Las tablas derivadas ofrecen un sinfín de posibilidades analíticas avanzadas, pero pueden ser difíciles de abordar, implementar y solucionar. Este libro de recetas contiene los casos prácticos más habituales de las tablas derivadas en Looker.
En esta página se incluyen los siguientes ejemplos:
- Crear una tabla a las 3:00 todos los días
- Añadir datos nuevos a una tabla grande
- Usar funciones de ventana de SQL
- Crear columnas derivadas para valores calculados
- Estrategias de optimización
- Usar PDTs para probar optimizaciones
UNIONdos tablas- Sumar una suma (añadir dimensiones a una medida)
- Tablas de resumen con notoriedad agregada
Recursos de tabla derivada
En estas guías se presupone que tienes conocimientos básicos sobre LookML y las tablas derivadas. Deberías saber cómo crear vistas y editar el archivo de modelo. Si quieres repasar alguno de estos temas, consulta los siguientes recursos:
- Tablas derivadas
- Términos y conceptos de LookML
- Crear tablas derivadas nativas
- Referencia del parámetro
derived_table - Almacenar en caché las consultas y volver a generar PDTs con grupos de datos
Crear una tabla a las 3:00 todos los días
En este ejemplo, los datos se reciben todos los días a las 2:00. Los resultados de una consulta sobre estos datos serán los mismos tanto si se ejecuta a las 3:00 como a las 21:00. Por lo tanto, es recomendable crear la tabla una vez al día y permitir que los usuarios obtengan los resultados de una caché.
Si incluye su grupo de datos en el archivo de modelo, podrá reutilizarlo con varias tablas y Exploraciones. Este grupo de datos contiene un parámetro sql_trigger_value que indica al grupo de datos cuándo debe activarse y volver a generar la tabla derivada.
Para ver más ejemplos de expresiones de activador, consulta la documentación de sql_trigger_value.
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
Añade el parámetro datagroup_trigger a la definición de derived_table en el archivo de vista y especifica el nombre del grupo de datos que quieras usar. En este ejemplo, el grupo de datos es standard_data_load.
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
Añadir datos nuevos a una tabla grande
Una PDT incremental es una tabla derivada persistente que Looker crea añadiendo datos nuevos a la tabla, en lugar de volver a crearla por completo.
En el siguiente ejemplo se usa la tabla orders para mostrar cómo se crea la tabla de forma incremental. Los datos de nuevos pedidos se reciben cada día y se pueden añadir a la tabla ya creada si añade los parámetros increment_key y increment_offset.
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
El valor increment_key se ha definido como created_at, que es el incremento de tiempo para el que se deben consultar los datos actualizados y añadirlos a la tabla derivada persistente en este ejemplo.
El valor increment_offset se define como 3 para especificar el número de periodos anteriores (con la granularidad de la clave de incremento) que se vuelven a generar para tener en cuenta los datos que llegan tarde.
Usar funciones de ventana de SQL
Algunos dialectos de bases de datos admiten funciones de ventana, sobre todo para crear números de secuencia, claves principales, totales acumulados y otros cálculos útiles de varias filas. Una vez que se ha ejecutado la consulta principal, las declaraciones derived_column se ejecutan en una pasada independiente.
Si el dialecto de tu base de datos admite funciones de ventana, puedes usarlas en tu tabla derivada nativa. Crea un parámetro derived_column con un parámetro sql que contenga tu función de ventana. Cuando hagas referencia a valores, debes usar el nombre de la columna tal como se define en tu tabla derivada nativa.
En el siguiente ejemplo se muestra cómo crear una tabla derivada nativa que incluya las columnas user_id, order_id y created_time. Después, usarías una columna derivada con una función de ventana SQL ROW_NUMBER() para calcular una columna que contenga el número de secuencia del pedido de un cliente.
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
Crear columnas derivadas para valores calculados
Puedes añadir parámetros derived_column para especificar columnas que no existan en la función Explorar del parámetro explore_source. Cada parámetro derived_column tiene un parámetro sql que especifica cómo crear el valor.
El cálculo de sql puede usar cualquier columna que haya especificado mediante parámetros column. Las columnas derivadas no pueden incluir funciones de agregación, pero sí cálculos que se pueden realizar en una sola fila de la tabla.
En este ejemplo se crea una columna average_customer_order, que se calcula a partir de las columnas lifetime_customer_value y lifetime_number_of_orders de la tabla derivada nativa.
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
Estrategias de optimización
Como los PDTs se almacenan en tu base de datos, debes optimizarlos siguiendo las estrategias que se indican a continuación, según lo permita tu dialecto:
Por ejemplo, para añadir persistencia, puede configurar el PDT para que se vuelva a compilar cuando se active el grupo de datos orders_datagroup y, a continuación, añadir índices en customer_id y first_order, como se muestra a continuación:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Si no añade un índice (o un equivalente para su dialecto), Looker le advertirá de que debe hacerlo para mejorar el rendimiento de las consultas.
Usar PDTs para probar optimizaciones
Puedes usar PDTs para probar diferentes opciones de indexación, distribución y otras opciones de optimización sin necesidad de recibir mucha asistencia de tus administradores de bases de datos o desarrolladores de ETL.
Supongamos que tienes una tabla, pero quieres probar diferentes índices. El LookML inicial de la vista puede ser similar al siguiente:
view: customer {
sql_table_name: warehouse.customer ;;
}
Para probar estrategias de optimización, puede usar el parámetro indexes para añadir índices a LookML, como se muestra a continuación:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Consulta la vista una vez para generar el PDT. Después, ejecuta las consultas de prueba y compara los resultados. Si los resultados son favorables, puedes pedirle a tu administrador de bases de datos o al equipo de ETL que añadan los índices a la tabla original.
UNION dos tablas
Puedes ejecutar un operador SQL UNION o UNION ALL en ambas tablas derivadas si tu dialecto de SQL lo admite. Los operadores UNION y UNION ALL combinan los conjuntos de resultados de dos consultas.
En este ejemplo se muestra el aspecto de una tabla derivada basada en SQL con un UNION:
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
La instrucción UNION del parámetro sql genera una tabla derivada que combina los resultados de ambas consultas.
La diferencia entre UNION y UNION ALL es que UNION ALL no elimina las filas duplicadas. Hay que tener en cuenta el rendimiento al usar UNION en lugar de UNION ALL, ya que el servidor de la base de datos debe hacer un trabajo adicional para eliminar las filas duplicadas.
Sumar una suma (añadir dimensiones a una medida)
Como regla general en SQL (y, por extensión, en Looker), no puedes agrupar una consulta por los resultados de una función de agregación (representada en Looker como medidas). Solo puedes agrupar por campos no agregados (representados en Looker como dimensiones).
Para agrupar por un agregado (por ejemplo, para obtener la suma de una suma), debe "dimensionalizar" una medida. Una forma de hacerlo es usar una tabla derivada, que crea una subconsulta del agregado.
A partir de una Exploración, Looker puede generar LookML para toda o la mayor parte de tu tabla derivada. Solo tienes que crear una exploración y seleccionar todos los campos que quieras incluir en la tabla derivada. A continuación, para generar el LookML de la tabla derivada nativa (o basada en SQL), sigue estos pasos:
Haz clic en el menú de rueda dentada de la exploración y selecciona Obtener LookML.
Para ver el LookML que se usa para crear una tabla derivada nativa de la exploración, haz clic en la pestaña Tabla derivada.
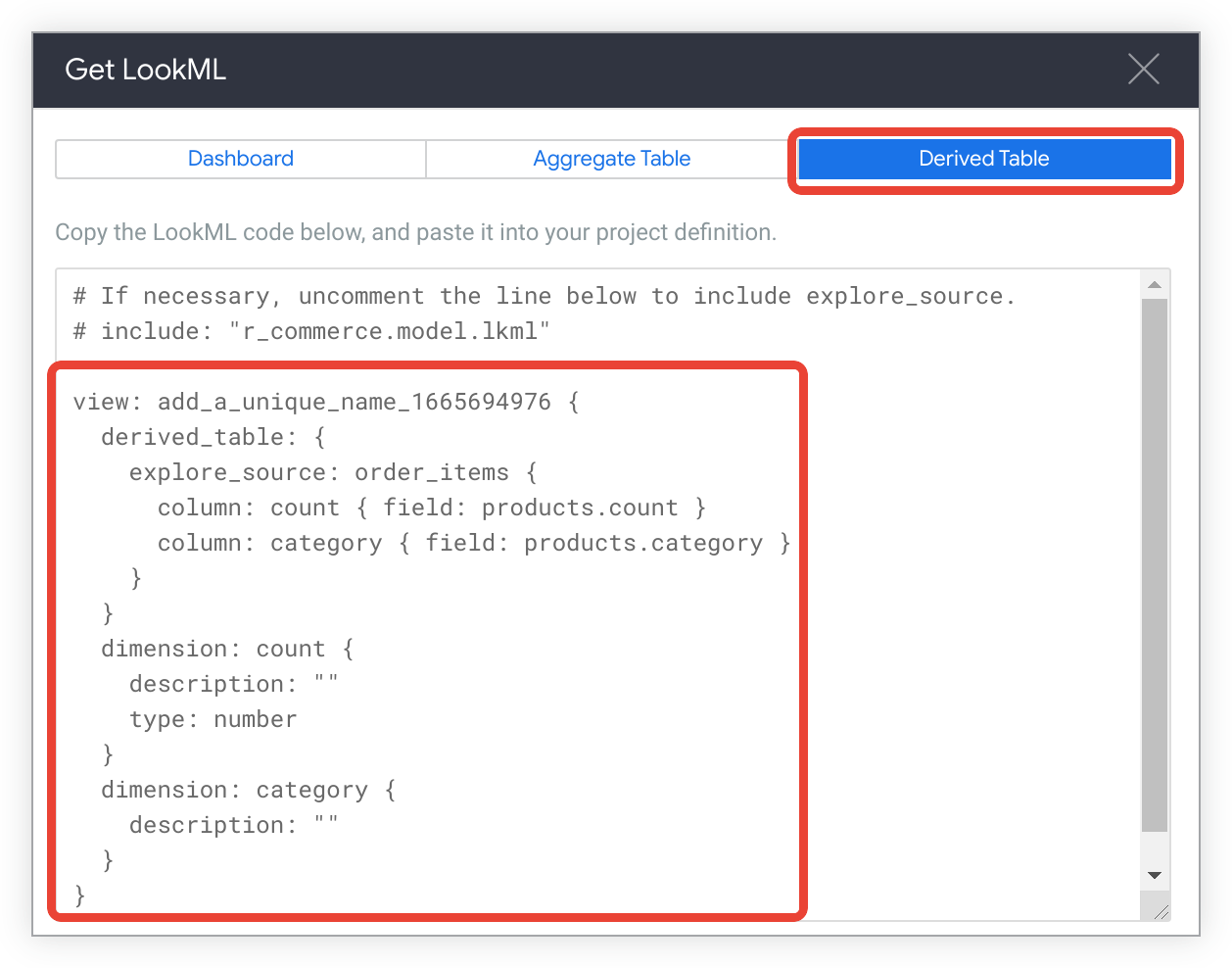
Copia el LookML.
Ahora que has copiado el LookML generado, pégalo en un archivo de vista siguiendo estos pasos:
En el modo Desarrollo, ve a los archivos del proyecto.
Haz clic en el icono + situado en la parte superior de la lista de archivos del proyecto en el IDE de Looker y selecciona Crear vista. También puedes crear el archivo en la carpeta. Para ello, haz clic en el menú de una carpeta y selecciona Crear vista.
Asigna un nombre descriptivo a la vista.
También puedes cambiar los nombres de las columnas, especificar columnas derivadas y añadir filtros.
Tablas de resumen con conocimiento de agregación
En Looker, es habitual encontrarse con conjuntos de datos o tablas muy grandes que, para ofrecer un buen rendimiento, requieren tablas de agregación o resúmenes.
Con la función de agregación de Looker, puede predefinir tablas agregadas con distintos niveles de granularidad, dimensionalidad y agregación, e indicar a Looker cómo usarlas en Exploraciones. Las consultas usarán estas tablas de resumen cuando Looker lo considere oportuno, sin que el usuario tenga que hacer nada. De esta forma, se reducirá el tamaño de las consultas, los tiempos de espera y se mejorará la experiencia de los usuarios.
A continuación, se muestra una implementación muy sencilla en un modelo de Looker para demostrar lo ligero que puede ser el reconocimiento de agregaciones. Supongamos que tienes una tabla de vuelos hipotética en la base de datos con una fila por cada vuelo registrado en la FAA. Puedes modelar esta tabla en Looker con su propia vista y Explore. A continuación, se muestra el código LookML de una tabla de datos agregados que puedes definir para la Exploración:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Con esta tabla agregada, un usuario puede consultar la exploración flights y Looker usará automáticamente la tabla agregada para responder a las consultas. Para obtener una guía más detallada sobre la visibilidad agregada, consulta el tutorial sobre la visibilidad agregada.