合并结果是一项便捷功能,可让您快速合并来自不同探索的数据,而无需在 LookML 中进行开发。合并后的结果会在主查询和次级查询之间有效执行左联接,这意味着字段名称、匹配值和最终结果表取决于次级查询中的数据与主查询的匹配方式。
这可能会导致您在探索之间执行合并时出现意外结果。“合并结果”文档介绍了其中的一些条件,例如:
不过,如果您希望次级查询中的值与主查询中的值匹配,但最终结果显示 null 值,该怎么办?
本页介绍了如何排查此意外结果。
用例示例
以下示例用例基于包含用户和订单信息的电子商务示例数据集。在此示例中,您需要将一个查询(按城市统计的用户数,用户数按用户所在的城市分组)与一个次级查询(按城市和用户所在的州统计的订单数,订单数按用户所在的城市和用户所在的州分组)合并:
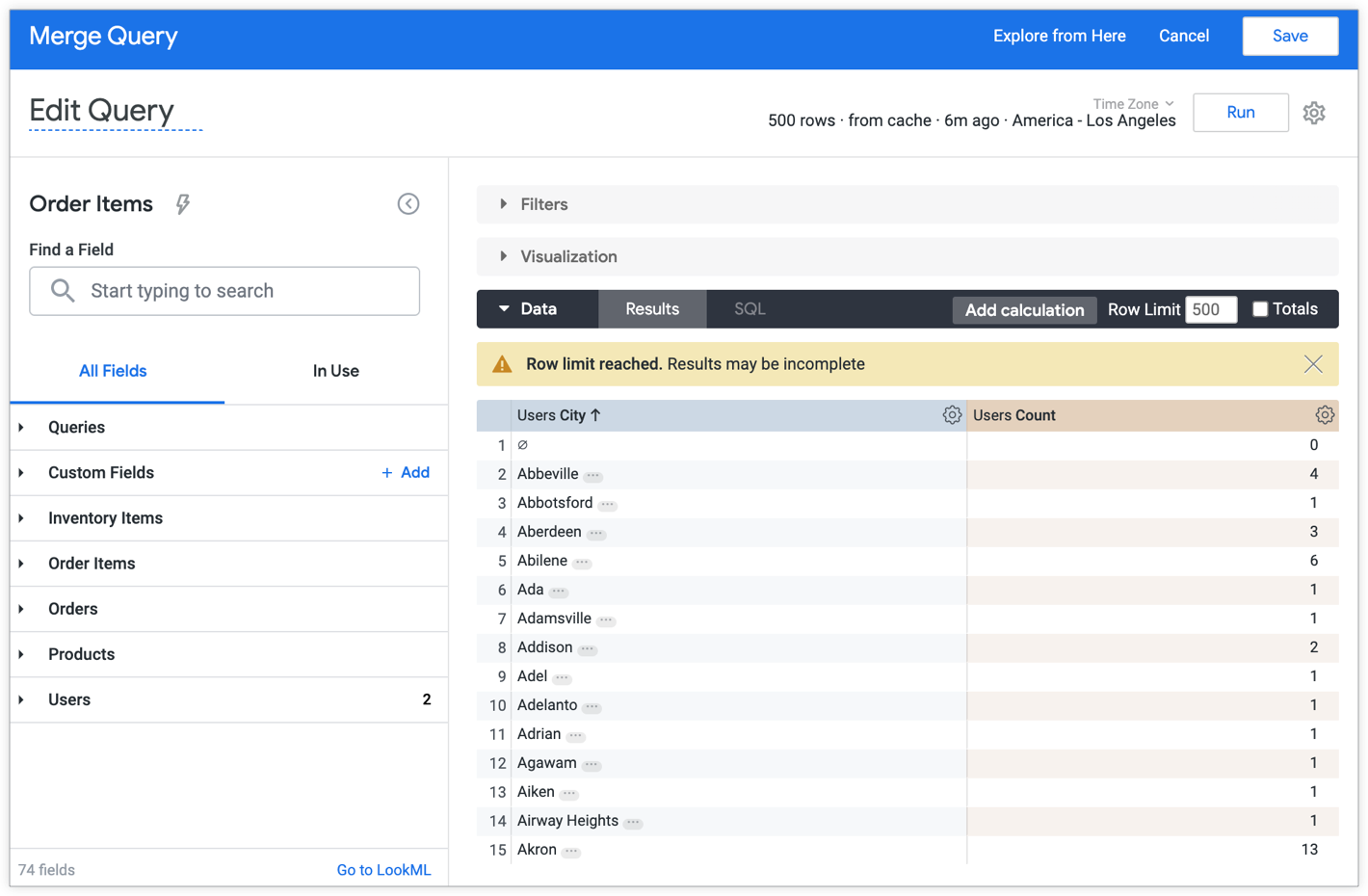
主要查询
主要查询是按用户所在的城市对用户数进行分组:
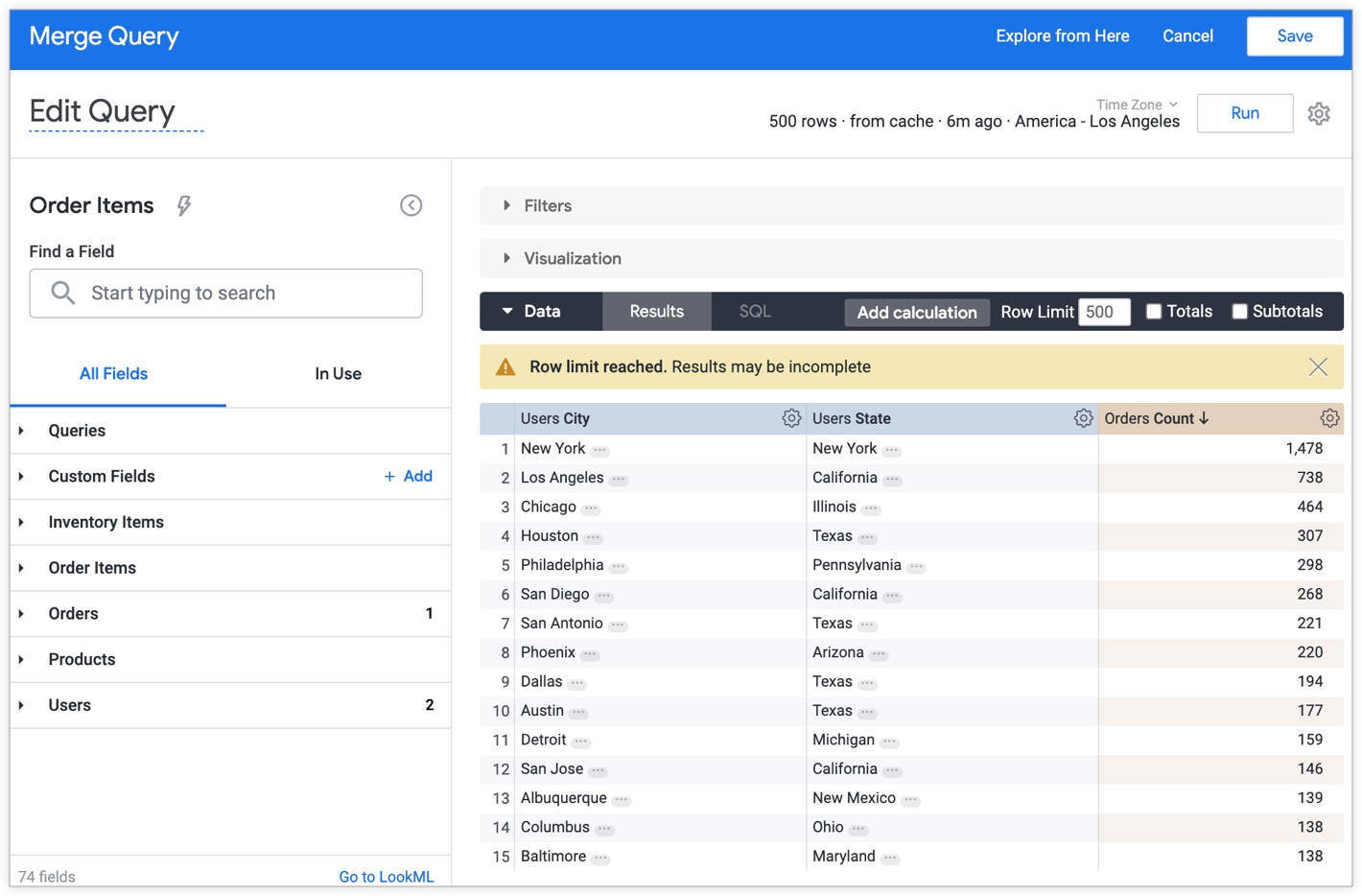
次要查询
次级查询是按用户所在的城市和用户所在的州对订单数量进行分组:
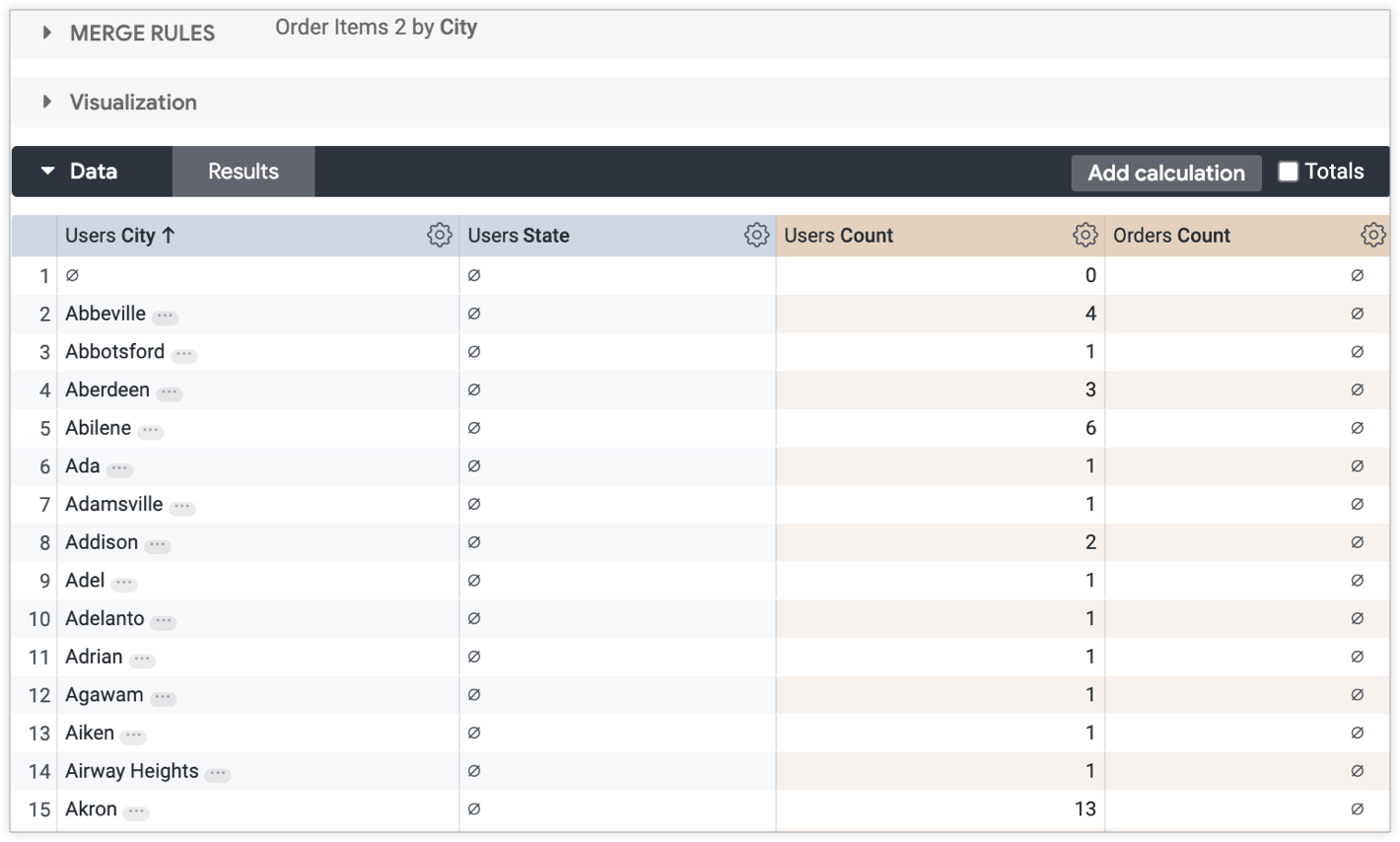
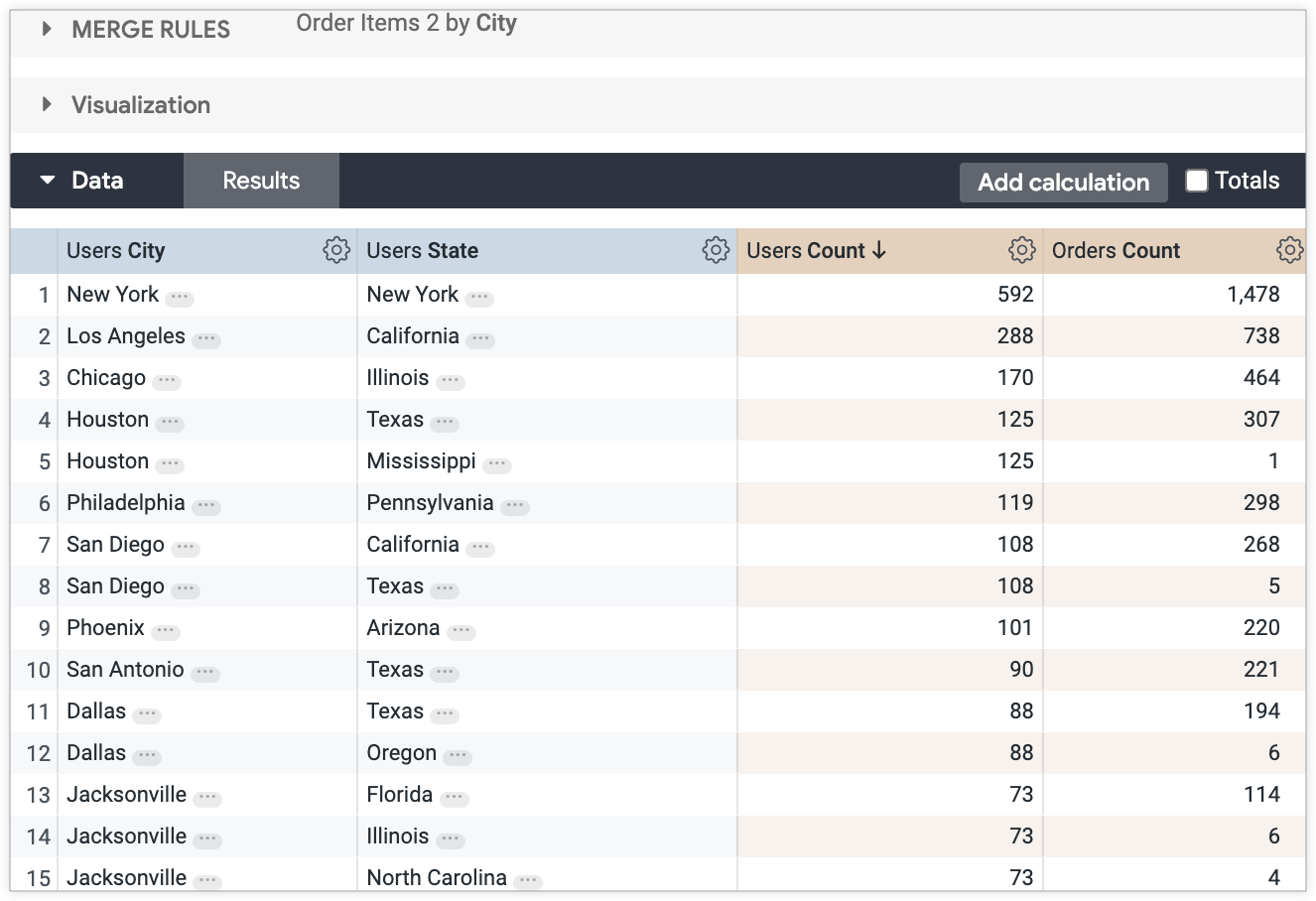
合并规则设置为按这两个查询共有的字段“用户所在的城市”合并这两个查询。由于您熟悉之前链接的文档中介绍的数据集和预期的合并结果行为,因此您知道,在每行中,每个城市都应与一个州和用户数相匹配。您希望合并后的结果与所有值匹配,并且不显示 null 值。
不过,结果中存在 null。超过一半的城市与州或订单数量不匹配:
解决方案
不用紧张。如果您确定数据中存在匹配值(请尝试运行单独的查询来确认这一点),则可以通过以下几种方法来解决此问题:
- 以相同的方式对每个来源查询进行排序。
- 提高来源查询行数限制。
以相同的方式对每个来源查询进行排序
由于合并的结果基于“探索”,而“探索”默认限制为 500 行,因此有时您要合并的查询结果不会包含在最终结果中。
要解决此问题,您可以修改和排序各个来源查询,以便它们更好地匹配。
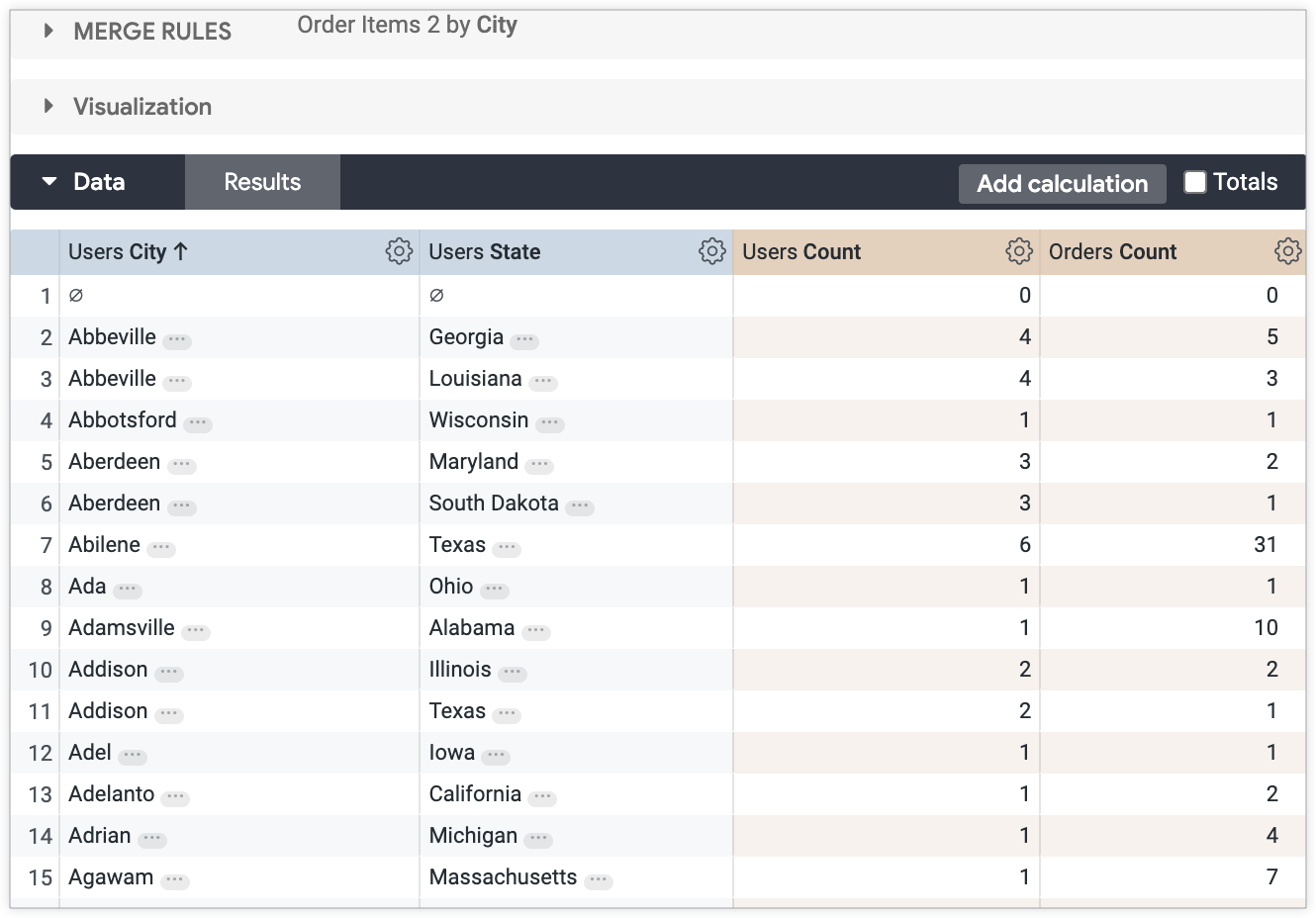
在示例用例中,主要查询按用户所在的城市从高到低排序。辅助查询则不受此限制。为了更好地匹配这两个查询的结果,您可以像对主要查询一样对次级查询进行排序,在本例中,按用户所在的城市从高到低排序。
将次级查询按与主查询类似的方式排序,可在最终合并时更准确地匹配结果:
提高来源查询行数上限
与前面介绍的第一种解决方案类似,意外 null 值也可能是由来源查询中设置的行数限制导致的。具体而言,在本例中,辅助查询(受默认 500 行的限制)的行数不足以匹配主查询生成的所有行,导致最终合并中显示 null 结果。
如需增加次级查询中的行数以与主查询相匹配,您可以增加次级查询行数上限。这样一来,与主查询匹配的行就可能更多,而次级查询列中的 null 值就可能更少:
摘要
如果遇到意外的合并结果,您可以按照以下步骤进行问题排查:
- 从“探索”的齿轮菜单中选择清除缓存并刷新选项,以确保查询会提取最新的结果。
- 确认显示 null 值的来源查询之间存在匹配的值,如“合并后的结果”文档的如果某个查询没有匹配的数据值,该怎么办?部分所述。
- 对来源查询进行排序,以便更好地匹配彼此。
- 将来源查询的行数上限提高到默认上限以上,以显示更多可匹配和合并的行。
- 如果这里讨论的所有解决方案都无法解决此行为,请尽可能将联接逻辑硬编码到 LookML 中,以获得更精确的结果。