组织 BigQuery 资源
与其他 Google Cloud 服务一样,BigQuery 资源是按层次结构组织的。您可以使用此层次结构来管理 BigQuery 工作负载的各个方面,例如权限、配额、槽预留和结算。
资源层次结构
BigQuery 继承了 Google Cloud 资源层次结构,并添加了特定于 BigQuery 的额外分组机制,称为数据集。本部分介绍此层次结构的元素。
数据集
数据集是用于组织和控制 BigQuery 资源的访问权限的逻辑容器。数据集与其他数据库系统中的架构类似。
您创建的大多数 BigQuery 资源(包括表、视图、函数和过程)都是在数据集中创建的。连接和作业是例外;它们与项目而不是数据集关联。
数据集有一个位置。创建表时,表数据存储在数据集的位置。在为生产数据创建表之前,请考虑您的位置要求。您无法在创建数据集后更改其位置。
项目
每个数据集都与一个项目相关联。如需使用 Google Cloud,您必须至少创建一个项目。项目是创建、启用和使用所有 Google Cloud 服务的基础。如需了解详情,请参阅资源层次结构。一个项目可以具有多个数据集,而不同位置的数据集可以位于同一项目中。
当您对 BigQuery 数据执行操作时(例如运行查询或将数据注入到表中),需要创建作业。作业始终与项目关联,但不必在包含数据的项目中运行。实际上,一个作业可能会引用多个项目中数据集的表。查询作业、加载作业或提取作业始终与其引用的表在同一位置运行。
每个项目都有一个与之关联的 Cloud Billing 账号。项目产生的费用将计入该账号。如果您使用按需价格,则查询费用计入运行查询的项目。如果您使用基于容量的价格,则槽预留会计入用于购买槽的管理项目。存储费用计入数据集所在的项目。
文件夹
文件夹是项目之上的额外分组机制。文件夹中的项目和文件夹会自动继承其父级文件夹的访问权限政策。文件夹可用于为公司内的不同法人实体、部门和团队建模。
组织
组织资源代表组织(例如公司),同时也是Google Cloud 资源层次结构中的根节点。
您不需要组织资源即可开始使用 BigQuery,但我们建议您创建一个组织资源。通过使用组织资源,管理员可以集中控制 BigQuery 资源,而不是让各个用户控制其创建的资源。
下图展示了资源层次结构的示例。在此示例中,组织在文件夹中有一个项目。该项目与一个结算账号关联,并且项目包含三个数据集。
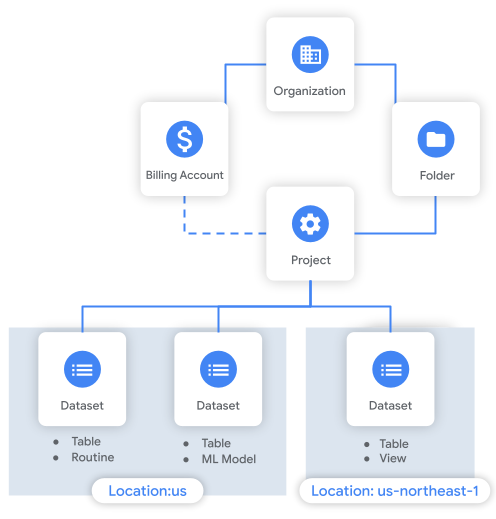
注意事项
在选择如何组织 BigQuery 资源时,请考虑以下几点:
- 配额。许多 BigQuery 配额在项目级层应用。少数配额在数据集级层应用。涉及计算资源的项目级配额(例如查询和加载作业)计入创建作业的项目,而不是存储项目。
- 结算。 如果您希望组织中的不同部门使用不同的 Cloud Billing 账号,则为每个团队创建不同的项目。在组织级层创建 Cloud Billing 账号并将项目关联到这些账号。
- 槽预留。预留的槽的范围限定为组织资源。购买预留槽容量后,您可以将槽池分配给组织中的任何项目或文件夹,也可以将槽分配给整个组织资源。项目会继承其父级文件夹或组织的槽预留。预留的槽与用于管理槽的管理项目相关联。如需了解详情,请参阅使用 Reservations 管理工作负载。
权限。请考虑您的权限层次结构如何影响组织中需要访问数据的人员。例如,如果您希望向整个团队提供特定数据的访问权限,则可以将该数据存储在单个项目中以简化访问管理。
表和其他实体会继承其父数据集的权限。数据集会继承资源层次结构中其父实体(项目、文件夹、组织)的权限。要对资源执行操作,用户需要该资源的相关权限以及创建 BigQuery 作业的权限。创建作业的权限与用于该作业的项目相关联。
模式
本部分介绍组织 BigQuery 资源的两种常见模式。
中央数据湖,部门数据集市。组织创建一个统一存储项目来保存其原始数据。组织内的各部门创建各自的数据集市项目用于分析。
部门数据湖,中央数据仓库。每个部门创建和管理自己的存储项目,以保存该部门的原始数据。然后,组织创建一个中央数据仓库项目用于分析。
每种方法各有利弊。许多组织将这两种模式的元素结合在一起。
中央数据湖,部门数据集市
在此模式中,您将创建一个统一存储项目来保存组织的原始数据。您的数据注入流水线也可以在此项目中运行。统一的存储项目充当组织的数据湖。
每个部门都有自己的专用项目,用于查询数据、保存查询结果以及创建视图。这些部门级项目充当数据集市。它们与部门的结算账号关联。
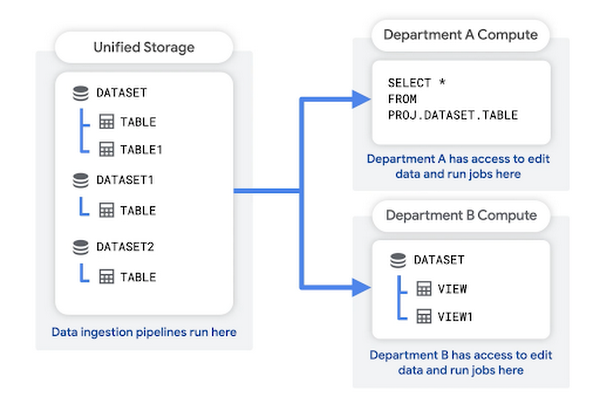
这种结构的优点包括:
- 集中式数据工程团队可以在一个位置管理注入流水线。
- 原始数据与部门级项目隔离。
- 如使用按需价格,运行查询的费用计入运行查询的部门。
- 通过基于容量的价格,您可以根据预计的计算要求为每个部门分配槽。
- 每个部门的项目级配额都与其他部门隔离。
使用此结构时,通常需要以下权限:
- 中央数据工程团队被授予存储项目的 BigQuery Data Editor 和 BigQuery Job User 角色。这允许他们在存储项目中注入和修改数据。
- 部门分析师被授予中央数据湖项目中特定数据集的 BigQuery Data Viewer 角色。这允许他们查询数据,但不能更新或删除原始数据。
- 部门分析师还被授予其部门的数据集市项目的 BigQuery Data Editor 角色和 Job User 角色。这允许他们在其项目中创建和更新表并运行查询作业,从而转换和汇总数据以用于部门特定用途。
如需了解详情,请参阅基本角色和权限。
部门数据湖,中央数据仓库
在此模式中,每个部门创建和管理自己的存储项目,用于保存该部门的原始数据。中央数据仓库项目存储原始数据的聚合或转换。
分析师可以查询和读取数据仓库项目中的汇总数据。数据仓库项目还为商业智能 (BI) 工具提供了一个访问层。
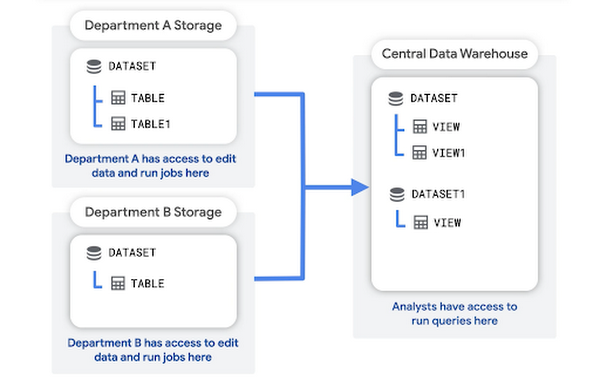
这种结构的优点包括:
- 通过为每个部门使用单独的项目,可以更轻松地在部门级层管理数据访问权限。
- 中央分析团队有一个用于运行分析作业的项目,这使监控查询变得更为轻松。
- 用户可以通过集中式 BI 工具访问数据,该工具与原始数据保持隔离。
- 槽可分配给数据仓库项目,以处理来自分析师和外部工具的所有查询。
使用此结构时,通常需要以下权限:
- 数据工程师被授予其部门的数据集市的 BigQuery Data Editor 和 BigQuery Job User 角色。这些角色允许他们在其数据集市中注入和转换数据。
- 分析师被授予数据仓库项目的 BigQuery Data Editor 和 BigQuery Job User 角色。这些角色允许他们在数据仓库中创建聚合视图并运行查询作业。
- 将 BigQuery 连接到 BI 工具的服务账号被授予特定数据集的 BigQuery Data Viewer 角色,该角色可以保存数据湖中的原始数据或数据仓库项目中的转换数据。
如需了解详情,请参阅基本角色和权限。
您还可以使用授权视图和已获授权的用户定义函数 (UDF) 等安全功能来向特定用户提供汇总数据,而无需向他们授予查看数据集市项目中原始数据的权限。
此项目结构可能会导致数据仓库项目中存在许多并发查询。因此,您可能会达到并发查询限制。如果您采用此结构,请考虑提高项目的此配额限制。此外,请考虑使用基于容量的结算,这样您可以购买槽池来运行查询。