이 페이지에서는 고객 호스팅 배포에 사용되는 가장 일반적인 아키텍처 패턴을 살펴보고 이를 구현하기 위한 권장사항을 설명합니다. 이 페이지를 효과적으로 사용하려면 시스템 아키텍처 개념과 사례를 잘 알고 있어야 합니다.
워크플로 전략
Looker 구현에서 자체 호스팅을 실행할 수 있는 옵션으로 식별한 후에는 배포를 통해 제공할 전략을 설정할 수 있습니다.
- 평가를 실시합니다. 계획된 워크플로와 기존 워크플로의 후보 목록을 식별합니다.
- 적용 가능한 아키텍처 패턴을 나열합니다. 파악한 후보 워크플로에서부터 적용 가능한 아키텍처 패턴을 파악합니다.
- 최적의 아키텍처 패턴에 우선순위를 지정하고 선택합니다. 아키텍처 패턴을 가장 중요한 작업과 결과에 맞춥니다.
- 아키텍처 구성요소를 구성하고 Looker 애플리케이션을 배포합니다. 보안 클라이언트 연결을 설정하는 데 필요한 호스트, 서드 파티 종속 항목, 네트워크 토폴로지를 구현합니다.
아키텍처 옵션
전용 가상 머신
한 가지 옵션은 Looker를 전용 가상 머신(VM)에서 단일 인스턴스로 실행하는 것입니다. 단일 인스턴스는 호스트를 수직으로 확장하고 기본 스레드 풀을 늘려 까다로운 워크로드를 처리할 수 있습니다. 그러나 대규모 자바 힙을 관리하는 데 드는 처리 오버헤드는 수확 체감 법칙에 따라 수직 확장이 이루어집니다. 일반적으로 중소 규모의 워크로드에 적합합니다. 다음 다이어그램은 전용 VM에서 실행되는 Looker 인스턴스, 로컬 및 원격 저장소, SMTP 서버, 이 옵션의 장점 및 권장사항 섹션에 강조표시된 데이터 소스 간의 기본 설정 및 선택적 설정을 보여줍니다.
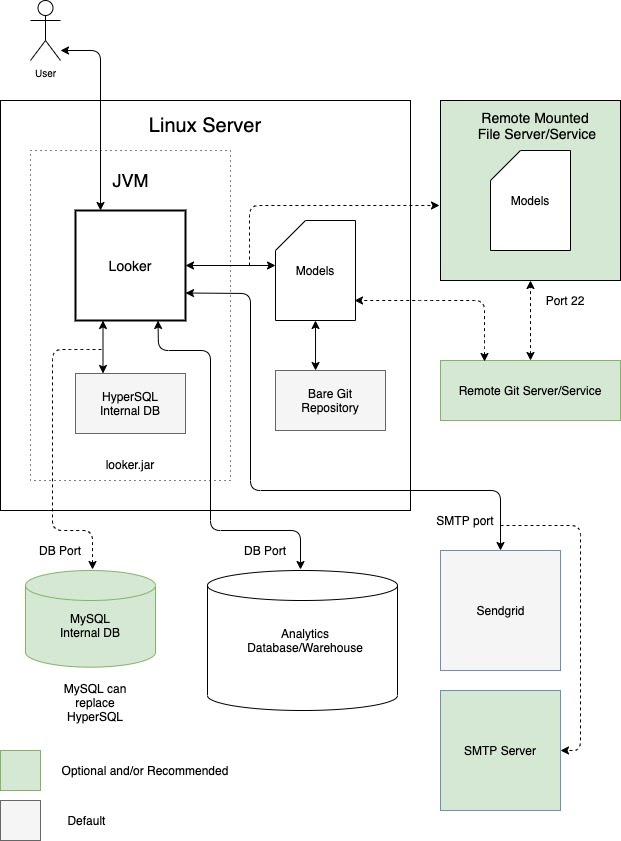
장점
- 전용 VM은 배포 및 유지관리가 쉽습니다.
- 내부 데이터베이스는 Looker 애플리케이션 내에서 호스팅됩니다.
- Looker 모델, Git 저장소, SMTP 서버, 백엔드 데이터베이스 구성요소를 로컬에서 또는 원격으로 구성할 수 있습니다.
- 이메일 알림 및 예약된 작업을 위해 Looker의 기본 SMTP 서버를 자체 서버로 대체할 수 있습니다.
권장사항
- 기본적으로 Looker는 프로젝트의 기본 Git 저장소를 생성할 수 있습니다. 중복화를 위해 원격 Git 저장소를 설정하는 것이 좋습니다.
-
기본적으로 Looker는 메모리 내 HyperSQL 데이터베이스로 시작합니다. 이 데이터베이스는 편리하고 가볍지만 많이 사용하면 성능 문제가 발생할 수 있습니다. 대규모 배포에는 MySQL 데이터베이스를 사용하는 것이 좋습니다.
~/looker/.db/looker.script파일이 600MB에 도달하면 원격 MySQL 데이터베이스로 마이그레이션하는 것이 좋습니다. - Looker 배포 시 Looker 라이선스 서비스를 검증해야 합니다. 포트 443의 아웃바운드 트래픽이 필요합니다.
- 사용 가능한 리소스와 Looker 스레드 풀을 늘려 전용 VM 배포를 수직으로 확장할 수 있습니다. 그러나 가비지 컬렉션 이벤트는 단일 스레드이고 다른 모든 스레드가 실행을 중지하므로 RAM을 늘리고 64GB에 도달하면 수확 체감 법칙이 적용됩니다. 16개 CPU와 64GB RAM이 있는 노드는 가격과 성능 사이에서 적절한 균형을 이룹니다.
- 배포에는 GB당 초당 작업 수(IOPS)가 2개인 스토리지가 있는 것이 좋습니다.
VM 클러스터
여러 VM에서 인스턴스 클러스터로 Looker를 실행하는 것은 서비스 장애 조치 및 중복의 이점을 활용하는 유연한 패턴입니다. 수평 확장성을 통해 힙 블로트 및 과도한 가비지 컬렉션 비용 발생 없이 처리량을 높일 수 있습니다. 노드에는 다양한 비즈니스 요구사항에 맞는 여러 배포 옵션을 맞춤설정할 수 있는 워크로드 전용 옵션이 있습니다. 클러스터 배포에는 Linux 시스템에 익숙하고 구성요소 부분을 관리할 수 있는 시스템 관리자가 한 명 이상 필요합니다.
표준 클러스터
대부분의 표준 배포에서는 동일한 서비스 노드의 클러스터로 충분합니다. 클러스터의 모든 노드는 같은 방식으로 구성되며 모두 같은 부하 분산기 풀에 있습니다. 이 구성의 노드는 Looker 사용자 요청, 렌더링 작업, 예약된 작업, API 요청 등을 제공할 가능성이 비등비등합니다.
이 유형의 구성은 대부분의 요청이 쿼리를 실행하고 Looker와 상호작용하는 Looker 사용자로부터 직접 발생하는 경우에 적합합니다. 스케줄러, 렌더러 또는 다른 소스에서 대량의 요청이 들어오면 분류가 시작됩니다. 이 경우 일정 및 렌더링과 같은 작업을 처리하도록 특정 서비스 노드를 지정하는 것이 좋습니다.
예를 들어 사용자는 일반적으로 데이터 전송이 월요일 아침에 실행되도록 예약합니다. 사용자가 월요일 아침에 Looker 쿼리를 실행하려고 하면 Looker에서 예약된 요청의 백로그를 처리하는 동안 성능 문제가 발생할 수 있습니다. 서비스 노드 수를 늘리면 클러스터에서 모든 Looker 기능에 비례하여 처리량을 늘립니다.
다음 다이어그램은 사용자, 앱, 스크립트에서 실행된 Looker에 대한 요청이 클러스터링된 Looker 인스턴스에서 어떻게 균형을 이루는지 보여줍니다.
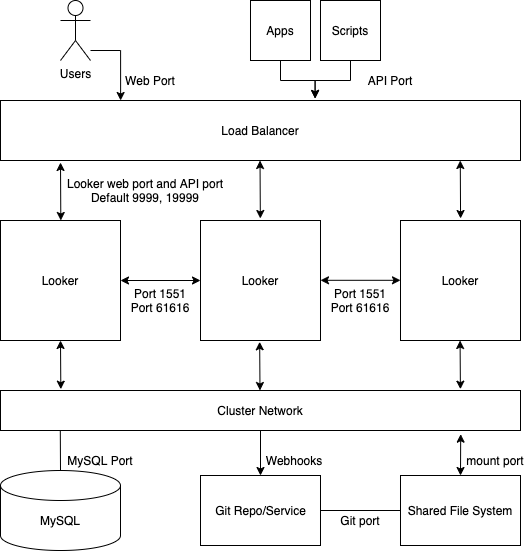
장점
- 표준 클러스터는 클러스터 토폴로지의 구성을 최소한으로 설정하여 전체적으로 최대화합니다.
- 자바 VM은 64GB 할당 메모리 임곗값에서 성능 저하를 보입니다. 이 때문에 수평 확장이 수직 확장보다 더 높은 수익을 달성합니다.
- 클러스터 구성은 서비스 중복성 및 장애 조치를 보장합니다.
권장사항
- 각 Looker 노드는 자체 전용 VM에서 호스팅되어야 합니다.
- 클러스터 인그레스 지점인 부하 분산기는 레이어 4 부하 분산기여야 합니다. 시간 제한(3,600초)이 길고 서명된 SSL 인증서가 있어야 하며 443(https)에서 9999(포트 Looker 서버 수신 대기)로 포트를 전달하도록 구성해야 합니다.
- 배포에는 GB당 IOPS가 2개인 스토리지가 있는 것이 좋습니다.
개발/스테이징/프로덕션
최종 사용자에게 최대 콘텐츠 업타임을 우선시하는 사용 사례의 경우 개발 작업과 분석 작업을 분류할 수 있는 별도의 Looker 환경을 사용하는 것이 좋습니다. 이 아키텍처는 격리된 개발 및 테스트 환경 뒤에서 프로덕션 환경 변경사항을 제어하여 최대한 안정적인 프로덕션 환경을 유지합니다.
이러한 이점을 얻으려면 상호 연결된 환경을 설정하고 강력한 출시 주기를 도입해야 합니다. 개발/스테이징/프로덕션 배포를 위해서는 워크플로 관리를 위해 Looker API 및 Git에 익숙한 개발자 팀도 필요합니다.
다음 다이어그램은 Dev 인스턴스에서 콘텐츠를 개발하는 LookML 개발자, QA 인스턴스에서 콘텐츠를 테스트하는 품질 보증(QA) 테스터, Production 인스턴스에서 콘텐츠를 사용하는 사용자/앱/스크립트 간의 콘텐츠 흐름을 보여줍니다.

장점
- LookML과 콘텐츠 검증은 비프로덕션 환경에서 이루어지므로, 프로덕션 사용자에게 도달하기 전에 모델 논리에 대한 수정이 철저한 검증을 거칠 수 있습니다.
- 실험실 기능 또는 인증 프로토콜과 같은 인스턴스 전체 기능을 프로덕션 환경에서 사용 설정하기 전에 개별적으로 테스트할 수 있습니다.
- 데이터 그룹 및 캐싱 정책은 비프로덕션 환경에서 테스트할 수 있습니다.
- Looker 프로덕션 모드 테스트는 최종 사용자 제공을 담당하는 프로덕션 환경과 분리됩니다.
- Looker 출시는 비프로덕션 환경에서 테스트할 수 있으므로 프로덕션 환경을 업데이트하기 전에 새로운 기능, 워크플로 변경사항, 문제를 충분히 테스트할 수 있습니다.
권장사항
- 최소 3개의 개별 인스턴스에서 동시에 발생하는 다양한 활동을 분리합니다.
- 개발 인스턴스: 개발자는 개발 환경을 사용하여 코드를 커밋하고, 실험을 수행하고, 버그를 수정하고, 안전하게 실수할 수 있습니다.
- QA 인스턴스: 테스트 또는 스테이징 환경이라고도 하며, 이곳에서 개발자가 수동 및 자동 테스트를 실행합니다. QA 환경은 복잡하며 많은 리소스를 소비할 수 있습니다.
- 프로덕션 인스턴스: 고객 또는 비즈니스에 가치를 창출합니다. 프로덕션은 눈에 잘 띄는 환경이므로 오류가 없어야 합니다.
- 문서화되고 반복 가능한 출시 주기 워크플로를 유지합니다.
- 많은 개발자와 QA 테스터를 대상으로 해야 하는 경우 Dev 또는 QA 인스턴스를 클러스터링할 수 있습니다. 독립형 VM이나 VM 클러스터로 남겨도 Dev 및 QA 인스턴스에는 앞의 각 섹션에서 설명한 것과 동일한 아키텍처 고려사항이 적용됩니다.
높은 예약 처리량
높은 예약 데이터 전송 처리량과 시의적절하고 안정적인 전송이 필요한 사용 사례의 경우, 오로지 예약 전용 노드 풀이 있는 클러스터를 구성에 포함하는 것이 좋습니다. 이 구성을 사용하면 웹 및 삽입된 애플리케이션을 빠르고 효율적으로 유지할 수 있습니다. 이러한 이점을 활용하려면 다음 다이어그램과 이 옵션의 장점 및 권장사항 섹션에 설명된 대로 맞춤설정된 시작 옵션과 적절한 부하 분산 규칙을 사용하여 노드를 설정해야 합니다.
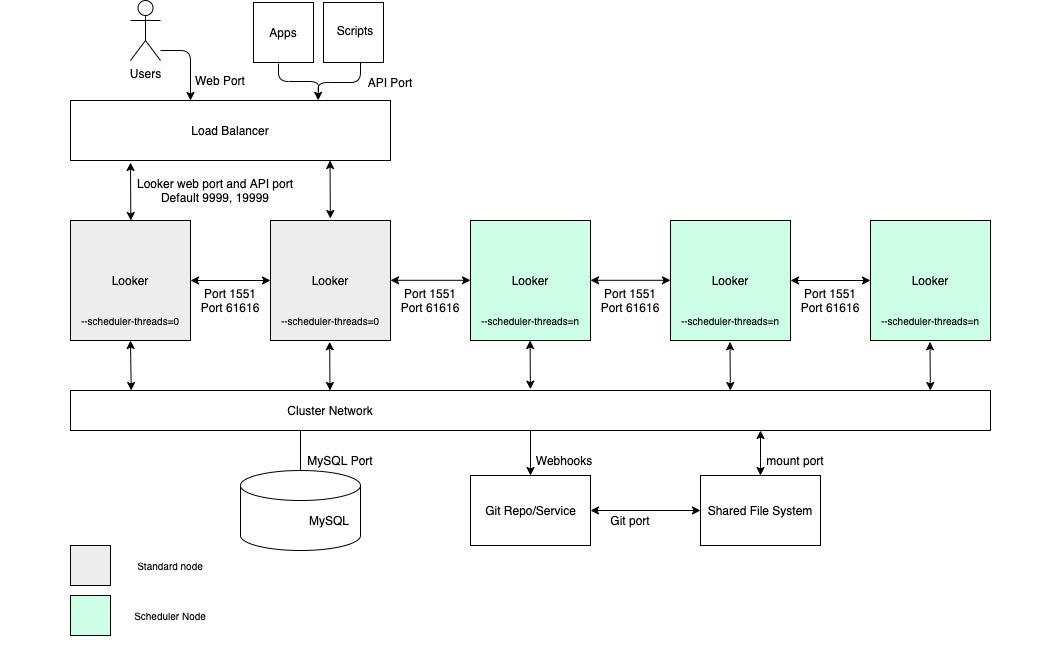
장점
- 특정 함수에 노드를 지정하는 것은 개발 및 임시 분석 함수에서 일정을 예약하는 데 필요한 리소스를 분류합니다.
- 사용자는 예약된 데이터 전송을 제공하는 역할을 하는 노드에서 순환 없이 LookML을 개발하고 콘텐츠를 탐색할 수 있습니다.
- 일반 노드로 유입되는 사용자 트래픽이 많아도 노드를 예약하여 처리되는 예약된 워크로드를 방해하지 않습니다.
권장사항
- 각 Looker 노드는 자체 전용 VM에서 호스팅되어야 합니다.
- 클러스터 인그레스 지점인 부하 분산기는 레이어 4 부하 분산기여야 합니다. 시간 제한(3,600초)이 길고 서명된 SSL 인증서가 있어야 하며 443(https)에서 9999(포트 Looker 서버 수신 대기)로 포트를 전달하도록 구성해야 합니다.
- 부하 분산 규칙에서 스케줄러 노드를 생략하여 최종 사용자 트래픽 및 내부 API 요청을 처리하지 않도록 합니다.
- 배포에는 GB당 IOPS가 2개인 스토리지가 있는 것이 좋습니다.
높은 렌더링 처리량
높은 렌더링 보고서 처리량이 필요한 사용 사례의 경우 렌더링 전용 노드 풀로 클러스터를 구성하는 것이 좋습니다. PDF 파일 또는 PNG/JPEG 이미지를 렌더링하는 것은 Looker에서 비교적 리소스 비용이 많이 드는 작업입니다. 렌더링은 메모리 집약적이고 CPU를 많이 사용할 수 있으며 Linux가 메모리 압력을 받고 있다면 실행 중인 프로세스를 종료시킬 수 있습니다. 렌더링 작업의 메모리 사용량을 미리 확인할 수 없으므로 렌더링 작업을 시작하면 Looker 프로세스가 종료될 수 있습니다. 전용 렌더링 노드를 구성하면 렌더링 작업을 최적으로 조정할 수 있으며 대화형 및 삽입된 애플리케이션의 응답성을 유지할 수 있습니다.
이러한 이점을 활용하려면 다음 다이어그램과 이 옵션의 장점 및 권장사항 섹션에 설명된 대로 맞춤설정된 시작 옵션과 적절한 부하 분산 규칙을 사용하여 노드를 설정해야 합니다. 또한 Looker의 렌더링 서비스는 CPU 시간 및 메모리를 공유하는 타사 Chromium 프로세스에 의존하므로 렌더링 노드에는 표준 노드보다 더 많은 호스트 리소스가 필요할 수 있습니다.
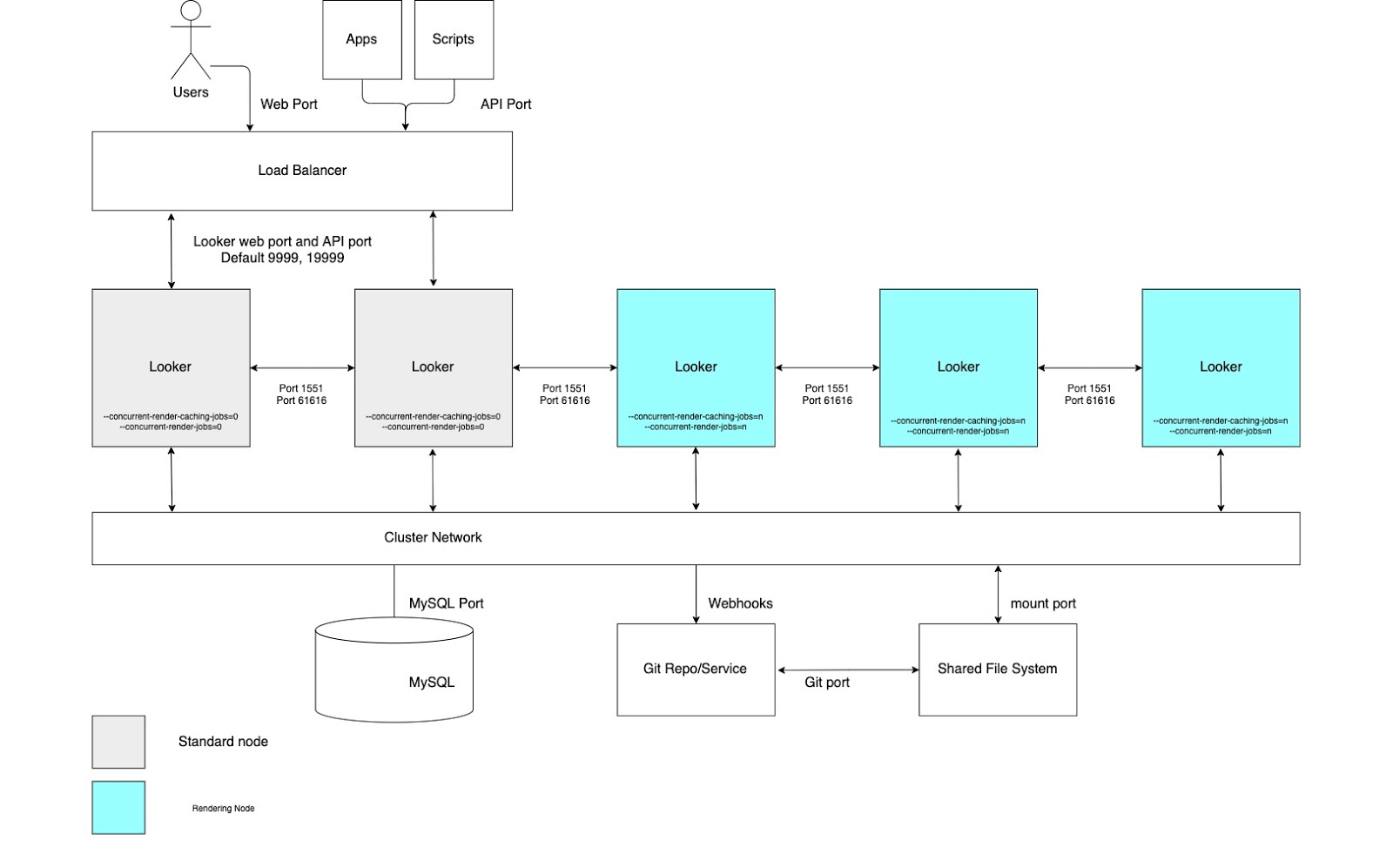
장점
- 특정 함수에 노드를 지정하는 것은 개발 및 임시 분석 함수에서 렌더링하기 위한 리소스를 분류합니다.
- 사용자는 PNG 및 PDF 렌더링을 담당하는 노드에서 순환을 수행하지 않고도 LookML을 개발하고 콘텐츠를 탐색할 수 있습니다.
- 일반 노드로 유입되는 사용자 트래픽이 많아도 렌더링 노드에서 처리되는 렌더링 워크로드를 방해하지 않습니다.
권장사항
- 각 Looker 노드는 자체 전용 VM에서 호스팅되어야 합니다.
- 클러스터 인그레스 지점인 부하 분산기는 레이어 4 부하 분산기여야 합니다. 시간 제한(3,600초)이 길고 서명된 SSL 인증서가 있어야 하며 443(https)에서 9999(포트 Looker 서버 수신 대기)로 포트를 전달하도록 구성해야 합니다.
- 부하 분산 규칙에서 렌더링 노드를 생략하여 최종 사용자 트래픽 및 내부 API 요청을 처리하지 않도록 합니다.
- 렌더링 노드에서 자바에 상대적으로 적은 메모리를 할당하여 Chromium의 프로세스에 더 큰 메모리 버퍼를 제공합니다. 메모리의 60%를 자바에 할당하는 대신 40~50%를 할당합니다.
- 비렌더링 노드에서 메모리 압력의 위험이 줄어들어 Looker 전용 메모리의 양이 증가할 수 있습니다. 기본값인 60% 대신 80%와 같이 큰 숫자를 사용하는 것이 좋습니다.
- 배포에는 GB당 IOPS가 2개인 스토리지가 있는 것이 좋습니다.