This page explores the most common architecture patterns for a customer-hosted deployment and describes the best practices for implementing them. To use this page effectively, you should be familiar with system architecture concepts and practices.
Workflow strategy
After you identify self-hosting as a viable option for your implementation of Looker, the next step is to elaborate the strategy to be served by the deployment.
- Conduct an assessment. Identify a candidate list of planned and existing workflows.
- List applicable architecture patterns. Starting with the identified candidate workflows, identify applicable architectural patterns.
- Prioritize and select the optimal architecture pattern. Align the architecture pattern with the most important tasks and outcomes.
- Configure the architectural components and deploy the Looker application. Implement the host, third-party dependencies, and network topology needed to establish secure client connections.
Architecture options
Dedicated virtual machine
One option is to run Looker as a single instance in a dedicated virtual machine (VM). A single instance can serve demanding workloads by vertically scaling the host and increasing the default thread pools. However, the processing overhead of managing a large Java heap subjects vertical scaling to the law of diminishing returns. It's generally acceptable for small to medium workloads. The following diagram depicts the default and optional setups between a Looker instance that is running in a dedicated VM, the local and remote repositories, the SMTP servers, and the data sources that are highlighted in the Advantages and Best practices sections for this option.
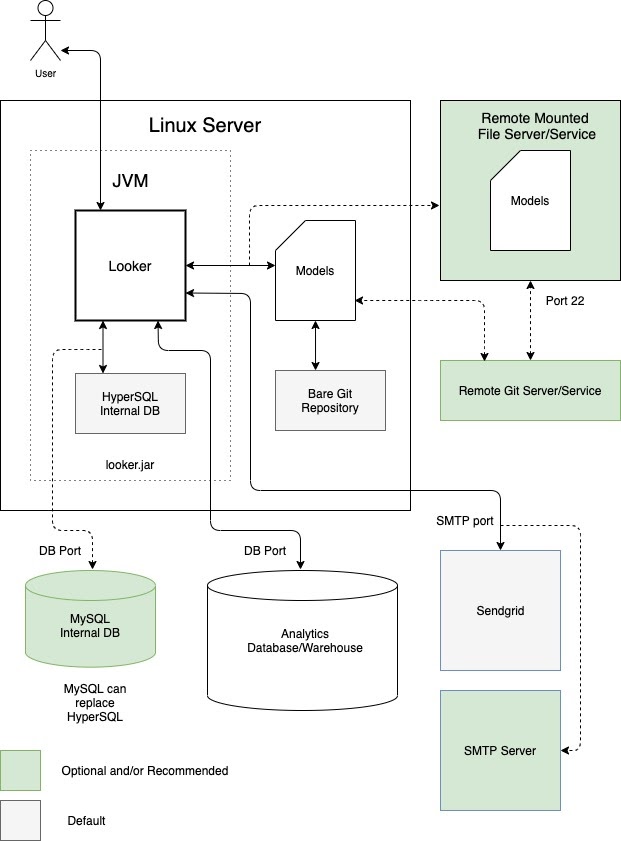
Advantages
- A dedicated VM is easy to deploy and maintain.
- The internal database is hosted within the Looker application.
- The Looker models, Git repository, SMTP server, and backend database components can be configured locally or remotely.
- You can replace Looker's default SMTP server with your own for email notifications and scheduled tasks.
Best practices
- By default, Looker can generate bare Git repositories for a project. We recommend that a remote Git repository be set up for redundancy.
-
By default, Looker starts with an in-memory HyperSQL database. This database is convenient and lightweight, but can experience performance issues with heavy use. We recommend the use of a MySQL database for larger deployments. We recommend migration to a remote MySQL database once the
~/looker/.db/looker.scriptfile reaches 600 MB. - Your Looker deployment will need to validate against the Looker licensing service; outbound traffic on port 443 is required.
- A dedicated VM deployment can be scaled vertically by increasing available resources and Looker thread pools. However, increasing RAM is subject to the law of diminishing returns once it reaches 64 GB, as garbage collection events are single threaded and halt all other threads to execute. Nodes with 16 CPUs and 64 GB of RAM is a good balance between price and performance.
- We recommend that your deployment have storage with 2 operations per second (IOPS) per GB.
Cluster of VMs
Running Looker as a cluster of instances across multiple VMs is a flexible pattern that benefits from service failover and redundancy. Horizontal scalability affords increased throughput without running into heap bloat and excessive garbage collection costs. Nodes have the option of workload dedication, which allows multiple deployment options to be tailored to different business requirements. Cluster deployments require at least one system administrator who is familiar with Linux systems and capable of managing the component parts.
Standard cluster
For most standard deployments, a cluster of identical service nodes is sufficient. All nodes in the cluster are configured the same way and are all in the same load-balancer pool. None of the nodes in this configuration would be any more or less likely to serve Looker user requests, a rendering task, a scheduled task, an API request, etc.
This kind of configuration is suitable when the majority of requests are coming directly from a Looker user who is running queries and interacting with Looker. It starts to break down when a large number of requests are coming from a scheduler, a renderer, or another source. In this case, it is beneficial to designate certain service nodes to handle tasks such as schedules and rendering.
For example, users will commonly schedule data deliveries to run on Monday morning. A user trying to run Looker queries on Monday morning may experience performance issues while Looker works on the backlog of scheduled requests. By increasing the number of service nodes, the cluster provides a proportional lift in throughput across all of Looker's capabilities.
The following diagram depicts how requests to Looker that are made from the user, apps, and scripts balance across a clustered Looker instance.
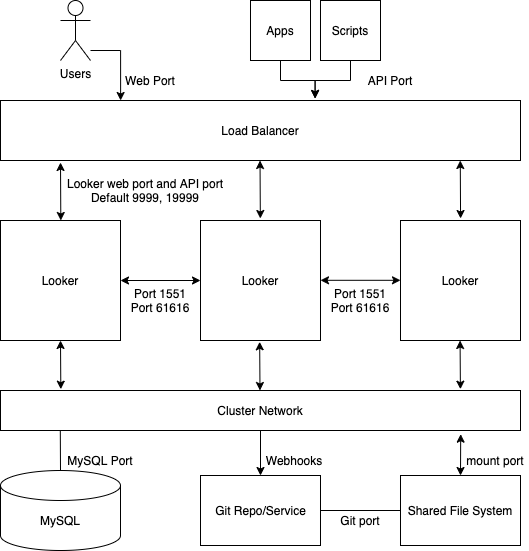
Advantages
- A standard cluster maximizes general throughout with minimal configuration of the cluster topology.
- The Java VM suffers performance degradation at the 64 GB allocated memory threshold; this is why horizontal scaling has greater returns than vertical scaling.
- A cluster configuration ensures service redundancy and failover.
Best practices
- Each Looker node should be hosted in its own dedicated VM.
- The load balancer, which is the cluster ingress point, should be a layer 4 load balancer. It should have a long timeout (3,600 seconds), be equipped with a signed SSL certificate, and be configured to port forward from 443 (https) to 9999 (port Looker server listens on).
- We recommend that your deployment have storage with 2 IOPS per GB.
Dev/Staging/Prod
For use cases that prioritize maximum content uptime to end users, we recommend separate Looker environments to compartmentalize development work and analytical work. By gating production environment changes behind isolated development and testing environments, this architecture maintains a production environment that is as stable as possible.
These benefits require the setup of the inter-connected environments and adoption of a robust release cycle. A Dev/Staging/Prod deployment also requires a team of developers who are familiar with the Looker API and Git for workflow administration.
The following diagram depicts the flow of content between LookML developers who develop content on the Dev instance, quality assurance (QA) testers who test the content on the QA instance, and users, apps, and scripts that consume the content on the Production instance.
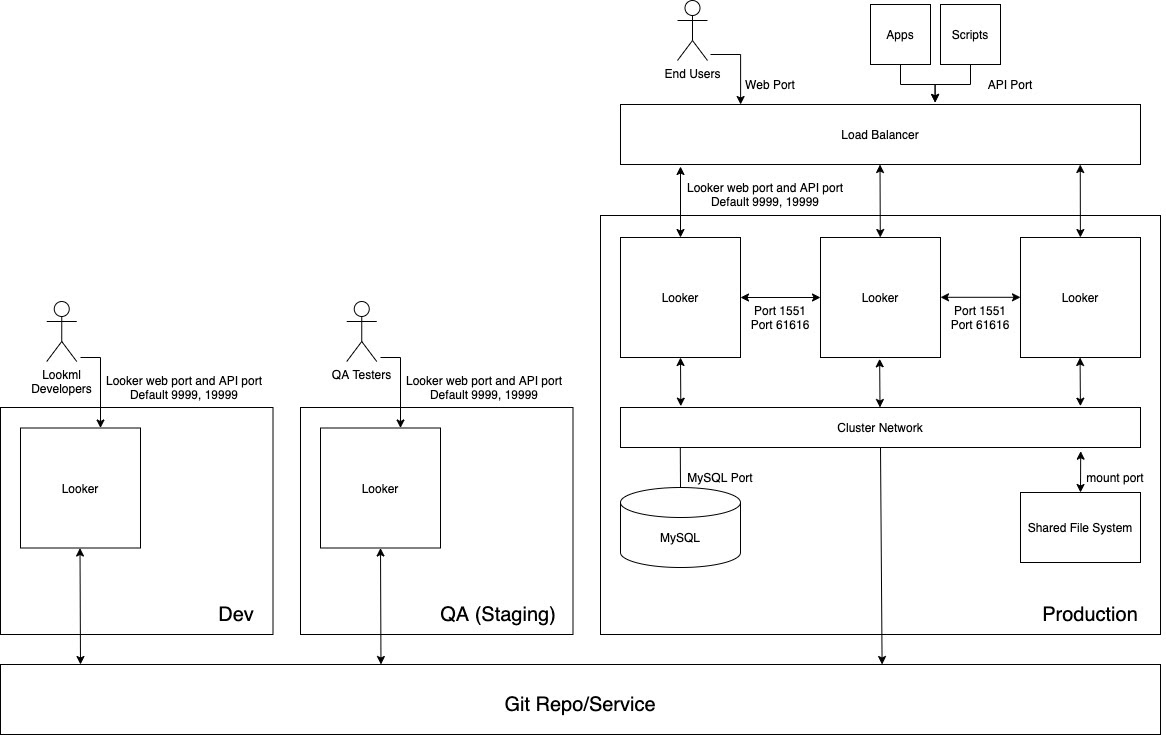
Advantages
- LookML and content validation occurs in a non-production environment, ensuring that any modifications to the model logic can be thoroughly vetted before reaching production users.
- Instance-wide features, such as Labs features or authentication protocols, can be tested in isolation before being enabled in the production environment.
- Datagroup and caching policies can be tested in a non-production environment.
- Looker production mode testing is decoupled from production environments that are responsible for serving end users.
- Looker releases can be tested in a non-production environment, giving ample time to test new features, workflow changes, and issues before updating the production environment.
Best practices
- Isolate the various activities occurring concurrently in at least three separate instances:
- Development instance: Developers use the development environment to commit code, conduct experiments, fix bugs, and safely make mistakes.
- QA instance: Also referred to as a test or a staging environment, this is where developers run manual and automated tests. The QA environment is complex and can consume a lot of resources.
- Production instance: This is where value is created for customers and/or the business. Production is a highly visible environment and should be free of errors.
- Maintain a documented, repeatable release cycle workflow.
- If it's necessary to serve high volumes of developers and QA testers, the Dev and/or QA instances can be clustered. Whether left as a standalone VM or cluster of VMs, the Dev and QA instances are subject to the same architectural considerations previously showcased in the respective sections.
High scheduling throughput
For use cases that require high scheduled data delivery throughput and timely, reliable deliveries, we recommend that the configuration include a cluster with a pool of nodes that are solely dedicated to scheduling. This configuration will help keep the web and embedded applications fast and responsive. These benefits require setting up nodes with customized startup options and proper load-balancing rules, as depicted in the following diagram and outlined in the Advantages and Best practices sections for this option.
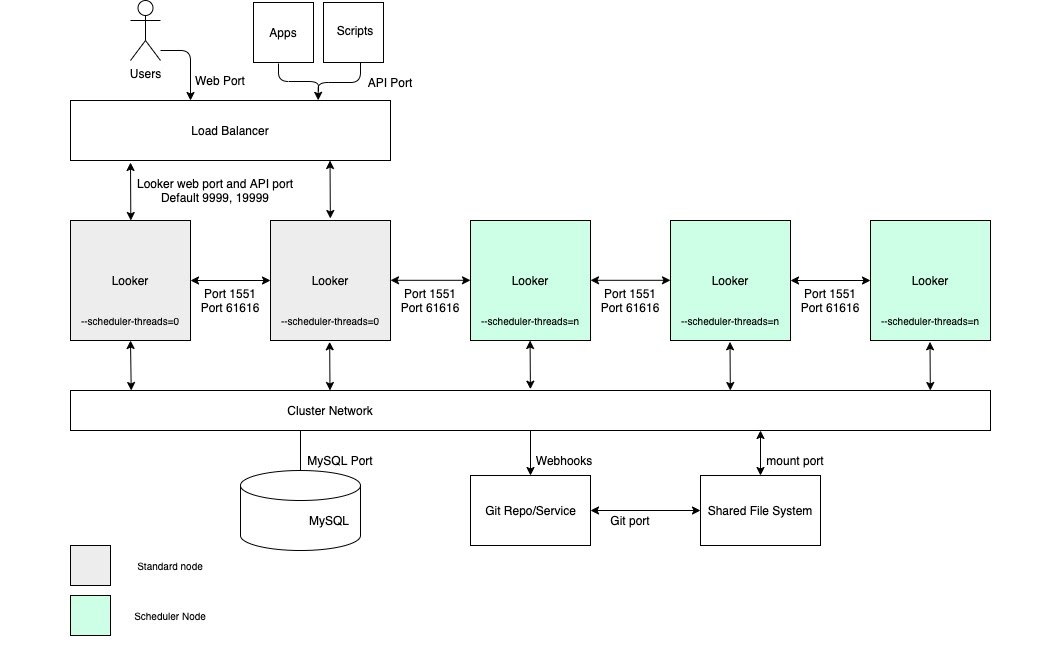
Advantages
- Dedicating nodes for a specific function compartmentalizes resources for scheduling from development and ad hoc analytics functions.
- Users can develop LookML and explore content without taking cycles from nodes responsible for servicing scheduled data deliveries.
- High user traffic funneled to the regular nodes does not impede scheduled workloads serviced by scheduling nodes.
Best practices
- Each Looker node should be hosted in its own dedicated VM.
- The load balancer, which is the cluster ingress point, should be a layer 4 load balancer. It should have a long timeout (3,600 seconds), be equipped with a signed SSL certificate, and be configured to port forward from 443 (https) to 9999 (port Looker server listens on).
- Omit scheduler nodes from load-balancing rules so they do not serve end user traffic and internal API requests.
- We recommend that your deployment have storage with 2 IOPS per GB.
High rendering throughput
For use cases that require high rendering report throughput, we recommend configuring a cluster with a pool of nodes that are solely dedicated to rendering. Rendering a PDF file or a PNG/JPEG image is a relatively resource costly operation in Looker. Rendering can be memory intensive and CPU heavy, and when Linux is under memory pressure it could kill a running process. Since the memory usage of a render job can't be determined ahead of time, kicking off a render job could result in the Looker process getting killed. Configuring dedicated rendering nodes will allow for optimal tuning of render jobs while also preserving the responsiveness of the interactive and embedded application.
These benefits require setting up nodes with customized startup options and proper load-balancing rules as depicted in the following diagram and explained in the Advantages and Best practices sections for this option. Additionally, rendering nodes may require more host resources than standard nodes, as Looker's rendering service depends on third-party Chromium processes sharing CPU time and memory.
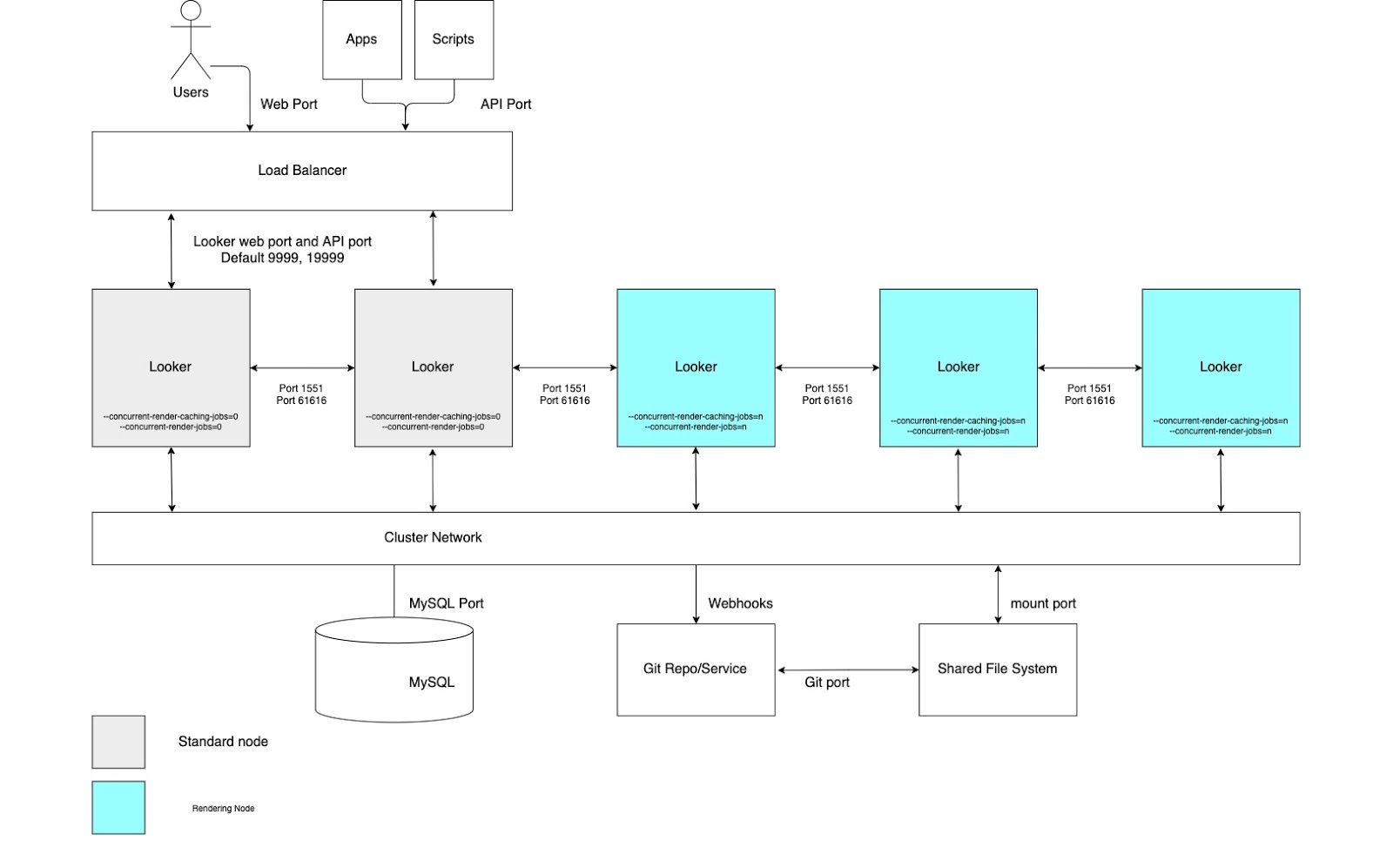
Advantages
- Dedicating nodes for a specific function compartmentalizes resources for rendering from development and ad hoc analytics functions.
- Users can develop LookML and explore content without taking cycles from the nodes that are responsible for rendering PNGs and PDFs.
- High user traffic funneled to the regular nodes does not impede rendering workloads that are serviced by rendering nodes.
Best practices
- Each Looker node should be hosted in its own dedicated VM.
- The load balancer, which is the cluster ingress point, should be a layer 4 load balancer. It should have a long timeout (3,600 seconds), be equipped with a signed SSL certificate, and be configured to port forward from 443 (https) to 9999 (port Looker server listens on).
- Omit rendering nodes from load-balancing rules, so they do not serve end user traffic and internal API requests.
- Allocate relatively less memory to Java in the rendering nodes to give Chromium's processes a larger memory buffer. Instead of allocating 60% of memory to Java, allocate 40-50%.
- The risk of memory pressure has been reduced on the non-render nodes, so the amount of memory dedicated to Looker can be increased. Instead of the default 60%, consider a higher number like 80%.
- We recommend that your deployment have storage with 2 IOPS per GB.