本文介绍如何将数据库从 Oracle® 联机事务处理 (OLTP) 系统迁移到 Spanner。
Spanner 使用的某些概念与其他企业数据库管理工具有所不同,因此您可能需要对应用进行某些调整,以充分利用其功能。您可能还需要使用 Google Cloud 中的某些其他服务作为 Spanner 的补充,以满足您的需求。
迁移限制
将应用迁移到 Spanner 时,您必须考虑其所提供的功能有何不同。您可能需要重新设计应用架构,以便契合 Spanner 的功能集并与其他 Google Cloud 服务进行集成。
存储过程和触发器
Spanner 不支持在数据库级层运行用户代码,因此在迁移过程中,您必须将由数据库级存储过程和触发器实现的业务逻辑迁移到应用中。
序列
我们建议使用 UUID 版本 4 作为生成主键值的默认方法。GENERATE_UUID() 函数(GoogleSQL、PostgreSQL)会以 STRING 类型返回 UUID 版本 4 值。
如果您需要生成 64 位整数值,Spanner 支持正位反转序列 (GoogleSQL、PostgreSQL),这些序列生成的值会在正 64 位数空间中均匀分布。您可以使用这些数字来避免 hotspotting 问题。
如需了解详情,请参阅主键默认值策略。
访问权限控制
借助 Identity and Access Management (IAM),您可以控制用户和群组在项目、Spanner 实例和 Spanner 数据库级层对 Spanner 资源的访问权限。如需了解详情,请参阅 IAM 概览。
针对访问您的数据库的所有用户和服务账号,根据最小权限原则审核并实施 IAM 政策。如果应用需要对特定表、列、视图或变更数据流进行受限访问,请实现精细访问权限控制 (FGAC)。如需了解详情,请参阅精细访问权限控制概览。
数据验证限制
Spanner 在数据库层支持一组有限的数据验证限制。
如果需要更复杂的数据限制,请在应用层实现。
下表讨论了 Oracle® 数据库中常见的限制类型,以及如何使用 Spanner 来实现它们。
| 限制 | 使用 Spanner 的实现 |
|---|---|
| NOT NULL | NOT NULL 列限制 |
| 唯一 | 具有 UNIQUE 限制的二级索引 |
| 外键(适用于普通表) | 请参阅创建和管理外键关系。 |
外键 ON DELETE/ON UPDATE 操作 |
仅适用于交错表;否则,在应用层实现 |
通过 CHECK 限制或触发器检查和验证值 |
在应用层实现 |
受支持的数据类型
Oracle® 数据库和 Spanner 支持的数据类型集有所不同。下表列出了 Oracle 数据类型及其在 Spanner 中的对应项。如需详细了解各种 Spanner 数据类型的定义,请参阅数据类型。
您可能还必须按照“备注”列中的说明进一步转换数据,让 Oracle 数据能够融入您的 Spanner 数据库中。
例如,您可以先将一个大型 BLOB 作为对象存储在 Cloud Storage 存储桶(而非数据库)中,然后再将对该 Cloud Storage 对象的 URI 引用以 STRING 形式存储在数据库中。
| Oracle 数据类型 | Spanner 对应项 | 备注 |
|---|---|---|
字符类型(CHAR、VARCHAR、NCHAR、NVARCHAR)
|
STRING
|
注意:Spanner 始终使用 Unicode 字符串。 Oracle 支持的长度上限为 32000 字节(具体取决于类型),而 Spanner 最多支持 2621440 个字符。 |
BLOB、LONG RAW、BFILE |
BYTES 或 STRING(包含对象的 URI)。
|
小型对象(小于 10 MiB)可以存储为 BYTES。要存储较大对象,建议使用替代性 Google Cloud 产品(如 Cloud Storage)。 |
CLOB、NCLOB、LONG
|
STRING(包含数据或外部对象的 URI) |
小型对象(少于 2621440 个字符)可以存储为 STRING。如需存储较大对象,建议使用替代性 Google Cloud 产品(如 Cloud Storage)。
|
NUMBER、NUMERIC、DECIMAL |
STRING、FLOAT64、INT64 |
Oracle NUMBER 数据类型等效于 GoogleSQL NUMERIC 数据类型。每种数据类型都支持 38 位精度和 9 位小数的标度:(P,S) = (38,9)。PostgreSQL NUMERIC 数据类型用于存储任意精度的数值数据。
FLOAT64 GoogleSQL 数据类型最多支持 16 位精度。 |
INT、INTEGER、SMALLINT |
INT64
|
|
BINARY_FLOAT、BINARY_DOUBLE
|
FLOAT64
|
|
DATE
|
DATE
|
在 Spanner 中,DATE 类型的默认 STRING 表示形式为 yyyy-mm-dd,这与 Oracle 不同,因此在日期及其 STRING 表示形式之间进行自动转换时,请谨慎操作。Spanner 提供了用于将日期转换为格式化字符串的 SQL 函数。 |
DATETIME
|
TIMESTAMP
|
Spanner 在存储时间时不会考虑时区。如果需要存储时区,则需要另外使用一个 STRING 列。
Spanner 提供了将时间戳转换为带时区格式的字符串的 SQL 函数。 |
XML
|
STRING(包含数据或外部对象的 URI) |
小型 XML 对象(少于 2621440 个字符)可以存储为 STRING。如需存储较大对象,建议使用替代性 Google Cloud 产品(如 Cloud Storage)。 |
URI、DBURI、XDBURI、HTTPURI |
STRING
|
|
ROWID
|
PRIMARY KEY
|
Spanner 使用表的主键在内部对各行进行排序和引用,因此在 Spanner 中,主键等效于 ROWID 数据类型。 |
SDO_GEOMETRY、SDO_TOPO_GEOMETRY_SDO_GEORASTER
|
Spanner 不支持地理空间数据类型。您必须使用标准数据类型存储此类数据,并在应用层实现所有搜索和过滤逻辑。 | |
ORDAudio、ORDDicom、ORDDoc、ORDImage、ORDVideo、ORDImageSignature |
Spanner 不支持媒体数据类型。建议使用 Cloud Storage 来存储媒体数据。 |
迁移过程
迁移过程的整个时间安排如下所示:
- 转换架构和数据模型。
- 转换任何 SQL 查询。
- 迁移您的应用,使其可同时使用 Oracle 和 Spanner。
- 从 Oracle 批量导出您的数据,并使用 Dataflow 将这些数据导入 Spanner。
- 在迁移期间确保两个数据库保持一致。
- 将您的应用与 Oracle 分离。
第 1 步:转换数据库和架构
您可以将现有架构转换为 Spanner 架构来存储您的数据。为使应用更易于修改,该架构应尽可能接近现有 Oracle 架构。不过,由于功能上存在差异,您可能需要进行一些更改。
如需了解如何提高吞吐量以及减少 Spanner 数据库中的热点,请参阅架构设计最佳做法。
主键
在 Spanner 中,所有需要存储多个行的表都必须有一个主键,它由表的一个或多个列组成。表的主键用于唯一标识表中的各行;表行按主键排序。由于 Spanner 具有高度分布式特性,因此您务必要选择一种能够随着数据增长而扩容的主键生成技术。如需了解详情,请参阅推荐的主键迁移策略。
请注意,指定主键后,如果不删除并重新创建表,则不能添加或移除主键列,也不能更改主键值。如需详细了解如何指定主键,请参阅架构和数据模型 - 主键。
交织表
Spanner 提供了一项可将两个表定义为具有一对多父子关系的功能。借助此功能,您可以在存储空间内将子数据行与其对应的父行相互交错,从而有效地预联接表,并提高父项和子项一起查询时的数据检索效率。
子表的主键必须以父表的主键列开头。从子行的角度来看,父行主键称为外键。您最多可以定义 6 个级别的父子关系。
您可以为子表定义 on-delete 操作,以确定父行被删除时发生的情况:要么所有子行均被删除,要么当子行存在时父行不能删除。
以下示例演示了如何创建一个与之前定义的父级 Singers 表互相交错的 Albums 表:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
创建二级索引
您还可以创建二级索引,以便将表中主键以外的数据编入索引。
Spanner 实现二级索引的方式与表相同,因此要用作索引键的列值将受到与表主键相同的限制。这也意味着,索引具有与 Spanner 表相同的一致性保证。
使用二级索引查找值等效于使用表联接执行查询。您可以利用索引提高查询性能,方法是使用 STORING 子句将原始表的列值存储在二级索引中,并将该索引设为覆盖索引。
只有在索引本身存储了所有查询列(覆盖查询)时,Spanner 的查询优化工具才会自动使用二级索引。如需在查询原始表中的列时强制使用索引,您必须在 SQL 语句中使用 FORCE INDEX 指令,例如:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
您可以使用索引强制某一表列使用唯一值,方法是在该列上定义 UNIQUE 索引。该索引会阻止添加重复值。
以下示例 DDL 语句将为 Albums 表创建二级索引:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
请注意,如果在数据加载后创建其他索引,则填充索引可能需要一些时间。建议您将索引添加速率限制为平均每天三次。如需详细了解如何创建二级索引,请参阅二级索引。 如需详细了解有关索引创建方面的限制,请参阅架构更新。
第 2 步:转换任何 SQL 查询
Spanner 采用 ANSI 2011 扩展版 SQL 方言,并提供了许多有助于转换和聚合数据的函数和运算符。对于使用 Oracle 专用的语法、函数和类型的任何 SQL 查询,都需要进行转换才能与 Spanner 兼容。
尽管 Spanner 不支持使用结构化数据作为列定义,但您可以在 SQL 查询中通过 ARRAY 和 STRUCT 类型来使用结构化数据。
例如,您可以使用 STRUCT 类型的 ARRAY(利用预联接的数据)编写一个返回艺术家的所有专辑的查询。如需了解详情,请参阅文档中的有关子查询的注意事项部分。
在执行 SQL 查询之前,您可以先使用 Google Cloud 控制台中的 Spanner Studio 页面来分析该查询。对大型表执行全表扫描的查询通常非常耗时,因此应谨慎使用。
如需详细了解如何优化 SQL 查询,请参阅 SQL 最佳做法文档。
第 3 步:迁移应用以使用 Spanner
Spanner 提供了各种语言版本的一组客户端库,并且支持使用 Spanner 专有的 API 调用,以及使用 SQL 查询和数据修改语言 (DML) 语句来读取和写入数据。对于某些查询(例如按键直接读取行),使用 API 调用时的执行速度可能更快,因为不需要转换 SQL 语句。
此外,您也可以通过 Java 数据库连接 (JDBC) 驱动程序,利用没有进行原生集成的现有工具和基础架构连接到 Spanner。
在迁移过程中,对于 Spanner 中不提供的功能,您必须在应用中实现它们。例如,如需实现用于验证数据值和更新一个相关表的触发器,您需要在应用中使用读写事务来读取现有行,验证限制,然后将更新后的行写入两个表。
Spanner 提供读写事务和只读事务,用于确保数据的外部一致性。另外,如果您需要读取一致的数据版本(通过以下方式指定),可以通过应用时间戳边界的读取事务:
- 过去某一确切时间(最多 1 小时前)的数据。
- 未来数据(在该时间到来之前,无法执行读取操作)。
- 与可接受的有限的过时程度对应的数据(在这种情况下,系统将在过去某个时间之前返回一致的视图,无需检查其他副本上有无更新的数据)。这可以带来性能优势,但同时也可能会读取过时的数据。
第 4 步:将数据从 Oracle 转移到 Spanner
要将数据从 Oracle 转移到 Spanner,您需要将 Oracle 数据库导出为一种可移植的文件格式(例如 CSV),然后使用 Dataflow 将该数据导入 Spanner。
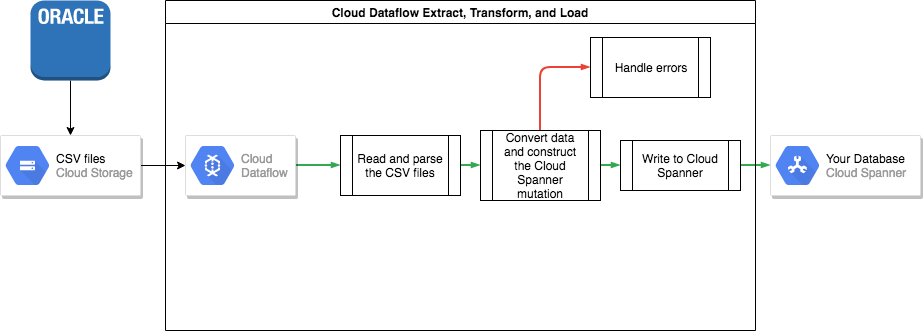
从 Oracle 批量导出
Oracle 没有内置任何用于将整个数据库导出或卸载为可移植文件格式的实用程序。
Oracle 常见问题解答中列出了一些导出方案。
其中包括:
- 使用 SQL*plus 或 SQLcl 将查询假脱机到一个文本文件。
- 使用 UTL_FILE 编写 PL/SQL 函数将表并行卸载到文本文件。
- 使用 Oracle APEX 或 Oracle SQL Developer 中的功能将表卸载到 CSV 或 XML 文件。
上述方案都存在一个缺点,那就是一次只能导出一个表,这意味着您必须暂停应用或让数据库处于静默状态,这样数据库才能保持一致的状态以进行导出。
其他方案涉及到第三方工具(请参阅 Oracle 常见问题解答页面),其中一些方案可以卸载整个数据库的一致视图。
卸载完成后,建议您将这些数据文件上传到 Cloud Storage 存储桶,以使其可供导入。
将数据批量导入 Spanner
由于 Oracle 与 Spanner 的数据库架构可能有所不同,因此您可能需要在导入过程中进行一些数据转换。
如需执行这些数据转换并将数据导入 Spanner,最简单的方法是使用 Dataflow。
Dataflow 是 Google Cloud 提供的一项分布式提取、转换和加载 (ETL) 服务。该服务为运行使用 Apache Beam SDK 编写的数据流水线以在多台机器上并行读取和处理大量数据提供了一个平台。
Apache Beam SDK 会要求您编写一个简单的 Java 程序来设置对数据的读取、转换和写入。Cloud Storage 和 Spanner 都会提供 Beam 连接器,因此您只需要编写数据转换代码。
如需查看有关从 CSV 文件读取数据并将数据写入 Spanner 的简单流水线示例,请参阅本文随附的示例代码库。
如果在 Spanner 架构中使用交错的父子表,那么请注意,导入过程会先创建父行,然后再创建子行。为此,Spanner 导入流水线代码会依次导入根级表的所有数据、所有 1 级子表、所有 2 级子表,以此类推。
您可以直接使用 Spanner 导入流水线来批量导入数据,但这种方法需要使用正确的架构将数据存储在 Avro 文件中。
第 5 步:确保两个数据库保持一致
许多应用都有可用性要求,这使得应用无法在导出和导入数据所需的时间内保持脱机状态。在将数据转移到 Spanner 期间,应用仍会修改现有数据库。您必须将应用运行期间发生的更新复制到 Spanne 数据库。
您可以通过多种方法让两个数据库保持同步,包括变更数据捕获以及在应用中实现同步更新。
变更数据捕获
Oracle GoldenGate 可以为您的 Oracle 数据库提供一个变更数据捕获 (CDC) 流。Oracle LogMiner 或 Oracle XStream Out 是 Oracle 数据库获取不涉及 Oracle GoldenGate 的 CDC 流的替代性接口。
您可以编写一个应用来订阅这些流中的一种,并在经过数据转换后对 Spanner 数据库进行相同的修改。此类流处理应用必须实现多种功能:
- 连接到 Oracle 数据库(源数据库)。
- 连接到 Spanner(目标数据库)。
- 重复执行以下操作:
- 接收其中一种 Oracle 数据库 CDC 流生成的数据。
- 解读 CDC 流生成的数据。
- 将数据转换为 Spanner
INSERT语句。 - 执行 Spanner
INSERT语句。
数据库迁移技术是一种中间件技术,该技术在其功能中已实现了所需的特性。根据客户要求,数据库迁移平台会作为单独的组件安装在源位置或目标位置。数据库迁移平台仅需要配置所涉及的数据库的连接,以指定并启动从源数据库到目标数据库的持续数据传输。
Striim 是Google Cloud上提供的数据库迁移技术平台。它可以提供从 Oracle GoldenGate 以及 Oracle LogMiner 和 Oracle XStream Out 到 CDC 流的连接。Striim 提供了一个图形工具,可让您配置数据库连接,以及将数据从 Oracle 传输到 Spanner 所需的任何转换规则。
您可以通过 Google Cloud Marketplace 安装 Striim、连接到源数据库和目标数据库、实施任何转换规则以及开始传输数据,而不必自行构建流处理应用。
通过应用同时更新两个数据库
您也可以将应用修改为向两个数据库写入数据。一个数据库(最初的 Oracle 数据库)被视为可靠数据源;在每次向该数据库写入数据之后,应用都会对整行内容进行读取和转换,并将其写入 Spanner 数据库。
这样,应用就会不断使用最新数据来覆盖 Spanner 行中的内容。
您确定所有数据都已正确转移后,可以将数据源切换到 Spanner 数据库。
如果在切换到 Spanner 时发现问题,这种机制提供了一条回滚路径。
验证数据一致性
随着数据不断流入 Spanner 数据库,您可以定期对 Spanner 数据和 Oracle 数据运行比较,以确保二者保持一致。
要验证一致性,您可以对两个数据源执行查询并比较查询结果。
借助 Dataflow,您可以使用 Join 转换对大型数据集执行详细比较。该转换采用 2 个键控数据集,并按键匹配值。 然后可以比较匹配值是否相等。
您可以定期运行此验证,直到一致性程度符合您的业务要求。
第 6 步:改用 Spanner 作为应用的可靠来源
当您确信数据迁移达到要求后,就可以将应用切换为使用 Spanner 作为可靠数据源。您应该继续向 Oracle 数据库写入更改,从而使 Oracle 数据库保持最新状态,以便在出现问题时获得一条回滚路径。
最后,您可以停用并移除 Oracle 数据库更新代码,然后关闭 Oracle 数据库。
导出和导入 Spanner 数据库
如需执行导出操作,您可以选择使用 Dataflow 模板将表从 Spanner 导出到 Cloud Storage 存储分区。生成的文件夹包含一组 Avro 文件和 JSON 清单文件(含导出的表)。 这些文件有多种用途,具体如下:
- 备份数据库以实现数据保留政策合规性或灾难恢复。
- 将 Avro 文件导入其他 Google Cloud 产品(如 BigQuery)。
后续步骤
- 了解如何优化 Spanner 架构。
- 了解如何在更复杂的情况下使用 Dataflow。