
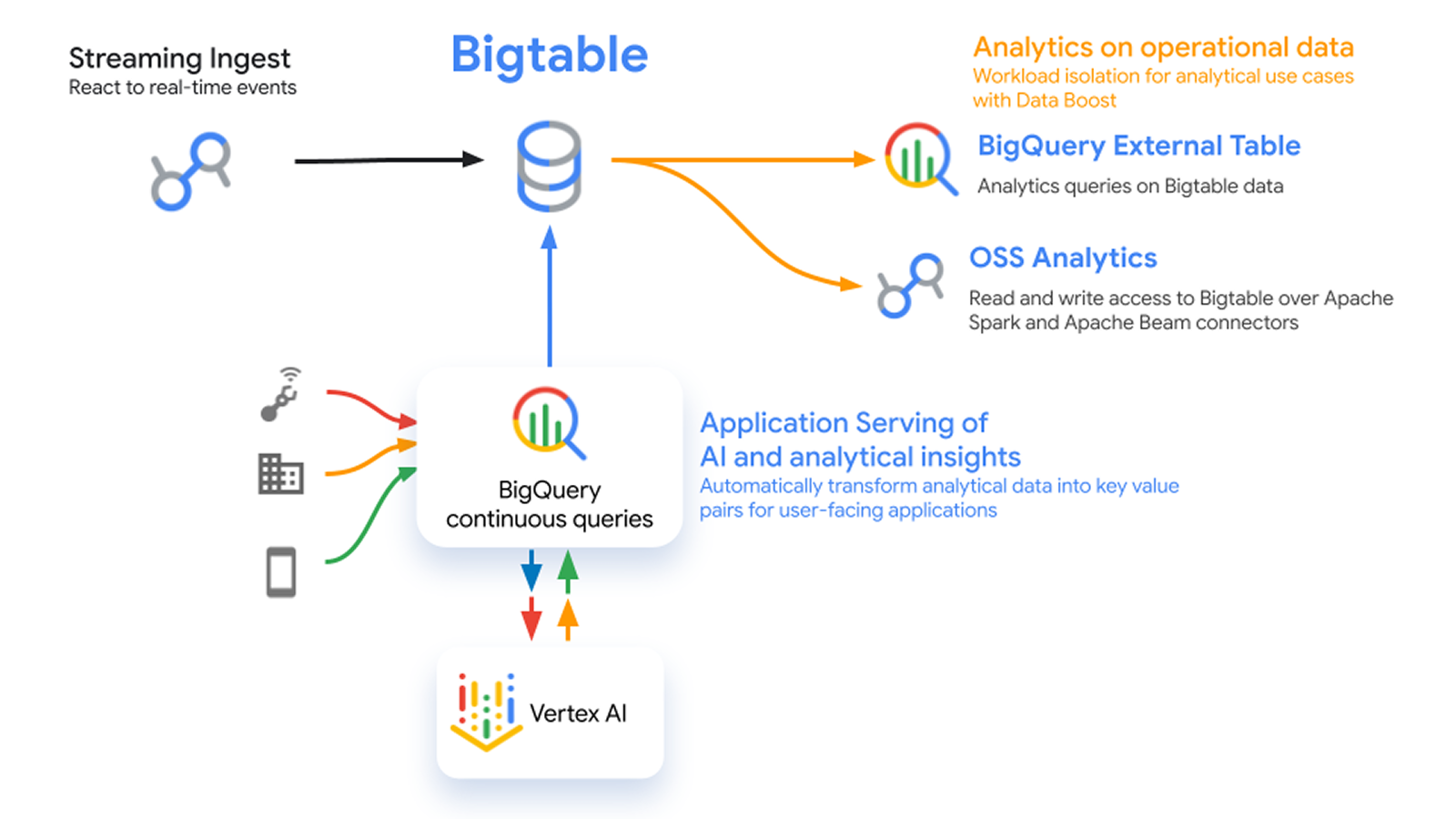
Bigtable
使用 NoSQL 类型中的先驱数据库服务扩缩对延迟敏感的应用
低延迟、兼容 Cassandra 和 HBase 的 NoSQL 数据库服务,适用于机器学习、运营分析和面向用户的应用。
新客户可获得 $300 赠金,用于抵扣 Bigtable 的相关费用。

功能
低延迟和高吞吐量
Bigtable 是一种键值对形式的宽列存储区,非常适合快速访问结构化、半结构化或非结构化数据。因此,对延迟敏感的工作负载(如个性化)非常适合 Bigtable。
分布式计数器、很高的单位成本读写吞吐量效率使得它也非常适合点击流和 IoT 用例,甚至也非常适合用于高性能计算 (HPC) 应用的批量分析,包括训练机器学习模型。
无限的写入和读取扩缩能力
Bigtable 将计算资源与数据存储空间分离,因而可以透明地调整处理资源。每个增加的节点都能够以同样的质量处理读取和写入操作,从而轻松实现横向扩缩。Bigtable 通过自动扩缩资源来适应服务器流量、处理分片、复制和查询处理,从而优化性能。
SQL 和持续的物化视图
Bigtable SQL 让用户能够使用熟悉的 SQL 语法构建全托管式实时应用,同时还具备专门的功能来保留 Bigtable 的灵活架构。您还可以使用 SQL 界面来构建增量物化视图,从而简化实时指标的创建。Bigtable 物化视图会在变化发生时立即处理,从而自动保持数据最新,同时不会影响您的写入和读取性能,并会根据流量自动扩缩。
灵活的数据模型
Bigtable 让您的数据模型自然发展。可存储标量、JSON、协议缓冲区、Avro、Arrow、嵌入、图片等各种对象,并根据需要动态地添加或移除新列。在单个数据库中基于原始的非结构化数据提供低延迟传送或高性能的批量分析。
从 NoSQL 数据库轻松迁移

从单个可用区快速扩容至 8 个区域
无论您的用户在哪里,由 Bigtable 支持的应用都可通过全球分布的多主配置实现低延迟读写。可用区级实例有助于节省费用,并且可以通过自动复制功能无缝扩容为多区域部署。运行多区域实例时,您的数据库可以防范单区域故障,并提供业界领先的 99.999% 可用性。
与工作负载隔离的高性能数据处理
借助 Bigtable Data Boost,用户可以更快地运行分析查询、批处理 ETL 流程、训练机器学习模型或导出数据,而不会影响事务型工作负载。Data Boost 不需要进行容量规划或管理。它支持直接查询存储在 Google 分布式存储系统 Colossus 中的数据(使用按需容量),使用户能够轻松处理混合工作负载并放心共享数据。
丰富的应用和工具支持
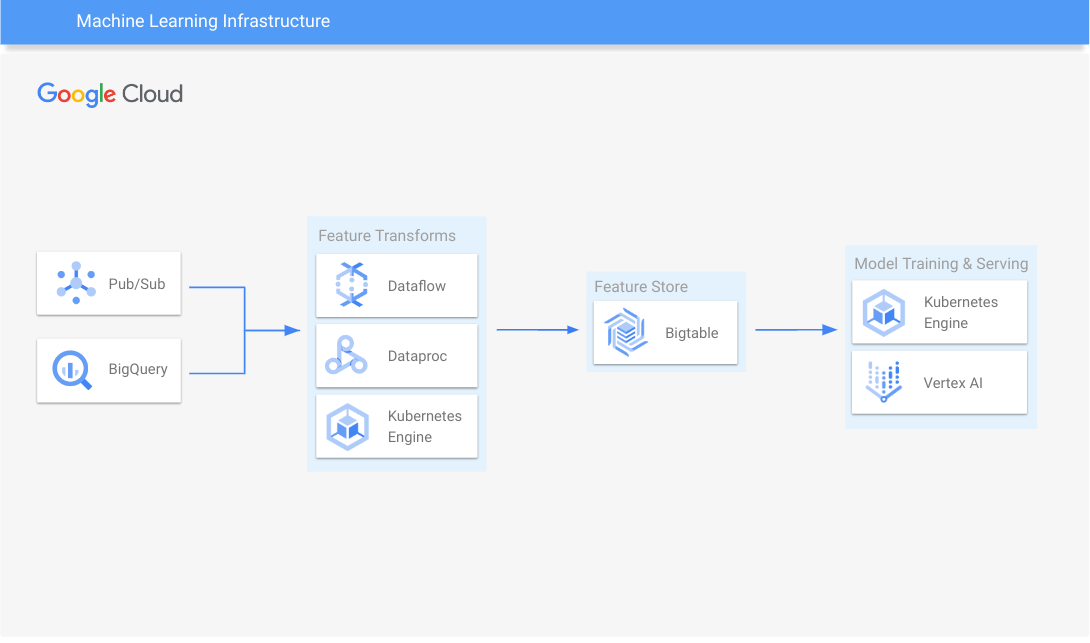
使用 Apache HBase API 可轻松连接到开源生态系统。通过与 Apache Spark、Hadoop、GKE、Dataflow、Dataproc、Vertex AI Vector Search 和 BigQuery 无缝集成,可更快地构建数据驱动型应用。利用 Java、Go、Python、C#、Node.js、PHP、Ruby、C++、HBase 的 SQL 和客户端库以及与 LangChain 的集成,满足开发团队的需求。
无隐性费用
没有 IOPS 费用,没有创建或恢复备份的费用,当工作负载增加时,也没有比例失调的读/写价格会影响预算。
实时变更数据捕获和事件
使用 Bigtable 变更数据流从 Bigtable 数据库中捕获变更数据并将其与其他系统集成,以用于分析、事件触发和合规性目的。
企业级安全和控制
支持 Cloud External Key Manager 的客户管理的加密密钥 (CMEK)、用于访问和控制的 IAM 集成、VPC-SC 支持、Access Transparency、Access Approval 以及全面的审核日志记录可帮助确保您的数据得到保护并遵守相关法规。精细的访问权限控制让您可以在表级、列级或行级授予访问权限。

灾难恢复
经济高效地对数据库进行即时的增量备份,并根据需要进行恢复。将备份存储在不同区域以提高弹性;针对测试和生产场景,可在实例或项目之间轻松恢复备份。
Vertex AI Vector Search 集成
使用 Bigtable to Vertex AI Vector Search 模板和 Vertex AI 将 Bigtable 数据库中的数据编入索引,以便使用 Vertex AI Vector Search 对向量嵌入执行相似度搜索。
LangChain 集成
利用内置的 kNN 最近邻向量搜索(预览版)及 LangChain 集成,轻松构建更准确、更透明且更可靠的生成式 AI 应用。如需了解详情,请访问 GitHub 代码库。

常见用途
实时分析
提高数据的新鲜度并减少查询延迟时间
学习资源
提高数据的新鲜度并减少查询延迟时间
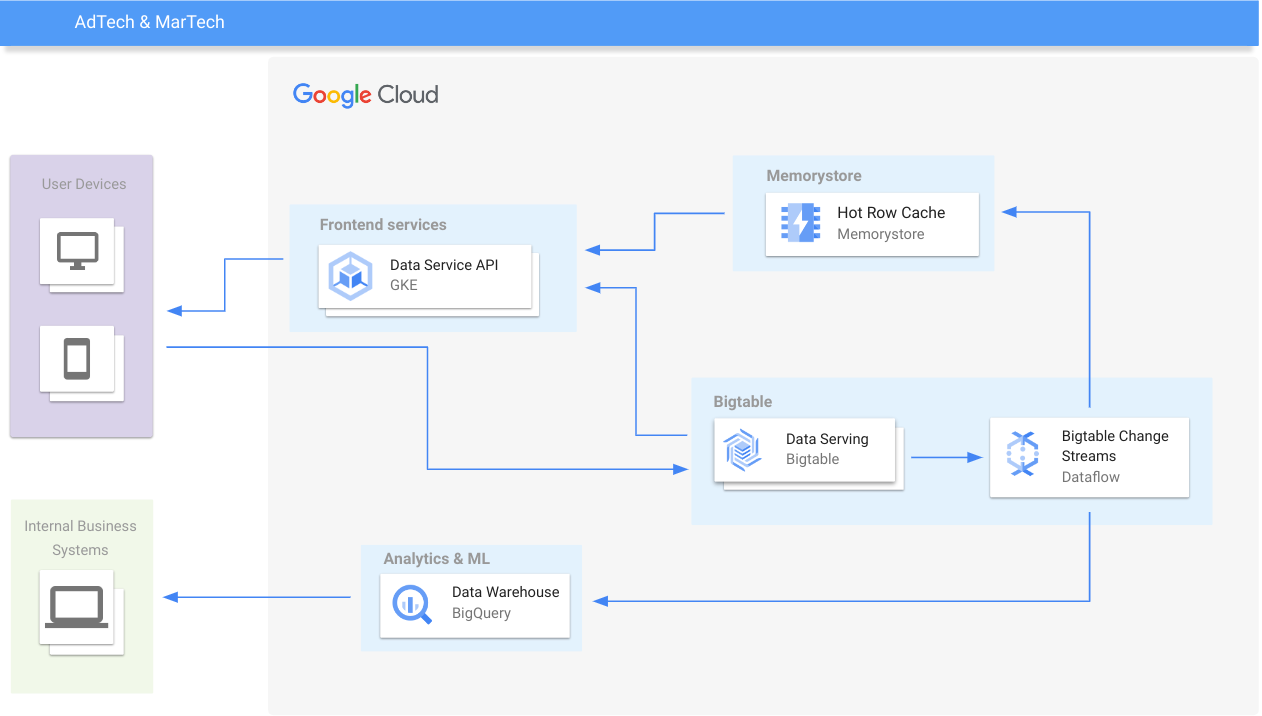
广告技术和零售
实时提供个性化体验
学习资源
实时提供个性化体验
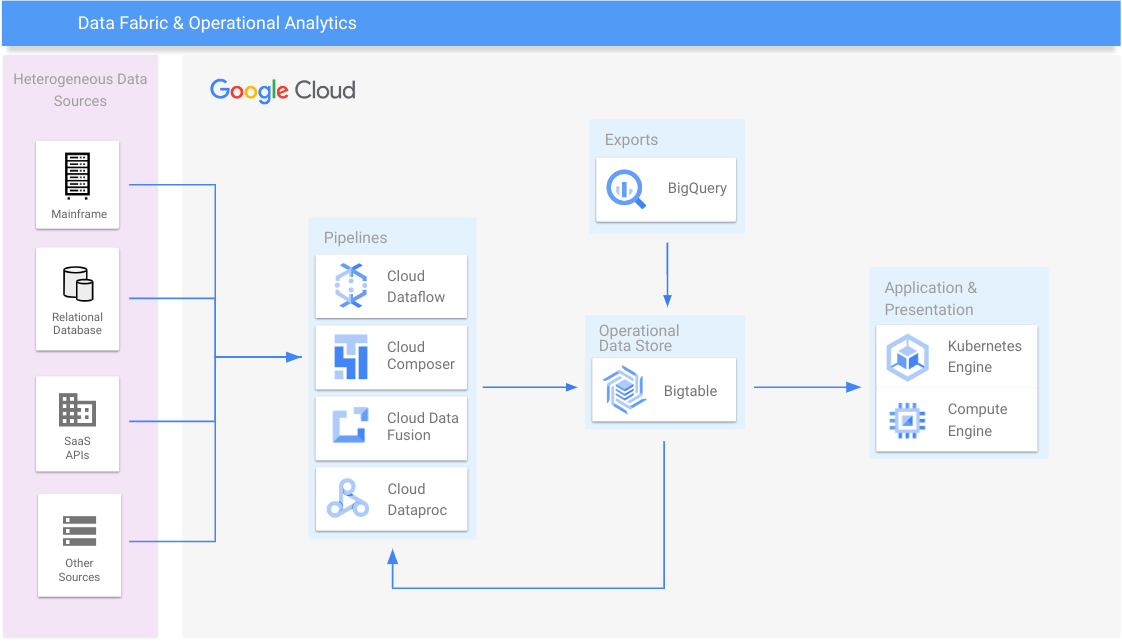
数据结构脉络和运营分析
整合数据孤岛,对旧式系统进行扩容
学习资源
整合数据孤岛,对旧式系统进行扩容
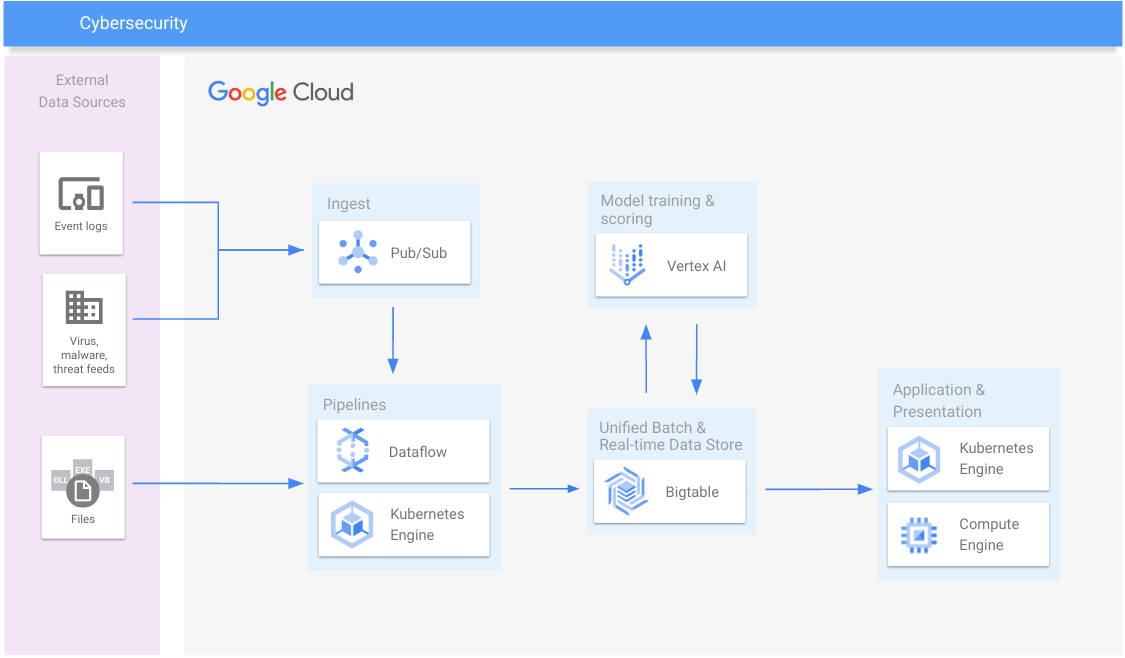
信息安全
检测恶意软件和支付诈骗,防范垃圾邮件和欺骗手段
学习资源
检测恶意软件和支付诈骗,防范垃圾邮件和欺骗手段
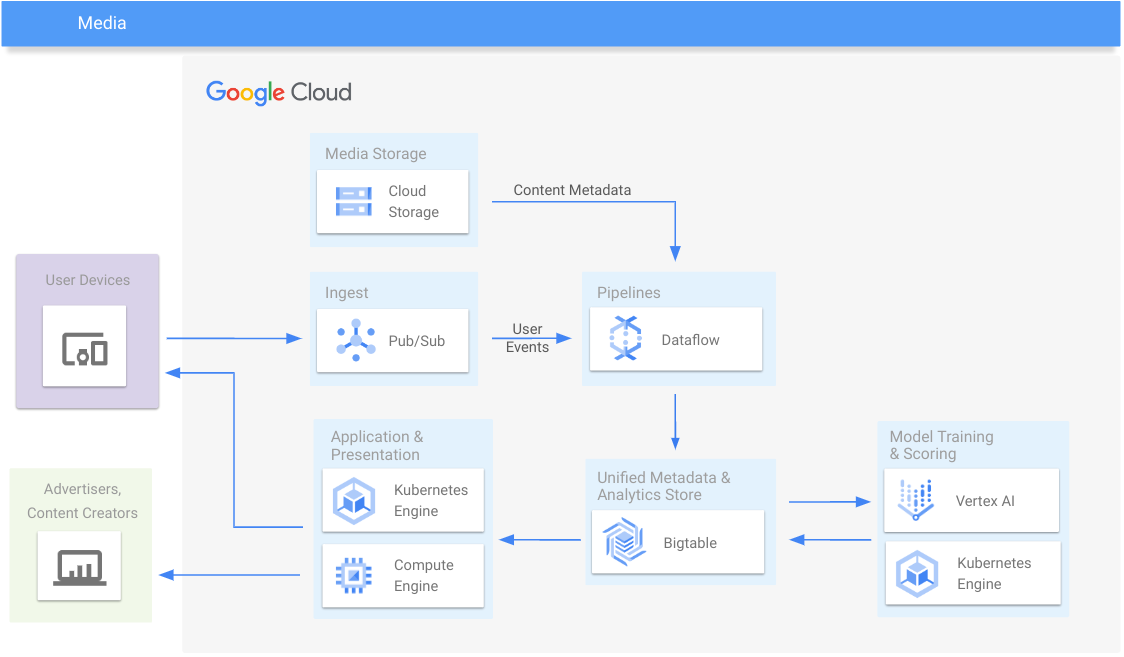
媒体
提供媒体内容和互动分析
学习资源
提供媒体内容和互动分析
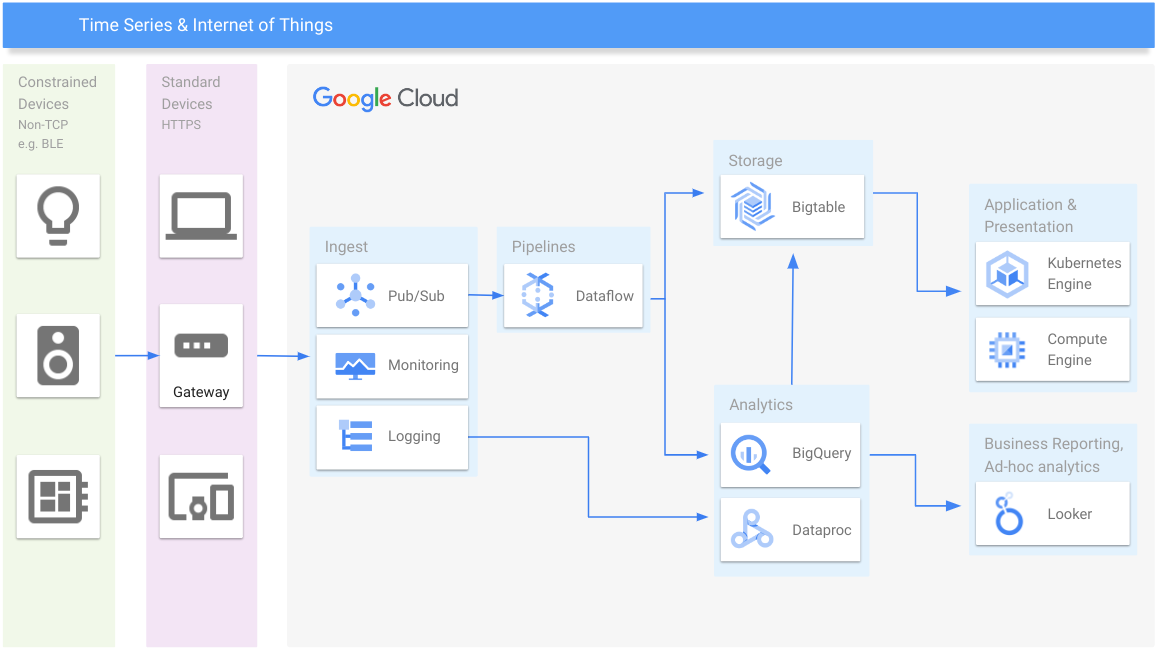
时序和 IoT
管理任意规模的时序数据
学习资源
管理任意规模的时序数据
价格
| Bigtable 定价方式 | Bigtable 价格基于计算容量、数据库存储空间、备份存储空间和网络用量。承诺使用折扣可进一步降低价格。 | |
|---|---|---|
| 服务 | 说明 | 价格 |
计算容量 | 计算容量预配为节点。 | 起价 $0.65 每个节点每小时 |
Data Boost | 用于批量处理的按需、隔离的计算资源 | 起价 $0.000845 每小时每个无服务器处理单元 |
数据存储 | SSD 价格取决于表的物理大小。每个副本分别计费。建议用于低延迟传送。 | 起价 $0.17 每月每 GB |
HDD 价格取决于表的物理大小。每个副本分别计费。 | 起价 $0.026 每月每 GB | |
备份 | 价格取决于备份的物理大小。Bigtable 备份是增量备份。 | 起价 $0.026 每月每 GB |
网络 | 入站 | 免费 |
同一区域内的出站流量 | 免费 | |
区域之间的出站流量 | 起价 $0.10 每 GB | |
复制 | 在同一区域内 | 免费 |
在区域之间 | 起价 $0.01 每 GB | |
Bigtable 定价方式
Bigtable 价格基于计算容量、数据库存储空间、备份存储空间和网络用量。承诺使用折扣可进一步降低价格。
计算容量预配为节点。
Starting at
$0.65
每个节点每小时
Data Boost
用于批量处理的按需、隔离的计算资源
Starting at
$0.000845
每小时每个无服务器处理单元
SSD
价格取决于表的物理大小。每个副本分别计费。建议用于低延迟传送。
Starting at
$0.17
每月每 GB
HDD
价格取决于表的物理大小。每个副本分别计费。
Starting at
$0.026
每月每 GB
备份
价格取决于备份的物理大小。Bigtable 备份是增量备份。
Starting at
$0.026
每月每 GB
入站
免费
同一区域内的出站流量
免费
区域之间的出站流量
Starting at
$0.10
每 GB
复制
在同一区域内
免费
在区域之间
Starting at
$0.01
每 GB
业务用例
了解其他企业如何借助 Bigtable 打造创新应用、提供出色的客户体验、降低费用并提高投资回报率



优势和客户
利用可无限扩缩以满足任何需求的创新应用拓展您的业务。
获享卓越性价比,只需为实际用量付费。
从其他 NoSQL 数据库轻松迁移,并使用开源 API 和迁移工具运行混合云或多云部署。















合作伙伴与集成
从评估和业务案例,到迁移和在 Bigtable 上构建新应用,具备 Bigtable 专业知识的合作伙伴可在您整个历程的每一步提供帮助。

































系统集成商
想要详细了解哪个合作伙伴或第三方集成最适合您的企业?请查看合作伙伴名录。
常见问题解答
Bigtable 是什么类型的数据库?
Bigtable 是一种 NoSQL 数据库服务,具体而言是键值对存储。它支持包含数万列的超宽表,因此也称为宽列数据库或分布式多维映射。Bigtable 是一种 NoSQL 数据库,其中 NoSQL 指的是 “Not Only SQL”(不仅是 SQL),而非 “Zero SQL”(零 SQL)。它不仅支持键值查找,还支持许多其他功能,包括聚合和全局二级索引。
Apache HBase 和 Cassandra 等热门开源项目是在 Bigtable 的启发下诞生的,因此 Bigtable 与它们非常相似。如果客户需要处理大量数据,并且想要寻找 Google Cloud 上经济实惠且高性能的全托管式 NoSQL 数据库解决方案,Bigtable 通常是最好的选择。
Bigtable 是否支持 SQL?
除了键值对 API 之外,Bigtable 还通过三种方式支持 SQL 查询:
- 对于低延迟应用开发,Bigtable 提供了一个 SQL 查询 API。此 API 以 GoogleSQL 为基础,具有类似于 Cassandra 查询语言 (CQL) 的宽列数据模型的扩展功能。 它支持 100 多种函数,包括聚合 (GROUP BY)、JSON 处理函数以及向量搜索 (kNN)。
- 对于数据科学用例或其他类型的批处理和 ETL,Bigtable 通过 Spark 客户端支持 SparkSQL。
- 如果用户想要执行事后探索性分析或混合多个来源的数据以进行批量分析,还可以从 BigQuery 访问 Bigtable 数据。只需在 BigQuery 中注册 Bigtable 表,然后像查询任何其他 BigQuery 表一样进行查询,而无需执行任何 ETL 或数据重复操作。
如何将数据库迁移到 Bigtable?
Bigtable 提供 Apache Cassandra 和 HBase API 以及迁移工具,可减少工作量并确保准确迁移数据,帮助您更快、更轻松地完成迁移。Bigtable 的 HBase 复制库和 Cassandra 迁移工具支持无停机的实时迁移。Bigtable 还提供实用程序以简化从 DynamoDB 的迁移。
Bigtable 是否是无服务器数据库?
与无服务器模型类似,Bigtable 存储按使用的容量 (GB) 计费。Bigtable 还提供线性横向扩缩,可根据需求波动自动扩缩计算资源。因此它不要求存储或计算的长期容量承诺。但是,低延迟计算的价格基于容量并按节点计费,而不是按请求计费,每个节点每秒最多可处理 1.7 万个请求。这使得 Bigtable 更适合大型工作负载,而不太适合小型应用。小型应用可能更适合使用 Firestore 等 Google Cloud 数据库。
针对批量数据处理,Bigtable 提供 Data Boost,该服务以无服务器处理单元 (SPU) 为单位计费。











