このページでは、Query Insights ダッシュボードを使用してクエリのパフォーマンスの問題を検出、分析する方法について説明します。
はじめに
Query Insights では、Cloud SQL データベースに対するクエリ パフォーマンスの問題を検出、診断、防止できます。直感的なモニタリングをサポートし、検出するだけでなくパフォーマンスの問題の根本原因の特定に役立つ診断情報を提供します。
Query Insights では、アプリケーション レベルでパフォーマンスをモニタリングでき、モデル、ビュー、コントローラ、ルート、ユーザー、ホストによるアプリケーション スタック全体で、問題のあるクエリの元をトレースできます。Query Insights ツールは、オープン標準と API を使用して、既存のアプリケーション モニタリング(APM)ツールや Google Cloudサービスと統合できます。これにより、お好みのツールを使用してクエリの問題をモニタリングし、トラブルシューティングできます。
Query Insights では、次の手順を行い、Cloud SQL クエリのパフォーマンスを向上させることができます。
Cloud SQL Enterprise Plus エディションの Query Insights
Cloud SQL Enterprise Plus エディションを使用している場合は、Query Insights の追加機能にアクセスして、高度なクエリ パフォーマンス診断を実行できます。Cloud SQL Enterprise Plus エディションの Query Insights では、Query Insights ダッシュボードの標準機能に加えて、次のことができます。
- 実行されたすべてのクエリの待機イベントをキャプチャして分析する。
- 集計されたデータベースの負荷を、クエリ、タグ、待機イベントのタイプなどの追加項目でフィルタリングする。
- 実行されたすべてのクエリのクエリプランをキャプチャする。
- 1 分あたり最大 200 件のクエリプランをサンプリングする。
- 最大 100 KB の長いクエリテキストをキャプチャする。
- 指標の準リアルタイムの更新を取得する(数秒単位)。
- 指標の保持期間を 30 日間に延長する。
- インデックス アドバイザーからインデックスの推奨事項を取得する。
- アクティブなクエリでセッションまたは長時間実行トランザクションを終了する。
- AI を活用したトラブルシューティング(プレビュー版)にアクセスする。
次の表は、Cloud SQL Enterprise エディションの Query Insights と Cloud SQL Enterprise Plus エディションの Query Insights の機能要件と機能を比較したものです。
| 比較領域 | Cloud SQL Enterprise エディションの Query Insights | Cloud SQL Enterprise Plus エディションの Query Insights |
|---|---|---|
| サポートされているデータベース バージョン | PostgreSQL 9.6 以降 | PostgreSQL 12 以降 |
| サポートされているマシンタイプ | すべてのマシンタイプでサポート | 共有コア マシンタイプを使用するインスタンスまたはリードレプリカ インスタンスではサポートされていません。 |
| サポートされるリージョン | Cloud SQL のリージョン ロケーション | Cloud SQL Enterprise Plus エディションのリージョン ロケーション |
| 指標の保持期間 | 7 日間 | 30 日間 |
| クエリの長さの上限 | 4,500 バイト | 100 KB |
| クエリプランのサンプルの最大数 | 20 | 200 |
| 待機イベント分析 | 利用不可 | 利用可能 |
| インデックス アドバイザーの推奨事項 | 利用不可 | 利用可能 |
| アクティブなクエリでセッションまたは長時間実行トランザクションを終了する | 利用不可 | 利用可能 |
| AI によるトラブルシューティング(プレビュー版) | 利用不可 | 利用可能 |
Cloud SQL Enterprise Plus エディションで Query Insights を有効にする
Cloud SQL Enterprise Plus エディションの Query Insights を有効にするには、Cloud SQL Enterprise Plus エディション インスタンスで Query Insights を有効にするときに [Enterprise Plus の機能を有効にする] を選択します。
料金
Cloud SQL Enterprise エディションまたは Cloud SQL Enterprise Plus エディションのインスタンスでは、Query Insights に追加料金は発生しません。
ストレージ要件
Cloud SQL Enterprise エディションの Query Insights は、Cloud SQL インスタンスの保存容量を占有しません。指標は Cloud Monitoring に保存されます。API リクエストについては、Cloud Monitoring の料金をご覧ください。Cloud Monitoring には、追加費用なしで使用できる枠が用意されています。
Cloud SQL Enterprise Plus エディションの Query Insights は、Cloud SQL インスタンスにアタッチされているディスクに指標データを保存します。そのため、ストレージの自動増量の設定を有効にしておく必要があります。
7 日間分のデータのストレージ要件は約 36 GB です。30 日間の場合は約 155 GB が必要です。Cloud SQL Enterprise Plus エディションの Query Insights は、最大 10 MB の RAM(共有メモリ)を使用します。指標は、クエリの完了から 30 秒以内に Query Insights で利用できるようになると想定されています。該当するストレージ料金が適用されます。制限事項
Cloud SQL Enterprise Plus エディション インスタンスの Query Insights には、次の制限が適用されます。
- インスタンスでシステムの負荷が高い場合、[Query Insights] ダッシュボードで指標データをクエリすると、クエリの読み込みが遅くなったり、タイムアウトしたりすることがあります。
- 古いバックアップを使用してインスタンスを復元すると、Cloud SQL Enterprise Plus エディションの Query Insights で、バックアップの時点からインスタンスを復元した時点までの指標が失われる可能性があります。たとえば、4 月 25 日に取得したバックアップを使用して 4 月 30 日にインスタンスを復元すると、4 月 25 日から 4 月 30 日までのすべての指標が失われる可能性があります。
- インスタンスで PostgreSQL 18 が使用されており、クエリの SQL ステートメントの先頭にコメントタグがある場合、クエリ分析情報を使用すると、アプリケーション タグが保存されないことがあります。この制限は、Cloud SQL Enterprise Plus エディションと Cloud SQL Enterprise エディションのインスタンスに適用されます。
始める前に
Query Insights を使用する前に、次の操作を行います。
- 必要なロールと権限を追加する。
- Cloud Trace API を有効にする。
- Cloud SQL Enterprise Plus エディションの Query Insights を使用している場合は、[ストレージの自動増量を有効にする] がインスタンスで有効になっていることを確認する。
必要なロールと権限
Query Insights ダッシュボードで過去のクエリ実行データにアクセスするために必要な権限を取得するには、Cloud SQL インスタンスをホストするプロジェクトに対する次の IAM ロールを付与するよう管理者に依頼してください。
-
データベース分析情報のモニタリング閲覧者(
roles/databaseinsights.monitoringViewer) -
Cloud SQL 閲覧者(
roles/cloudsql.viewer)
ロールの付与については、プロジェクト、フォルダ、組織へのアクセス権の管理をご覧ください。
必要な権限は、カスタムロールや他の事前定義ロールから取得することもできます。
Cloud Trace API を有効にする
クエリプランとそのエンドツーエンドのビューを表示するには、 Google Cloud プロジェクトで Cloud Trace API を有効にする必要があります。この設定により、Google Cloud プロジェクトは認証済みのソースからトレースデータを追加料金なしで受信できます。このデータは、インスタンスのパフォーマンスの問題を検出して診断する際に役立ちます。
Cloud Trace API が有効になっていることを確認する手順は、次のとおりです。
- Google Cloud コンソールから [API とサービス] に移動します。
- [有効な API とサービス] をクリックします。
- 検索バーに「
Cloud Trace API」と入力します。 - [API が有効です] と表示されている場合、この API は有効になっており、操作は不要です。それ以外の場合は、[有効にする] をクリックします。
ストレージの自動増量を有効にする
Cloud SQL Enterprise Plus エディションの Query Insights を使用している場合は、ストレージの自動増量を有効にするインスタンス設定が有効になっていることを確認してください。デフォルトでは、Cloud SQL インスタンスでこのオプションが有効になっています。
以前にこのインスタンス設定を無効にした場合、Cloud SQL Enterprise Plus エディションの Query Insights を有効にするには、まずストレージの自動増量を再度有効にしてください。ストレージの自動増量をオフにして Cloud SQL Enterprise Plus エディションの Query Insights を有効にすることはできません。
Query Insights を有効にする
Query Insights を有効にすると、他のすべてのオペレーションが一時停止します。これらのオペレーションには、ヘルスチェック、ロギング、モニタリング、その他のインスタンス オペレーションが含まれます。
コンソール
インスタンスで Query Insights を有効にする
-
Google Cloud コンソールで、Cloud SQL の [インスタンス] ページに移動します。
- インスタンスの [概要] ページを開くには、インスタンス名をクリックします。
- [構成] タイルで、[構成の編集] をクリックします。
- [インスタンスのカスタマイズ] で [Query Insights] を開きます。
- [Query Insights を有効にする] チェックボックスを選択します。
- 省略可: インスタンスの追加機能を選択します。一部の機能は、Cloud SQL Enterprise Plus エディションでのみ使用できます。
- [保存] をクリックします。
| 機能 | 説明 | Cloud SQL Enterprise エディション | Cloud SQL Enterprise Plus エディション |
|---|---|---|---|
| Enterprise Plus の機能を有効にする | このチェックボックスをオンにすると、Cloud SQL で Cloud SQL Enterprise Plus エディションの Query Insights が有効になります。Cloud SQL Enterprise Plus エディションの Query Insights を使用すると、アクティブなクエリでセッションと長時間実行トランザクションを終了し、指標データの保持期間を 30 日に延長できます。AI を活用したトラブルシューティング(プレビュー)を有効にするには、このチェックボックスをオンにする必要があります。 | 利用不可 | 利用可能
デフォルト: 無効 |
| アクティブ クエリ分析 | アクティブに実行されているクエリの詳細を確認できます。Cloud SQL Enterprise Plus エディションで有効になっている場合は、セッションと長時間実行トランザクションを終了することもできます。Cloud SQL for PostgreSQL インスタンスでアクティブ クエリを有効にするには、このチェックボックスをオンにします。詳細については、アクティブなクエリをモニタリングするをご覧ください。 | 利用可能
デフォルト: 無効 |
利用可能
デフォルト: 無効 |
| インデックス アドバイザーの推奨事項 | クエリ処理を高速化するためのインデックスの推奨事項を提供します。詳細については、インデックス アドバイザーを使用するをご覧ください。インデックス アドバイザーを有効にすると、インスタンスを再起動する必要があります。インデックス アドバイザーを無効にしても、再起動は必要ありません。 | 利用不可 | 利用可能 デフォルト: 無効 |
| AI を活用したトラブルシューティング | このチェックボックスをオンにすると、パフォーマンスの異常検出と、根本原因と状況の分析が有効になり、クエリとデータベースの問題を修正するための推奨事項を取得できます。この機能はプレビュー版です。この機能を有効にしてアクセスするには、 Google Cloud コンソールを使用する必要があります。詳細については、AI アシスタンスによる観察とトラブルシューティングをご覧ください。 | 利用不可 | 利用可能
デフォルト: 無効 |
| クライアント IP アドレスを保存する | クライアント IP アドレスの保存を有効にするには、このチェックボックスをオンにします。Cloud SQL では、クエリの送信元の IP アドレスを保存し、そのデータをグループ化して指標を実行できます。クエリは複数のホストから送信されます。クライアント IP アドレスからのクエリのグラフを確認すると、問題の原因を特定しやすくなります。 | 利用可能
デフォルト: 無効 |
利用可能
デフォルト: 無効 |
| アプリケーション タグを保存 | アプリケーション タグ ストレージを有効にするには、このチェックボックスをオンにします。アプリケーション タグを保存すると、リクエストを行っている API とモデル ビュー コントローラ(MVC)のルートを特定し、データをグループ化して指標を実行できます。このオプションでは、sqlcommenter オープンソースのオブジェクト リレーショナル マッピング(ORM)自動計測ライブラリを使用して、特定のタグセットを含むクエリをコメント化する必要があります。この情報により、Query Insights が問題の原因および問題の原因となっている MVC を特定できます。アプリケーション パスは、アプリケーションのモニタリングに役立ちます。 | 利用可能
デフォルト: 無効 |
利用可能
デフォルト: 無効 |
| クエリの長さをカスタマイズする |
クエリ文字列の長さの上限をカスタマイズするには、このチェックボックスをオンにします。分析クエリの場合はより長いほうが便利ですが、必要なメモリ量が増えます。指定された上限を超えるクエリ文字列は、表示時に切り捨てられます。 クエリ長の上限を変更するには、インスタンスを再起動する必要があります。 長さの上限を超えるクエリにもタグを追加できます。 |
バイト単位の上限は 256~4500 バイトに設定できます。デフォルト: 1024
|
バイト単位の上限は 1024~100000 に指定できます。
デフォルト: 10000 バイト。
|
| 最大サンプリング レートを設定する |
最大サンプリング レートを設定するには、このチェックボックスをオンにします。サンプリング レートとは、インスタンス上のすべてのデータベースで 1 分間にキャプチャされる実行済みクエリプランのサンプル数です。サンプリング レートを上げると、通常は得られるデータポイントの数が増えますが、パフォーマンスのオーバーヘッドが増加する可能性があります。
サンプリングを無効にするには、値を 0 に設定します。 |
この値を 0~20 の数値に変更します。デフォルト: 5
|
最大値を 200 に増やしてデータポイントを増やすこともできます。デフォルト: 200
|
複数のインスタンスで Query Insights を有効にする
-
Google Cloud コンソールで、Cloud SQL の [インスタンス] ページに移動します。
- 任意の行にある [その他の操作] メニューをクリックします。
- [Query Insights を有効にする] を選択します。
- ダイアログで、[複数のインスタンスの Query Insights を有効にする] チェックボックスをオンにします。
- [有効にする] をクリックします。
- 続くダイアログで、Query Insights を有効にするインスタンスを選択します。
- [Query Insights を有効にする] をクリックします。
gcloud
gcloud を使用して Cloud SQL インスタンスの Query Insights を有効にするには、次のように --insights-config-query-insights-enabled フラグを指定して gcloud sql instances patch を実行します。実行する前に INSTANCE_ID をインスタンスの ID に置き換えてください。
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled
また、次のオプション フラグを 1 つ以上使用します。
--insights-config-record-client-addressクエリの送信元であるクライアント IP アドレスを保存します。これにより、そのデータをグループ化して、そのデータに対して指標を実行できます。クエリは複数のホストから送信されます。クライアント IP アドレスからのクエリのグラフを確認すると、問題の原因を特定しやすくなります。
--insights-config-record-application-tagsアプリケーション タグを保存します。このタグは、リクエストを行っている API とモデル ビュー コントローラ(MVC)のルート決定や、指標を実行するためのデータのグループ化に役立ちます。このオプションでは、特定のタグセットを使用してクエリにコメントする必要があります。これを行うには、sqlcommenter オープンソース オブジェクト リレーショナル マッピング(ORM)自動計測ライブラリを使用します。この情報は、Query Insights で問題の原因を特定する際に役立ちます。また、問題の原因となっている MVC も把握できます。アプリケーション パスは、アプリケーションのモニタリングに役立ちます。
--insights-config-query-string-lengthデフォルトのクエリ長の上限を設定します。分析クエリの場合はより長いほうが便利ですが、必要なメモリ量が増えます。クエリ長を変更するには、インスタンスを再起動する必要があります。 長さの上限を超えるクエリにもタグを追加できます。 Cloud SQL Enterprise エディションの場合、バイト単位の値を
256~4500に指定できます。デフォルトのクエリ長は1024バイトです。Cloud SQL Enterprise Plus エディションの場合、バイト単位の上限を1024~100000に指定できます。デフォルト値は10000バイトです。--insights-config-query-plans-per-minuteインスタンス上のすべてのデータベースで、実行されるクエリプランのサンプルがデフォルトで 1 分間に最大 5 回キャプチャされます。サンプリング レートを上げると、通常は得られるデータポイントの数が増えますが、パフォーマンスのオーバーヘッドが増加する可能性があります。サンプリングを無効にするには、この値を
0に設定します。Cloud SQL Enterprise エディションの場合、この値は 0~20 に変更できます。Cloud SQL Enterprise Plus エディションの場合、最大値を 200 まで増やして、より多くのデータポイントを提供できます。 デフォルトでは、インスタンス上のすべてのデータベースで、最大サンプリング レートは 1 分あたり200個のクエリプラン サンプルです。
次のように置き換えます。
- INSIGHTS_CONFIG_QUERY_STRING_LENGTH: 格納されるクエリ文字列の長さ(バイト単位)。
- API_TIER_STRING: インスタンスに使用するカスタム インスタンス構成。
- REGION: インスタンスのリージョン。
gcloud sql instances patch INSTANCE_ID \ --insights-config-query-insights-enabled \ --insights-config-query-string-length=INSIGHTS_CONFIG_QUERY_STRING_LENGTH \ --insights-config-query-plans-per-minute=QUERY_PLANS_PER_MINUTE \ --insights-config-record-application-tags \ --insights-config-record-client-address \ --tier=API_TIER_STRING \ --region=REGION
REST v1
REST API を使用して Cloud SQL インスタンスの Query Insights を有効にするには、insightsConfig 設定で instances.patch メソッドを呼び出します。
リクエストのデータを使用する前に、次のように置き換えます。
- PROJECT_ID: プロジェクト ID
- INSTANCE_ID: インスタンス ID
HTTP メソッドと URL:
PATCH https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_ID
リクエストの本文(JSON):
{
"settings" : {
"insightsConfig" : {
"queryInsightsEnabled" : true,
"recordClientAddress" : true,
"recordApplicationTags" : true,
"queryStringLength" : 1024,
"queryPlansPerMinute" : 20,
}
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/instances/INSTANCE_ID",
"status": "PENDING",
"user": "user@example.com",
"insertTime": "2025-03-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "OPERATION_ID",
"targetId": "INSTANCE_ID",
"selfLink": "https://sqladmin.googleapis.com/v1/projects/PROJECT_ID/operations/OPERATION_ID",
"targetProject": "PROJECT_ID"
}
Terraform
Terraform を使用して Cloud SQL インスタンスの Query Insights を有効にするには、query_insights_enabled フラグを true に設定します。
また、次のオプション フラグを 1 つ以上使用することもできます。
query_string_length: Cloud SQL Enterprise エディションの場合、バイト単位の値を256~4500に指定できます。デフォルトのクエリ長は1024バイトです。Cloud SQL Enterprise Plus エディションの場合、バイト単位の上限を1024~100000に指定できます。 デフォルト値は10000バイトです。record_application_tags: クエリからアプリケーション タグを記録する場合は、値をtrueに設定します。record_client_address: クライアント IP アドレスを記録する場合は、値をtrueに設定します。デフォルトはfalseです。-
query_plans_per_minute: Cloud SQL Enterprise エディションの場合、値を0~20に設定できます。デフォルトは5です。 Cloud SQL Enterprise Plus エディションの場合、最大値を200まで増やして、より多くのデータポイントを提供できます。 デフォルトでは、インスタンス上のすべてのデータベースで、最大サンプリング レートは 1 分あたり200個のクエリプラン サンプルです。
次に例を示します。
resource "google_sql_database_instance" "INSTANCE_NAME" { name = "INSTANCE_NAME" database_version = "POSTGRESQL_VERSION" region = "REGION" root_password = "PASSWORD" deletion_protection = false # set to true to prevent destruction of the resource settings { tier = "DB_TIER" insights_config { query_insights_enabled = true query_string_length = 2048 # Optional record_application_tags = true # Optional record_client_address = true # Optional query_plans_per_minute = 10 # Optional } } }
Google Cloud プロジェクトで Terraform 構成を適用するには、次のセクションの手順を完了します。
Cloud Shell を準備する
- Cloud Shell を起動します。
-
Terraform 構成を適用するデフォルトの Google Cloud プロジェクトを設定します。
このコマンドは、プロジェクトごとに 1 回だけ実行する必要があります。これは任意のディレクトリで実行できます。
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
Terraform 構成ファイルに明示的な値を設定すると、環境変数がオーバーライドされます。
ディレクトリを準備する
Terraform 構成ファイルには独自のディレクトリ(ルート モジュールとも呼ばれます)が必要です。
-
Cloud Shell で、ディレクトリを作成し、そのディレクトリ内に新しいファイルを作成します。ファイルの拡張子は
.tfにする必要があります(例:main.tf)。このチュートリアルでは、このファイルをmain.tfとします。mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
チュートリアルを使用している場合は、各セクションまたはステップのサンプルコードをコピーできます。
新しく作成した
main.tfにサンプルコードをコピーします。必要に応じて、GitHub からコードをコピーします。Terraform スニペットがエンドツーエンドのソリューションの一部である場合は、この方法をおすすめします。
- 環境に適用するサンプル パラメータを確認し、変更します。
- 変更を保存します。
-
Terraform を初期化します。これは、ディレクトリごとに 1 回だけ行います。
terraform init
最新バージョンの Google プロバイダを使用する場合は、
-upgradeオプションを使用します。terraform init -upgrade
変更を適用する
-
構成を確認して、Terraform が作成または更新するリソースが想定どおりであることを確認します。
terraform plan
必要に応じて構成を修正します。
-
次のコマンドを実行します。プロンプトで「
yes」と入力して、Terraform 構成を適用します。terraform apply
Terraform に「Apply complete!」というメッセージが表示されるまで待ちます。
- Google Cloud プロジェクトを開いて結果を表示します。 Google Cloud コンソールの UI でリソースに移動して、Terraform によって作成または更新されたことを確認します。
指標は、クエリの完了から数分以内に Query Insights で利用できるようになると想定されています。Cloud Monitoring のデータ保持ポリシーを確認します。
Query Insights のトレースは Cloud Trace に保存されます。Cloud Trace のデータ保持ポリシーを確認します。
Query Insights ダッシュボードを表示する
Query Insights ダッシュボードには、選択された要素に基づいて、クエリ負荷が表示されます。クエリ負荷は、選択された期間内のインスタンス内のすべてのクエリの合計作業量の測定値です。ダッシュボードには、クエリの負荷を確認するための一連のフィルタが用意されています。
Query Insights ダッシュボードを開くには、次の手順を行います。
- インスタンスの [概要] ページを開くには、インスタンス名をクリックします。
- Cloud SQL ナビゲーション メニューで [Query Insights] をクリックするか、[インスタンスの概要] ページで [クエリ分析情報に移動すると、クエリとパフォーマンスに関する詳細情報を確認できます] をクリックします。
Query Insights ダッシュボードが開きます。Cloud SQL Enterprise エディションと Cloud SQL Enterprise Plus エディションのどちらの Query Insights を使用しているかに応じて、Query Insights ダッシュボードにはインスタンスに関する次の情報が表示されます。
Cloud SQL Enterprise Plus エディション
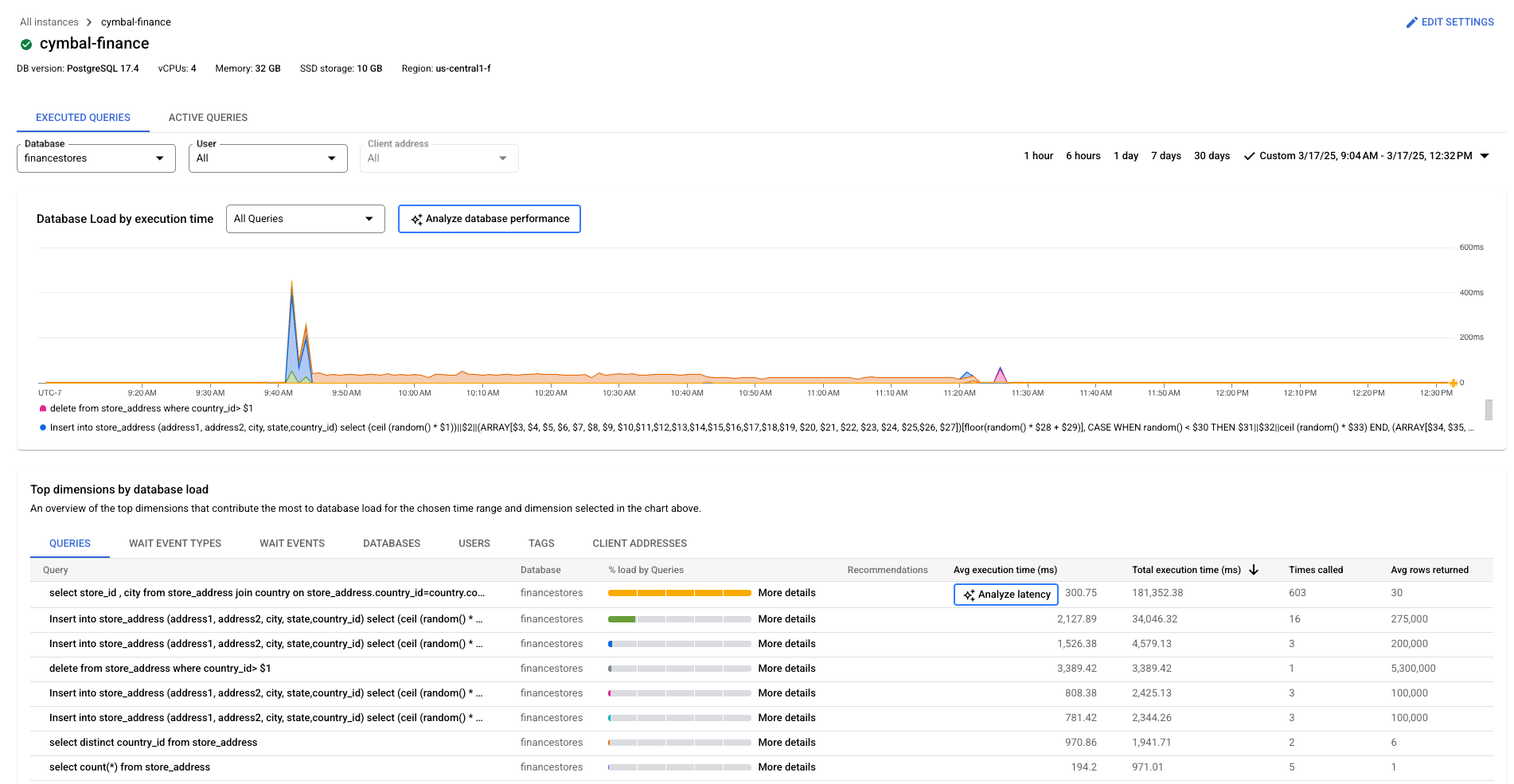
- すべてのクエリ: 選択した期間のすべてのクエリのデータベースの負荷が表示されます。各クエリは個別に色分けされます。特定のクエリの特定の時点を表示するには、クエリのグラフの上にポインタを置きます。
- データベース: 特定またはすべてのデータベースのクエリ負荷がフィルタリングされます。
- ユーザー: 特定のユーザー アカウントからのクエリ負荷をフィルタリングします。
- クライアント アドレス: 特定の IP アドレスからのクエリ負荷をフィルタリングします。
- 期間: 1 時間、6 時間、1 日、7 日、30 日、カスタム範囲など、時間範囲でクエリ負荷をフィルタリングします。
- 待機イベントのタイプ: CPU とロックの待機イベントタイプでクエリの負荷をフィルタリングします。
- クエリ、待機イベントのタイプ、データベース、ユーザー、タグ、クライアント アドレス: データベースの負荷に最も大きく影響している上位の項目をグラフ上で並べ替えます。データベース負荷のフィルタリングをご覧ください。
Cloud SQL Enterprise エディション
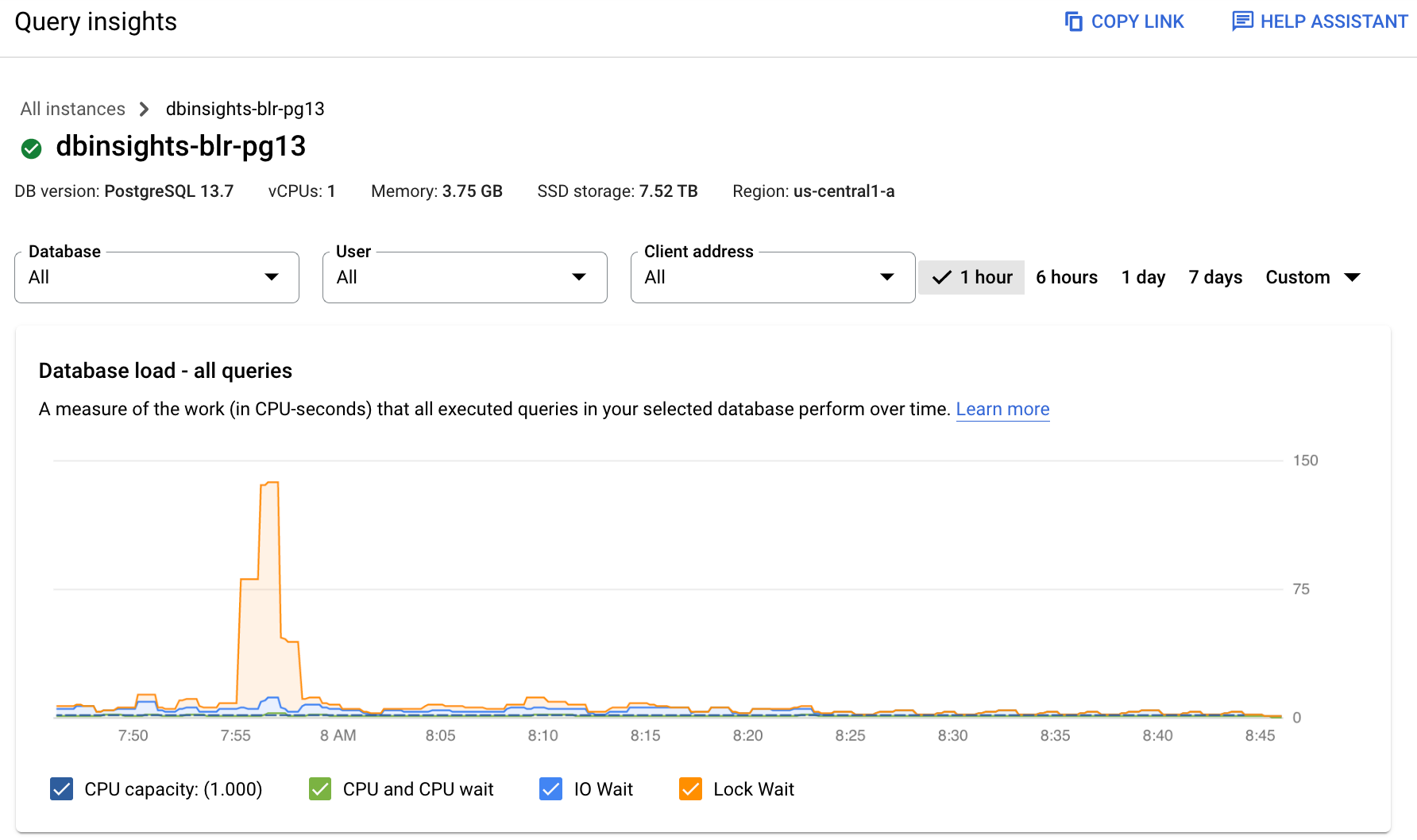
- データベース: 特定またはすべてのデータベースのクエリ負荷がフィルタリングされます。
- ユーザー: 特定のユーザー アカウントからのクエリ負荷をフィルタリングします。
- クライアント アドレス: 特定の IP アドレスからのクエリ負荷をフィルタリングします。
- 期間: 1 時間、6 時間、1 日、7 日、30 日、カスタム範囲など、時間範囲でクエリ負荷をフィルタリングします。
- データベース負荷グラフ: フィルタリングされたデータに基づき、クエリ負荷のグラフを表示します。
- CPU 容量、CPU と CPU 待機、IO 待機、ロック待機: 選択したオプションに基づいて負荷がフィルタリングされます。これらのフィルタの詳細については、上位のクエリのデータベース負荷を表示するをご覧ください。
- クエリとタグ: 選択したクエリまたは選択した SQL クエリタグのいずれかでクエリ負荷をフィルタリングします。データベース負荷のフィルタリングをご覧ください。
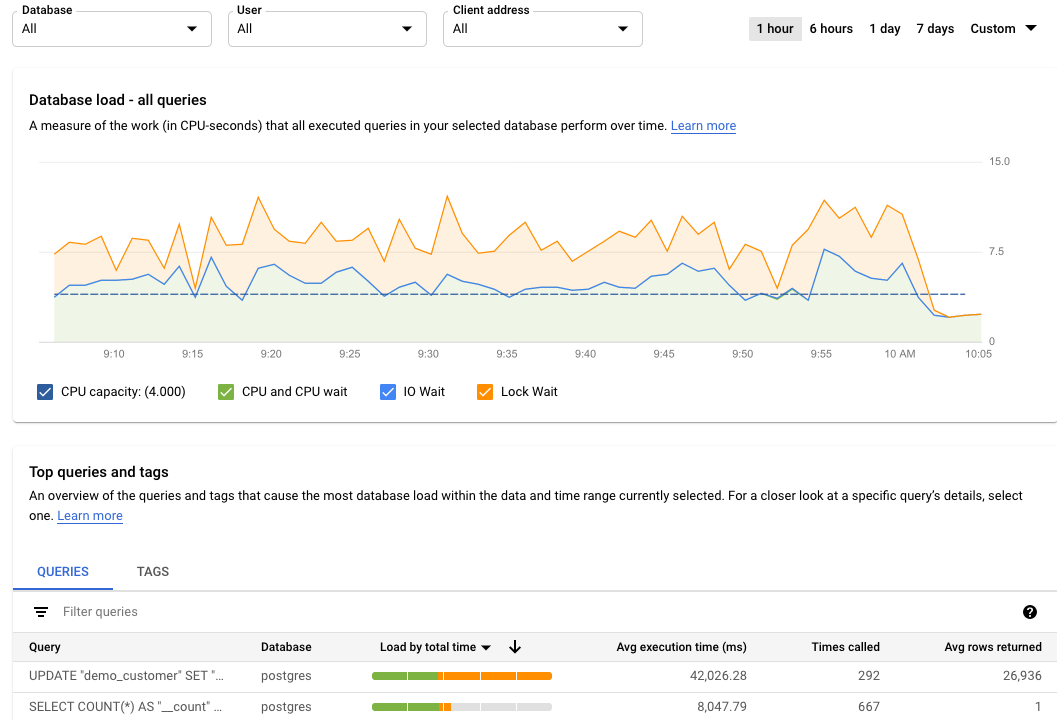
すべてのクエリのデータベース負荷を表示する
データベースのクエリ負荷は、選択したデータベースで実行されたクエリの作業量の経時的な測定結果(CPU 秒単位)です。実行中の各クエリは、CPU リソース、IO リソース、またはロックリソースを使用または待機しています。データベースのクエリ負荷は、実時間に対する、指定の時間枠内で完了したすべてのクエリで要した時間の比率です。
トップレベルの Query Insights ダッシュボードには、[データベース負荷 - すべての上位クエリ] グラフが表示されます。ダッシュボードのプルダウン メニューでは、特定のデータベース、ユーザー、またはクライアント アドレスのグラフがフィルタリングされます。
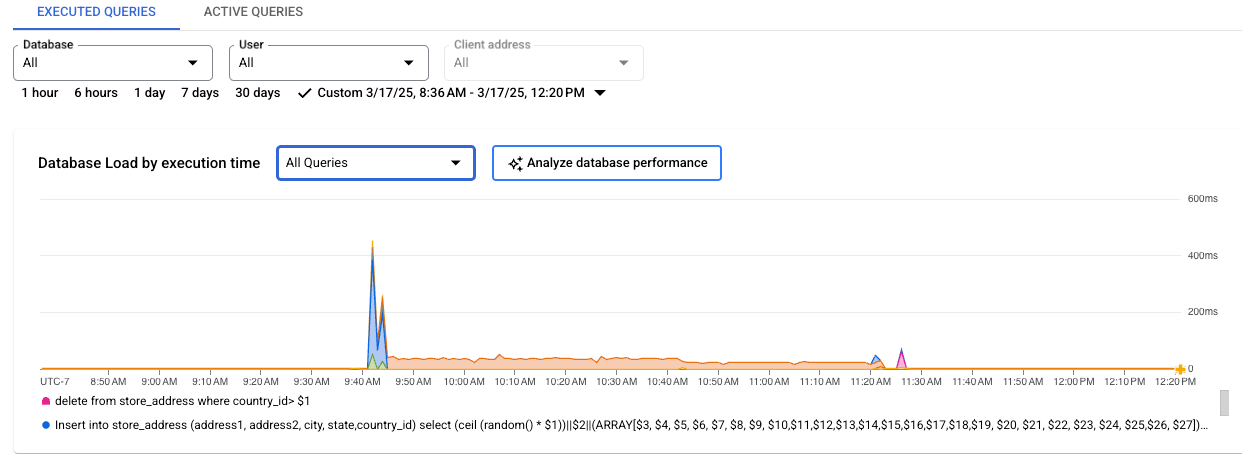
Cloud SQL Enterprise Plus エディション
Cloud SQL Enterprise エディション
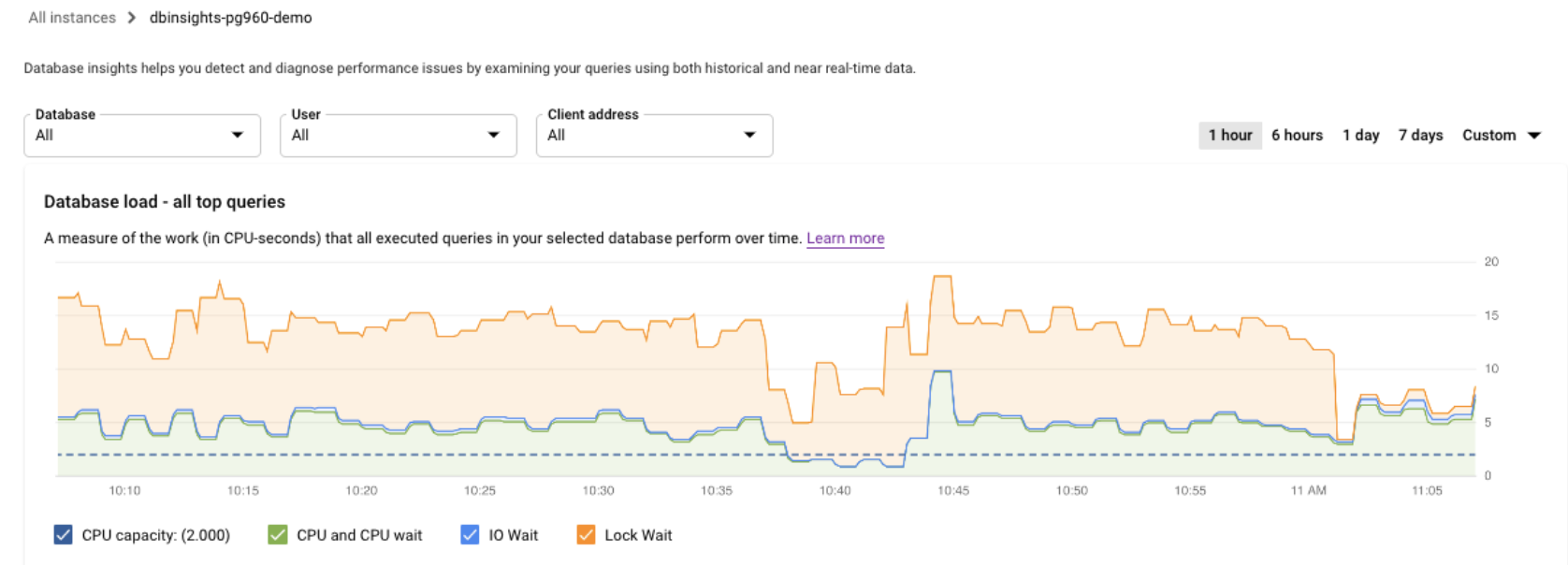
グラフの色付きの線で、クエリ負荷をカテゴリ別に表示します。
- CPU 容量: インスタンスで利用可能な CPU の数。
- CPU と CPU 待機: 実時間に対する、アクティブな状態のクエリで要した時間の比率です。IO 待機とロック待機は、アクティブ状態のクエリをブロックしません。この指標は、クエリが CPU を使用している可能性があることを示します。また、他のプロセスが CPU を使用しているときに Linux スケジューラがクエリを実行しているサーバー プロセスをスケジューリングするのをクエリが待機している可能性もあります。
- IO 待機: 実時間に対する、IO を待機していたクエリで要した時間の比率です。IO 待機には、読み取り IO 待機と書き込み IO 待機が含まれます。IO 待機に関する情報の内訳が必要な場合は、Cloud Monitoring で確認できます。詳細については、Cloud SQL の指標をご覧ください。詳細については、PostgreSQL のイベント テーブルをご覧ください。
- ロック待機: 実時間に対する、ロックを待機していたクエリで要した時間の比率です。通常のロック待機の他に、LwLock 待機と BufferPin ロック待機が含まれます。ロック待機の情報の詳細を確認するには、Cloud Monitoring を使用します。詳細については、Cloud SQL の指標をご覧ください。
グラフの色付きの線で、データベースごとの負荷を実行時間別に表示します。 グラフを確認し、フィルタ オプションを使用して以下の質問を検討してください。
- クエリ負荷は高いですか?時間の経過にともなってグラフが増加または減少していますか?負荷が高くない場合は、クエリに問題はありません。
- 高い負荷がどのくらい続いていますか?その値はいまだけ高くなっていますか。それとも、長い間、高くなっていますか?範囲セレクタを使用して、さまざまな期間を選択し、問題が発生した期間を探します。ズームインすると、クエリ負荷の急増が観測される時間枠が拡大表示されます。ズームアウトすると、最大 1 週間のタイムラインが表示されます。
- 高負荷の原因は何ですか?CPU 容量、CPU と CPU 待機、ロック待機、IO 待機を確認するオプションを選択できます。これらの各オプションのグラフは色が異なるため、負荷が最も高いものを見つけることができます。グラフの濃い青色の線は、システムの最大 CPU 容量を示しています。これにより、クエリ負荷をシステムの最大 CPU 容量と比較できます。この比較を行うことで、インスタンスの CPU リソースが不足しているかどうかを把握できます。
- どのデータベースで負荷が発生していますか?[データベース] プルダウン メニューからデータベースを選択して、負荷が最も高いデータベースを特定します。
- 特定のユーザーまたは IP アドレスが高負荷の原因となっていますか?プルダウン メニューから別のユーザーとアドレスを選択して、高負荷の原因を特定します。
データベース負荷のフィルタリング
クエリまたはタグでデータベース負荷をフィルタリングできます。Cloud SQL Enterprise Plus エディションの Query Insights を使用している場合は、データベース負荷グラフをカスタマイズして、次のいずれかのディメンションを使用して表示データを分類できます。すべてのクエリ
待機イベントのタイプ
待機イベント
データベース
ユーザー
タグ
クライアント アドレス
データベース負荷グラフをカスタマイズするには、[実行時間別のデータベース負荷] プルダウンからディメンションを選択します。
データベース負荷の主な要因を表示する
データベースの負荷に最も影響を与えている項目を表示するには、[データベースの負荷別の上位項目] テーブルを使用します。[データベースの負荷別の上位項目] テーブルには、[実行時間別のデータベース負荷] グラフのプルダウンで選択した期間と項目の上位項目が表示されます。期間またはディメンションを変更すると、別のディメンションまたは期間の上位の主要因を確認できます。
[データ負荷別の上位項目] テーブルで、次のタブを選択できます。
| タブ | 説明 |
|---|---|
| クエリ | このテーブルには、合計実行時間が上位の正規化されたクエリが表示されます。クエリごとに、列に表示されるデータは次のように一覧表示されます。
|
| 待機イベントのタイプ | このテーブルには、選択した期間中に発生した上位の待機イベントの種類のリストが表示されます。このテーブルは、Cloud SQL Enterprise Plus エディションの Query Insights でのみ使用できます。
|
| 待機イベント | このテーブルには、選択した期間中に発生した上位の待機イベントのリストが表示されます。このテーブルは、Cloud SQL Enterprise Plus エディションの Query Insights でのみ使用できます。
|
| データベース | このテーブルには、選択した期間中に実行されたすべてのクエリで負荷増加の要因となった上位のデータベースのリストが表示されます。
|
| ユーザー | このテーブルには、実行されたすべてのクエリについて、選択した期間の上位ユーザーのリストが表示されます。
|
| タグ | タグの詳細については、クエリタグでフィルタリングするをご覧ください。 |
| クライアント アドレス | このテーブルには、実行されたすべてのクエリについて、選択した期間の上位ユーザーのリストが表示されます。
|
クエリでフィルタリングする
[データベースの負荷別の上位項目] テーブルでは、クエリ負荷が最も大きいクエリの概要を確認できます。このテーブルには、Query Insights ダッシュボードで選択された期間とオプションに対応する、正規化されたすべてのクエリが表示されます。選択した期間内の合計実行時間でクエリが並べ替えられます。
Cloud SQL Enterprise Plus エディション
テーブルを並べ替えるには、列見出しを選択します。
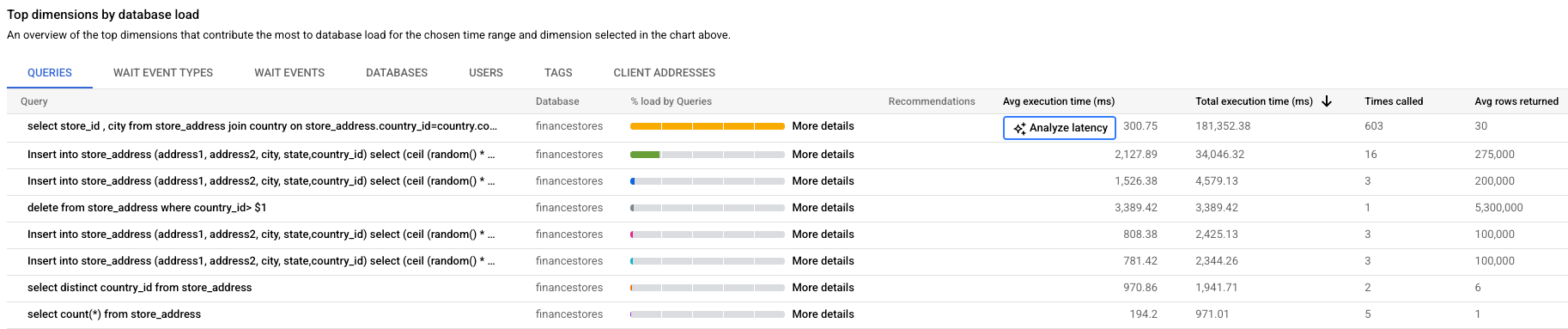
Cloud SQL Enterprise エディション
テーブルを並べ替えるには、[クエリのフィルタリング] から列見出しまたはプロパティを選択します。
テーブルには以下のプロパティが表示されます。
- クエリ: 正規化されたクエリ文字列。Query Insights では、デフォルトでクエリ文字列の 1,024 文字のみが表示されます。
UTILITY COMMANDというラベルの付いたクエリには通常、BEGIN、COMMIT、EXPLAINコマンド、またはラッパー コマンドが含まれます。 - データベース: クエリが実行されたデータベース。
- 推奨事項: クエリのパフォーマンスを向上させるため提案された推奨事項(インデックスの作成など)。
- 負荷(合計時間別)/ 負荷(CPU 別)/ 負荷(IO 待機別)/ 負荷(ロック待機別): 特定のクエリをフィルタリングして最大の負荷を見つけるオプションです。
- クエリ別の負荷の割合(%): 個々のクエリによる負荷の割合。
- レイテンシを分析: このインスタンスで AI を活用したトラブルシューティング(プレビュー)を有効にしている場合は、このリンクをクリックして低速なクエリのトラブルシューティングを行えます。
- 平均実行時間(ミリ秒): クエリの平均実行時間。
- 呼び出された回数: アプリケーションがクエリを呼び出した回数。
- 返された平均行数: クエリに対して返された行数の平均。
Query Insights は、正規化されたクエリのみを保存し、表示します。
デフォルトでは、Query Insights は IP アドレスやタグ情報を収集しません。この情報を収集するように Query Insights を設定できます。また、必要に応じて収集を無効にすることもできます。
クエリプランのトレースでは、定数値が収集または保存されず、定数として表示される PII 情報が削除されます。
PostgreSQL 9.6 と 10 では、Query Insights は正規化されたクエリを表示します。つまり、文字定数は「?」に置換されます。次の例では、名前定数が削除され、? に置換されます。
UPDATE "demo_customer" SET "customer_id" = ?::uuid, "name" = ?, "address" = ?, "rating" = ?, "balance" = ?, "current_city" = ?, "current_location" = ? WHERE "demo_customer"."id" = ?
PostgreSQL バージョン 11 以降では、$1、$2 などの変数がリテラル定数値と置換されます。
UPDATE "demo_customer" SET "customer_id" = $1::uuid, "name" = $2, "address" = $3, "rating" = $4, "balance" = $5, "current_city" = $6, "current_location" = $7 WHERE "demo_customer"."id" = $8
クエリタグでフィルタリングする
アプリケーションのトラブルシューティングを行うには、最初に SQL クエリにタグを追加する必要があります。クエリ負荷タグは、選択したタグのクエリ負荷の内訳の時間変化を示します。
Query Insights は、アプリケーション中心のモニタリングを提供して、ORM を使用して構築されたアプリケーションのパフォーマンスの問題を診断できるようにします。アプリケーション スタック全体の担当者である場合、Query Insights で、アプリケーションの視点からクエリをモニタリングできます。クエリのタグ付けは、ビジネス ロジックやマイクロサービスの使用など、より高レベルなコンストラクトで問題を見つけるのに役立ちます。
たとえば、支払いタグ、在庫タグ、ビジネス分析タグ、出荷タグなどのように、ビジネス ロジックでクエリにタグを付けることができます。このようにすると、さまざまなビジネス ロジックごとに作成されるクエリ負荷を特定できます。たとえば、午後 1 時にビジネス分析タグが急増している、過去 1 週間にわたって決済サービスが予想外の増加傾向を見せている、などの予期しないイベントに気づく可能性があります。
タグのデータベース負荷を計算するために、Query Insights は選択したタグを使用するすべてのクエリにかかる時間を使用します。このツールでは、実時間を使用して 1 分間隔で完了時間を計算できます。
Query Insights ダッシュボードで、タグテーブルを表示するには、[タグ] を選択します。タグが合計負荷を合計時間で割った値で並べ替えられます。
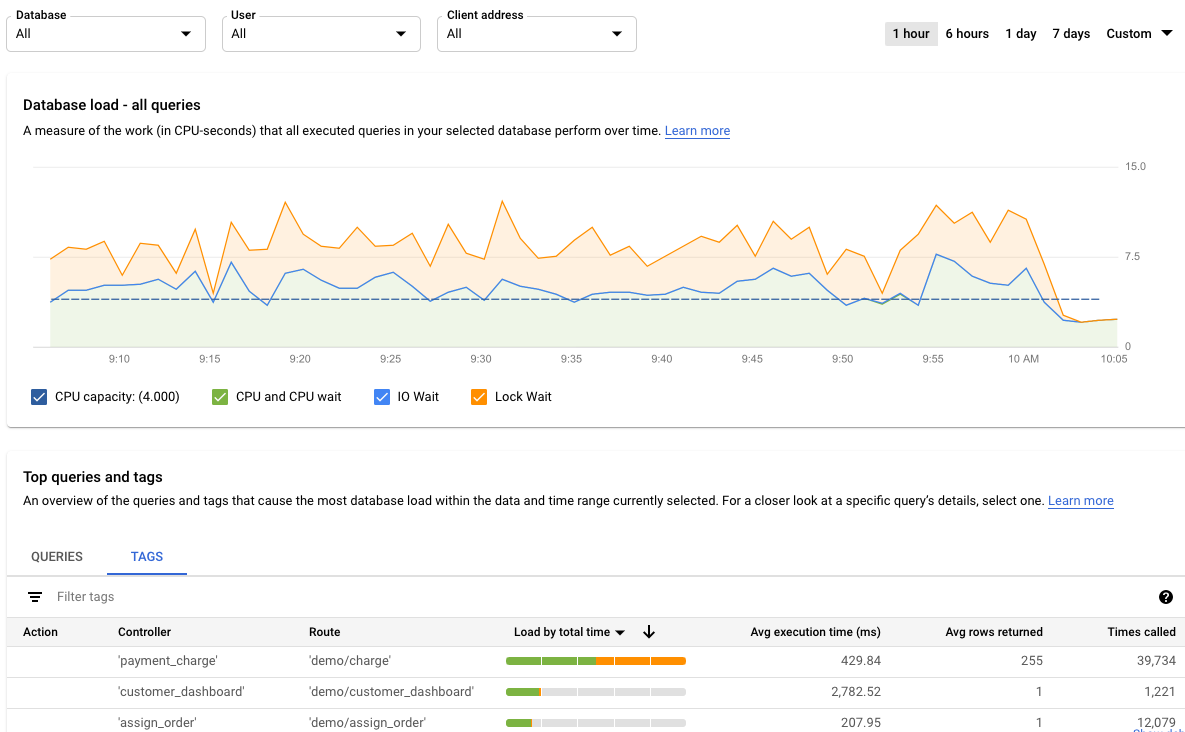
テーブルを並べ替えるには、[タグのフィルタリング] からプロパティを選択するか、列見出しをクリックします。テーブルには以下のプロパティが表示されます。
- アクション、コントローラ、フレームワーク、ルート、アプリケーション、DB ドライバ: クエリに追加した各プロパティが列として表示されます。タグでフィルタリングする場合は、これらのプロパティのうち少なくとも 1 つを追加する必要があります。
- 負荷(合計時間別)/ 負荷(CPU 別)/ 負荷(IO 待機別)/ 負荷(ロック待機別): 特定のクエリをフィルタリングして、各オプションの最大負荷を見つけるオプション。
- 平均実行時間(ミリ秒): クエリの平均実行時間。
- 返された平均行数: クエリに対して返された行数の平均。
- 呼び出された回数: アプリケーションがクエリを呼び出した回数。
- データベース: クエリが実行されたデータベース。
特定のクエリまたはタグのクエリの詳細を表示する
特定のクエリまたはタグが問題の根本原因であるかどうかを確認するには、[クエリ] タブまたは [タグ] タブで次の操作を行います。
- リストを降順で並べ替えるには、[負荷(合計実行時間別)] ヘッダーをクリックします。
- リストの上部にあるクエリまたはタグをクリックします。このクエリまたはタグは、負荷が最も高く、他のインスタンスよりも時間がかかっています。
[クエリの詳細] ページが開き、選択したクエリまたはタグの詳細が表示されます。
特定のクエリ負荷の調査
選択したクエリの [クエリの詳細] ページが次のように表示されます。

[データベースの負荷 - 特定のクエリ] グラフは、正規化クエリが選択したクエリで時間の経過に伴って行った作業量(CPU 秒)の測定結果を示します。実時間の 1 分間隔で完了した正規化クエリで要した時間を使用して、負荷を計算します。テーブルの上部には、集計と PII の理由からリテラルが削除された状態で、正規化されたクエリの最初の 1,024 文字が表示されます。
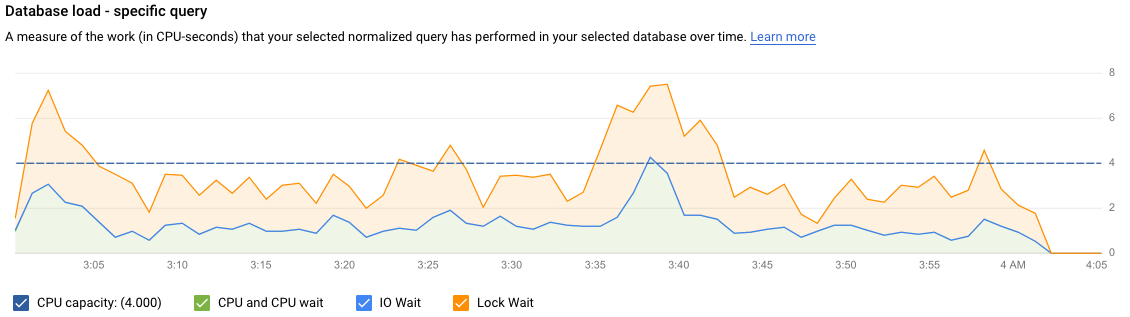
全クエリのグラフと同様に、データベース、ユーザー、クライアント アドレスで、特定のクエリの負荷をフィルタリングできます。クエリ負荷は、CPU 容量、CPU と CPU 待機、IO 待機、ロック待機に分割されます。
タグ付けされた特定のクエリ負荷の調査
選択したタグのダッシュボードが次のように表示されます。たとえば、マイクロサービスの支払いからのすべてのクエリに payment というタグを付けている場合、payment タグを表示することで、急上昇しているクエリの負荷を確認できます。
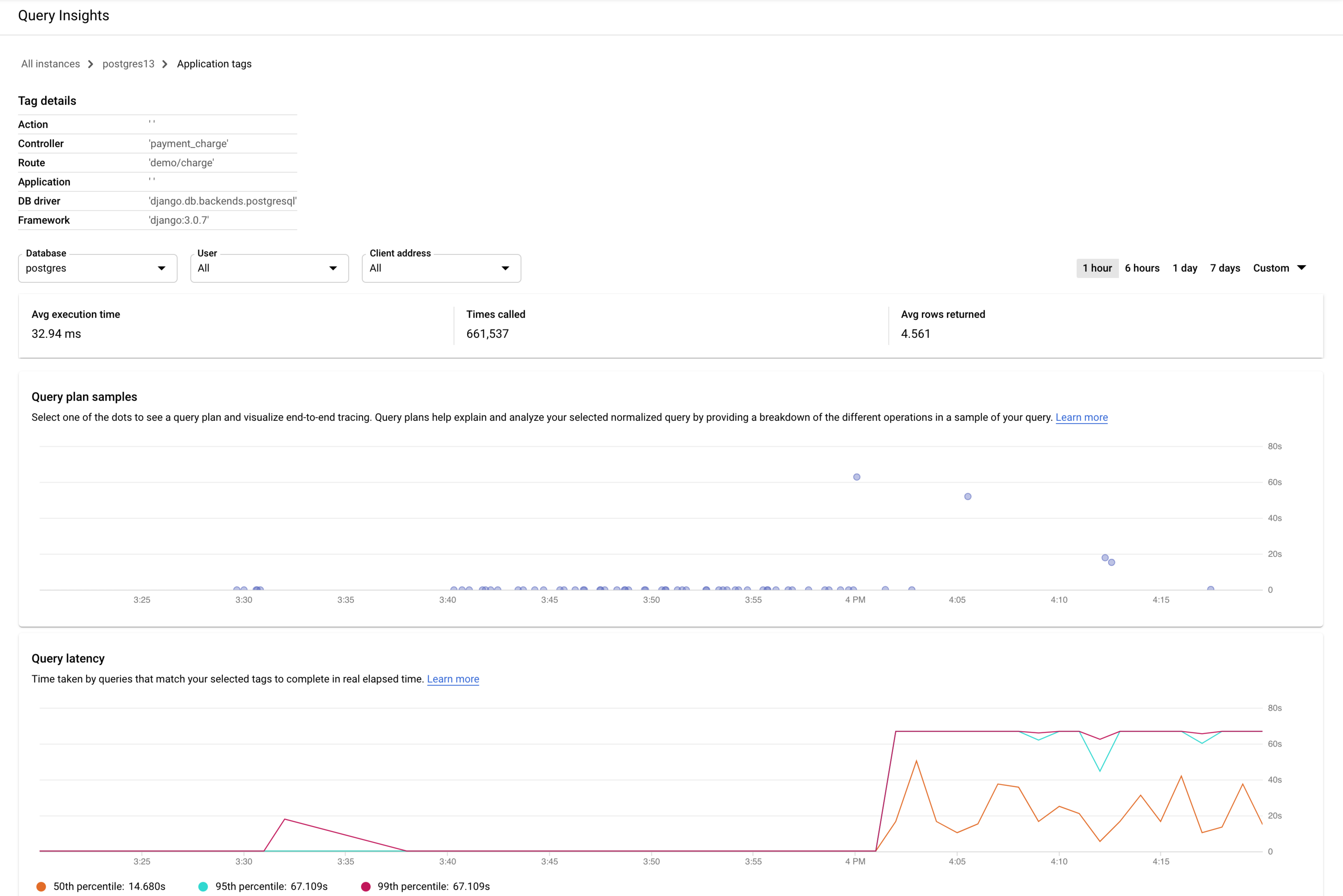
[データベースの負荷 - 特定のタグ] グラフは、選択したタグに一致するクエリが選択したデータベースで行った作業量(CPU 秒)の測定結果を時系列で示します。全クエリのグラフと同様に、データベース、ユーザー、クライアント アドレスで、特定のタグの負荷をフィルタリングできます。
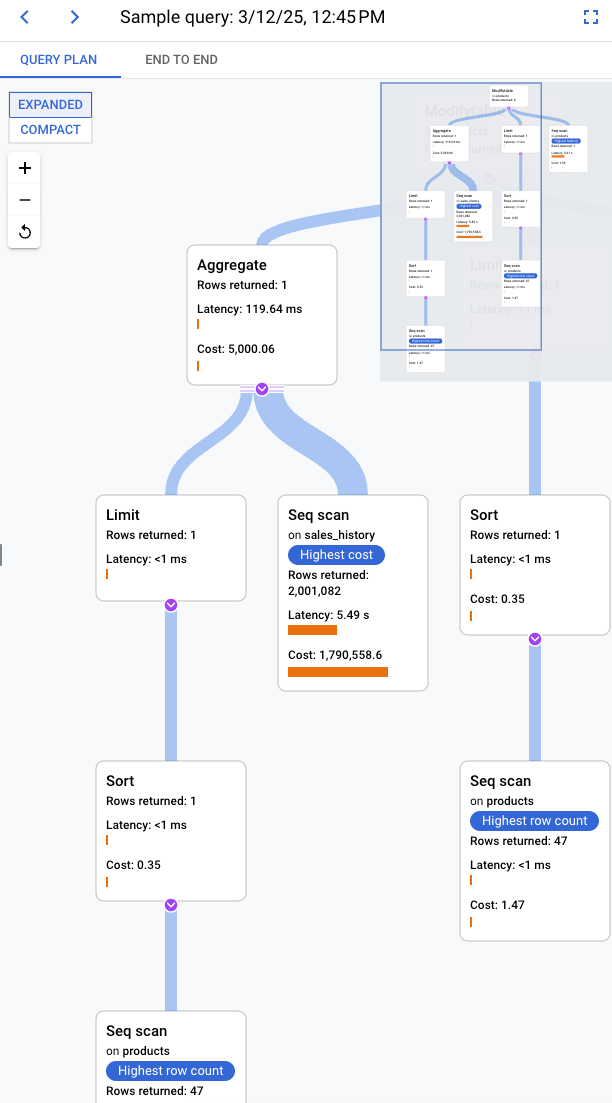
サンプリングされたクエリプランでのオペレーションの調査
クエリプランは、クエリのサンプルを取得し、それを個々のオペレーションに分割します。クエリ内の各オペレーションが説明され、分析されます。
[クエリプランのサンプル] グラフには、特定の時間に実行されているすべてのクエリプランと、各プランの実行にかかった時間が表示されます。クエリプランのサンプルが 1 分あたりにキャプチャされるペースを変更できます。Query Insights を有効にするをご覧ください。

デフォルトでは、クエリプランのサンプルのグラフに表示されているとおり、右側のパネルには長時間かかるサンプル クエリプランの詳細が表示されます。別のサンプル クエリプランの詳細を表示するには、グラフで関連する円をクリックします。詳細が開き、クエリプランのすべてのオペレーションのモデルが表示されます。
オペレーションごとに、レイテンシ、返される行、そのオペレーションの費用が表示されます。オペレーションを選択すると、共有ヒットブロック、スキーマのタイプ、ループ、プラン行などの詳細が表示されます。
以下の質問を確認して、問題を絞り込んでみてください。
- リソースの消費量とは何ですか?
- 他のクエリとどのように関係していますか?
- 消費は時間とともに変化していますか?
サンプルクエリにより生成されたトレースを調べる
クエリプランの例を確認する方法だけでなく、クエリ分析情報を使用して、クエリの例のコンテキスト内のエンドツーエンドのアプリケーション トレースを確認する方法もあります。このトレースでは特定のリクエストのデータベース アクティビティを確認できるため、問題のあるクエリの発生元を特定するのに役立ちます。また、リクエスト中にアプリケーションが Cloud Logging に送信するログエントリがトレースにリンクされるため、調査に役立ちます。
コンテキスト内のトレースを確認するには、次の操作を行います。
- [クエリの例] 画面で、[End-to-end Trace] タブをクリックします。このタブには、クエリによって生成されたトレースのスパン(個々のオペレーションのレコード)の詳細を示すガントチャートが表示されます。
- 属性やメタデータといった各スパンの詳細を確認するには、スパンを選択します。
トレースは [Trace エクスプローラ] ページでも確認できます。このためには、[Cloud Trace で表示] をクリックします。[Trace エクスプローラ] ページを使用してトレースデータを調査する方法の詳細については、トレースを検索して調査するをご覧ください。
レイテンシを調べる
レイテンシとは、正規化されたクエリの実行に要した実時間です。クエリまたはタグのレイテンシを調べるには、レイテンシ グラフを使用します。レイテンシ ダッシュボードには、外れ値の動作を見つけるために 50、95、99 パーセンタイルのレイテンシが表示されます。
以下の図は、CPU 容量、CPU と CPU 待機、IO 待機、ロック待機のフィルタを選択した、特定のクエリの 50 パーセンタイルでのデータベース負荷のグラフを示します。
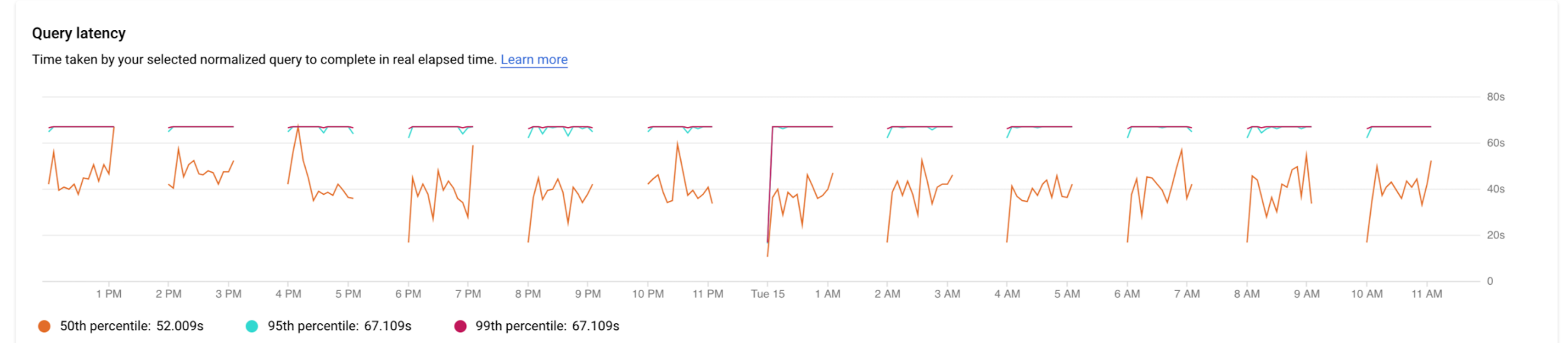
並列クエリでは、クエリの一部を実行するのに複数のコアが使用されるためクエリ負荷が高くなる可能性がありますが、レイテンシは実時間で測定されます。
以下の質問を確認して、問題を絞り込んでみてください。
- 高負荷の原因は何ですか?CPU 容量、CPU と CPU 待機、I/O 待機、ロック待機を確認するオプションを選択します。
- 高い負荷がどのくらい続いていますか?高いのは今だけですか?それとも、長い間、高いですか?期間を変更して、負荷が悪化しはじめた日時を見つけます。
- レイテンシの急増はありますか?時間枠を変更して、正規化されたクエリの履歴レイテンシを調査します。
SQL クエリにタグを追加する
SQL クエリにタグを追加すると、アプリケーションのトラブルシューティングが簡単になります。sqlcommenter を使用すると、自動または手動で SQL クエリにタグを追加できます。
ORM での sqlcommenter の使用
SQL クエリを直接記述する代わりに ORM を使用すると、パフォーマンスの問題を引き起こすアプリケーション コードが見つからない可能性があります。また、アプリケーション コードによるクエリのパフォーマンスへの影響の分析に支障をきたすことがあります。この問題に対処するために、Query Insights では sqlcommenter というオープンソース ライブラリが用意されています。このライブラリは、ORM ツールを使用するデベロッパーと管理者が、パフォーマンスの問題を引き起こしているアプリケーション コードを検出するのに役立ちます。
ORM と sqlcommenter を併用している場合、タグは自動的に作成されます。アプリケーションでコードの追加や変更を行う必要はありません。
sqlcommenter はアプリケーション サーバーにインストールできます。計測ライブラリを使用すると、MVC フレームワークに関連するアプリケーション情報を、SQL コメントとしてクエリとともにデータベースに伝播できます。データベースはこれらのタグを取得し、正規化されたクエリによって集計される統計とは無関係に、タグによる統計の記録と集計を開始します。Query Insights では、クエリ負荷を引き起こしているアプリケーションを把握し、パフォーマンスの問題を引き起こしているアプリケーション コードを特定できるように、タグが表示されます。
SQL データベース ログの結果を調べると、次のように表示されます。
SELECT * from USERS /action='run+this', controller='foo%3', traceparent='00-01', tracestate='rojo%2'/
サポートされるタグには、コントローラ名、ルート、フレームワーク、アクションが含まれます。
sqlcommenter の ORM ツールセットは、次のプログラミング言語に対応しています。
| Python |
|
| Java |
|
| Ruby |
|
| Node.js |
|
| PHP |
|
sqlcommenter の詳細と、ORM フレームワークで sqlcommenter を使用する方法については、sqlcommenter のドキュメントをご覧ください。
sqlcommenter を使用してタグを追加する
ORM を使用していない場合は、SQL クエリに対して正しい SQL コメント形式で、sqlcommenter のタグまたはコメントを手動で追加する必要があります。また、各 SQL ステートメントに、シリアル化された Key-Value ペアを含むコメントを追加する必要があります。次のキーの少なくとも 1 つを使用します。
action=''controller=''framework=''route=''application=''db driver=''
Query Insights は、他のすべてのキーを無視します。
ブロックされたアクティブ クエリ
特定のアクティブ クエリがブロックされている場合や、想定よりもはるかに長く実行されている場合は、他の依存クエリがブロックされる可能性があります。
Cloud SQL では、特定の長時間実行クエリまたはブロックされたアクティブ クエリを終了できます。
詳細については、ブロックされたアクティブなクエリをご覧ください。
Query Insights を無効にする
コンソール
Google Cloud コンソールを使用して Cloud SQL インスタンスの Query Insights を無効にするには、次の操作を行います。
-
Google Cloud コンソールで、Cloud SQL の [インスタンス] ページに移動します。
- インスタンスの [概要] ページを開くには、インスタンス名をクリックします。
- [構成] タイルで、[構成の編集] をクリックします。
- 構成オプションのセクションで [Query Insights] を開きます。
- [クエリ分析情報の有効化] チェックボックスをオフにします。
- [保存] をクリックします。
gcloud
gcloud を使用して Cloud SQL インスタンスの Query Insights を無効にするには、次のように --no-insights-config-query-insights-enabled フラグを指定して gcloud sql instances patch を実行します。実行する前に INSTANCE_ID をインスタンスの ID に置き換えてください。
gcloud sql instances patch INSTANCE_ID \ --no-insights-config-query-insights-enabled
REST
REST API を使用して Cloud SQL インスタンスの Query Insights を無効にするには、次のように queryInsightsEnabled を false に設定して instances.patch メソッドを呼び出します。
リクエストのデータを使用する前に、次のように置き換えます。
- project-id: プロジェクト ID。
- instance-id: インスタンス ID。
HTTP メソッドと URL:
PATCH https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id
リクエストの本文(JSON):
{
"settings" : { "insightsConfig" : { "queryInsightsEnabled" : false } }
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"kind": "sql#operation",
"targetLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/instances/instance-id",
"status": "PENDING",
"user": "user@example.com",
"insertTime": "2021-01-28T22:43:40.009Z",
"operationType": "UPDATE",
"name": "operation-id",
"targetId": "instance-id",
"selfLink": "https://sqladmin.googleapis.com/sql/v1beta4/projects/project-id/operations/operation-id",
"targetProject": "project-id"
}
Cloud SQL Enterprise Plus エディションで Query Insights を無効にする
Cloud SQL Enterprise Plus エディションで Query Insights を無効にするには、次の操作を行います。
-
Google Cloud コンソールで、Cloud SQL の [インスタンス] ページに移動します。
- インスタンスの [概要] ページを開くには、インスタンス名をクリックします。
- [編集] をクリックします。
- [インスタンスのカスタマイズ] で [Query Insights] を開きます。
- [Enterprise Plus の機能を有効にする] チェックボックスをオフにします。
- [保存] をクリックします。
次のステップ
- リリース時のブログ: Cloud SQL Enterprise Plus エディションに搭載された Query Insights の最新機能でデータベースのボトルネックを迅速に解消
- Cloud SQL の指標をご覧ください。Query Insights の指標タイプの文字列は
database/postgresql/insightsで始まります。 - ブログ: Cloud SQL Insights でクエリ パフォーマンスのトラブルシューティング スキルが向上
- 動画: Cloud SQL Insights の導入
- ポッドキャスト: Cloud SQL Insights
- Insights の Codelab
- CPU の高使用率を最適化する
- メモリの高使用率を最適化する
- ブログ: Sqlcommenter のご紹介: オープンソース ORM の自動計測ライブラリ
- ブログ: Sqlcommenter を使用してクエリのタグ付けを有効にする