Halaman ini membahas pola arsitektur paling umum untuk deployment yang dihosting pelanggan dan menjelaskan praktik terbaik untuk menerapkannya. Untuk menggunakan halaman ini secara efektif, Anda harus memahami konsep dan praktik arsitektur sistem.
Strategi alur kerja
Setelah Anda mengidentifikasi hosting mandiri sebagai opsi yang layak untuk penerapan Looker, langkah selanjutnya adalah menguraikan strategi yang akan ditayangkan oleh deployment.
- Lakukan penilaian. Identifikasi daftar kandidat alur kerja yang telah direncanakan dan yang sudah ada.
- Mencantumkan pola arsitektur yang berlaku. Dimulai dengan alur kerja kandidat yang teridentifikasi, identifikasi pola arsitektur yang berlaku.
- Prioritaskan dan pilih pola arsitektur yang optimal. Menyelaraskan pola arsitektur dengan tugas dan hasil yang paling penting.
- Konfigurasi komponen arsitektur dan deploy aplikasi Looker. Terapkan host, dependensi pihak ketiga, dan topologi jaringan yang diperlukan untuk membuat koneksi klien yang aman.
Opsi arsitektur
Mesin virtual khusus
Salah satu opsi adalah menjalankan Looker sebagai satu instance dalam virtual machine (VM) khusus. Satu instance dapat melayani beban kerja yang berat dengan menskalakan host secara vertikal dan meningkatkan kumpulan thread default. Namun, overhead pemrosesan dalam mengelola heap Java yang besar membuat penskalaan vertikal tunduk pada hukum penurunan hasil. Umumnya dapat diterima untuk beban kerja kecil hingga sedang. Diagram berikut menggambarkan penyiapan default dan opsional antara instance Looker yang berjalan di VM khusus, repositori lokal dan jarak jauh, server SMTP, dan sumber data yang disorot di bagian Keuntungan dan Praktik terbaik untuk opsi ini.
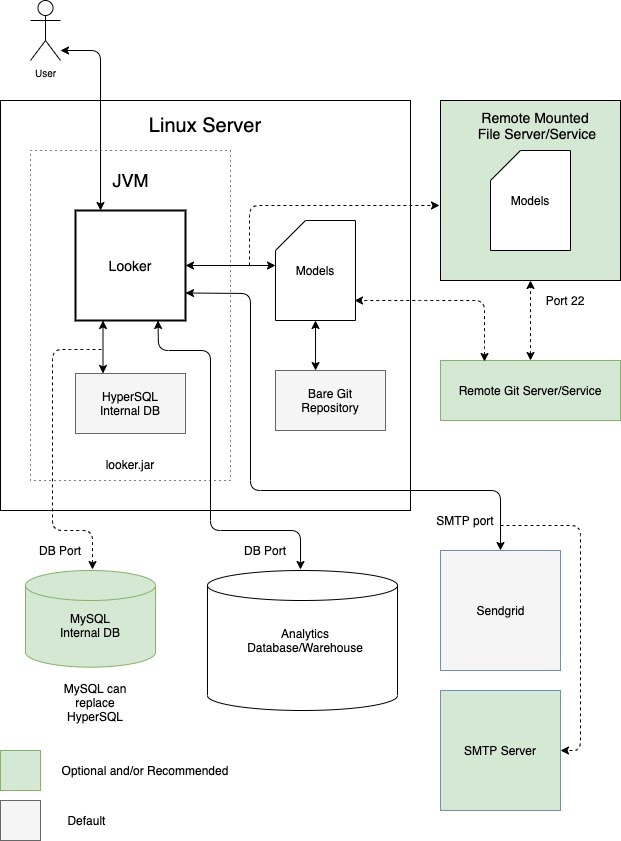
Kelebihan
- VM khusus mudah di-deploy dan dikelola.
- Database internal dihosting dalam aplikasi Looker.
- Komponen model Looker, repositori Git, server SMTP, dan database backend dapat dikonfigurasi secara lokal atau dari jarak jauh.
- Anda dapat mengganti server SMTP default Looker dengan server Anda sendiri untuk notifikasi email dan tugas terjadwal.
Praktik terbaik
- Secara default, Looker dapat membuat repositori Git kosong untuk project. Sebaiknya repositori Git jarak jauh disiapkan untuk redundansi.
-
Secara default, Looker dimulai dengan database HyperSQL dalam memori. Database ini praktis dan ringan, tetapi dapat mengalami masalah performa saat digunakan secara berat. Sebaiknya gunakan database MySQL untuk deployment yang lebih besar. Sebaiknya lakukan migrasi ke database MySQL jarak jauh setelah file
~/looker/.db/looker.scriptmencapai 600 MB. - Deployment Looker Anda harus divalidasi terhadap layanan pemberian lisensi Looker; traffic keluar di port 443 diperlukan.
- Deployment VM khusus dapat diskalakan secara vertikal dengan meningkatkan resource yang tersedia dan kumpulan thread Looker. Namun, peningkatan RAM tunduk pada hukum penurunan hasil setelah mencapai 64 GB, karena peristiwa pengumpulan sampah adalah thread tunggal dan menghentikan semua thread lain untuk dieksekusi. Node dengan 16 CPU dan RAM 64 GB adalah keseimbangan yang baik antara harga dan performa.
- Sebaiknya deployment Anda memiliki penyimpanan dengan 2 operasi per detik (IOPS) per GB.
Cluster VM
Menjalankan Looker sebagai cluster instance di beberapa VM adalah pola fleksibel yang diuntungkan dari failover dan redundansi layanan. Skalabilitas horizontal memungkinkan peningkatan throughput tanpa mengalami pembengkakan heap dan biaya pengumpulan sampah yang berlebihan. Node memiliki opsi dedikasi workload, yang memungkinkan beberapa opsi deployment disesuaikan dengan berbagai persyaratan bisnis. Deployment cluster memerlukan setidaknya satu administrator sistem yang memahami sistem Linux dan mampu mengelola bagian komponen.
Cluster standar
Untuk sebagian besar deployment standar, cluster node layanan yang identik sudah cukup. Semua node dalam cluster dikonfigurasi dengan cara yang sama dan semuanya berada dalam kumpulan load balancer yang sama. Tidak ada node dalam konfigurasi ini yang lebih atau kurang mungkin melayani permintaan pengguna Looker, tugas rendering, tugas terjadwal, permintaan API, dll.
Konfigurasi semacam ini cocok jika sebagian besar permintaan berasal langsung dari pengguna Looker yang menjalankan kueri dan berinteraksi dengan Looker. Proses ini mulai terganggu saat sejumlah besar permintaan berasal dari scheduler, perender, atau sumber lain. Dalam hal ini, sebaiknya tetapkan node layanan tertentu untuk menangani tugas seperti jadwal dan rendering.
Misalnya, pengguna biasanya menjadwalkan pengiriman data untuk dijalankan pada Senin pagi. Pengguna yang mencoba menjalankan kueri Looker pada Senin pagi mungkin mengalami masalah performa saat Looker memproses backlog permintaan terjadwal. Dengan meningkatkan jumlah node layanan, cluster memberikan peningkatan proporsional dalam throughput di semua kemampuan Looker.
Diagram berikut menggambarkan cara permintaan ke Looker yang dibuat dari pengguna, aplikasi, dan skrip diseimbangkan di seluruh instance Looker yang dikelompokkan.
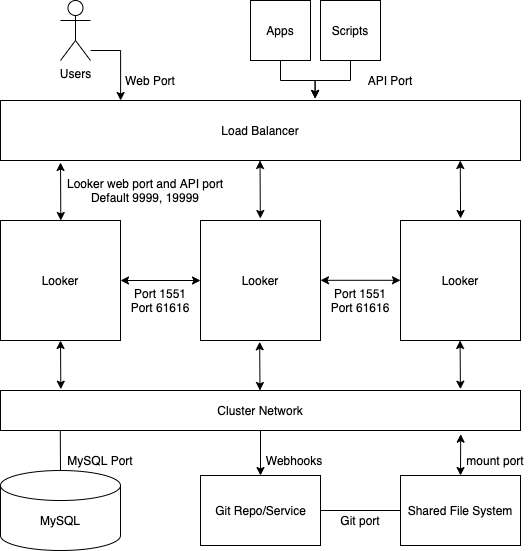
Kelebihan
- Cluster standar memaksimalkan throughput umum dengan konfigurasi topologi cluster yang minimal.
- VM Java mengalami penurunan performa pada batas memori yang dialokasikan sebesar 64 GB; itulah sebabnya penskalaan horizontal memberikan hasil yang lebih baik daripada penskalaan vertikal.
- Konfigurasi cluster memastikan redundansi dan failover layanan.
Praktik terbaik
- Setiap node Looker harus dihosting di VM khusus miliknya sendiri.
- Load balancer, yang merupakan titik ingress cluster, harus berupa load balancer layer 4. Server harus memiliki waktu tunggu yang lama (3.600 detik), dilengkapi dengan sertifikat SSL yang ditandatangani, dan dikonfigurasi untuk meneruskan port dari 443 (https) ke 9999 (port yang digunakan server Looker untuk memproses).
- Sebaiknya deployment Anda memiliki penyimpanan dengan 2 IOPS per GB.
Dev/Staging/Prod
Untuk kasus penggunaan yang memprioritaskan waktu aktif konten maksimum bagi pengguna akhir, sebaiknya gunakan lingkungan Looker terpisah untuk mengelompokkan pekerjaan pengembangan dan pekerjaan analisis. Dengan membatasi perubahan lingkungan produksi di balik lingkungan pengembangan dan pengujian yang terisolasi, arsitektur ini mempertahankan lingkungan produksi yang sestabil mungkin.
Manfaat ini memerlukan penyiapan lingkungan yang saling terhubung dan penerapan siklus rilis yang kuat. Deployment Dev/Staging/Prod juga memerlukan tim developer yang memahami Looker API dan Git untuk administrasi alur kerja.
Diagram berikut menggambarkan alur konten antara developer LookML yang mengembangkan konten di instance Dev, penguji penjamin kualitas (QA) yang menguji konten di instance QA, serta pengguna, aplikasi, dan skrip yang menggunakan konten di instance Produksi.
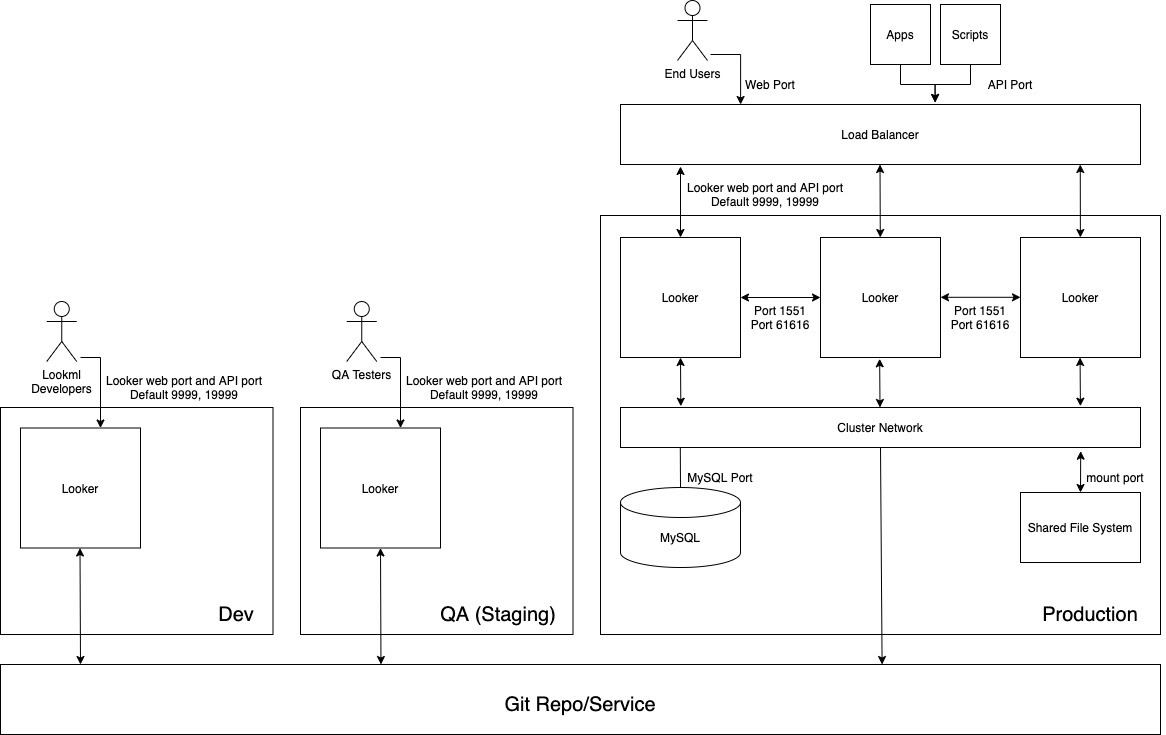
Kelebihan
- Validasi LookML dan konten terjadi di lingkungan non-produksi, sehingga memastikan bahwa setiap modifikasi pada logika model dapat diperiksa secara menyeluruh sebelum mencapai pengguna produksi.
- Fitur di seluruh instance, seperti fitur Labs atau protokol autentikasi, dapat diuji secara terpisah sebelum diaktifkan di lingkungan produksi.
- Kebijakan grup data dan caching dapat diuji di lingkungan non-produksi.
- Pengujian mode produksi Looker tidak terkait dengan lingkungan produksi yang bertanggung jawab untuk melayani pengguna akhir.
- Rilis Looker dapat diuji di lingkungan non-produksi, sehingga memberikan waktu yang cukup untuk menguji fitur baru, perubahan alur kerja, dan masalah sebelum mengupdate lingkungan produksi.
Praktik terbaik
- Mengisolasi berbagai aktivitas yang terjadi secara bersamaan dalam minimal tiga instance terpisah:
- Instance pengembangan: Developer menggunakan lingkungan pengembangan untuk melakukan commit kode, melakukan eksperimen, memperbaiki bug, dan melakukan kesalahan dengan aman.
- Instance QA: Juga disebut sebagai lingkungan pengujian atau staging, di sinilah developer menjalankan pengujian manual dan otomatis. Lingkungan QA sangat kompleks dan dapat menghabiskan banyak resource.
- Instance produksi: Di sinilah nilai dibuat untuk pelanggan dan/atau bisnis. Produksi adalah lingkungan yang sangat terlihat dan harus bebas dari error.
- Pertahankan alur kerja siklus rilis yang terdokumentasi dan dapat diulang.
- Jika perlu melayani developer dan penguji QA dalam volume tinggi, instance Dev dan/atau QA dapat dikelompokkan. Baik dibiarkan sebagai VM mandiri atau cluster VM, instance Dev dan QA tunduk pada pertimbangan arsitektur yang sama yang sebelumnya ditampilkan di bagian masing-masing.
Throughput penjadwalan tinggi
Untuk kasus penggunaan yang memerlukan throughput pengiriman data terjadwal yang tinggi serta pengiriman yang tepat waktu dan andal, sebaiknya konfigurasi mencakup cluster dengan kumpulan node yang khusus ditujukan untuk penjadwalan. Konfigurasi ini akan membantu menjaga kecepatan dan responsivitas aplikasi web dan sematan. Manfaat ini memerlukan penyiapan node dengan opsi startup yang disesuaikan dan aturan penyeimbangan beban yang tepat, seperti yang digambarkan dalam diagram berikut dan diuraikan di bagian Keuntungan dan Praktik terbaik untuk opsi ini.
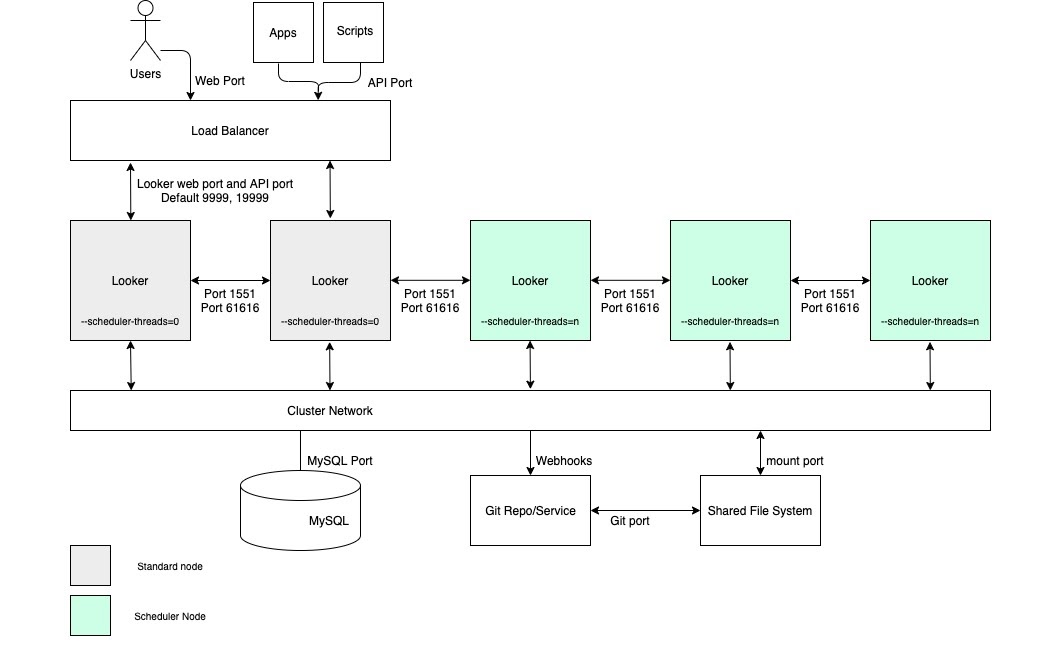
Kelebihan
- Mengkhususkan node untuk fungsi tertentu akan mengelompokkan sumber daya untuk penjadwalan dari fungsi pengembangan dan analisis ad-hoc.
- Pengguna dapat mengembangkan LookML dan menjelajahi konten tanpa mengambil siklus dari node yang bertanggung jawab untuk melayani pengiriman data terjadwal.
- Traffic pengguna yang tinggi yang diarahkan ke node reguler tidak menghalangi workload terjadwal yang dilayani oleh node penjadwalan.
Praktik terbaik
- Setiap node Looker harus dihosting di VM khusus miliknya sendiri.
- Load balancer, yang merupakan titik ingress cluster, harus berupa load balancer layer 4. Server harus memiliki waktu tunggu yang lama (3.600 detik), dilengkapi dengan sertifikat SSL yang ditandatangani, dan dikonfigurasi untuk meneruskan port dari 443 (https) ke 9999 (port yang digunakan server Looker untuk memproses).
- Kecualikan node penjadwal dari aturan load balancing agar tidak melayani traffic pengguna akhir dan permintaan API internal.
- Sebaiknya deployment Anda memiliki penyimpanan dengan 2 IOPS per GB.
Throughput rendering tinggi
Untuk kasus penggunaan yang memerlukan throughput laporan rendering tinggi, sebaiknya konfigurasi cluster dengan kumpulan node yang khusus didedikasikan untuk rendering. Merender file PDF atau gambar PNG/JPEG adalah operasi yang relatif mahal sumber dayanya di Looker. Rendering dapat menggunakan banyak memori dan CPU, dan saat Linux mengalami tekanan memori, Linux dapat menghentikan proses yang sedang berjalan. Karena penggunaan memori tugas rendering tidak dapat ditentukan sebelumnya, memulai tugas rendering dapat menyebabkan proses Looker dihentikan. Mengonfigurasi node rendering khusus akan memungkinkan penyetelan tugas rendering yang optimal sekaligus mempertahankan responsivitas aplikasi interaktif dan sematan.
Manfaat ini memerlukan penyiapan node dengan opsi startup yang disesuaikan dan aturan penyeimbangan beban yang tepat seperti yang digambarkan dalam diagram berikut dan dijelaskan di bagian Keuntungan dan Praktik terbaik untuk opsi ini. Selain itu, node rendering mungkin memerlukan lebih banyak resource host daripada node standar, karena layanan rendering Looker bergantung pada proses Chromium pihak ketiga yang berbagi waktu CPU dan memori.
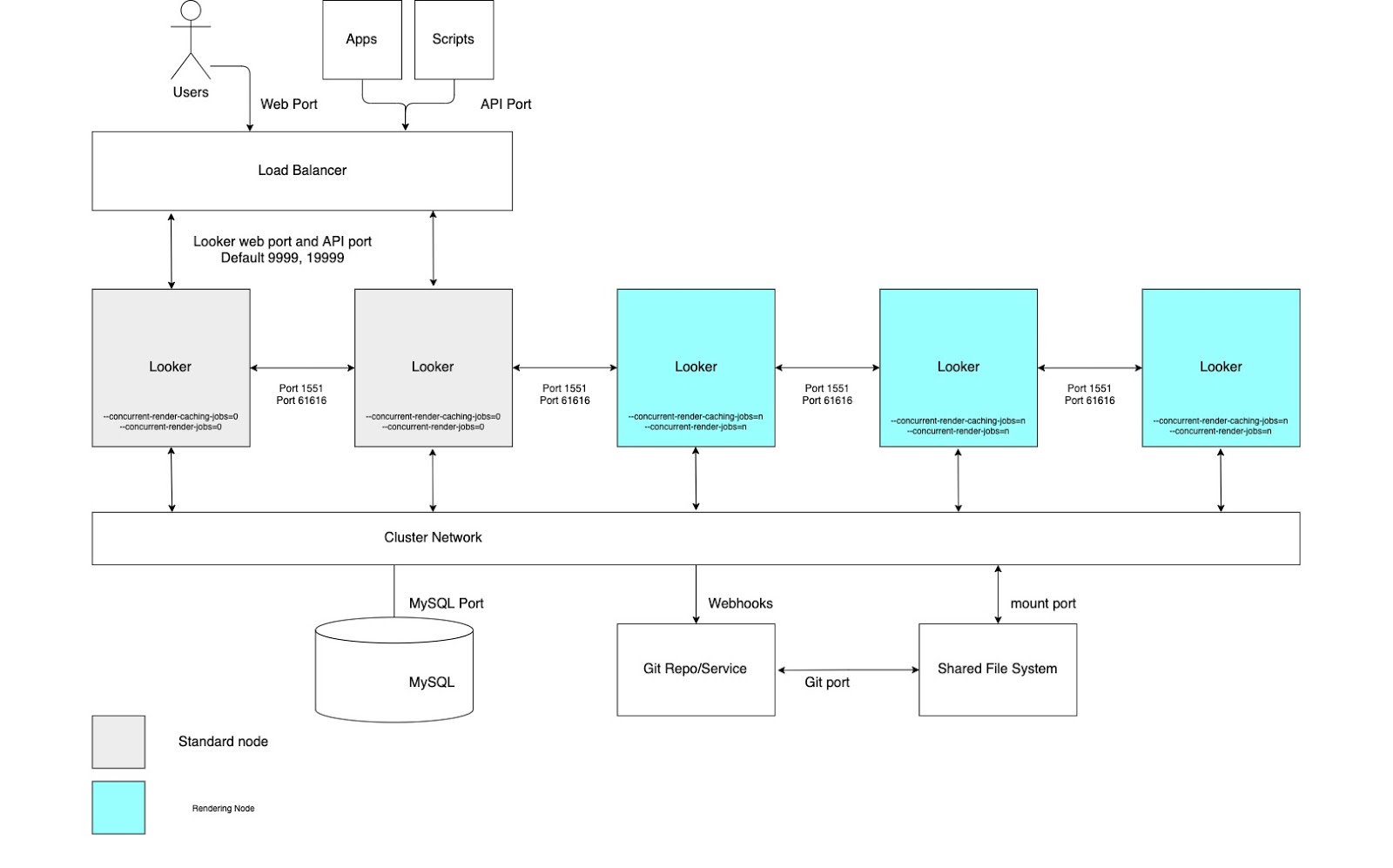
Kelebihan
- Mengkhususkan node untuk fungsi tertentu mengelompokkan resource untuk rendering dari fungsi pengembangan dan analisis ad hoc.
- Pengguna dapat mengembangkan LookML dan menjelajahi konten tanpa mengambil siklus dari node yang bertanggung jawab untuk merender PNG dan PDF.
- Traffic pengguna yang tinggi yang diarahkan ke node reguler tidak menghalangi beban kerja rendering yang dilayani oleh node rendering.
Praktik terbaik
- Setiap node Looker harus dihosting di VM khusus miliknya sendiri.
- Load balancer, yang merupakan titik ingress cluster, harus berupa load balancer layer 4. Server harus memiliki waktu tunggu yang lama (3.600 detik), dilengkapi dengan sertifikat SSL yang ditandatangani, dan dikonfigurasi untuk meneruskan port dari 443 (https) ke 9999 (port yang digunakan server Looker untuk memproses).
- Menghapus node rendering dari aturan load balancing, sehingga node tersebut tidak melayani traffic pengguna akhir dan permintaan API internal.
- Mengalokasikan memori yang relatif lebih sedikit ke Java di node rendering untuk memberikan buffer memori yang lebih besar pada proses Chromium. Daripada mengalokasikan 60% memori ke Java, alokasikan 40-50%.
- Risiko tekanan memori telah dikurangi pada node non-render, sehingga jumlah memori yang dikhususkan untuk Looker dapat ditingkatkan. Daripada 60% default, pertimbangkan angka yang lebih tinggi seperti 80%.
- Sebaiknya deployment Anda memiliki penyimpanan dengan 2 IOPS per GB.