, go to the Cloud Data Fusion Instances page.
In the Actions column for the instance, click View instance to open the instance in Cloud Data Fusion.
Store your SQL Server password as a secure key
Add your SQL Server password as a secure key in your Cloud Data Fusion instance.
From Cloud Data Fusion, click System Admin.
Click the Configuration tab.
Click Make HTTP Calls.

Select PUT.
In the path field, enter
namespaces/NAMESPACE_ID/securekeys/password.In the Body field, enter
{"data":"password"}. Replace password with your SQL Server password.Click Send.
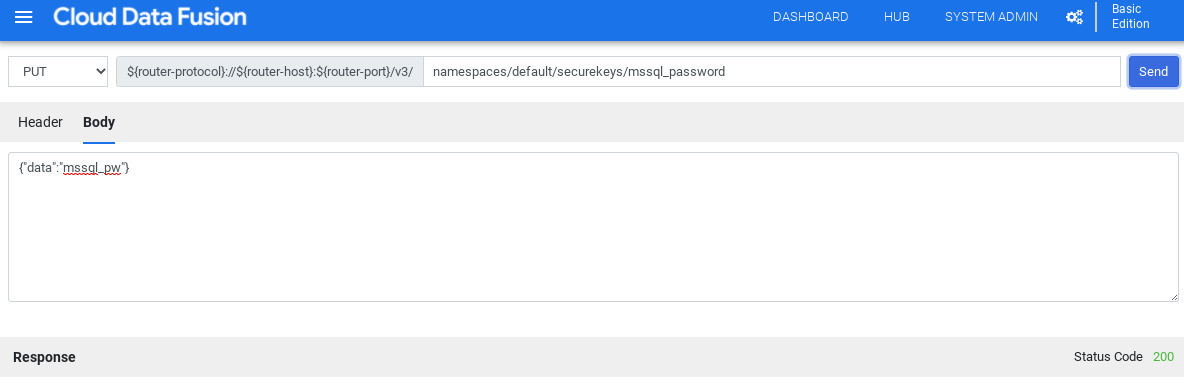
The Response must have status code 200 to continue.
Get the JDBC driver for SQL Server
You can get the driver from the Hub or in the Pipeline Studio in Cloud Data Fusion.
Hub
In the Cloud Data Fusion UI, click Hub.
In the search bar, enter
SQL Server JDBC Driverand select the driver.Click Download. Follow the download steps shown.
Click Deploy. Upload the JAR file from the previous step.
Click Finish.
Pipeline Studio
Go to Microsoft.com.
Choose your download and click Download.
In Cloud Data Fusion, click menu Menu and go to the Pipeline Studio page.
Click Add.
For the driver, click Upload.
Select the JAR file, located in the
jre7folder.Click Next.
To configure the driver, enter a Name and Class name.
Click Finish.
Deploy the SQL Server Plugin
In Cloud Data Fusion, click Hub.
In the search bar, enter
SQL Server Plugins.Click SQL server plugins.
Click Deploy.
Click Finish.
Click Create a pipeline.
Connect to SQL Server
You can connect to SQL Server from Cloud Data Fusion in Wrangler or the Pipeline Studio.
Wrangler
In Cloud Data Fusion, click menu Menu and go to the Wrangler page.
Click Add connection.
An Add connection window opens.
Click SQL Server to verify that the driver is installed.

Enter details in the required connection fields. In the Password field, select the secure key you stored previously. It ensures that your password is retrieved using Cloud KMS.
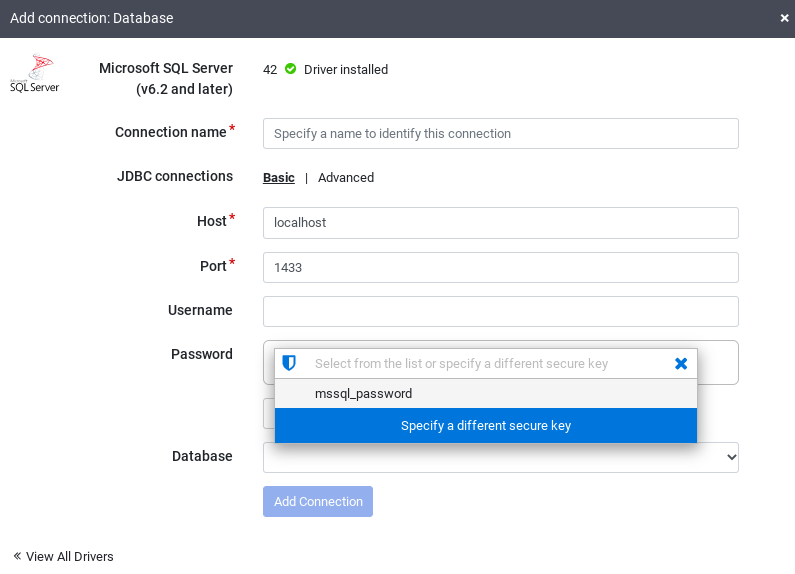
To check that a connection can be established with the database, click Test connection.
Click Add connection.
After your SQL Server database is connected and you've created a pipeline that reads from your SQL Server table, you can apply transformations and write your output to a sink.
Pipeline Studio
Open your Cloud Data Fusion instance and go to the Pipeline Studio page.
Expand the Source menu and click SQL Server.

On the SQL Server node, click Properties.
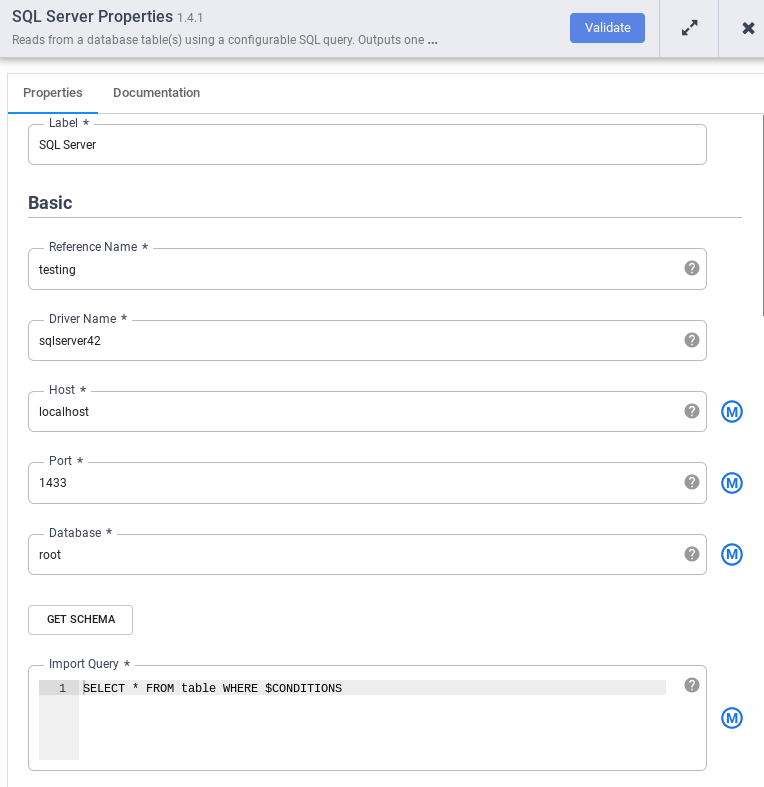
In the Reference name field, enter a name that identifies your SQL Server source.
In the Database field, enter the name of the database to connect to.
In the Import query field, enter the query to run. For example,
SELECT * FROM table WHERE $CONDITIONS.Click Validate.
Click close .
After your SQL Server database is connected and you've created a pipeline that reads from your SQL Server table, add any desired transformations and write your output to a sink.
What's next
- Learn how to read data from multiple SQL Server tables.
- Learn more about Cloud Data Fusion.
- Follow one of the tutorials.