パフォーマンスについて
このページでは、最適な条件下にある Bigtable で実現可能なおおよそのパフォーマンス、パフォーマンスに影響を与える可能性がある要因、Bigtable のパフォーマンスをテストして問題があった場合のトラブルシューティングのヒントを示します。
通常のワークロードでのパフォーマンス
Bigtable では、パフォーマンスを高い精度で予測し、線形的にスケーリングできます。次に説明するパフォーマンス低下の原因を回避した場合、各 Bigtable ノードで実現されるおおよそのスループットは、クラスタで使用されているストレージの種類に応じて次のようになります。
| ストレージの種類 | 読み取り | 書き込み | スキャン | ||
|---|---|---|---|---|---|
| SSD | 1 秒あたり最大 17,000 行 | または | 1 秒あたり最大 14,000 行 | または | 最大 220 MB/秒 |
| HDD | 1 秒あたり最大 500 行 | または | 1 秒あたり最大 10,000 行 | または | 最大 180 MB/秒 |
この推定値は、各行に 1 KB のデータが格納されていることを前提としています。
一般に、クラスタにノードを追加すると、クラスタのパフォーマンスは線形的にスケーリングします。たとえば、ノードが 10 個の SSD クラスタを作成すると、通常の読み取り専用または書き込み専用のワークロードの場合、このクラスタでは 1 秒あたり最大 140,000 行をサポートできます。
Bigtable の容量を計画する
Bigtable クラスタを計画する際は、レイテンシとスループットのどちらを最適化するか決定します。たとえば、バッチデータ処理ジョブでは、スループットは重視しても、レイテンシはそれほど重視しないことがあります。一方、ユーザー リクエストを処理するオンライン サービスの場合は、スループットよりもレイテンシの方を優先する場合があります。スループットを最適化するときに、一般的なワークロードでのパフォーマンス セクションの数値を達成できます。
CPU 使用率
ほとんどの場合、自動スケーリングを使用することをおすすめします。これにより、Bigtable は使用状況に基づいてノードを追加または削除できます。詳細については、自動スケーリングをご覧ください。
自動スケーリング ターゲットを構成する場合、または手動ノード割り当てを選択する場合は、次のガイドラインを使用してください。これらのガイドラインは、インスタンスに含まれるクラスタの数に関係なく適用されます。手動ノード割り当てを使用するクラスタでは、パフォーマンスを最適にするために、CPU 使用率をこれらの値未満に保つことを目標に、クラスタの CPU 使用率をモニタリングする必要があります。
| 最適化の目標 | 最大 CPU 使用率 |
|---|---|
| スループット | 90% |
| レイテンシ | 60% |
モニタリングの詳細については、モニタリングをご覧ください。
ストレージの利用率
容量計画のもう一つの考慮事項はストレージです。クラスタのストレージ容量は、ストレージ タイプとクラスタ内のノード数によって決まります。クラスタに保存されるデータ量が増加すると、Bigtable はクラスタ内のすべてのノードにデータを分散してストレージを最適化します。
ノードのストレージ使用量は、クラスタのストレージ使用率(バイト数)をクラスタ内のノード数で割ることで計算できます。たとえば、3 つの HDD ノードと 9 TB のデータのあるクラスタについて考えてみましょう。各ノードに格納される容量は約 3 TB です。これは、ノード上限(16 TB)あたりの HDD ストレージの 18.75% に相当します。
ストレージの使用率を高めると、クラスタ全体で CPU のニーズを満たすのに十分なノード数がある場合でも、ワークロードでのクエリ処理のレイテンシが増加する可能性があります。これは、ノードあたりのストレージが大きいほど、インデックス作成などのバックグラウンド処理が必要になるためです。より多くのストレージを処理するためにバックグラウンドの作業が増加すると、レイテンシが増加し、スループットが低下する可能性があります。
自動スケーリングの設定を構成する際は、まず次の手順を行います。手動ノード割り当てを選択した場合は、クラスタのストレージ使用率をモニタリングし、以下を維持するためにノードを追加または削除します。
| 最適化の目標 | 最大ストレージ使用率 |
|---|---|
| スループット | 70% |
| レイテンシ | 60% |
詳細については、ノードあたりのストレージをご覧ください。
Bigtable に対して通常のワークロードを実行する
容量の計画を行う際は、Bigtable クラスタに対し、必ず独自の一般的なワークロードを実行してください。これにより、アプリケーションに最適なリソース割り当てを把握できます。
Google の PerfKit Benchmarker は、YCSB を使用してクラウド サービスのベンチマークを行います。Bigtable 用の PerfKitBenchmarker チュートリアルに従って、独自のワークロード用のテストを作成できます。その際は、生成されるベンチマークが本番環境で次の特性を反映するように、ベンチマーク構成 yaml ファイルのパラメータを調整する必要があります。
- テーブルの合計サイズ。調整できますが、100 GB 以上を使用してください。
- 行データの形状(行キーのサイズ、列の数、行のデータサイズなど)
- データアクセス パターン(行キーの分布)
- 読み取りと書き込みの混在
ベスト プラクティスについては、Bigtable を使ったパフォーマンス テストをご覧ください。
パフォーマンス低下の原因
Bigtable のパフォーマンスが上記の推定値よりも低くなることがあります。その原因として次のことが考えらます。
- 1 つの読み取りリクエストで連続していない行キーまたは行範囲を大量に読み取る。Bigtable はテーブルをスキャンし、リクエストされた行を順次読み取ります。この並列性の欠如が全体的なレイテンシに影響を与え、ホットノードが読み取られると、テール レイテンシの増加につながる場合があります。詳細については、読み取りとパフォーマンスをご覧ください。
- テーブルのスキーマが正しく設計されていません。Bigtable で良好なパフォーマンスを得るには、各テーブルに読み取りおよび書き込みを均等に分散できるスキーマを設計することが不可欠です。また、あるテーブルのホットスポットが、同じインスタンスの他のテーブルのパフォーマンスに影響する可能性もあります。詳しくは、スキーマ設計のベスト プラクティスをご覧ください。
- Bigtable テーブルの行に大量のデータが含まれています。前述のパフォーマンス推定値は、各行に 1 KB のデータが含まれていることを前提としています。1 行あたり大量のデータを読み取り、書き込みできますが、1 行あたりのデータ量を増やすと、1 秒あたりの行数も減少します。
- Bigtable テーブルの行に大量のセルが含まれています。 Bigtable が行内の各セルを処理するため時間がかかります。セルが多くなると、テーブルにデータを格納する際やネットワーク経由でのデータを送信する際のオーバーヘッドも増加します。たとえば、1 KB(1,024 バイト)のデータを格納する場合、1 バイトずつ 1,024 個のセルに分散させるのではなく、データを 1 つのセルに格納したほうがスペース効率が良くなります。必要以上に多くのセルにデータを分割すると、最高のパフォーマンスが得られない可能性があります。タイムスタンプ付きバージョンのデータが列に複数含まれることで行に多数のセルが含まれている場合は、最新の値のみを保持することを検討してください。既存のテーブルに対する別の方法としては、以前のバージョンすべての削除を書き換えごとに送信することが挙げられます。
Bigtable クラスタに十分なノードが存在しません。クラスタのノードは、クラスタの読み取りと書き込み、ストレージの追跡、圧縮などのメンテナンス タスクを行うクラスタを提供します。コンピューティングとストレージの両方の推奨制限を満たすのに十分なノードをクラスタで確保する必要があります。モニタリング ツールを使用して、クラスタが過負荷状態になっているかどうかチェックしてください。
- コンピューティング - Bigtable クラスタの CPU が過負荷状態のときにノードを追加すると、より多くのノードにワークロードを分散してパフォーマンスを改善できます。
- ストレージ - ノードあたりのストレージ使用量が推奨値を上回る場合は、クラスタがリクエストを処理するのに十分な CPU を備えていても、最適なレイテンシとスループットを維持するためにノードを追加する必要があります。これは、ノードあたりのストレージを増やすと、ノードあたりのバックグラウンド メンテナンス作業が増えるためです。詳細については、ストレージの使用量とパフォーマンスのトレードオフをご覧ください。
最近 Bigtable クラスタがスケールアップまたはスケールダウンされています。クラスタ内のノード数が増加した後、クラスタのパフォーマンスが大幅に向上するまでに、負荷のかかった状態が最大 20 分間続く可能性があります。Bigtable は、その負荷に基づいてクラスタ内のノードをスケーリングします。
クラスタ内のノード数を減らしてスケールダウンする場合は、レイテンシの急増を最小限に抑えるため、10 分間は 10% を超えるクラスタサイズの縮小は行わないようにしてください。
Bigtable クラスタが HDD ディスクを使用しています。ほとんどの場合、クラスタには SSD ディスクを使用すべきです。SSD ディスクを使用すると、HDD ディスクに比べてパフォーマンスが大幅に向上します。詳しくは、SSD ストレージか HDD ストレージの選択をご覧ください。
ネットワーク接続で問題が発生しています。ネットワークの問題が発生するとスループットが低下し、読み取りと書き込みに要する時間が通常より長くなります。特に、クライアントが Bigtable クラスタと同じゾーンで実行されていない場合や、クライアントが Google Cloudの外部で実行されている場合は、問題が発生することがあります。
レプリケーションを有効にしていますが、アプリケーションが古いクライアント ライブラリを使用しています。レプリケーションを有効にした後にレイテンシが増加した場合は、アプリケーションで使用している Cloud Bigtable クライアント ライブラリが最新かどうか確認してください。古いバージョンのクライアント ライブラリは、レプリケーションをサポートするように最適化されていない場合があります。Cloud Bigtable クライアント ライブラリで、使用しているクライアント ライブラリの GitHub リポジトリを探してください。ライブラリのバージョンを確認して、必要に応じてアップグレードしてください。
レプリケーションを有効にしましたが、クラスタにノードを追加していません。レプリケーションを使用するインスタンスの場合、各クラスタで、アプリケーションからの負荷に加えて、レプリケーションの作業を処理する必要があります。クラスタのプロビジョニングが不足すると、レイテンシが増加する可能性があります。これは、Google Cloud Console のインスタンスの CPU 使用率グラフで確認できます。
ワークロードが異なるとパフォーマンスも変化するため、最も正確なベンチマークが得られるよう、テストは自分のワークロードを使って実行してください。
コールド スタートと低 QPS
コールド スタートをし QPS が低い場合、レイテンシが増加する可能性があります。Bigtable は、頻繁にアクセスされる大きなテーブルで優れたパフォーマンスを発揮します。このため、使用していない期間(コールド スタート)の後にリクエストの送信を開始する場合、Bigtable が接続を再確立している間、レイテンシが高くなる可能性があります。 QPS が低い場合、レイテンシも高くなります。
QPS が低い場合や、アクティブでない状態が一定時間続いた後に Bigtable テーブルにリクエストを送信することがわかっている場合は、接続をウォーム状態に保ち、このような高レイテンシを防ぐために、次の方法を試してください。
- 低頻度で人工的なトラフィックを常時テーブルに送信する。
- 安定した QPS でプールがアクティブになるように接続プールを構成する。
QPS が低い期間中は、エラーを返すオペレーションの割合よりも Bigtable が返すエラー数のほうが重要になります。
クライアントの初期化時にコールド スタートする。使用している Java 用 Cloud Bigtable クライアントのバージョンが 2.18.0 より前の場合は、チャネルの更新を有効にすることができます。新しいバージョンでは、チャネルの更新がデフォルトで有効になっています。チャンネルの更新は次の 2 つの処理を行います。
- クライアントが初期化されると、最初のリクエストを送信する前にチャネルを準備します。
- サーバーは、長時間接続している接続を 1 時間ごとに切断します。チャネル プライミングでは、期限切れのチャネルが事前に入れ替わります。
ただし、この方法では、無活動期間があってもチャンネルがアクティブな状態に保たれるわけではありません。
Bigtable が時間の経過とともにデータを最適化する方法
各テーブルの基盤となるデータを格納するために、Bigtable はデータを複数のタブレットに分割します。タブレットは、Bigtable クラスタ内のノード間を移動できます。このストレージ方式により、Bigtable は、2 つの異なる戦略を用いて、時間の経過に伴うデータの最適化を実行できます。
- Bigtable は、各 Bigtable ノード上にほぼ同じ量のデータを格納しようと試みます。
- Bigtable はすべての Bigtable ノード上に、読み取りオペレーションと書き込みオペレーションを均等に分散しようと試みます。
この 2 つの戦略は互いに矛盾することがあります。たとえば、あるタブレットの行に対する読み取り頻度が非常に高い場合、Bigtable は、一部のノードに格納されるデータが他のノードより多くなったとしても、そのタブレットを専用のノードに格納することがあります。
このプロセスで、Bigtable は、1 つのタブレットを 2 つ以上の小さなタブレットに分割して、タブレット サイズを減らすことや、既存のタブレット内のアクセスが集中している行を分離することがあります。
以下の各セクションで、これらの戦略について詳しく説明します。
各ノードにデータ量を分散配置する
Bigtable テーブルにデータを書き込む際、Bigtable では、テーブルのデータを複数のタブレットに分割します。各タブレットにはテーブル内の連続する範囲の行が格納されます。
テーブルへの書き込みが数 GB 未満の場合、Bigtable はすべてのタブレットをクラスタ内の 1 つのノードに保存します。
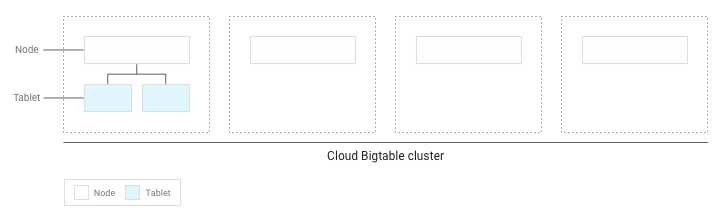
タブレットが蓄積すると、Bigtable は、その一部をクラスタ内のほかのノードに移動させて、クラスタ全体でデータ量が均等に分散されるようにします。
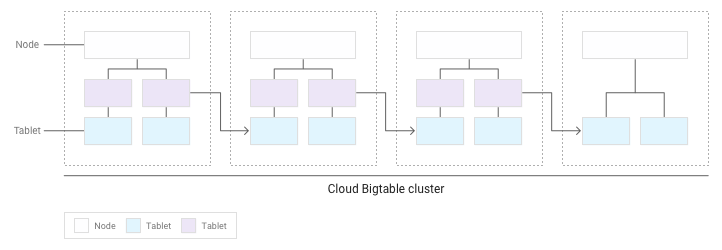
各ノードに読み取りオペレーションと書き込みオペレーションを分散させる
スキーマの設計が正しければ、読み取りオペレーションと書き込みオペレーションが表全体にほぼ均等に分散されるはずです。ただし、特定の行に対するアクセス頻度が他の行より高くなるのを避けられないケースもあります。Bigtable は、各ノードにタブレットを分散配置する際に読み取りオペレーションと書き込みオペレーションを考慮することで、このようなケースに対応できるようにします。
たとえば、読み取りオペレーションの 25% がクラスタ内の少数のタブレットに集中しており、それ以外のすべてのタブレットには読み取りオペレーションが均等に分散しているとします。
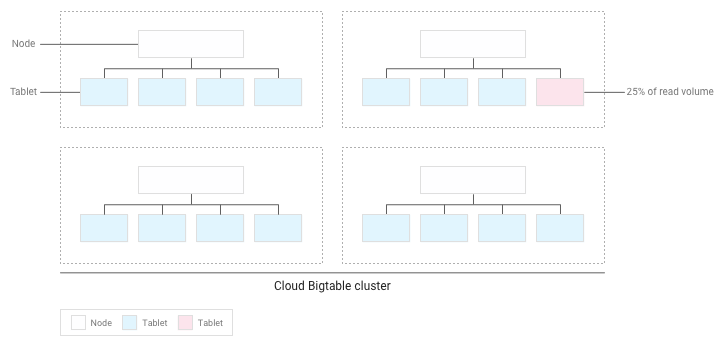
Bigtable は既存のタブレットを再配置して、読み取りオペレーションがクラスタ全体でできる限り均等に分散するようにします。
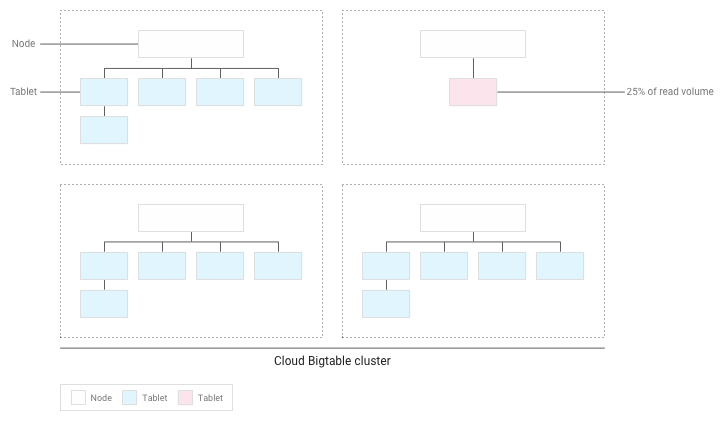
Bigtable でパフォーマンスをテストする
Bigtable に依存するアプリケーションのパフォーマンス テストを行う場合は、テストを計画および実行する際に、次のガイドラインに従ってください。
- 十分なデータでテストする。
- 本番環境インスタンスのテーブルに含まれるデータがノードあたり合計 100 GB 以下の場合は、同じ量のデータのテーブルでテストします。
- テーブルに含まれるデータがノードあたり 100 GB を超える場合は、ノードあたり 100 GB 以上のデータを含むテーブルでテストします。たとえば、本番環境のインスタンスに 1 つの 4 ノードクラスタがあり、インスタンスのテーブルに合計 1 TB のデータが含まれている場合は、400 GB 以上のテーブルを使用してテストを実行します。
- 単一のテーブルでテストする。
- ノードあたりの推奨ストレージ使用率を超えないようにします。詳細については、ノードあたりのストレージ使用率をご覧ください。
- テスト前に、負荷の大きな事前テストを数分間実行します。この手順により、Bigtable は観察したアクセス パターンに基づいてノード間にデータを分散させます。
- 最低 10 分間テストを実行します。この手順により、Bigtable はデータをさらに最適化するので、ディスクからの読み取りだけでなく、メモリからのキャッシュ経由の読み取りも確実にテストできます。
パフォーマンスに関する問題のトラブルシューティング
アプリケーションでパフォーマンスのボトルネックが発生していると思われる場合は、以下のすべての項目をチェックしてください。
- Key Visualizer でテーブルのスキャン結果を確認します。Bigtable 用 Key Visualizer ツールは、クラスタ内の各テーブルの使用パターンを表示する新しいスキャンデータを 15 分ごとに生成します。Key Visualizer を使用すると、使用パターンが問題の原因かどうかを確認できます。たとえば、ホットスポットになっている行や CPU の過剰使用を確認できます。Key Visualizer の使い方を学習する。
- Bigtable の読み取りと書き込みを実行するコードをコメントアウトしてみます。パフォーマンスの問題が解消した場合は、次善のパフォーマンスしか得られないような方法で Bigtable を使用している可能性があります。パフォーマンスの問題が解決しない場合は、おそらく Bigtable とは無関係の問題が発生しています。
作成するクライアント数をできるだけ少なくします。Bigtable でクライアントを作成する処理は比較的負荷の大きいオペレーションです。このため、作成するクライアント数はできるだけ少なくする必要があります。
- レプリケーションを使用する場合や、アプリ プロファイルを使用してインスタンスへのトラフィックの種類を識別する場合は、アプリ プロファイルごとに 1 つのクライアントを作成し、アプリ全体でそのクライアントを共有します。
- レプリケーションやアプリ プロファイルを使用しない場合は、クライアントを 1 つだけ作成し、アプリケーション全体で共有します。
Java 用 HBase クライアントを使用している場合は、クライアントではなく
Connectionオブジェクトを作成するため、確立する接続の数をできる限り少なくする必要があります。テーブル内で多数の異なる行の読み取りと書き込みが行われていることを確認します。Bigtable では、読み取りオペレーションと書き込みオペレーションがテーブル全体に均等に分散され、結果として、ワークロードがクラスタ内のすべてのノードに分散されるときに、最高のパフォーマンスが得られます。読み取りオペレーションと書き込みオペレーションをすべての Bigtable ノードに分散させることができない場合は、パフォーマンスが低下します。
読み取りおよび書き込みオペレーションが少数の行に限られていることが判明したら、スキーマの設計を見直して読み取りおよび書き込みオペレーションがより均等に分散されるようにする必要があります。
読み取りオペレーションと書き込みオペレーションで、ほぼ同じパフォーマンスが得られていることを確認します。読み取りオペレーションが書き込みオペレーションに比べてかなり速いことが判明したら、存在しない行キー、またはごく少数の行しか含まれていない広範囲の行キーを読み取ろうとしている可能性があります。
読み取りオペレーションと書き込みオペレーションの間で正当な比較を行うには、読み取りオペレーションの 90% 以上が有効な結果を返すという状態を目指す必要があります。また、広範な行キーを読み取る場合は、存在する可能性のある最大行数ではなく、その範囲内の実際の行数に基づくパフォーマンスを計測するようにします。
データに適したタイプの書き込みリクエストを使用します。データの書き込みに最適な方法を選択すると、高いパフォーマンスを維持できます。
1 行のレイテンシを確認します。
ReadRowsリクエストの送信時に予期しないレイテンシが発生した場合は、リクエストの最初の行のレイテンシを確認して原因を絞り込むことができます。デフォルトでは、ReadRowsリクエストの全体的なレイテンシには、リクエストの各行のレイテンシと、行間の処理時間が含まれます。全体的なレイテンシが高くても、最初の行のレイテンシが低い場合は、Bigtable の問題ではなく、リクエスト数または処理時間がレイテンシの原因であることを意味します。Java 用 Bigtable クライアント ライブラリを使用している場合は、クライアントサイドの指標を有効にすると、Google Cloud コンソールの Metric Explorer に
read_rows_first_row_latency指標を表示できます。ワークロードごとに個別のアプリ プロファイルを使用します。新しいワークロードを追加した後にパフォーマンスの問題が発生した場合は、新しいワークロード用に新しいアプリ プロファイルを作成します。さらに、アプリ プロファイルの指標を個別にモニタリングして、より詳細なトラブルシューティングを行うことができます。複数のアプリ プロファイルの使用が推奨される理由について詳しくは、アプリ プロファイルの仕組みをご覧ください。
クライアント サイドの指標を有効にします。クライアント サイドの指標を設定すると、パフォーマンスの問題の最適化とトラブルシューティングに役立ちます。たとえば、Bigtable は均等に分散された高 QPS で最適に機能します。リクエストのごく一部でレイテンシが P100(最大)に増加しても、Bigtable のパフォーマンスの問題が増大するとは限りません。クライアント サイドの指標を使用すると、リクエスト ライフサイクルのどの部分がレイテンシの原因となっているかを把握できます。
次のステップ
- Bigtable スキーマの設計方法を確認する。
- Bigtable パフォーマンスのモニタリング方法を確認する。
- Key Visualizer で問題のトラブルシューティングを行う方法を学習する。
- プログラムで Bigtable クラスタにノードを追加するサンプルコードを見る。