AI 하이퍼컴퓨터란 무엇인가요?
AI 하이퍼컴퓨터란 무엇인가요?
목적에 맞게 빌드된 하드웨어, 개방형 소프트웨어, 유연한 소비를 결합한 아키텍처입니다. 각 구성요소는 서로 잘 작동하도록 신중하게 통합되어 성능, 비용, 개발자 생산성을 개선합니다.
발표된 최신 소식 확인(2026년 4월): Google AI 인프라의 다음 단계: 에이전트 시대에 따른 확장
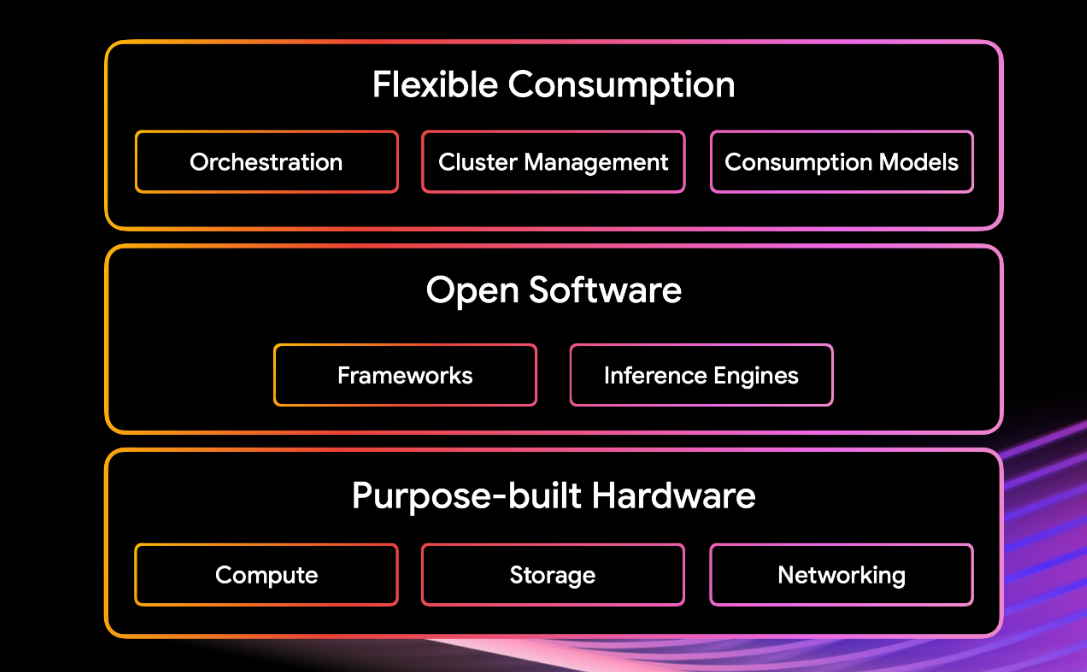
더 스마트하고 빠른 학습
더 스마트하고 빠른 학습
몇 달이 아닌 몇 주 만에 모델을 빌드하세요. Google의 학습 스택을 사용하여 성능 저하 없이 개발 및 테스트 속도를 높이세요.

LLM을 더 빠르게 학습시키고 조정
TPU 8t와 Google DeepMind와 공동 설계하고 Pathways부터 Pallas(학습), Ray부터 Agent Sandbox(튜닝)에 이르는 오픈소스 프레임워크와 통합된 소프트웨어를 함께 사용하면 대규모 언어 모델을 36% 더 빠르게 개발하고 모든 가속기에서 최대 97%의 생산성(Goodput)을 확보할 수 있습니다. 또한 모든 고객에게 동일한 솔루션이 적합하지 않다는 점을 잘 알고 있으므로 NVIDIA와 긴밀히 협력하여 최신 GPU를 제공하고 있습니다. Google Cloud는 올해 말에 차세대 NVIDIA Vera Rubin NVL72를 기반으로 한 인스턴스를 최초로 제공하는 기업 중 하나가 될 것입니다.
독점 데이터를 사용하여 경량 모델을 더 스마트하게 학습
BigQuery와 함께 Gemini Enterprise Agent Platform을 사용하면 데이터 자산, ML 개발, 가속기를 한곳에 결합하여 독점 데이터에 대한 모델을 16배 더 빠르게 학습시킬 수 있습니다. G4 VM을 사용하든 Ironwood TPU를 사용하든 AI 하이퍼컴퓨터로 구동됩니다.
MuJoCo-Warp로 적응형 물리 에이전트 빌드
DeepMind의 MuJoCo-Warp에서 GPU 기반 시뮬레이션을 실행하면 표준 MuJoCo보다 최대 100배 더 빠릅니다. 그런 다음 Veo, Genie, Nano Banana의 합성 미디어를 사용해 불가능하거나 위험하거나 비용이 많이 드는 에지 케이스를 시뮬레이션하거나 BigQuery에서 페타바이트 규모의 실제 센서 데이터를 수집합니다. Google Cloud에서 물리적 에이전트를 빌드하는 방법을 여기에서 자세히 알아보세요.
반응형의 효율적인 추론
반응형의 효율적인 추론
검증된 모델 프로필과 완전 통합된 Google 및 개방형 소프트웨어를 활용하여 복잡성과 낭비를 줄이면서 애플리케이션 응답성을 높일 수 있습니다.
지연 시간이 거의 없는 LLM 서빙
통합된 추론 기술을 사용하여 고객에게 유용하고 반응성이 뛰어난 서비스를 제공합니다. GKE Inference Gateway를 사용하면 첫 번째 토큰까지의 시간을 71% 단축할 수 있고, 분할 서빙을 위해 llm-d를 사용하면 초당 최대 12만 개의 토큰을 서빙할 수 있으며, Anywhere Cache와 TPU 8i를 사용하면 모델을 5배 더 빠르게 로드하여 작업 메모리를 필요한 곳에 정확히 유지할 수 있습니다.
사전 빌드된 시각, 인식, 미디어 모델 제공
올해 말에 출시될 예정인 A5X VM(NVIDIA Vera Rubin) 및 TPU 8i를 포함하여 원하는 TPU 또는 GPU를 사용하여 Gemini Enterprise Agent Platform에서 제공되는 200개 이상의 모델 중 하나를 사용하면 기존 ML 모델을 70% 더 빠르게 배포할 수 있습니다.
안전하고 비용 효율적으로 에이전트 제공
GKE 에이전트 샌드박스에서 수많은 에이전트를 안전하게 제공하고, 필요에 따라 즉시 일시중지 및 재개하면서 초당 최대 300개의 샌드박스를 프로비저닝하므로 유휴 상태인 에이전트에 대한 비용을 지불할 필요가 없습니다.
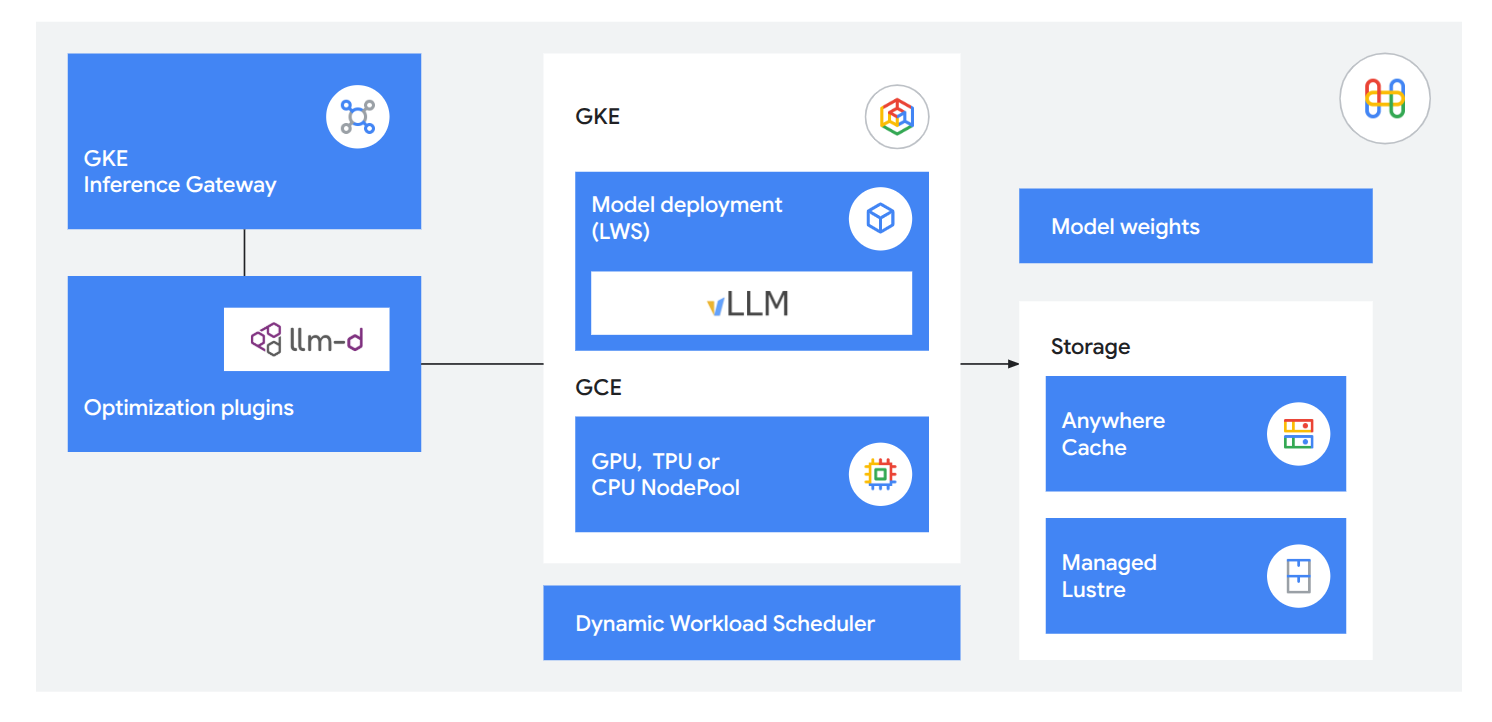
유연하고 개방적이며 안정적인 운영
유연하고 개방적이며 안정적인 운영
엑사스케일에 적합한 자동화된 클러스터 유지보수 및 관리를 통해 하이브리드 및 멀티 클라우드 환경 전반에서 프레임워크 또는 가속기를 사용할 수 있습니다.

코드를 다시 작성하지 않고 TPU와 GPU 간 전환
TorchTPU는 네이티브 PyTorch 지원을 제공하여 개발자의 TPU 학습 곡선을 없애므로 복잡한 코드 재작성 없이도 사용 가능한 최고의 가속기를 사용할 수 있습니다.
거의 모든 규모의 모든 환경에 AI 배포
오픈소스 Kubernetes를 기반으로 하는 GKE는 최대 130,000개의 노드를 지원하는 엔터프라이즈 규모의 멀티 클라우드 이식성을 제공하며, 하이브리드 배포를 위해 Agent Platform 및 Google Distributed Cloud와 기본적으로 통합됩니다.
고급 클러스터 진단 및 모니터링 가능성 도구로 클러스터 유지보수 자동화
AI 하이퍼컴퓨터의 모든 가속기는 Cluster Director 기능을 통해 지원되며, 여기에는 사전 배포 상태 점검, 360도 모니터링 가능성 대시보드, 상시 가동 상태 점검이 포함됩니다.
몇 주가 아닌 몇 분 만에 멀티 클라우드 워크로드 연결
매달 27엑사바이트 이상의 데이터를 이동하는 Fortune 100대 기업의 65% 이상이 신뢰하는 네트워킹 백본인 크로스 클라우드 네트워크를 사용하면 지연 없는 연결로 클라우드 전반의 서비스를 연결할 수 있습니다.
원하는 방식으로 가속기 용량 확보
Google Cloud의 유연한 소비 모델을 사용하면 다양한 방식으로 가속기 비용을 절감하고 일정을 예약할 수 있습니다. 스팟 VM을 사용하면 일괄 작업 또는 내결함성 작업의 비용을 최대 91% 절감할 수 있고, 동적 워크로드 스케줄러를 사용하면 시작 날짜가 유동적인 작업의 비용을 최대 50% 절감할 수 있으며, 약정 사용 할인에 가입하면 비용을 최대 50% 절감할 수 있습니다.
에이전트 지원 시스템
에이전트 지원 시스템
Google과 선도적인 AI 연구소에서 신뢰하는 인프라 기반을 통해 확장하면서 성능의 한계를 뛰어넘고 에너지를 책임감 있게 사용하세요.
신뢰할 수 있는 기반에서 AI 로드맵의 위험을 줄이세요
Google Cloud는 상위 10개 AI 연구소 중 9곳과 자금 지원을 받는 AI 스타트업의 70%를 지원합니다. AI 하이퍼컴퓨터에 배포하면 2025년 12월 한 달 동안에만 350명에 가까운 고객을 위해 1,000억 개 이상의 토큰을 안정적으로 처리한 데이터 센터를 사용하게 됩니다.
업계 최고의 에너지 효율성 달성
AI 하이퍼컴퓨터를 포함한 Google Cloud의 데이터 센터는 5년 전보다 단위 전력당 6배 더 많은 컴퓨팅 성능을 제공하여 업계 최고 수준의 에너지 효율성을 실현합니다. 이를 통해 8세대 TPU는 이전 세대보다 80% 더 나은 가격 대비 성능과 20% 더 높은 에너지 효율성을 제공할 수 있습니다.
전력망과 지역 사회에 미치는 영향 감소
실리콘부터 에지까지 가장 가치 있는 IP 보호
Google Cloud의 Titanium 아키텍처의 커스텀 Titan 칩은 검증 가능한 신뢰할 수 있는 하드웨어 루트와 제로 트러스트 보안을 제공합니다. cloudvulndb.org의 독립적인 분석에 따르면 Google Cloud 시스템은 다른 주요 클라우드보다 심각한 취약점이 최대 70% 적습니다.
세계 최고의 혁신 기업을 지원합니다










AI 하이퍼컴퓨터에 대해 자세히 알아보기
- IDC: AI 하이퍼컴퓨터의 비즈니스 가치이 IDC 보고서는 AI 워크로드에 대한 AI 하이퍼컴퓨터의 실제 고객 영향을 살펴봅니다. 전체 보고서를 읽고 ROI 353% 개선, IT팀 효율성 55% 향상, 애플리케이션/워크로드 계획되지 않은 다운타임 67% 감소를 보여주는 고객 데이터를 확인하세요.
전문 길이: 5분
보고서 읽기 - Google, Gartner® Magic Quadrant의 전략적 클라우드 플랫폼 서비스 부문에서 리더로 선정Gartner®는 8년 연속으로 Google을 Gartner Magic Quadrant™의 전략적 클라우드 플랫폼 서비스 부문 리더로 선정했습니다. 하지만 올해는 중요한 이정표가 되는 해입니다. Google은 이제 비전의 완성도 면에서 가장 선도적인 기업으로 평가받은 것입니다.
전문 길이: 5분
결과 확인 - Google, The Forrester Wave™: 2025년 4분기 AI 인프라 솔루션에서 리더로 선정Google은 현재 제품 카테고리에서 모든 공급업체 중 가장 높은 점수를 받았으며 비전, 아키텍처, 학습, 추론, 효율성, 보안 등을 포함하되 이에 국한되지 않고 19개 평가 기준 중 16개에서 최고 점수를 받았습니다.
전문 길이: 5분
결과 확인
- 첫 번째 추론 스택 설계 및 배포GKE, Cloud TPU, TensorFlow, PyTorch, JAX, Keras 등 Google Cloud에서 추론 솔루션을 구성하는 필수 구성요소를 알아보세요.
2시간 과정
과정 수강하기 - GKE에서 vLLM을 사용하여 Gemma 3 27B 추론 서빙이 튜토리얼에서는 vLLM 서빙 프레임워크를 사용하여 Gemma 3 27B 대규모 언어 모델(LLM)을 배포하고 서빙하는 방법을 보여줍니다. Google Kubernetes Engine(GKE)의 단일 A4 가상 머신(VM) 인스턴스에 Gemma 3을 배포합니다.
15분 가이드
튜토리얼 보기 - A4 GKE 클러스터에서 Gemma 3 파인 튜닝이 튜토리얼에서는 Google Cloud의 멀티 노드, 멀티 GPU GKE 클러스터에서 Gemma 3 대규모 언어 모델(LLM)을 파인 튜닝하는 방법을 보여줍니다. 이 클러스터는 8개의 NVIDIA B200 GPU가 있는 A4 가상 머신(VM) 인스턴스를 사용합니다.
15분 가이드
튜토리얼 보기
- A4 Slurm 클러스터에서 Qwen2 학습이 튜토리얼에서는 Google Cloud의 멀티 노드, 멀티 GPU Slurm 클러스터에서 대규모 언어 모델(LLM)을 학습시키는 방법을 보여줍니다. 이 튜토리얼에서 사용하는 모델은 Qwen2 15억 파라미터 모델을 기반으로 합니다. Slurm 클러스터는 각각 8개의 NVIDIA B200 GPU를 갖춘 2개의 a4-highgpu-8g 가상 머신(VM)을 사용합니다.
15분 가이드
튜토리얼 보기 - TPU에서 vLLM으로 Qwen2-7B-Instruct 서빙이 튜토리얼에서는 v6e TPU VM에서 vLLM TPU 서빙 프레임워크를 사용하여 Qwen/Qwen2-7B-Instruct 모델을 서빙합니다.
15분 가이드
튜토리얼 보기
분석가 인사이트
- IDC: AI 하이퍼컴퓨터의 비즈니스 가치이 IDC 보고서는 AI 워크로드에 대한 AI 하이퍼컴퓨터의 실제 고객 영향을 살펴봅니다. 전체 보고서를 읽고 ROI 353% 개선, IT팀 효율성 55% 향상, 애플리케이션/워크로드 계획되지 않은 다운타임 67% 감소를 보여주는 고객 데이터를 확인하세요.
전문 길이: 5분
보고서 읽기 - Google, Gartner® Magic Quadrant의 전략적 클라우드 플랫폼 서비스 부문에서 리더로 선정Gartner®는 8년 연속으로 Google을 Gartner Magic Quadrant™의 전략적 클라우드 플랫폼 서비스 부문 리더로 선정했습니다. 하지만 올해는 중요한 이정표가 되는 해입니다. Google은 이제 비전의 완성도 면에서 가장 선도적인 기업으로 평가받은 것입니다.
전문 길이: 5분
결과 확인 - Google, The Forrester Wave™: 2025년 4분기 AI 인프라 솔루션에서 리더로 선정Google은 현재 제품 카테고리에서 모든 공급업체 중 가장 높은 점수를 받았으며 비전, 아키텍처, 학습, 추론, 효율성, 보안 등을 포함하되 이에 국한되지 않고 19개 평가 기준 중 16개에서 최고 점수를 받았습니다.
전문 길이: 5분
결과 확인
튜토리얼
- 첫 번째 추론 스택 설계 및 배포GKE, Cloud TPU, TensorFlow, PyTorch, JAX, Keras 등 Google Cloud에서 추론 솔루션을 구성하는 필수 구성요소를 알아보세요.
2시간 과정
과정 수강하기 - GKE에서 vLLM을 사용하여 Gemma 3 27B 추론 서빙이 튜토리얼에서는 vLLM 서빙 프레임워크를 사용하여 Gemma 3 27B 대규모 언어 모델(LLM)을 배포하고 서빙하는 방법을 보여줍니다. Google Kubernetes Engine(GKE)의 단일 A4 가상 머신(VM) 인스턴스에 Gemma 3을 배포합니다.
15분 가이드
튜토리얼 보기 - A4 GKE 클러스터에서 Gemma 3 파인 튜닝이 튜토리얼에서는 Google Cloud의 멀티 노드, 멀티 GPU GKE 클러스터에서 Gemma 3 대규모 언어 모델(LLM)을 파인 튜닝하는 방법을 보여줍니다. 이 클러스터는 8개의 NVIDIA B200 GPU가 있는 A4 가상 머신(VM) 인스턴스를 사용합니다.
15분 가이드
튜토리얼 보기
- A4 Slurm 클러스터에서 Qwen2 학습이 튜토리얼에서는 Google Cloud의 멀티 노드, 멀티 GPU Slurm 클러스터에서 대규모 언어 모델(LLM)을 학습시키는 방법을 보여줍니다. 이 튜토리얼에서 사용하는 모델은 Qwen2 15억 파라미터 모델을 기반으로 합니다. Slurm 클러스터는 각각 8개의 NVIDIA B200 GPU를 갖춘 2개의 a4-highgpu-8g 가상 머신(VM)을 사용합니다.
15분 가이드
튜토리얼 보기 - TPU에서 vLLM으로 Qwen2-7B-Instruct 서빙이 튜토리얼에서는 v6e TPU VM에서 vLLM TPU 서빙 프레임워크를 사용하여 Qwen/Qwen2-7B-Instruct 모델을 서빙합니다.
15분 가이드
튜토리얼 보기












