En este instructivo, se describe cómo migrar de Amazon DynamoDB a Spanner. Por lo general, lo usan propietarios de app que desean trasladarse de un sistema NoSQL a Spanner, que es un sistema de base de datos SQL muy escalable, 100% relacional y tolerante a errores que es compatible con las transacciones. Si usas tablas de Amazon DynamoDB de forma coherente, en términos de tipos y diseño, la asignación a Spanner es sencilla. Si tus tablas de Amazon DynamoDB contienen valores y tipos de datos arbitrarios, tal vez sería más fácil trasladarse a otros servicios NoSQL, como Datastore o Firestore.
En este instructivo, se supone que conoces los esquemas de base de datos, los tipos de datos, los aspectos principales de NoSQL y los sistemas de base de datos relacional. El instructivo se basa en la ejecución de tareas predefinidas para realizar una migración de ejemplo. Después del instructivo, puedes modificar el código y los pasos proporcionados para que coincidan con tu entorno.
En el siguiente diagrama arquitectónico, se describen los componentes usados en el instructivo para migrar datos:

Objetivos
- Migrar datos de Amazon DynamoDB a Spanner
- Crear una tabla de migración y base de datos de Spanner
- Asignar un esquema NoSQL a un esquema relacional
- Crear y exportar un conjunto de datos de muestra que use Amazon DynamoDB.
- Transferir datos entre Amazon S3 y Cloud Storage
- Usar Dataflow para cargar datos en Spanner
Costos
En este instructivo, se usan los siguientes componentes facturables de Google Cloud:
Los cargos de Spanner se calculan según la cantidad de capacidad de procesamiento de tu instancia y los datos almacenados durante el ciclo de facturación mensual. Durante el instructivo, usarás una configuración mínima de estos recursos que se limpian al final. Para situaciones reales, calcula tus requisitos de almacenamiento y capacidad de procesamiento. Luego, usa la documentación de instancias de Spanner a fin de determinar la cantidad de capacidad de procesamiento que necesitas.
Además de los recursos de Google Cloud , en este instructivo se usan los siguientes recursos de Amazon Web Services (AWS):
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
Solo se necesitan estos servicios durante el proceso de migración. Al final del instructivo, sigue las instrucciones para limpiar todos los recursos a fin de evitar cargos innecesarios. Usa la calculadora de precios de AWS para calcular estos costos.
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Establece la zona predeterminada de Compute Engine. Por ejemplo,
us-central1-b. gcloud config set compute/zone us-central1-b - Clona el repositorio de GitHub que contiene el código de muestra. git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git
- Ve al directorio clonado. cd dynamodb-spanner-migration
- Crea un entorno virtual de Python. pip3 install virtualenv virtualenv env
- Active el entorno virtual. source env/bin/activate
- Instala los módulos requeridos de Python. pip3 install -r requirements.txt
- En la consola de AWS, ve a la sección IAM, haz clic en Funciones y, luego, selecciona Crear función.
- En Tipo de entidad de confianza, asegúrate de que el servicio de AWS esté seleccionado.
- En Caso de uso, selecciona Lambda y, luego, haz clic en Siguiente.
- En la casilla de filtro Políticas de permisos, ingresa
AWSLambdaDynamoDBExecutionRoley presionaReturnpara buscar. - Selecciona la casilla de verificación AWSLambdaDynamoDBExecutionRole y, luego, haz clic en Siguiente.
- En la casilla Nombre de función, ingresa
dynamodb-spanner-lambda-roley, luego, haz clic en Crear función. - Mientras sigues en la sección IAM de la consola de AWS, haz clic en Usuarios y, a continuación, selecciona Agregar usuarios.
- En la casilla Nombre de usuario, ingresa
dynamodb-spanner-migration. En Tipo de acceso, selecciona la casilla de verificación a la izquierda de Clave de acceso: Acceso programático.
Haz clic en Next: Permissions.
Haz clic en Adjuntar las políticas existentes de forma directa y, mediante el cuadro Buscar para filtrar, selecciona la casilla de verificación junto a cada una de estas tres políticas:
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
Haz clic en Siguiente: Etiquetas y Siguiente: Revisar y, luego, haz clic en Crear usuario.
Haz clic en Mostrar para ver las credenciales. El ID de clave de acceso y la clave de acceso secreto se muestran para el usuario recién creado. Deja esta ventana abierta por ahora, ya que necesitarás las credenciales en la siguiente sección. Almacena estas credenciales de forma segura, ya que con ellas, puedes realizar cambios en tu cuenta y afectar a tu entorno. Al final de este instructivo, podrás borrar el usuario de IAM.
En Cloud Shell, configura la interfaz de línea de comandos de AWS (CLI).
aws configure
Aparecerá este resultado:
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- Ingresa el
ACCESS KEY IDy laSECRET ACCESS KEYde la cuenta IAM de AWS que creaste. - En el campo Nombre de región predeterminado, ingresa
us-west-2. Deja los otros campos con sus valores predeterminados.
- Ingresa el
Cierra la ventana de la consola de IAM de AWS.
En Cloud Shell, crea una tabla de Amazon DynamoDB que use los atributos de la tabla de muestra.
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75Verifica que el estado de la tabla sea
ACTIVE.aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'Propaga la tabla con los datos de muestra.
python3 make-fake-data.py --table Migration --items 25000
Crea una instancia de Spanner en la misma región en la que estableciste la zona de Compute Engine predeterminada. Por ejemplo,
us-central1.gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"Crea una base de datos en la instancia de Spanner junto con la tabla de muestra.
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"En Cloud Shell, habilita las transmisiones de Amazon DynamoDB en tu tabla de origen.
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGESConfigura un tema de Pub/Sub para recibir los cambios.
gcloud pubsub topics create spanner-migration
Aparecerá este resultado:
Created topic [projects/your-project/topics/spanner-migration].
Crea una cuenta de servicio de IAM para enviar actualizaciones de tablas al tema de Pub/Sub.
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"Aparecerá este resultado:
Created service account [spanner-migration].
Crea una vinculación de política de IAM a fin de que la cuenta de servicio tenga permiso para realizar publicaciones en Pub/Sub. Reemplaza
GOOGLE_CLOUD_PROJECTpor el nombre de tu proyecto Google Cloud .gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comAparece este resultado:
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
Crea las credenciales para la cuenta de servicio.
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comAparecerá este resultado:
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
Prepara y empaqueta la función de AWS Lambda para enviar los cambios de la tabla de Amazon DynamoDB al tema de Pub/Sub.
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd - zip -g pubsub-lambda.zip ddbpubsub.py
Crea una variable para capturar los nombres de recursos de Amazon (ARN) de la función de ejecución de Lambda que creaste antes.
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)Usa el paquete
pubsub-lambda.zippara crear la función de AWS Lambda.aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"Aparece este resultado:
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128, ... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }Create a variable to capture the ARN of the Amazon DynamoDB stream for your table.
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)Adjunta la función de Lambda a la tabla de Amazon DynamoDB.
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZONPara optimizar la capacidad de respuesta durante las pruebas, agrega
--batch-size 1al final del comando anterior, que activa la función cada vez que creas, actualizas o borras un elemento.Verás un resultado similar al siguiente:
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...En Cloud Shell, crea una variable para un nombre de bucket que usarás en varias de las siguientes secciones.
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-exportCrea un bucket de Amazon S3 para recibir la exportación de DynamoDB.
aws s3 mb s3://${BUCKET}En la consola de administración de AWS, ve a DynamoDB y haz clic en Tablas.
Haz clic en la tabla
Migration.En la pestaña Exportaciones y transmisión, haz clic en Exportar a S3.
Habilita
point-in-time-recovery(PITR) si se te solicita.Haz clic en Explorar S3 para elegir el bucket de S3 que creaste antes.
Haz clic en Exportar (Export).
Haz clic en el ícono Actualizar para actualizar el estado del trabajo de exportación. El trabajo tarda varios minutos en terminar de exportarse.
En el momento que el proceso finaliza, revisa el bucket de salida.
aws s3 ls --recursive s3://${BUCKET}Este paso tardará unos 5 minutos. Una vez que se complete, verás un resultado como el siguiente:
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
En Cloud Shell, crea un bucket de Cloud Storage para recibir los archivos exportados de Amazon S3.
gcloud storage buckets create gs://${BUCKET}Sincroniza los archivos de Amazon S3 en Cloud Storage. Para la mayoría de las operaciones de copia, el comando
rsynces eficaz. Si tus archivos de exportación son grandes (de varios GB o más), usa el Servicio de transferencia de Cloud Storage para administrar la transferencia en segundo plano.gcloud storage rsync s3://${BUCKET} gs://${BUCKET} --recursive --delete-unmatched-destination-objectsPara escribir los datos de los archivos exportados en la tabla de Spanner, ejecuta un trabajo de Dataflow con un código de muestra de Apache Beam.
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"Para ver el progreso del trabajo de importación, ve a Dataflow en la Google Cloud consola.
Mientras se ejecuta el trabajo, puedes mirar el grafo de ejecución para examinar los registros. Haz clic en el trabajo cuyo Estado sea En ejecución.
Haz clic en cada etapa para ver cuántos elementos se procesaron. La importación se completa cuando todas las etapas dicen Se realizó con éxito. La misma cantidad de elementos que se crearon en tu tabla de Amazon DynamoDB se muestran como procesados en cada etapa.
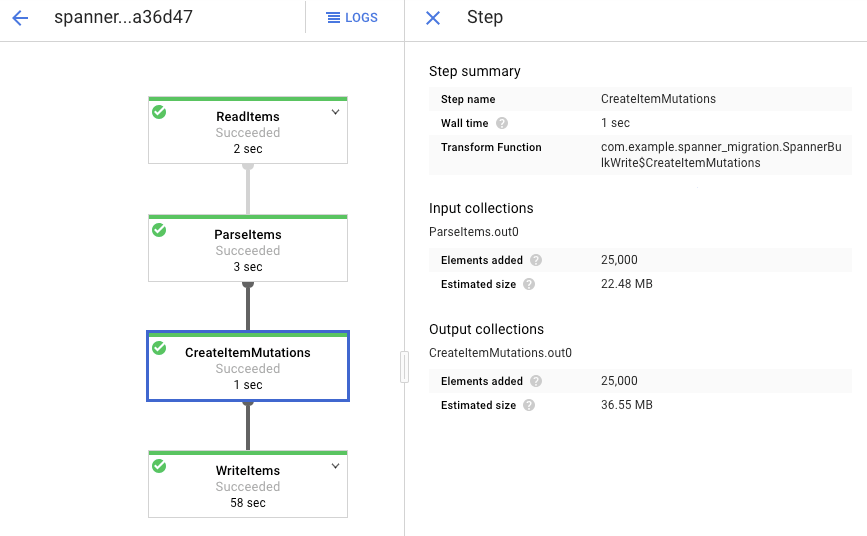
Verifica que la cantidad de registros en la tabla de destino de Spanner coincida con la cantidad de elementos en la tabla de Amazon DynamoDB.
aws dynamodb describe-table --table-name Migration --query Table.ItemCount gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"
Aparece este resultado:
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
Muestra entradas aleatorias en cada tabla para asegurar de que los datos sean coherentes.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"Aparecerá este resultado:
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
Consulta la tabla de Amazon DynamoDB con el mismo
Usernameque se mostró en la consulta de Spanner del paso anterior. Por ejemplo,aallen2538El valor es específico de los datos de muestra en tu base de datos.aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'Los valores de los otros campos deben coincidir con los del resultado de Spanner. Aparecerá este resultado:
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }Crea una suscripción al tema de Pub/Sub al que AWS Lambda envía eventos.
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migrationAparecerá este resultado:
Created subscription [projects/your-project/subscriptions/spanner-migration].
Para transmitir los cambios que ingresan a Pub/Sub y escribir la tabla de Spanner, ejecuta el trabajo de Dataflow desde Cloud Shell.
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"De manera similar al paso de carga por lotes, para ver el progreso del trabajo, ve a Dataflow en la consola de Google Cloud .
Haz clic en el trabajo cuyo Estado sea En ejecución.
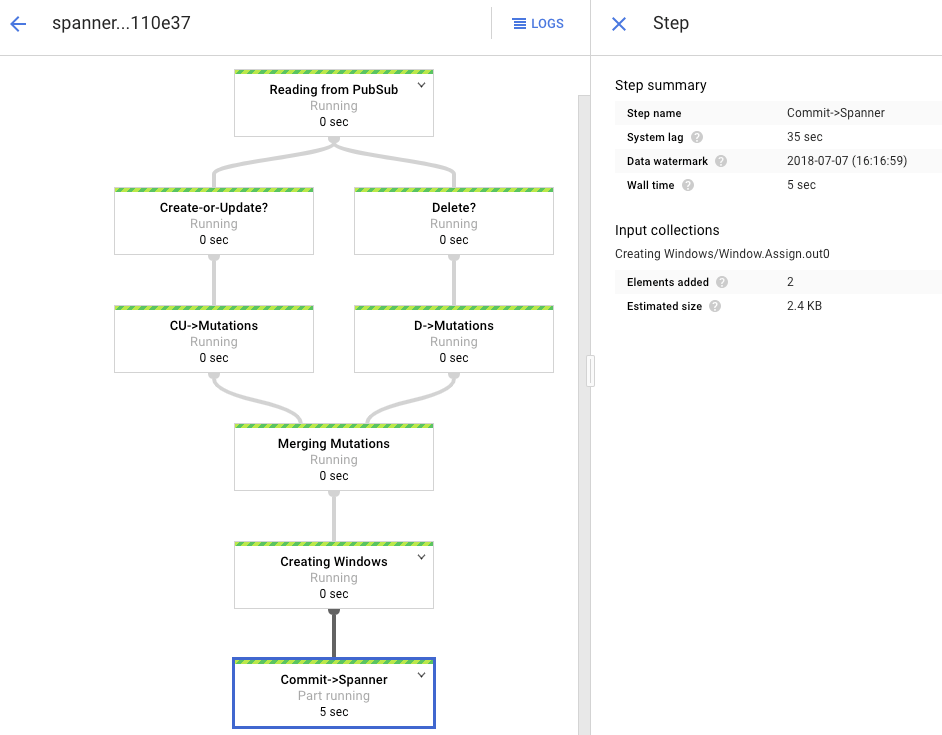
El grafo de procesamiento muestra un resultado similar al anterior, pero cada elemento procesado se cuenta en la ventana de estado. El tiempo de demora del sistema es un cálculo aproximado de cuánto esperar antes de que los cambios aparezcan en la tabla de Spanner.
Consulta una fila no existente en Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"La operación no mostrará ningún resultado.
Crea un registro en Amazon DynamoDB con la misma clave que usaste en la consulta de Spanner. Si el comando se ejecuta de forma correcta, no hay resultado.
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'Vuelve a ejecutar la misma consulta para verificar que la fila esté ahora en Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"El resultado muestra la fila que se insertó:
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
Cambia algunos atributos en el elemento original y actualiza la tabla Amazon DynamoDB.
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEWVerás un resultado similar al siguiente:
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }Verifica que los cambios se propaguen en la tabla de Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"El resultado aparece de la siguiente manera:
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
Borra el elemento de prueba de la tabla de origen de Amazon DynamoDB.
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'Verifica que la fila correspondiente se borre de la tabla de Spanner. Cuando se propaga el cambio, el siguiente comando no muestra filas:
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Ve a Spanner.
Haz clic en Spanner Studio.
En el campo Consulta, ingresa la siguiente consulta y, a continuación, haz clic en Ejecutar consulta.
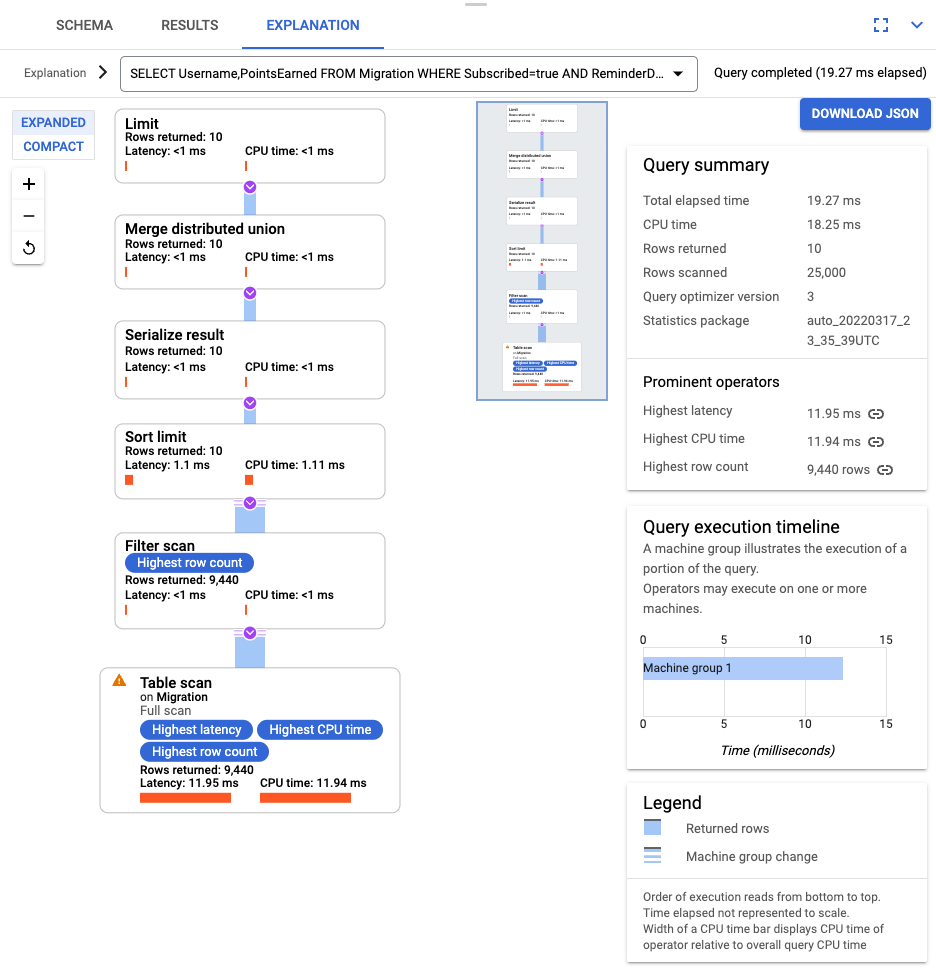
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
Luego de ejecutar la consulta, haz clic en Explicación y toma nota de las Filas analizadas en comparación con las Filas mostradas. Sin un índice, Spanner analiza toda la tabla para mostrar un pequeño subconjunto de datos que coincida con la consulta.
Si esto representa una consulta común, crea un índice compuesto en las columnas Subscribed y ReminderDate. En la consola de Spanner, selecciona el panel de navegación izquierdo Índices y, luego, haz clic en Crear índice.
En el cuadro de texto, ingresa la definición del índice.
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
Para comenzar a compilar la base de datos en segundo plano, haz clic en Crear.
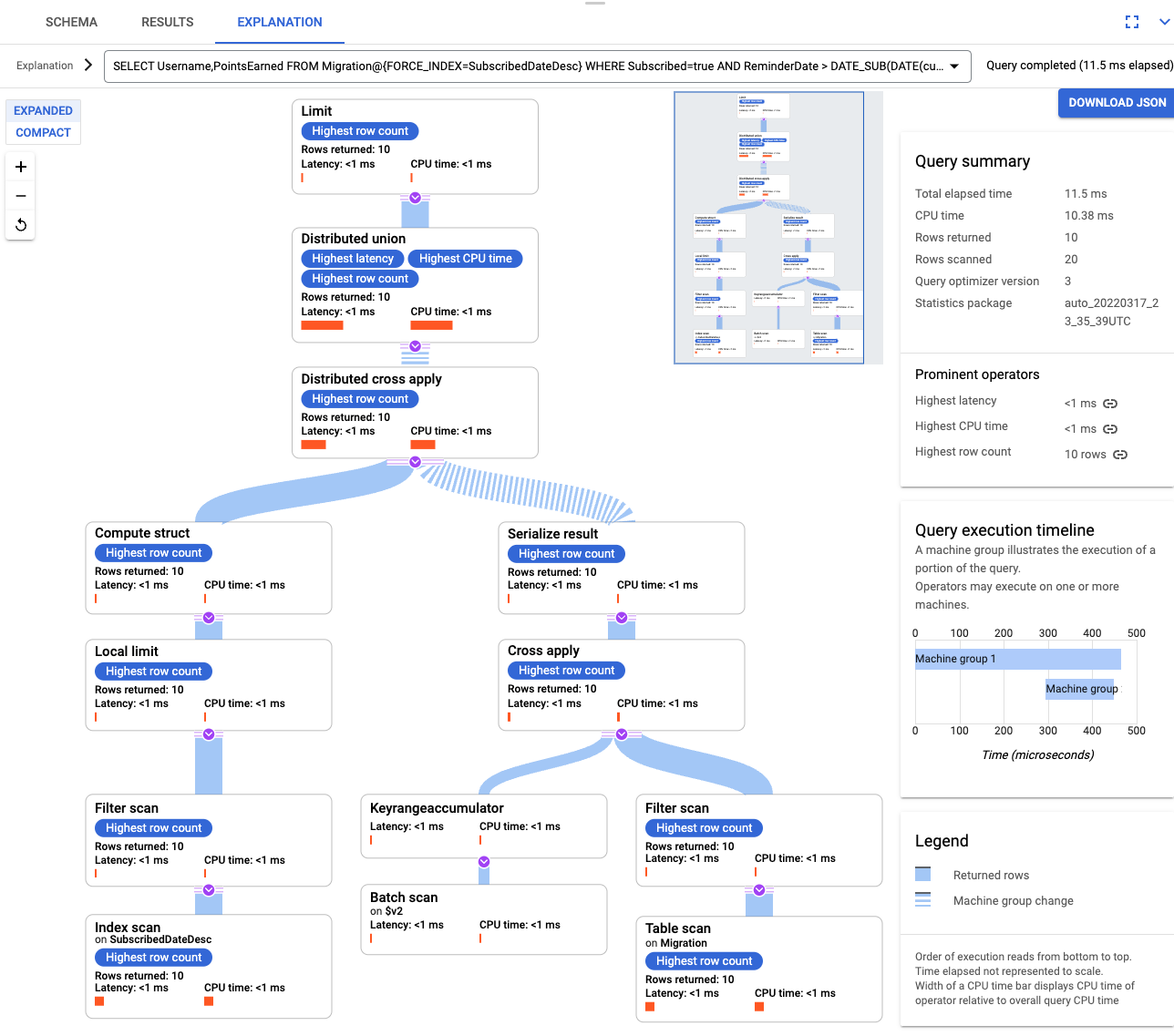
Después de crear el índice, vuelve a ejecutar la consulta y agrega el índice.
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10Vuelve a examinar la explicación de consulta. Ten en cuenta que la cantidad de Filas analizadas ha disminuido. Las Filas mostradas en cada paso coinciden con la cantidad que mostró la consulta.
Con el objetivo de analizar JSON entrante y compilar mutaciones, usa GSON. Ajusta la definición de JSON para que coincida con tus datos.
Define la asignación JSON correspondiente.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Borra la tabla de DynamoDB llamada Migración.
- Borra el bucket de Amazon S3 y la función de Lambda que creaste durante los pasos de migración.
- Por último, borra el usuario de IAM de AWS que creaste durante este instructivo.
- Lee la página Optimizar el diseño del esquema para Cloud Spanner.
- Obtén información para usar Dataflow en situaciones más complejas.
Cuando completes las tareas que se describen en este documento, podrás borrar los recursos que creaste para evitar que se te siga facturando. Para obtener más información, consulta Realiza una limpieza.
Prepara el entorno
En este instructivo, ejecutarás comandos en Cloud Shell. Cloud Shell te brinda acceso a la línea de comandos en Google Cloudy, además, incluye Google Cloud CLI y otras herramientas que necesitas para el desarrollo en Google Cloud . La inicialización de Cloud Shell puede tomar varios minutos.
Configura el acceso a AWS
En este instructivo, crearás y borrarás tablas de Amazon DynamoDB, depósitos de Amazon S3 y otros recursos. Para acceder a estos recursos, primero debes crear los permisos necesarios de administración de identidades y accesos (IAM) de AWS. Puedes usar una cuenta de AWS de prueba o una zona de pruebas para evitar que se afecten los recursos de producción en la misma cuenta.
Crea una función IAM de AWS para AWS Lambda
En esta sección, crearás una función IAM de AWS que AWS Lambda usa en un paso posterior del instructivo.
Crea un usuario IAM de AWS
Sigue estos pasos para crear un usuario IAM de AWS con acceso programático a los recursos de AWS que se usarán en todo el instructivo.
Configura la interfaz de línea de comandos de AWS
Obtén información sobre el modelo de datos
En la siguiente sección, se describen las similitudes y diferencias entre los tipos de datos, índices y claves para Amazon DynamoDB y Spanner.
Tipos de datos
Spanner usa tipos de datos de GoogleSQL. En la siguiente tabla, se describe cómo los tipos de datos de Amazon DynamoDB se asignan a los tipos de datos de Spanner.
| Amazon DynamoDB | Spanner |
|---|---|
| Número | Según la precisión o el uso previsto, se puede asignar a INT64, FLOAT64, MARCA DE TIEMPO o FECHA. |
| String | String |
| Booleano | BOOL |
| Nulo | Sin tipo explícito. Las columnas pueden contener valores nulos. |
| Binario | Bytes |
| Conjuntos | Arreglo |
| Mapa y lista | Realiza la estructura si esta es coherente y se puede describir mediante la sintaxis de la tabla DDL. |
Clave primaria
Una clave primaria de Amazon DynamoDB establece la unicidad y puede ser una clave hash o una combinación de una clave hash más una clave de rango. Este instructivo comienza con la demostración de la migración de una tabla de Amazon DynamoDB cuya clave primaria es una clave hash. Esta clave hash se convierte en la clave primaria de tu tabla de Spanner. Más adelante, en la sección sobre tablas intercaladas, crearás una situación en la que una tabla de Amazon DynamoDB usa una clave primaria compuesta por una clave hash y una clave de rango.
Índices secundarios
Tanto Amazon DynamoDB como Spanner admiten la creación de un índice en un atributo que no es una clave primaria. Toma nota de los índices secundarios de la tabla de Amazon DynamoDB para poder crearlos en la tabla de Spanner, proceso que se explica en una sección posterior de este instructivo.
Tabla de muestra
Para que este instructivo sea más sencillo de comprender, migra la siguiente tabla de muestra de Amazon DynamoDB a Spanner:
| Amazon DynamoDB | Spanner | |
|---|---|---|
| Nombre de la tabla |
Migration
|
Migration
|
| Clave primaria |
"Username" : String
|
"Username" : STRING(1024)
|
| Tipo de clave | Hash | No corresponde |
| Otros campos |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
Prepara la tabla de Amazon DynamoDB
En la siguiente sección, crearás una tabla de origen de Amazon DynamoDB y la propagarás con los datos.
Crear una base de datos de Spanner
Debes crear una instancia de Spanner con la menor capacidad de procesamiento posible: 100 unidades de procesamiento. Esta capacidad de procesamiento es suficiente para el alcance de este instructivo. Para una implementación de producción, consulta la documentación sobre instancias de Spanner para determinar la capacidad de procesamiento adecuada y cumplir con los requisitos de rendimiento de tu base de datos.
En este ejemplo, crearás un esquema de tabla al mismo tiempo que la base de datos. También es posible y común llevar a cabo actualizaciones de esquemas después de crear la base de datos.
Prepara la migración
En las siguientes secciones, se muestra cómo exportar la tabla de origen de Amazon DynamoDB y configurar la replicación de Pub/Sub para registrar cualquier cambio en la base de datos que ocurra mientras la exportas.
Transmite cambios a Pub/Sub
Usa una función de AWS Lambda para transmitir los cambios de la base de datos a Pub/Sub.
Exporta la tabla de Amazon DynamoDB a Amazon S3
Realice la migración
Una vez que la publicación de Pub/Sub está en su lugar, puedes seguir adelante con cualquier cambio en la tabla generado después de la exportación.
Copia la tabla exportada a Cloud Storage
Importa los datos por lotes
Repite los cambios nuevos
Cuando se completa el trabajo de importación por lotes, configura un trabajo de transmisión para escribir actualizaciones continuas de la tabla de origen en Spanner. Te suscribes a los eventos de Pub/Sub y los escribes en Spanner
La función de Lambda que creaste está configurada para registrar los cambios en la tabla de origen de Amazon DynamoDB y publicarlos en Pub/Sub.
El trabajo de Dataflow que ejecutaste en la fase de carga por lotes era un conjunto finito de entradas, también conocido como un conjunto de datos delimitado. Este trabajo de Dataflow usa Pub/Sub como una fuente de transmisión y se considera ilimitado. Para obtener más información sobre estos dos tipos de fuentes, consulta la sección sobre PCollections en la guía de programación de Apache Beam. El trabajo de Dataflow en este paso debe permanecer activo, por lo que no se finaliza cuando termina de procesarse. El trabajo de transmisión de Dataflow permanece en el estado En ejecución, en lugar del estado Se realizó con éxito.
Verifica la replicación
Realiza algunos cambios en la tabla de origen para verificar que los cambios se repliquen en la tabla de Spanner.
Usa tablas intercaladas
Spanner es compatible con el concepto de tablas intercaladas. Este es un modelo de diseño en el que un elemento de nivel superior tiene varios elementos anidados que se relacionan con ese elemento de nivel superior, como un cliente y sus pedidos o un jugador y sus puntuaciones de juego. Si tu tabla de origen Amazon DynamoDB usa una clave primaria que consta de una clave hash y una clave de rango, puedes modelar un esquema de tabla intercalada como se muestra en el siguiente diagrama. Esta estructura permite consultar de manera eficaz la tabla intercalada mientras unes los campos en la tabla superior.

Aplica índices secundarios
Se recomienda aplicar índices secundarios a las tablas de Spanner después de cargar los datos. Ahora que la replicación funciona, configura un índice secundario para acelerar las solicitudes. Al igual que las tablas de Spanner, los índices secundarios de Spanner son 100% coherentes. No tienen coherencia eventual, que es usual en muchas bases de datos NoSQL. Esta característica puede ayudarte a simplificar el diseño de tu app.
Ejecuta una consulta que no use ningún índice. Busca los casos N superiores, especificados con un valor de columna particular. Esta es una consulta común en Amazon DynamoDB para la eficiencia de la base de datos.
Índices intercalados
Puedes configurar los índices intercalados en Spanner. Los índices secundarios en la sección anterior están en la raíz de la jerarquía de la base de datos y usan los índices de la misma forma que una base de datos convencional. Un índice intercalado está en el contexto de su fila intercalada. Consulta Opciones de índice para obtener más detalles acerca de dónde aplicar los índices intercalados.
Ajusta tu modelo de datos
Modifica tus archivos de origen de Apache Beam para adaptar la parte de la migración de este instructivo a tu propia situación. Lo importante es que no cambies el esquema de origen durante la ventana de migración real; de lo contrario, puedes perder datos.
En los pasos anteriores, modificaste el código fuente de Apache Beam para la importación masiva. Modifica el código fuente para la parte de transmisión de la canalización de una manera similar. Por último, ajusta la secuencia de comandos de creación de tablas, índices y esquemas de tu base de datos de destino de Spanner.
Limpia
Para evitar que se apliquen cargos a tu Google Cloud cuenta por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
Borra los recursos de AWS
Si tu cuenta de AWS se usa por fuera de este instructivo, ten cuidado cuando borres los siguientes recursos: