En una base de datos de Spanner, Spanner crea automáticamente un índice para la clave principal de cada tabla. Por ejemplo, no tienes que hacer nada para indexar la clave principal de Singers, ya que se indexa automáticamente.
También puedes crear índices secundarios para otras columnas. Si añades un índice secundario a una columna, será más eficiente buscar datos en esa columna. Por ejemplo, si necesitas buscar rápidamente un álbum por título, debes crear un índice secundario en AlbumTitle para que Spanner no tenga que analizar toda la tabla.
Si la búsqueda del ejemplo anterior se realiza en una transacción de lectura y escritura, la búsqueda más eficiente también evita mantener bloqueos en toda la tabla, lo que permite insertar y actualizar simultáneamente filas de la tabla que no estén en el AlbumTitle intervalo de búsqueda.
Además de las ventajas que aportan a las búsquedas, los índices secundarios también pueden ayudar a Spanner a ejecutar búsquedas de forma más eficiente, lo que permite realizar búsquedas de índice en lugar de búsquedas de tabla completas.
Spanner almacena los siguientes datos en cada índice secundario:
- Todas las columnas de clave de la tabla base
- Todas las columnas incluidas en el índice
- Todas las columnas especificadas en la cláusula
STORINGopcional (bases de datos del dialecto de GoogleSQL) o en la cláusulaINCLUDE(bases de datos del dialecto de PostgreSQL) de la definición del índice.
Con el tiempo, Spanner analiza tus tablas para asegurarse de que tus índices secundarios se utilizan en las consultas adecuadas.
Añadir un índice secundario
El momento más eficiente para añadir un índice secundario es cuando creas la tabla. Para crear una tabla y sus índices al mismo tiempo, envía las instrucciones DDL de la nueva tabla y los nuevos índices en una sola solicitud a Spanner.
En Spanner, también puedes añadir un nuevo índice secundario a una tabla mientras la base de datos sigue sirviendo tráfico. Al igual que con cualquier otro cambio de esquema en Spanner, añadir un índice a una base de datos ya creada no requiere que la base de datos esté sin conexión y no bloquea columnas ni tablas completas.
Cada vez que se añade un nuevo índice a una tabla, Spanner rellena automáticamente el índice para reflejar una vista actualizada de los datos que se están indexando. Spanner gestiona este proceso de relleno para ti y se ejecuta en segundo plano con recursos de nodo de baja prioridad. La velocidad de relleno de índices se adapta a los cambios en los recursos de los nodos durante la creación de índices, y el relleno no afecta significativamente al rendimiento de la base de datos.
La creación de índices puede tardar desde varios minutos hasta muchas horas. Como la creación de índices es una actualización de esquema, está sujeta a las mismas restricciones de rendimiento que cualquier otra actualización de esquema. El tiempo necesario para crear un índice secundario depende de varios factores:
- El tamaño del conjunto de datos
- La capacidad de computación de la instancia
- La carga de la instancia
Para ver el progreso de un proceso de relleno de índice, consulta la sección de progreso.
Ten en cuenta que usar la columna Marca de tiempo de la confirmación como primera parte del índice secundario puede crear puntos de acceso y reducir el rendimiento de escritura.
Usa la instrucción CREATE INDEX para definir un índice secundario en tu esquema. A continuación, se incluyen algunos ejemplos:
Para indexar todos los Singers de la base de datos por su nombre y apellidos, haz lo siguiente:
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Para crear un índice de todos los Songs de la base de datos por el valor de SongName, sigue estos pasos:
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
Para indexar solo las canciones de un cantante concreto, usa la cláusula INTERLEAVE IN para intercalar el índice en la tabla Singers:
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
Para indexar solo las canciones de un álbum concreto, sigue estos pasos:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
Para indexar por orden descendente de SongName, haz lo siguiente:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
Ten en cuenta que la anotación DESC anterior solo se aplica a SongName. Para indexar por orden descendente de otras claves de índice, anótalas también con DESC:
SingerId DESC, AlbumId DESC.
También debes tener en cuenta que PRIMARY_KEY es una palabra reservada y no se puede usar como nombre de un índice. Es el nombre que se le da al pseudoíndice
que se crea cuando se crea una tabla con la especificación PRIMARY KEY.
Para obtener más información y consultar las prácticas recomendadas para elegir entre índices no intercalados e índices intercalados, consulta Opciones de índice y Usar un índice intercalado en una columna cuyo valor aumente o disminuya de forma monótona.
Índices e intercalación
Los índices de Spanner se pueden intercalar con otras tablas para colocar las filas de índice junto a las de otra tabla. Al igual que en el intercalado de tablas de Spanner, las columnas de clave principal del elemento superior del índice deben ser un prefijo de las columnas indexadas, con el mismo tipo y orden de clasificación. A diferencia de las tablas intercaladas, no es necesario que los nombres de las columnas coincidan. Cada fila de un índice intercalado se almacena físicamente junto con la fila principal asociada.
Por ejemplo, supongamos que se da el siguiente esquema:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
Para indexar todos los Singers de la base de datos por su nombre y apellidos, debes crear un índice. A continuación, te indicamos cómo definir el índice SingersByFirstLastName:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Si quieres crear un índice de Songs en (SingerId, AlbumId, SongName),
puedes hacer lo siguiente:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
También puedes crear un índice intercalado con un ancestro de Songs,
como el siguiente:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
Además, también puedes crear un índice de Songs en
(PublisherId, SingerId, AlbumId, SongName) que esté intercalado con una tabla
que no sea un elemento antecesor de Songs, como Publishers. Ten en cuenta que la clave principal de la tabla Publishers (id) no es un prefijo de las columnas indexadas del siguiente ejemplo. Esto sigue estando permitido porque Publishers.Id y Songs.PublisherId comparten el mismo tipo, orden y nulidad.
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
Comprobar el progreso del relleno de índice
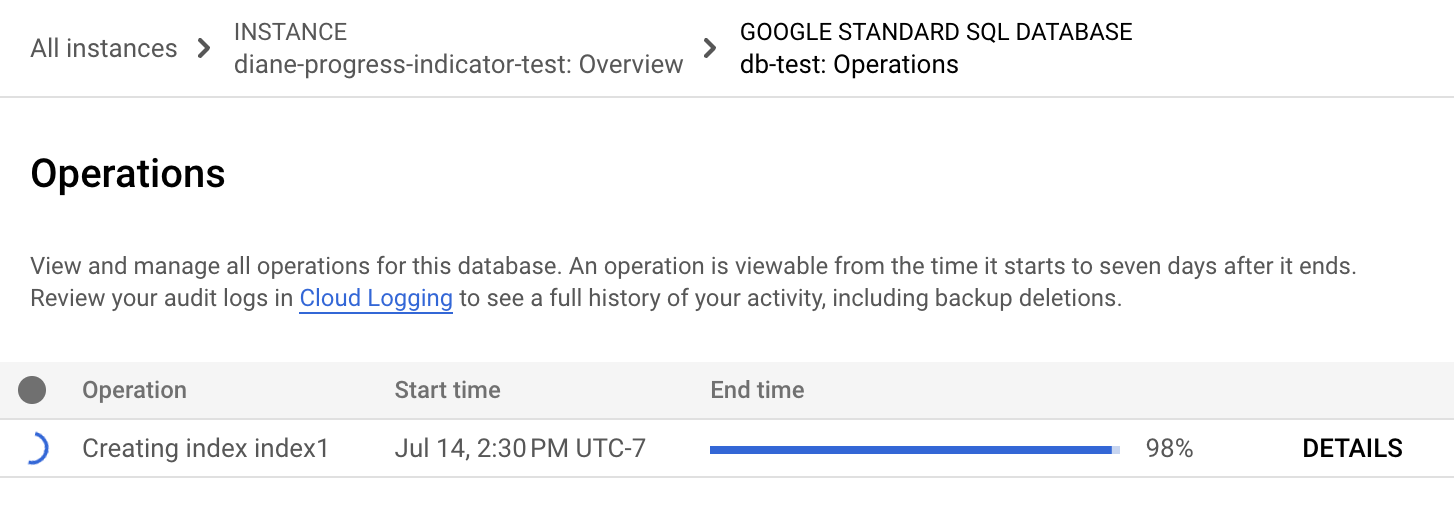
Consola
En el menú de navegación de Spanner, haga clic en la pestaña Operaciones. En la página Operaciones se muestra una lista de las operaciones en curso.
Busca la operación de relleno en la lista. Si sigue en curso, el indicador de progreso de la columna Hora de finalización muestra el porcentaje de la operación que se ha completado, como se muestra en la siguiente imagen:
gcloud
Usa gcloud spanner operations describe para comprobar el progreso de una operación.
Obtén el ID de la operación:
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Haz los cambios siguientes:
- INSTANCE-NAME con el nombre de la instancia de Spanner.
- DATABASE-NAME con el nombre de la base de datos.
Notas sobre el uso:
Para limitar la lista, especifica la marca
--filter. Por ejemplo:--filter="metadata.name:example-db"solo muestra las operaciones de una base de datos específica.--filter="error:*"solo muestra las operaciones de copia de seguridad que no se han realizado.
Para obtener información sobre la sintaxis de los filtros, consulta Filtros de temas de gcloud. Para obtener información sobre cómo filtrar operaciones de copia de seguridad, consulta el campo
filteren ListBackupOperationsRequest.La marca
--typeno distingue entre mayúsculas y minúsculas.
El resultado es similar al siguiente:
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadataEjecuta
gcloud spanner operations describe:gcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
Haz los cambios siguientes:
- INSTANCE-NAME: nombre de la instancia de Spanner.
- DATABASE-NAME: nombre de la base de datos de Spanner.
- PROJECT-NAME: nombre del proyecto.
- OPERATION-ID: el ID de la operación que quieres comprobar.
La sección
progressde la salida muestra el porcentaje de la operación que se ha completado. La salida tiene un aspecto similar al siguiente:done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST v1
Obtén el ID de la operación:
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Haz los cambios siguientes:
- INSTANCE-NAME con el nombre de la instancia de Spanner.
- DATABASE-NAME con el nombre de la base de datos.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- PROJECT-ID: el ID del proyecto.
- INSTANCE-ID: el ID de instancia.
- DATABASE-ID: el ID de la base de datos.
- OPERATION-ID: el ID de la operación.
Método HTTP y URL:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
En gcloud y REST, puedes consultar el progreso de cada instrucción de relleno de índice en la sección progress. Por cada instrucción de la matriz de instrucciones, hay un campo correspondiente en la matriz de progreso. El orden de esta matriz de progreso se corresponde con el de la matriz de instrucciones. Cuando estén disponibles, los campos startTime, progressPercent y endTime se rellenarán en consecuencia.
Ten en cuenta que el resultado no muestra una hora estimada de cuándo se completará el proceso de relleno.
Si la operación tarda demasiado, puedes cancelarla. Para obtener más información, consulta Cancelar la creación de índices.
Situaciones al ver el progreso del relleno de índice
Hay diferentes situaciones que pueden darse al intentar comprobar el progreso de un relleno de índice. Las instrucciones de creación de índices que requieren un relleno de índice forman parte de las operaciones de actualización de esquemas, y puede haber varias instrucciones que formen parte de una operación de actualización de esquemas.
El primer caso es el más sencillo, que se da cuando la instrucción de creación de índice es la primera instrucción de la operación de actualización del esquema. Como la instrucción de creación de índices es la primera, es la primera que se procesa y se ejecuta debido al orden de ejecución.
Inmediatamente, el campo startTime de la instrucción de creación del índice se rellenará con la hora de inicio de la operación de actualización del esquema. A continuación, el campo progressPercent de la instrucción de creación del índice se rellena cuando el progreso del relleno inicial del índice supera el 0%. Por último, el campo endTime se rellena una vez que se confirma la instrucción.
El segundo caso se da cuando la instrucción de creación de índice no es la primera instrucción de la operación de actualización del esquema. Ningún campo relacionado con la instrucción de creación de índices se rellenará hasta que se hayan confirmado las instrucciones anteriores debido al orden de ejecución.
Al igual que en el caso anterior, una vez que se confirman las instrucciones anteriores, primero se rellena el campo startTime de la instrucción de creación de índice y, después, el campo progressPercent. Por último, el campo endTime se rellena cuando se completa la confirmación de la
declaración.
Cancelar la creación del índice
Puedes usar la CLI de Google Cloud para cancelar la creación de índices. Para obtener una lista de operaciones de actualización de esquema de una base de datos de Spanner, usa el comando gcloud spanner operations list e incluye la opción --filter:
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
Busca el OPERATION_ID de la operación que quieras cancelar y, a continuación, usa el comando gcloud spanner operations cancel para cancelarla:
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
Ver los índices
Para ver información sobre los índices de una base de datos, puedes usar laGoogle Cloud consola o la interfaz de línea de comandos de Google Cloud:
Consola
Ve a la página Instancias de Spanner en la Google Cloud consola.
Haga clic en el nombre de la instancia que quiera ver.
En el panel de la izquierda, haz clic en la base de datos que quieras ver y, a continuación, en la tabla que quieras ver.
Haz clic en la pestaña Índices. La consola Google Cloud muestra una lista de índices.
Opcional: Para obtener detalles sobre un índice, como las columnas que incluye, haz clic en su nombre.
gcloud
Usa el comando gcloud spanner databases ddl describe:
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
La CLI de gcloud imprime las instrucciones del lenguaje de definición de datos (DDL)
para crear las tablas y los índices de la base de datos. Las instrucciones CREATE
INDEX describen los índices que ya existen. Por ejemplo:
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
Consultar con un índice específico
En las siguientes secciones se explica cómo especificar un índice en una instrucción SQL y con la interfaz de lectura de Spanner. En los ejemplos de estas secciones se da por hecho que ha añadido una columna MarketingBudget a la tabla Albums y que ha creado un índice llamado AlbumsByAlbumTitle:
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Especificar un índice en una instrucción SQL
Cuando usas SQL para consultar una tabla de Spanner, Spanner usa automáticamente los índices que probablemente hagan que la consulta sea más eficiente. Por lo tanto, no es necesario especificar un índice para las consultas SQL. Sin embargo, para las consultas que sean críticas para tu carga de trabajo, Google te recomienda que uses directivas FORCE_INDEX en tus instrucciones SQL para obtener un rendimiento más constante.
En algunos casos, Spanner puede elegir un índice que provoque un aumento de la latencia de las consultas. Si has seguido los pasos para solucionar problemas de regresiones de rendimiento y has confirmado que es conveniente probar con otro índice para la consulta, puedes especificar el índice como parte de la consulta.
Para especificar un índice en una instrucción SQL, usa la sugerencia FORCE_INDEX para proporcionar una directiva de índice. Las directivas de índice usan la siguiente sintaxis:
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
También puedes usar una directiva de índice para indicar a Spanner que analice la tabla base en lugar de usar un índice:
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
Puedes usar una directiva de índice para indicar a Spanner que analice un índice de una tabla con esquemas con nombre:
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
En el siguiente ejemplo se muestra una consulta SQL que especifica un índice:
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
Una directiva de índice puede obligar al procesador de consultas de Spanner a leer columnas adicionales que la consulta necesita, pero que no están almacenadas en el índice.
El procesador de consultas obtiene estas columnas combinando el índice y la tabla base. Para evitar esta unión adicional, usa una cláusula STORING (bases de datos con dialecto de GoogleSQL) o INCLUDE (bases de datos con dialecto de PostgreSQL) para almacenar las columnas adicionales en el índice.
En el ejemplo anterior, la columna MarketingBudget no se almacena en el índice, pero la consulta de SQL selecciona esta columna. Por lo tanto, Spanner debe buscar la columna MarketingBudget en la tabla base y, a continuación, combinarla con los datos del índice para devolver los resultados de la consulta.
Spanner genera un error si la directiva de índice tiene alguno de los siguientes problemas:
- El índice no existe.
- El índice está en otra tabla base.
- A la consulta le falta una expresión de filtrado
NULLobligatoria para un índiceNULL_FILTERED.
En los siguientes ejemplos se muestra cómo escribir y ejecutar consultas que obtengan los valores de AlbumId, AlbumTitle y MarketingBudget mediante el índice AlbumsByAlbumTitle:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Especificar un índice en la interfaz de lectura
Cuando usas la interfaz de lectura de Spanner y quieres que Spanner use un índice, debes especificarlo. La interfaz de lectura no selecciona el índice automáticamente.
Además, el índice debe contener todos los datos que aparecen en los resultados de la consulta, excepto las columnas que forman parte de la clave principal. Esta restricción se debe a que la interfaz de lectura no admite combinaciones entre el índice y la tabla base. Si necesitas incluir otras columnas en los resultados de la consulta, tienes varias opciones:
- Usa una cláusula
STORINGoINCLUDEpara almacenar las columnas adicionales en el índice. - Consulta sin incluir las columnas adicionales y, a continuación, usa las claves principales para enviar otra consulta que lea las columnas adicionales.
Spanner devuelve los valores del índice en orden ascendente por clave de índice. Para recuperar los valores en orden descendente, sigue estos pasos:
Anota la clave de índice con
DESC. Por ejemplo:CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);La anotación
DESCse aplica a una sola clave de índice. Si el índice incluye más de una clave y quieres que los resultados de la consulta aparezcan en orden descendente en función de todas las claves, incluye una anotaciónDESCpara cada clave.Si la lectura especifica un intervalo de claves, asegúrate de que el intervalo de claves también esté en orden descendente. Es decir, el valor de la clave de inicio debe ser mayor que el valor de la clave de finalización.
En el siguiente ejemplo se muestra cómo obtener los valores de AlbumId y AlbumTitle mediante el índice AlbumsByAlbumTitle:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Crear un índice para análisis solo de índice
También puedes usar la cláusula STORING (para bases de datos con dialecto de GoogleSQL) o la cláusula INCLUDE (para bases de datos con dialecto de PostgreSQL) para almacenar una copia de una columna en el índice. Este tipo de índice ofrece ventajas para las consultas y las llamadas de lectura que lo usan, pero a costa de usar almacenamiento adicional:
- Las consultas de SQL que usan el índice y seleccionan columnas almacenadas en la cláusula
STORINGoINCLUDEno requieren una unión adicional a la tabla base. - Las llamadas a
read()que usan el índice pueden leer las columnas almacenadas por la cláusulaSTORING/INCLUDE.
Por ejemplo, supongamos que has creado una versión alternativa de AlbumsByAlbumTitle
que almacena una copia de la columna MarketingBudget en el índice (fíjate en la cláusula STORING o INCLUDE en negrita):
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
Con el índice AlbumsByAlbumTitle antiguo, Spanner debe combinar el índice con la tabla base y, a continuación, recuperar la columna de la tabla base. Con el nuevo índice AlbumsByAlbumTitle2, Spanner lee la columna directamente del índice, lo que resulta más eficiente.
Si usas la interfaz de lectura en lugar de SQL, el nuevo índice AlbumsByAlbumTitle2
también te permite leer la columna MarketingBudget directamente:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Modificar un índice
Puedes usar la instrucción ALTER INDEX para añadir columnas adicionales a un índice o eliminar columnas. De esta forma, se puede actualizar la lista de columnas definida por la cláusula STORING (bases de datos del dialecto de GoogleSQL) o la cláusula INCLUDE (bases de datos del dialecto de PostgreSQL) al crear el índice. No puede usar esta instrucción para añadir o eliminar columnas de la clave de índice. Por ejemplo, en lugar de crear un nuevo índice AlbumsByAlbumTitle2, puedes usar ALTER INDEX para añadir una columna a AlbumsByAlbumTitle, como se muestra en el siguiente ejemplo:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
Cuando añades una columna a un índice, Spanner usa un proceso de relleno en segundo plano. Mientras se realiza el relleno, la columna del índice no se puede leer, por lo que es posible que no obtengas la mejora del rendimiento esperada. Puedes usar el comando gcloud spanner operations para enumerar la operación de larga duración y ver su estado.
Para obtener más información, consulta describe operation.
También puedes usar cancel operation para cancelar una operación en curso.
Una vez completado el relleno, Spanner añade la columna al índice. A medida que el índice aumenta, las consultas que lo usan pueden ralentizarse.
En el siguiente ejemplo se muestra cómo eliminar una columna de un índice:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
Índice de valores NULL
De forma predeterminada, Spanner indexa los valores NULL. Por ejemplo, recuerda la definición del índice SingersByFirstLastName en la tabla Singers:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Todas las filas de Singers se indexan aunque FirstName o LastName, o ambos, sean NULL.

Cuando se indexan los valores de NULL, puedes realizar consultas y lecturas SQL eficientes sobre los datos que incluyen valores de NULL. Por ejemplo, usa esta instrucción de consulta SQL para buscar todos los Singers con un NULL FirstName:
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
Orden de clasificación de los valores NULL
Spanner ordena NULL como el valor más pequeño de cualquier tipo. En el caso de una columna ordenada de forma ascendente (ASC), los valores NULL se ordenan primero. En una columna ordenada de forma descendente (DESC), los valores NULL se ordenan al final.
Inhabilitar la indexación de valores NULL
GoogleSQL
Para inhabilitar la indexación de valores nulos, añade la palabra clave NULL_FILTERED a la definición del índice. Los índices NULL_FILTERED son especialmente útiles para indexar columnas dispersas, en las que la mayoría de las filas contienen un valor NULL. En estos casos, el índice NULL_FILTERED puede ser considerablemente más pequeño y eficiente de mantener que un índice normal que incluya valores NULL.
Aquí tienes una definición alternativa de SingersByFirstLastName que no indexa los valores de NULL:
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
La palabra clave NULL_FILTERED se aplica a todas las columnas de clave de índice. No puede especificar el filtrado NULL por columnas.
PostgreSQL
Para excluir las filas con valores nulos en una o varias columnas indexadas, usa el predicado WHERE COLUMN IS NOT NULL.
Los índices filtrados por valores NULL son especialmente útiles para indexar columnas dispersas, donde la mayoría de las filas contienen un valor NULL. En estos casos, el índice filtrado por nulos puede ser considerablemente más pequeño y eficiente de mantener que un índice normal que incluya valores NULL.
Aquí tienes una definición alternativa de SingersByFirstLastName que no indexa los valores de NULL:
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
Si se excluyen los valores NULL, se impide que Spanner los utilice en algunas consultas. Por ejemplo, Spanner no usa el índice en esta consulta porque omite las filas de Singers en las que LastName es NULL. Por lo tanto, si se usara el índice, la consulta no devolvería las filas correctas:
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
Para que Spanner pueda usar el índice, debes reescribir la consulta de forma que excluya las filas que también se excluyen del índice:
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
Campos de proto de índice
Usa columnas generadas para indexar campos en búferes de protocolo almacenados en columnas PROTO, siempre que los campos que se indexen usen los tipos de datos primitivos o ENUM.
Si defines un índice en un campo de mensaje de protocolo, no puedes modificar ni eliminar ese campo del esquema proto. Para obtener más información, consulta Actualizaciones de esquemas que contienen un índice en campos proto.
A continuación, se muestra un ejemplo de la tabla Singers con una columna de mensaje proto SingerInfo. Para definir un índice en el campo nationality de PROTO,
debes crear una columna generada almacenada:
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
Tiene la siguiente definición del tipo proto googlesql.example.SingerInfo:
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
A continuación, define un índice en el campo nationality del proto:
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
La siguiente consulta de SQL lee datos mediante el índice anterior:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
Notas:
- Usa una directiva de índice para acceder a los índices de los campos de las columnas de búfer de protocolo.
- No puedes crear un índice en campos de búfer de protocolo repetidos.
Actualizaciones de esquemas que contienen un índice en campos proto
Si defines un índice en un campo de mensaje de protocolo, no puedes modificar ni eliminar ese campo del esquema proto. Esto se debe a que, después de definir el índice, se realiza una comprobación de tipos cada vez que se actualiza el esquema. Spanner captura la información de tipo de todos los campos de la ruta que se utilizan en la definición del índice.
Índices únicos
Los índices se pueden declarar UNIQUE. Los índices UNIQUE añaden una restricción a los datos que se indexan, lo que impide que haya entradas duplicadas para una clave de índice determinada.
Spanner aplica esta restricción en el momento de confirmar la transacción.
En concreto, no se podrá confirmar ninguna transacción que provoque que existan varias entradas de índice para la misma clave.
Si una tabla contiene datos que no son UNIQUE desde el principio, no se podrá crear un índice UNIQUE en ella.
Nota sobre los índices UNIQUE NULL_FILTERED
Un índice UNIQUE NULL_FILTERED no exige la unicidad de la clave de índice cuando al menos una de las partes de la clave del índice es NULL.
Por ejemplo, supongamos que ha creado la siguiente tabla e índice:
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
Las dos filas siguientes de ExampleTable tienen los mismos valores para las claves de índice secundario Key1, Key2 y Col1:
1, NULL, 1, 1
1, NULL, 2, 1
Como Key2 es NULL y el índice se ha filtrado por nulos, las filas no estarán presentes en el índice ExampleIndex. Como no se insertan en el índice, este no los rechazará por infringir la unicidad en (Key1, Key2,
Col1).
Si quieres que el índice aplique la unicidad de los valores de la tupla (Key1, Key2, Col1), debes anotar Key2 con NOT NULL en la definición de la tabla o crear el índice sin filtrar los valores nulos.
Eliminar un índice
Usa la instrucción DROP INDEX para eliminar un índice secundario de tu esquema.
Para eliminar el índice llamado SingersByFirstLastName, haz lo siguiente:
DROP INDEX SingersByFirstLastName;
Índice para acelerar el análisis
Cuando Spanner necesita realizar un análisis de tabla (en lugar de una búsqueda indexada) para obtener valores de una o varias columnas, puedes recibir resultados más rápidos si existe un índice para esas columnas y en el orden especificado por la consulta. Si realizas con frecuencia consultas que requieren análisis, considera la posibilidad de crear índices secundarios para que estos análisis se realicen de forma más eficiente.
En concreto, si necesitas que Spanner analice con frecuencia la clave principal u otro índice de una tabla en orden inverso, puedes aumentar su eficiencia mediante un índice secundario que haga explícito el orden elegido.
Por ejemplo, la siguiente consulta siempre devuelve un resultado rápido, aunque Spanner tenga que analizar Songs para encontrar el valor más bajo de SongId:
SELECT SongId FROM Songs LIMIT 1;
SongId es la clave principal de la tabla, que se almacena (como todas las claves principales) en orden ascendente. Spanner puede analizar el índice de esa clave y encontrar el primer resultado rápidamente.
Sin embargo, sin la ayuda de un índice secundario, la siguiente consulta no se devolvería tan rápido, sobre todo si Songs contiene muchos datos:
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
Aunque SongId es la clave principal de la tabla, Spanner no tiene forma de obtener el valor más alto de la columna sin recurrir a un análisis completo de la tabla.
Si añades el siguiente índice, esta consulta se podrá completar más rápido:
CREATE INDEX SongIdDesc On Songs(SongId DESC);
Con este índice, Spanner lo usaría para devolver un resultado para la segunda consulta mucho más rápido.
Siguientes pasos
- Consulta las prácticas recomendadas de SQL para Spanner.
- Consulta información sobre los planes de ejecución de consultas de Spanner.
- Consulta cómo solucionar problemas de regresiones en el rendimiento de las consultas SQL.