Ce document explique comment utiliser la console Google Cloud pour créer une règle d'alerte basée sur des métriques qui envoie des notifications lorsque les valeurs d'une métrique sont supérieures ou inférieures au seuil pour une période de retest spécifique. Par exemple, la condition d'une règle d'alerte peut être remplie lorsque l'utilisation du processeur est supérieure à 80 % pendant au moins cinq minutes.
Ce contenu ne concerne pas les règles d'alerte basées sur les journaux. Pour en savoir plus sur les règles d'alerte basées sur les journaux, qui vous avertissent lorsqu'un message particulier s'affiche dans les journaux, consultez la page Surveiller vos journaux.
Ce document ne décrit pas les éléments suivants :
- Découvrez comment recevoir une notification lorsque les données cessent d'arriver. Pour en savoir plus, consultez Créer des règles d'alerte en cas d'absence de métrique.
- Recevoir des notifications en fonction de la valeur prédite d'une métrique. Pour en savoir plus, consultez Créer des règles d'alerte basées sur des valeurs de métriques prévues.
Découvrez comment créer une règle d'alerte à l'aide de l'API Cloud Monitoring. Pour en savoir plus, consultez Créer des règles d'alerte à l'aide de l'API.
Créer une règle d'alerte dont la condition inclut une requête MQL (Monitoring Query Language). Ces règles peuvent utiliser un seuil statique ou dynamique. Pour en savoir plus, consultez les documents suivants :
Cette fonctionnalité n'est disponible que pour les projets Google Cloud . Pour les configurations App Hub, sélectionnez le projet hôte ou le projet de gestion App Hub.
Avant de commencer
-
Pour obtenir les autorisations nécessaires pour créer et modifier des règles d'alerte à l'aide de la console Google Cloud , demandez à votre administrateur de vous accorder le rôle IAM Éditeur Monitoring (
roles/monitoring.editor) sur votre projet. Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.Vous pouvez également obtenir les autorisations requises avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour en savoir plus sur les rôles Cloud Monitoring, consultez Contrôler l'accès avec Identity and Access Management.
Assurez-vous de bien maîtriser les concepts généraux des règles d'alerte. Pour en savoir plus sur ces sujets, consultez Présentation des alertes.
Configurez les canaux de notification que vous souhaitez utiliser pour recevoir les notifications. À des fins de redondance, nous vous recommandons de créer plusieurs types de canaux de notification. Pour en savoir plus, consultez Créer et gérer des canaux de notification.
Créer une règle d'alerte
Pour créer une règle d'alerte qui compare la valeur de cette métrique à un seuil statique, procédez comme suit :
-
Dans la console Google Cloud , accédez à la page notifications Alertes :
Accéder à l'interface des alertes
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Monitoring.
- Dans la barre d'outils de la console Google Cloud , sélectionnez votre projet Google Cloud . Pour les configurations App Hub, sélectionnez le projet hôte ou le projet de gestion App Hub.
- Sélectionnez Créer une règle.
Sélectionnez la série temporelle à surveiller :
Cliquez sur Sélectionner une métrique, parcourez les menus pour sélectionner un type de ressource et un type de métrique, puis cliquez sur Appliquer.
Le menu Sélectionner une métrique contient des fonctionnalités qui vous aident à trouver les types de métriques disponibles :
- Pour trouver un type de métrique spécifique, utilisez la barre de filtre filter_list.
Par exemple, si vous saisissez
util, le menu est limité aux entrées incluantutil. Les entrées s'affichent lorsqu'elles réussissent un test "contient" non sensible à la casse.
- Pour afficher tous les types de métriques, même ceux sans données, cliquez sur Actif. Par défaut, les menus n'affichent que les types de métriques comportant des données. Pour en savoir plus, consultez Métrique non listée dans le menu.
Vous pouvez surveiller n'importe quelle métrique intégrée ou définie par l'utilisateur.
- Pour trouver un type de métrique spécifique, utilisez la barre de filtre filter_list.
Par exemple, si vous saisissez
Facultatif : Pour surveiller un sous-ensemble des séries temporelles qui correspondent aux types de métriques et de ressources que vous avez sélectionnés à l'étape précédente, cliquez sur Ajouter un filtre. Dans la boîte de dialogue du filtre, sélectionnez le libellé sur lequel filtrer, un comparateur, puis la valeur du filtre. Par exemple, le filtre
zone =~ ^us.*.a$utilise une expression régulière correspondant à toutes les données de séries temporelles dont le nom de zone commence paruset se termine para. Pour en savoir plus, consultez Filtrer les séries temporelles sélectionnées.Facultatif : Pour modifier l'alignement des points d'une série temporelle, définissez les champs Fenêtre glissante et Fonction de fenêtre glissante dans la section Transformer les données.
Si vous surveillez une métrique basée sur les journaux, nous vous recommandons de définir le menu Période mobile sur au moins 10 minutes.
Ces champs indiquent comment les points enregistrés dans une fenêtre sont combinés. Par exemple, supposons que la fenêtre soit de 15 minutes et que la fenêtrage soit
max. Le point aligné correspond à la valeur maximale de tous les points des 15 dernières minutes. Pour en savoir plus, consultez Alignement : régularisation au sein de la série.Vous pouvez également surveiller le taux de variation d'une valeur de métrique en définissant le champ Fonction de fenêtre mobile sur Variation en pourcentage. Pour en savoir plus, consultez Surveiller un taux de variation.
Facultatif : Combinez les séries temporelles lorsque vous souhaitez réduire le nombre de séries temporelles surveillées par une règle ou lorsque vous souhaitez surveiller uniquement une collection de séries temporelles. Par exemple, au lieu de surveiller l'utilisation du processeur de chaque instance de VM, vous pouvez calculer la moyenne de l'utilisation du processeur pour toutes les VM d'une zone, puis surveiller cette moyenne. Par défaut, les séries temporelles ne sont pas combinées. Pour obtenir des informations générales, consultez Réduction : combiner des séries temporelles.
Pour combiner toutes les séries temporelles, procédez comme suit :
- Dans la section Dans les séries temporelles, cliquez sur expand_more Développer.
- Définissez le champ Agrégation de séries temporelles sur une valeur autre que
none. Par exemple, pour afficher la valeur moyenne de la série temporelle, sélectionnezmean. - Vérifiez que le champ Grouper les séries temporelles par est vide.
Pour combiner ou regrouper des séries temporelles par valeurs de libellé, procédez comme suit :
- Dans la section Dans les séries temporelles, cliquez sur expand_more Développer.
- Définissez le champ Agrégation de séries temporelles sur une valeur autre que
none. - Dans le champ Grouper les séries temporelles par, sélectionnez les libellés de regroupement.
Par exemple, si vous regroupez par libellé
zone, puis que vous définissez le champ d'agrégation sur une valeur demean, le graphique affiche une série temporelle pour chaque zone pour laquelle il existe des données. La série temporelle affichée pour une zone spécifique correspond à la moyenne de toutes les séries temporelles de cette zone.Cliquez sur Suivant.
Configurez le déclencheur de condition :
Laissez le champ Type de condition sur la valeur par défaut Seuil.
Facultatif : Mettez à jour le menu Déclencheur d'alerte, qui comporte les valeurs suivantes :
À chaque infraction de série temporelle : paramètre par défaut. Toute série temporelle qui ne respecte pas le seuil pendant toute la période de retest entraîne le respect de la condition.
Pourcentage de séries temporelles enfreintes : un pourcentage de séries temporelles doit enfreindre le seuil pendant toute la période de nouveau test avant que la condition ne soit remplie. Par exemple, vous pouvez recevoir une notification lorsque 50 % des séries temporelles surveillées dépassent le seuil pour l'ensemble de la période de nouveau test.
Nombre de séries temporelles enfreintes : un nombre spécifique de séries temporelles doit enfreindre le seuil pour l'ensemble de la période de nouveau test avant que la condition ne soit remplie. Par exemple, vous pouvez recevoir une notification lorsque 32 séries temporelles surveillées dépassent le seuil pendant toute la période de nouveau test.
Toutes les séries temporelles enfreintes : toutes les séries temporelles doivent enfreindre le seuil pendant toute la durée de la fenêtre du nouveau test pour que la condition soit remplie.
Pour en savoir plus sur les intervalles utilisés par Monitoring pour aligner et mesurer les données de séries temporelles, consultez Périodes d'alignement et fenêtres de retest.
Indiquez quand la valeur d'une métrique dépasse le seuil à l'aide des champs Position du seuil et Valeur du seuil. Par exemple, si vous définissez ces valeurs sur Au-dessus du seuil et
0.3, toute mesure supérieure à0.3enfreint le seuil.Facultatif : Pour sélectionner la durée pendant laquelle les mesures doivent dépasser le seuil avant que Monitoring n'envoie une notification, développez Options avancées, puis utilisez le menu Fenêtre de retest.
La valeur par défaut est Pas de nouveau test. Avec ce paramètre, une seule mesure peut entraîner l'envoi d'une notification. Pour en savoir plus et obtenir un exemple, consultez Paramètres de la période d'alignement et de la durée.
Facultatif : Pour spécifier comment Monitoring évalue la condition lorsque les données cessent d'arriver, développez Options avancées, puis utilisez le menu Évaluation des données manquantes.
Le menu Données manquantes pour l'évaluation est désactivé lorsque la valeur de la Période avant nouveau test est définie sur Aucun nouveau test.
Google Cloud console
Champ "Évaluation des données manquantes"Résumé Détails Données manquantes (vide) Les incidents ouverts restent ouverts.
Aucun nouvel incident n'est ouvert.Pour les conditions remplies, la condition continue d'être remplie lorsque les données cessent d'arriver. Si un incident est ouvert pour cette condition, il le reste. Lorsqu'un incident est ouvert et qu'aucune donnée n'arrive, le minuteur de fermeture automatique démarre après un délai d'au moins 15 minutes. Si le minuteur expire, l'incident est clos.
Pour les conditions qui ne sont pas remplies, elles continuent de ne pas l'être lorsque les données cessent d'arriver.
Les points de données manquants sont traités comme des valeurs qui ne respectent pas la condition du règlement. Les incidents ouverts restent ouverts.
Vous pouvez ouvrir de nouveaux incidents.Pour les conditions remplies, la condition continue d'être remplie lorsque les données cessent d'arriver. Si un incident est ouvert pour cette condition, il le reste. Lorsqu'un incident est ouvert et qu'aucune donnée n'arrive pendant la durée de fermeture automatique plus 24 heures, l'incident est fermé.
Pour les conditions non remplies, ce paramètre fait que la condition de seuil de métrique se comporte comme un
metric-absence condition. Si les données n'arrivent pas dans le délai spécifié par la fenêtre de nouveau test, la condition est considérée comme remplie. Pour une règle d'alerte à une seule condition, un incident est ouvert lorsque celle-ci est remplie.Les points de données manquants sont traités comme des valeurs qui ne violent pas la condition du règlement. Les incidents ouverts sont fermés.
Aucun nouvel incident n'est ouvert.Pour les conditions remplies, la condition cesse de l'être lorsque les données cessent d'arriver. Si un incident est ouvert pour cette condition, il est fermé.
Pour les conditions qui ne sont pas remplies, elles continuent de ne pas l'être lorsque les données cessent d'arriver.
Cliquez sur Suivant.
Facultatif : Créez une règle d'alerte avec plusieurs conditions.
La plupart des règles surveillent un seul type de métrique. Par exemple, une règle peut surveiller le nombre d'octets écrits dans une instance de VM. Si vous souhaitez surveiller plusieurs types de métriques, créez une règle avec plusieurs conditions. Chaque condition surveille un type de métrique. Après avoir créé les conditions, vous devez spécifier comment elles sont combinées. Pour en savoir plus, consultez Règles comportant plusieurs conditions.
Pour créer une règle d'alerte à plusieurs conditions, procédez comme suit :
- Pour chaque condition supplémentaire, cliquez sur Ajouter une condition d'alerte, puis configurez cette condition.
- Cliquez sur Suivant et configurez la façon dont les conditions sont combinées.
- Cliquez sur Suivant pour passer à la configuration des notifications et de la documentation.
Configurez la notification et ajoutez des libellés utilisateur :
Développez le menu Notifications et nom, puis sélectionnez vos canaux de notification. À des fins de redondance, nous vous recommandons d'ajouter plusieurs types de canaux de notification à une règle d'alerte. Pour en savoir plus, consultez Gérer les canaux de notification.
Facultatif : Pour utiliser un objet personnalisé dans votre notification au lieu de l'objet par défaut, modifiez le champ Objet de la notification.
Facultatif : Pour recevoir une notification en cas de fermeture d'un incident, cochez la case Notifier en cas de fermeture des incidents. Par défaut, si vous créez une règle d'alerte avec la console Google Cloud , une notification n'est envoyée qu'à la création d'un incident.
(Facultatif) Pour modifier la durée pendant laquelle Monitoring attend avant de fermer un incident après l'arrêt de l'arrivée des données, sélectionnez une option dans le menu Durée de fermeture automatique des incidents. Par défaut, lorsque les données cessent d'arriver, Monitoring attend sept jours avant de fermer un incident ouvert.
Facultatif : Pour associer votre règle d'alerte à une application App Hub, dans la section Libellés d'application, sélectionnez une application, puis un service ou une charge de travail. Ces libellés s'affichent dans les incidents et les notifications.
Facultatif : Sélectionnez une option dans le menu Niveau de gravité de la règle. Le niveau de gravité s'affiche dans les incidents et les notifications.
Facultatif : Pour ajouter des libellés personnalisés à la règle d'alerte, dans la section Libellés utilisateur de la règle, procédez comme suit :
- Cliquez sur Ajouter un libellé, puis saisissez un nom pour le libellé dans le champ Clé. Les noms de libellés doivent commencer par une lettre minuscule et peuvent contenir des lettres minuscules, des chiffres, des traits de soulignement et des tirets.
Par exemple, saisissez
severity. - Cliquez sur Valeur, puis saisissez une valeur pour votre libellé. Les valeurs de libellé peuvent contenir des lettres minuscules, des chiffres, des traits de soulignement et des tirets.
Par exemple, saisissez
critical.
Pour savoir comment utiliser les libellés de règles pour gérer vos notifications, consultez Annoter les incidents avec des libellés.
- Cliquez sur Ajouter un libellé, puis saisissez un nom pour le libellé dans le champ Clé. Les noms de libellés doivent commencer par une lettre minuscule et peuvent contenir des lettres minuscules, des chiffres, des traits de soulignement et des tirets.
Par exemple, saisissez
Facultatif : Dans la section Documentation, saisissez le contenu à inclure dans la notification.
Pour mettre en forme votre documentation, vous pouvez utiliser du texte brut, le format Markdown et des variables. Vous pouvez également inclure des liens pour aider les utilisateurs à déboguer l'incident, comme des liens vers des playbooks internes, des tableaux de bord Google Cloud et des pages externes. Par exemple, le modèle de documentation suivant décrit un incident d'utilisation du processeur pour une ressource
gce_instanceet inclut plusieurs variables pour référencer les ressources REST de la règle d'alerte et de la condition. Le modèle de documentation redirige ensuite les lecteurs vers des pages externes pour les aider à déboguer.Lors de la création des notifications, Monitoring remplace les variables de documentation par leurs valeurs. Les valeurs remplacent les variables uniquement dans les notifications. Le volet d'aperçu et les autres emplacements dans la console Google Cloud n'affichent que le format Markdown.
Aperçu
## CPU utilization exceeded ### Summary The ${metric.display_name} of the ${resource.type} ${resource.label.instance_id} in the project ${resource.project} has exceeded 90% for over 15 minutes. ### Additional resource information Condition resource name: ${condition.name} Alerting policy resource name: ${policy.name} ### Troubleshooting and Debug References Repository with debug scripts: example.com Internal troubleshooting guide: example.com ${resource.type} dashboard: example.comFormat dans la notification
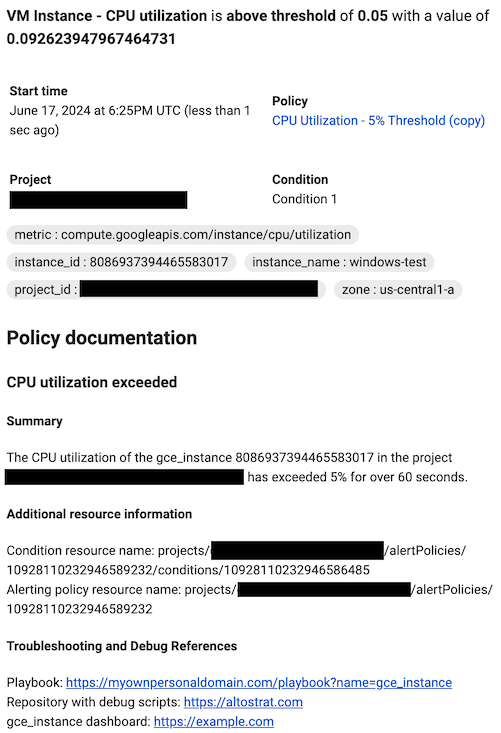
Pour en savoir plus, consultez Annoter les notifications avec une documentation définie par l'utilisateur et Utiliser des contrôles de canal.
Cliquez sur Nom de l'alerte et saisissez un nom pour la règle d'alerte.
Cliquez sur Créer une règle.
Filtrer la série temporelle sélectionnée
Les filtres permettent de s'assurer que seules les séries temporelles répondant à un ensemble de critères sont surveillées. Lorsque vous appliquez des filtres, vous pouvez réduire le nombre de lignes sur le graphique, ce qui peut améliorer ses performances. Vous pouvez également réduire la quantité de données surveillées en appliquant une agrégation. Les filtres permettent de s'assurer que seules les séries temporelles répondant à un ensemble de critères sont utilisées. Lorsque vous appliquez des filtres, il y a moins de séries temporelles à évaluer, ce qui peut améliorer les performances de l'alerte.
Un filtre est composé d'une étiquette, d'un comparateur et d'une valeur. Par exemple, pour faire correspondre toutes les séries temporelles dont le libellé zone commence par "us-central1", vous pouvez utiliser le filtre zone=~"us-central1.*", qui utilise une expression régulière pour effectuer la comparaison.
Lorsque vous filtrez par ID de projet ou par conteneur de ressources, vous devez utiliser l'opérateur d'égalité, (=). Lorsque vous filtrez par d'autres libellés, vous pouvez utiliser n'importe quel comparateur compatible.
En règle générale, vous pouvez filtrer les libellés de métriques et de ressources, ainsi que par groupe de ressources.
Lorsque vous fournissez plusieurs critères de filtrage, seules les séries temporelles qui répondent à tous les critères sont surveillées.
Pour ajouter un filtre, cliquez sur Ajouter un filtre, remplissez les champs de la boîte de dialogue, puis cliquez sur OK. Dans la boîte de dialogue, vous utilisez le champ Filtre pour sélectionner le critère de filtrage, l'opérateur de comparaison, puis la valeur. Le menu déroulant ne liste que les valeurs qui sont apparues au cours de la semaine dernière, mais vous pouvez saisir n'importe quelle valeur. Chaque ligne du tableau suivant liste un opérateur de comparaison, sa signification et un exemple :
| Opérateur | Signification | Exemple |
|---|---|---|
= |
Égalité | resource.labels.zone = "us-central1-a" |
!= |
Différent de | resource.labels.zone != "us-central1-a" |
=~ |
Égalité expression régulière2 | monitoring.regex.full_match("^us.*") |
!=~ |
Inégalité Expression régulière2 | monitoring.regex.full_match("^us.*") |
starts_with |
La valeur commence par | resource.labels.zone = starts_with("us") |
ends_with |
La valeur se termine par | resource.labels.zone = ends_with("b") |
has_substring |
La valeur contient | resource.labels.zone = has_substring("east") |
one_of |
Une | resource.labels.zone = one_of("asia-east1-b", "europe-north1-a") |
!starts_with |
La valeur ne commence pas par | resource.labels.zone != starts_with("us") |
!ends_with |
La valeur ne se termine pas par | resource.labels.zone != ends_with("b") |
!has_substring |
La valeur ne contient pas | resource.labels.zone != has_substring("east") |
!one_of |
La valeur n'est pas l'une des suivantes | resource.labels.zone != one_of("asia-east1-b", "europe-north1-a") |
Résoudre les problèmes
Cette section contient des conseils de dépannage.
La métrique ne figure pas dans le menu des métriques disponibles
Pour surveiller une métrique qui ne figure pas dans le menu Sélectionner une métrique, procédez de l'une des manières suivantes :
Pour créer une règle d'alerte qui surveille une métrique Google Cloud , développez le menu Sélectionner une métrique, puis cliquez sur Actif. Lorsque cette option est désactivée, le menu liste toutes les métriques pour les servicesGoogle Cloud , ainsi que toutes les métriques avec des données.
Pour configurer une condition pour un type de métrique personnalisé avant que ce type de métrique ne génère des données, vous devez spécifier le type de métrique à l'aide d'un filtre Monitoring :
- Sélectionnez ? dans l'en-tête de la section Sélectionner une métrique, puis sélectionnez Mode de filtrage direct dans l'info-bulle.
Saisissez un filtre de surveillance ou un sélecteur de série temporelle. Pour en savoir plus sur la syntaxe, consultez les documents suivants :
Surveiller un taux de variation
Pour surveiller le taux de variation de la valeur d'une métrique, définissez le champ Fonction de fenêtre glissante sur Variation en pourcentage. Lorsque la condition est évaluée, Monitoring calcule le taux de variation de la métrique en pourcentage, puis compare ce pourcentage au seuil de la condition. Ce processus de comparaison se déroule en deux étapes :
- Si la série temporelle a un type de métrique
DELTAouCUMULATIVE, elle est convertie en une série temporelle de typeGAUGE. Pour en savoir plus sur la conversion, consultez Genres, types et conversions. - La surveillance calcule le pourcentage de variation en comparant la valeur moyenne de la fenêtre glissante de 10 minutes la plus récente à la valeur moyenne de la fenêtre glissante de 10 minutes précédant le début de la période d'alignement.
Vous ne pouvez pas modifier la période glissante de 10 minutes utilisée pour les comparaisons dans une règle d'alerte de taux de variation. Cependant, c'est vous qui spécifiez la période d'alignement au moment de la création de la condition.
Étapes suivantes
- Pour créer une règle qui compare la valeur d'une série temporelle à un seuil dynamique, vous devez utiliser MQL. Pour en savoir plus, consultez Créer des niveaux de gravité dynamiques à l'aide de MQL.
Les instructions de cette page s'appliquent à toutes les règles d'alerte. Les documents suivants fournissent des conseils pour des configurations spécifiques :