用于空间分析的网格系统
本文档介绍了在 BigQuery 中使用地理空间网格系统(例如 S2 和 H3)在标准化地理区域中整理空间数据的目的和方法。还介绍了如何为应用选择合适的网格系统。本文档适用于在 BigQuery 中处理空间数据和执行空间分析的任何人。
使用空间分析的概览和挑战
空间分析有助于显示实体(商店或住宅)与物理空间中的事件之间的关系。使用地球表面作为物理空间的空间分析称为地理空间分析。BigQuery 包含地理空间功能和函数,可让您大规模执行地理空间分析。
许多地理空间应用场景都涉及汇总本地化区域内的数据,并将这些区域的统计汇总数据进行比较。这些本地化区域在空间数据库表中以多边形表示。在某些情况下,此方法称为统计地理学。确定地理区域范围的方法需要标准化,以便更好地生成报告、进行分析和空间索引。 例如,零售商可能希望分析其商店所在区域或他们考虑开设新店的区域的人口特征随时间的变化情况。或者,保险公司可能希望通过分析特定区域的普遍自然灾害风险,来加深对房产风险的了解。
由于许多区域的数据隐私权法规非常严格,因此包含位置信息的数据集需要进行去标识化或部分匿名化,以帮助保护数据中所代表个人的隐私。例如,您可能需要对包含未偿还抵押贷款相关数据的数据集执行地理信用集中度风险分析。为了对数据集进行去标识化,使其适合进行合规性分析,您需要保留有关房产位置的相关信息,但要避免使用具体地址或经纬度坐标。
在上述示例中,这些分析的设计师面临以下挑战:
- 如何绘制用于分析随时间变化情况的区域边界?
- 如何使用现有行政边界(例如人口普查区)或多分辨率网格系统?
本文档旨在通过解释每种选项、介绍最佳实践并帮助您避免常见误区来回答这些问题。
选择统计区域时的常见误区
房地产销售、营销活动、电子商务货件和保险政策等业务数据集非常适合进行空间分析。这些数据集通常包含看似方便的空间联接键,例如人口普查区、邮政编码或城市名称。包含人口普查区、邮政编码和城市表示形式的公开数据集随处可见,因此很容易想到将它们用作统计汇总的行政边界。
虽然这些行政边界和其他行政边界在名义上很方便,但也有缺点。此外,这些边界可能在分析项目的早期阶段效果不错,但在后期阶段会发现其缺点。
邮政编码
邮政编码用于在世界各地的不同国家/地区投递邮件,并且由于其普遍性,通常用于引用空间数据集和非空间数据集中的位置和区域。以之前的抵押贷款示例为例,数据集通常需要先进行去标识化,然后才能进行下游分析。由于每个房产地址都包含邮政编码,因此可以访问邮政编码参考表,这使其成为空间分析的便捷联接键选项。
使用邮政编码的缺点在于,它们不是以多边形表示的,并且邮政编码区域没有单一的正确信息来源。此外,邮政编码无法很好地反映真实的人类行为。 美国最常用的邮政编码数据来自美国人口普查局 TIGER/Line Shapefile,其中包含一个名为 ZCTA5 (Zip Code Tabulation Area) 的数据集。此数据集表示从邮件投递路线推导出的邮政编码边界的近似值。不过,有些表示单个建筑物的邮政编码根本没有边界。其他国家/地区也存在此问题,因此很难形成一个包含权威邮政编码边界的单一全局事实表,以便在不同系统和数据集之间使用。
此外,世界各地使用的邮政编码格式并不统一。 有些是数字,介于 3 到 10 位之间,有些是字母数字。 此外,国家/地区之间也存在重叠,因此有必要将原产地与邮政编码一起存储在单独的列中。有些国家/地区不使用邮政编码,这进一步增加了分析的复杂性。
人口普查区、城市和县
有些行政单位(例如人口普查区、城市和县)不存在权威边界缺失的问题。例如,在大多数情况下,城市的边界都是由政府机关确定的。美国人口普查区由美国人口普查局以及大多数其他国家/地区的类似机构明确界定。
使用这些行政边界和其他行政边界的缺点是,它们会随着时间的推移而发生变化,并且在地理位置上彼此不一致。县和市可能会合并或拆分,有时还会更名。在美国,人口普查区每十年更新一次,而在其他国家/地区,更新时间各不相同。令人困惑的是,在某些情况下,地理边界可能会发生变化,但其唯一标识符保持不变,这使得分析和了解随时间的变化变得困难。
某些行政边界的另一个常见缺点是,它们是离散的区域,没有地理层次结构。除了比较各个区域之外,一个常见的要求是将区域的汇总与其他汇总进行比较。例如,实施 Huff 模型的零售商可能希望使用多个距离来运行此分析,而这些距离可能与业务中其他地方使用的行政区域不对应。
单分辨率网格和多分辨率网格
单分辨率网格由离散单元组成,与包含这些单元的较大区域没有地理关系。例如,邮政编码与较大行政单位(例如可能包含邮政编码的城市或县)的边界之间存在不一致的地理关系。对于空间分析,务必了解不同区域之间的关系,而无需深入了解定义区域多边形的历史和立法。
多分辨率网格有时也称为分层网格,因为每个缩放级别的单元都会细分为更高缩放级别的更小单元。多分辨率网格由包含在较大单元内的明确定义的单元层次结构组成。例如,人口普查区包含街区组,而街区组又包含街区。这种一致的分层关系有助于进行统计汇总。例如,通过计算某个普查区内包含的所有街区组的平均收入,您可以显示该人口普查区(包含这些街区组)的平均收入。对于邮政编码来说这是不可能的,因为所有邮政编码区域都位于单一分辨率下。由于没有标准化的邻近区域定义方式,也无法比较不同国家/地区的收入,因此很难比较某个普查区与周围普查区的收入。
S2 和 H3 网格系统
本部分简要介绍了 S2 和 H3 网格系统。
S2
S2 几何是 Google 开发并于 2011 年向公众发布的开源分层网格系统。您可以使用 S2 网格系统,通过为每个单元分配一个唯一的 64 位整数来整理空间数据并对其编入索引。分辨率有 31 个级别。每个单元都以正方形表示,专为球面几何图形(有时称为地理位置)上的操作而设计。每个正方形又细分为四个较小的正方形。邻居遍历(即识别相邻 S2 单元的能力)的定义不太明确,因为正方形可能具有 4 个或 8 个相关邻居,具体取决于分析类型。以下是多分辨率 S2 网格单元的示例:
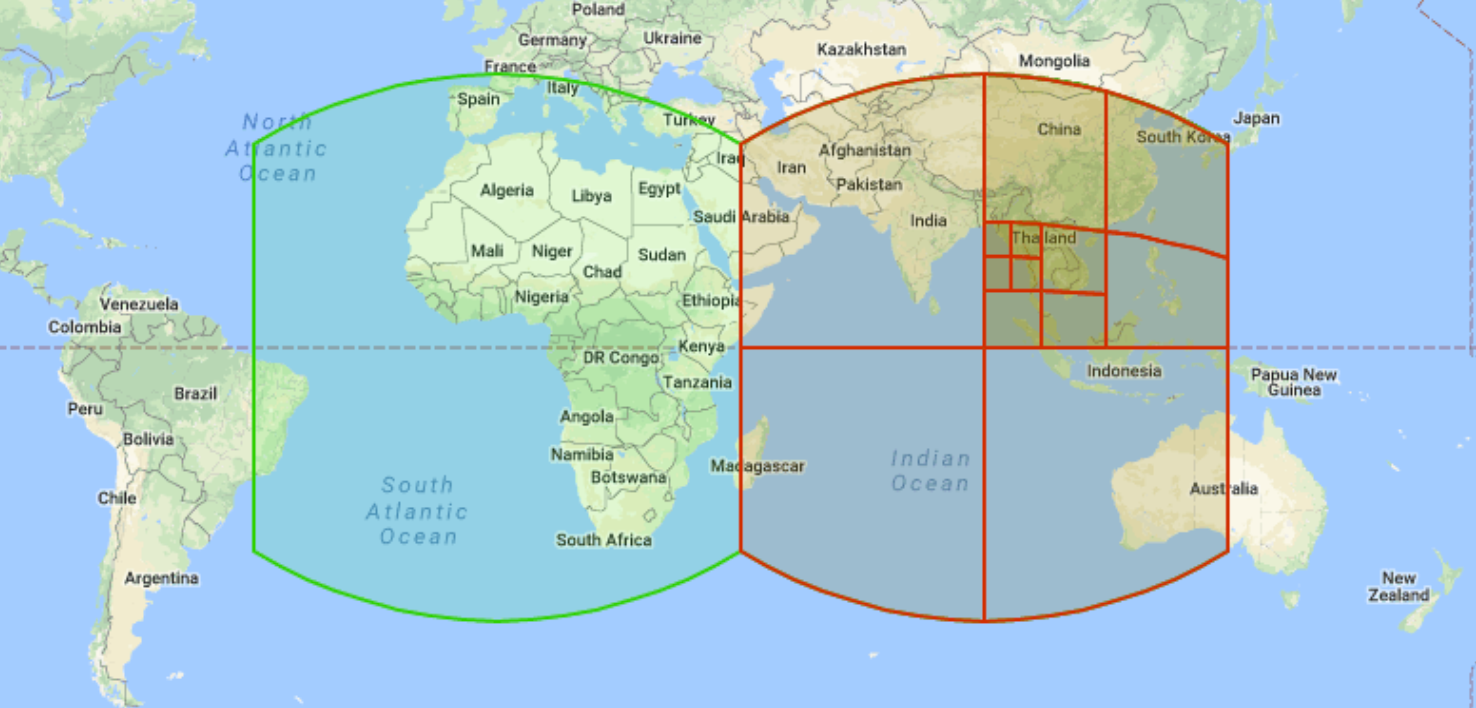
BigQuery 使用 S2 单元为空间数据编入索引,并公开多个函数。例如,S2_CELLIDFROMPOINT 会返回包含地球表面上某个点的 S2 单元 ID(位于给定级别)。
H3
H3 是 Uber 开发并由 Overture Maps 使用的开源分层网格系统。分辨率有 16 个级别。每个单元都表示为六边形,与 S2 类似,每个单元都分配有一个唯一的 64 位整数。在直观呈现覆盖墨西哥湾的 H3 单元的示例中,较小的 H3 单元并未完全包含在较大的单元中。
每个单元细分为七个较小的六边形。细分并不精确,但足以满足许多应用场景。每个单元格与六个相邻单元格共用一条边,从而简化了相邻遍历。例如,在每个级别,都有 12 个五边形,它们与 5 个邻居共享一条边,而不是 6 个。虽然 BigQuery 不支持 H3,但您可以使用 Carto Analytics Toolbox for BigQuery 为 BigQuery 添加 H3 支持。
虽然 S2 和 H3 库都是开源的,并且可根据 Apache 2 许可获取,但 H3 库的文档更详细。
HEALPix
天文学领域常用的另一种球体网格化方案称为分层等面积等纬度像素化 (HEALPix)。HEALPix 与分层像素深度无关,但计算时间保持不变。
HEALPix 是一种用于球体的分层等面积像素化方案。它用于表示和分析天球(或其他球体)上的数据。除了计算时间恒定之外,HEALPix 网格还具有以下特征:
- 网格单元是分层的,其中保留了父子关系。
- 在特定层次结构中,各个单元的面积相等。
- 这些单元遵循等纬度分布,从而提高了频谱方法的性能。
BigQuery 不支持 HEALPix,但有许多语言实现,包括 JavaScript,这可以方便地在 BigQuery 用户定义的函数 (UDF) 中使用。
每种索引编制策略的应用场景示例
本部分提供了一些示例,可帮助您评估哪种网格系统最适合您的应用场景。
许多分析和报告应用场景都涉及可视化,无论是作为分析本身的一部分,还是用于向业务利益相关方报告。这些可视化图表通常以 Web Mercator 格式呈现,这是 Google 地图和许多其他网络地图应用使用的平面投影。如果直观呈现起着至关重要的作用,H3 单元格会提供主观上更好的直观呈现体验。S2 单元(尤其是在较高纬度)往往比 H3 更容易出现失真,并且在平面投影中显示时,与较低纬度的单元格不一致。
H3 单元格可简化实现,其中邻居比较在分析中发挥着重要作用。例如,对城市不同区域进行比较分析可能有助于确定哪个位置适合开设新的零售店或配送中心。分析需要对给定单元的属性进行统计计算,并将其与相邻单元进行比较。
S2 单元在全局性分析(例如涉及距离和角度测量的分析)中效果更好。Niantic 的 Pokemon Go 利用 S2 单元来确定游戏资产的位置和分布方式。S2 单元的确切划分属性可确保游戏资产能够均匀分布在全球各地。
后续步骤
- 如需了解空间聚簇的最佳实践,请参阅 BigQuery 中的空间聚簇 - 最佳实践。
- 了解如何根据不完美的数据创建空间层次结构。
- 了解 GitHub 上的 S2 几何图形。
- 了解 GitHub 上的 H3 几何图形。
- 请参阅使用 H3、BigQuery 和 Earth Engine 的示例。