Distributed counting in Bigtable: why you need it, and how to get started
Bora Beran
Group Product Manager
Steve Niemitz
Senior Staff Software Engineer
Having a single view or set of metrics that captures your entire business is critical for delighting your users and staying ahead of your competitors. Whether you need to understand user needs and preferences by identifying popular features or evaluating a design change (A/B test), measure engagement by tracking shares, likes, and unique visits, or improve the user experience by building real-time recommendations, these experiences depend on access to up-to-date statistics. In most database environments, that means building “counters”, which typically involve complex Lambda architectures that often force you to make difficult tradeoffs between cost, speed and accuracy.
A couple of weeks ago, at Google Cloud Next ‘24 in Tokyo, we announced the general availability of new capabilities to make it easy to build distributed counters in Bigtable, empowering you to focus on growth, not data wrangling. Read on for a deep dive on counters in Bigtable, the use cases, and how to get started.
Counting with Bigtable
Distributed counting needs special data structures to handle large data volumes with low latency. This allows processing event streams in real-time for analytics and machine learning. Ultimately, it enables use cases such as fraud detection, personalization, and operational reporting.
Bigtable’s new aggregate types are such structures that make it easy to sum daily user engagement, find the minimum to determine the lowest sensor reading, use a maximum to identify your peak usage, or track an approximate count of distinct users. These new specialized types take advantage of certain properties of the operations such as the commutative and associative nature of the math to much more efficiently perform calculations at write-time at scale, even in globe-spanning deployments, and reduce the need for complex, time-consuming, costly streaming architectures.
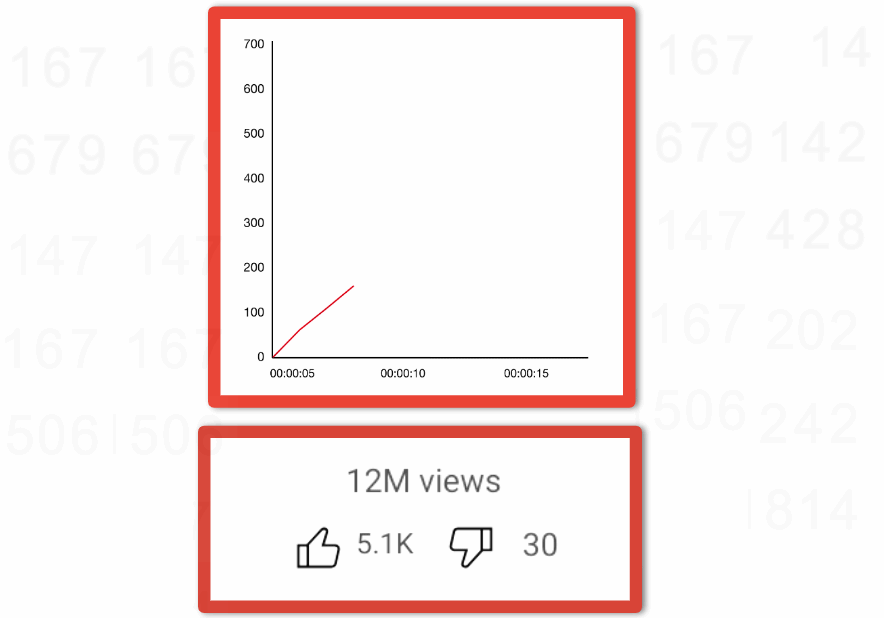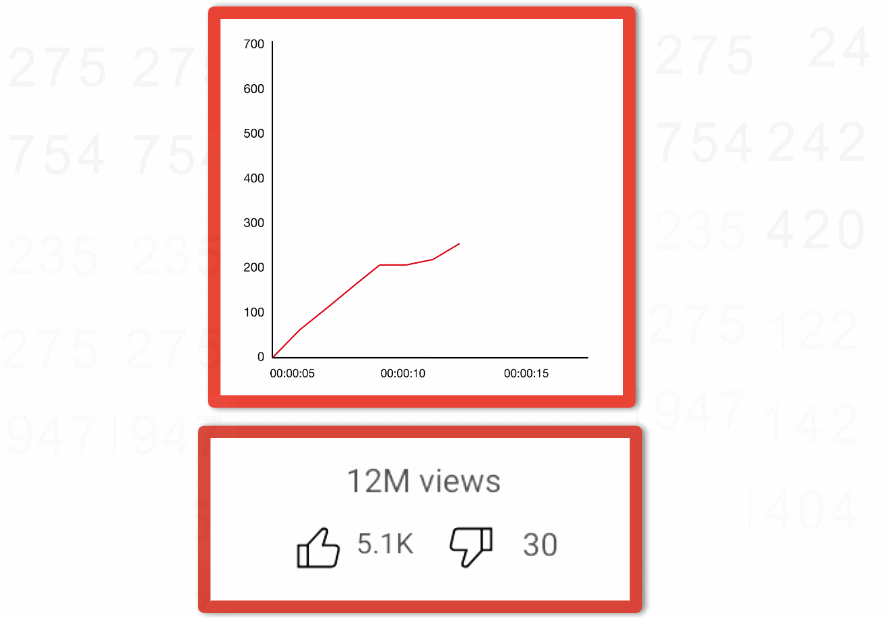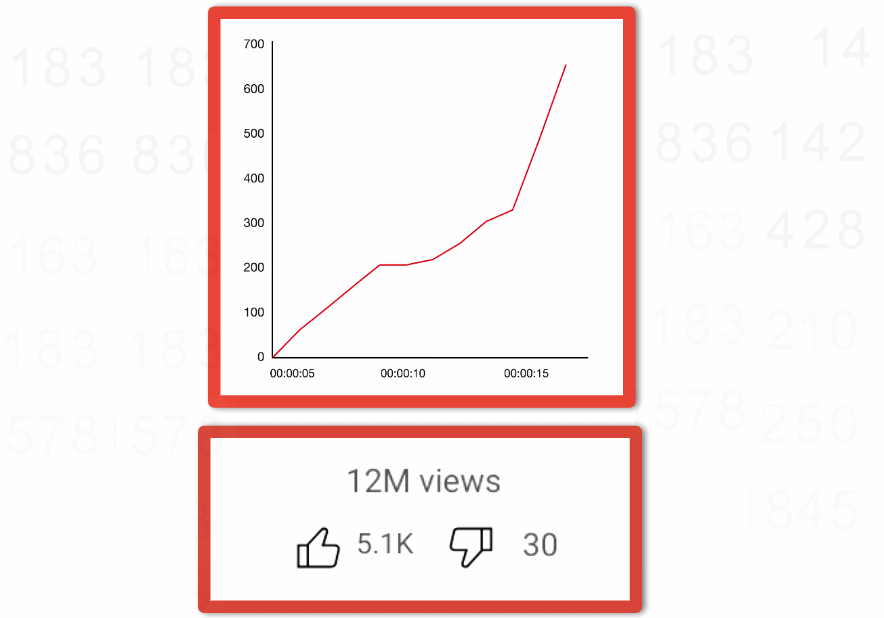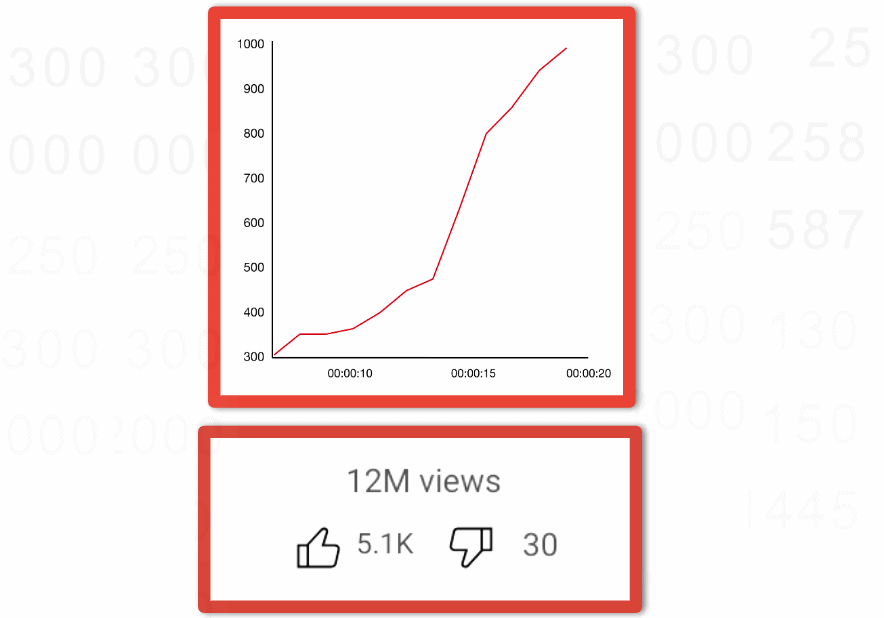
Image provides an example of a counter that you have probably seen before that is tracking engagement as likes, dislikes, and views over time.
Let’s now take a look at how Bigtable can streamline your analytics workflows.
Example use cases
Imagine you're running a social media app and need to track billions of interactions with content every day throughout the world, such as the total number of impressions, views, and clicks. This use case is not much different than tracking interactions with ads in marketing, product listings in retail or page views on any website. In the past, you had two main options. Either you could write each activity to the database and then run multiple queries to calculate the totals; that can be expensive, result in delayed metrics, and negatively impact serving performance during processing, even on specialized columnar systems. Or you could turn to a streaming framework, which, while capable of handling real-time data, has a complicated architecture with management overhead and significant additional costs.
With Bigtable, you can simply increment a counter for each activity as it occurs, which makes the total count available within Bigtable instantly. You can also decrement, even delete or reset counts, and the numbers will synchronize. The results can be read from a dashboard or application with single-digit millisecond latency, providing your global workforce, partners, advertisers, and customers with up-to-date key engagement metrics for various campaigns and marketing initiatives.
While seemingly simple, counting can be quite powerful. Consider these additional use cases:
-
Web analytics: Measure Unique visitors, daily/weekly/monthly active users.
-
AdTech: Track impressions, engagements, clicks for ads served.
-
IoT & telemetry: Aggregate sensor data, track device usage, or identify trends and anomalies.
-
Social media: Measure user interactions, analyze content popularity, or track trending topics.
-
Gaming: Monitor player activity, track achievements, or analyze game performance.
-
E-commerce: Track sales, inventory levels, or customer engagement metrics in real time.
Benefits
-
Efficient data aggregation: Automatically generate metrics in Bigtable on any table. Merge values (+/-) or delete/reset counters. Metrics can be stored across time windows and retrieved with low-latency lookups.
-
Massive throughput: Build metrics on streaming data with tens of thousands of mutations per second per Bigtable node even on a single metric.
-
Global consistency: Metrics can be consolidated throughout the globe and any inconsistencies are automatically resolved and won’t diverge (i.e. they’re eventually consistent).
Building your first counter
Building a counter in Bigtable is straightforward. For this walkthrough, let’s build on our previous example that is tracking billions of daily user interactions throughout the world. Let’s say we now want to track the unique individuals that are engaging with each post.
First, create an aggregate column family, specifying the desired aggregation function. This may be a SUM, MIN, MAX, or, for our example, the HyperLogLog (HLL) data type, which lets us approximately count by unique values. Bigtable relies on HLL++ sketch for this approximation.
In the code snippets below, we assume we have an existing table called posts where each row is a social media post that’s already storing the text copy, author, etc. We will add a counter directly to this table.
We will use Bigtable’s command line tool (cbt) to add a column family called count that has no garbage collection policy (never) and is of HLL type, that will accept integers as inputs (inthll).
Each column within the column family shares the same type. Typically, we would write new data to a Bigtable column by calling SetCell. However, when writing to aggregate column families like sum, min, max or HLL, we instead make an AddToCell request, either from a Bigtable client library or from the cbt command-line tool, as shown here.
In the above example, we are recording that a user represented by an ID of 100 has viewed the post with a row key of id123. The number following the @ represents a UNIX timestamp in microseconds. Each Bigtable write requires a timestamp. Truncated timestamps can be used to group interactions into hourly, daily, weekly, etc. buckets, so we can generate a time-series view of unique users. Using Bigtable client libraries, you can even update multiple counters within a row in a single transaction, which allows you to update related metrics e.g., view counts vs. unique viewer counts, and hierarchical metrics like daily, monthly, annual counts for a home listing, or song, album, artist streams for a music service in a single write. Check out this example for more on time-bucketing. For this example, let’s assume we’re tracking daily unique counts.
When you add a value to an HLL cell, the value is added to a probabilistic set of all values added since the last reset. This means that the application does not record individual user ids, hence it is fast and takes much less space. To find out more about HLL++ and how you can use sketches created with BigQuery and Dataflow in Bigtable and vice versa, check out the Zetasketch library.
We can easily retrieve counts using Bigtable client libraries. Below is an example that shows how we can retrieve all the information necessary to display a social media post along with the unique view count in a single, compact query using the recently introduced SQL API.
Given the date truncation approach we chose, we could also easily retrieve distinct counts over time to better understand viewership trends.
It all adds up
Bigtable now offers powerful tools that simplify data aggregation and enhance your analytics capabilities. By enabling you to perform calculations in the database at write-time, Bigtable saves time, reduces complexity, and provides instant access to critical insights. If you're looking to streamline your analytical workflows, Bigtable can help provide a real-time edge. To learn more and get started, check out the Bigtable documentation.

