Auf dieser Seite werden die gängigsten Architekturmuster für eine vom Kunden gehostete Bereitstellung untersucht und die Best Practices für die Implementierung beschrieben. Damit Sie diese Seite effektiv nutzen können, sollten Sie mit Konzepten und Praktiken der Systemarchitektur vertraut sein.
Workflow-Strategie
Nachdem Sie Self-Hosting als praktikable Option für die Implementierung von Looker identifiziert haben, müssen Sie als Nächstes die Strategie für die Bereitstellung ausarbeiten.
- Bewertung durchführen. Identifizieren Sie eine Liste potenzieller geplanter und vorhandener Workflows.
- Geeignete Architekturmuster auflisten: Bestimmen Sie anhand der identifizierten potenziellen Arbeitsabläufe geeignete Architekturmuster.
- Priorisieren und wählen Sie das optimale Architekturmuster aus. Richten Sie das Architekturmuster an den wichtigsten Aufgaben und Ergebnissen aus.
- Architekturkomponenten konfigurieren und Looker-Anwendung bereitstellen. Implementieren Sie den Host, die Drittanbieterabhängigkeiten und die Netzwerktopologie, die zum Herstellen sicherer Clientverbindungen erforderlich sind.
Architekturoptionen
Dedizierte virtuelle Maschine
Eine Möglichkeit besteht darin, Looker als einzelne Instanz auf einer dedizierten virtuellen Maschine (VM) auszuführen. Eine einzelne Instanz kann anspruchsvolle Arbeitslasten bewältigen, indem der Host vertikal skaliert und die Standard-Threadpools vergrößert werden. Der Verarbeitungsaufwand für die Verwaltung eines großen Java-Heaps unterliegt jedoch dem Gesetz des abnehmenden Grenzprodukts. Für kleine bis mittlere Arbeitslasten ist das in der Regel akzeptabel. Das folgende Diagramm zeigt die Standard- und optionalen Konfigurationen zwischen einer Looker-Instanz, die auf einer dedizierten VM ausgeführt wird, den lokalen und Remote-Repositories, den SMTP-Servern und den Datenquellen, die in den Abschnitten Vorteile und Best Practices für diese Option hervorgehoben sind.
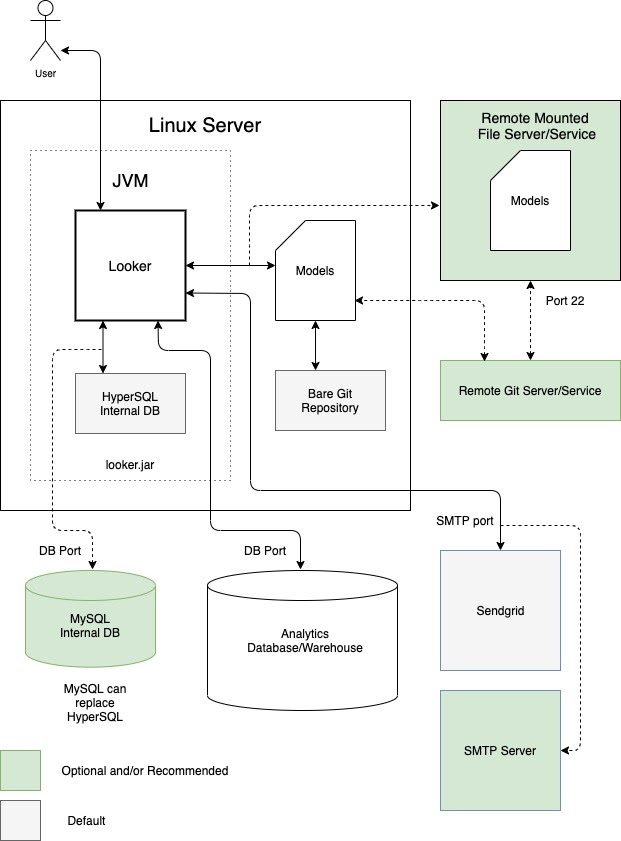
Vorteile
- Eine dedizierte VM lässt sich einfach bereitstellen und verwalten.
- Die interne Datenbank wird in der Looker-Anwendung gehostet.
- Die Komponenten für Looker-Modelle, Git-Repository, SMTP-Server und Backend-Datenbank können lokal oder remote konfiguriert werden.
- Sie können den Standard-SMTP-Server von Looker durch Ihren eigenen ersetzen, um E-Mail-Benachrichtigungen und geplante Aufgaben zu senden.
Best Practices
- Standardmäßig kann Looker Bare-Git-Repositories für ein Projekt generieren. Wir empfehlen, ein Remote-Git-Repository für die Redundanz einzurichten.
-
Standardmäßig wird Looker mit einer speicherresidenten HyperSQL-Datenbank gestartet. Diese Datenbank ist praktisch und ressourcenschonend, kann aber bei starker Nutzung Leistungsprobleme verursachen. Für größere Bereitstellungen empfehlen wir die Verwendung einer MySQL-Datenbank. Wir empfehlen, zu einer Remote-MySQL-Datenbank zu migrieren, sobald die Datei
~/looker/.db/looker.script600 MB erreicht. - Ihre Looker-Bereitstellung muss mit dem Looker-Lizenzierungsdienst abgeglichen werden. Dazu ist ausgehender Traffic über Port 443 erforderlich.
- Eine dedizierte VM-Bereitstellung kann vertikal skaliert werden, indem die verfügbaren Ressourcen und Looker-Threadpools erhöht werden. Das Erhöhen des RAM unterliegt jedoch dem Gesetz des abnehmenden Grenzertrags, sobald es 64 GB erreicht, da Garbage Collection-Ereignisse Single-Threaded sind und alle anderen Threads anhalten, um ausgeführt zu werden. Knoten mit 16 CPUs und 64 GB RAM bieten ein gutes Preis-Leistungs-Verhältnis.
- Wir empfehlen, dass Ihre Bereitstellung Speicher mit 2 E/A-Vorgängen pro Sekunde (IOPS) pro GB hat.
Cluster von VMs
Wenn Sie Looker als Cluster von Instanzen auf mehreren VMs ausführen, profitieren Sie von Service-Failover und Redundanz. Die horizontale Skalierbarkeit ermöglicht einen höheren Durchsatz, ohne dass es zu Heap-Bloat und übermäßigen Kosten für die Garbage Collection kommt. Knoten können für Arbeitslasten reserviert werden. So lassen sich mehrere Bereitstellungsoptionen an unterschiedliche geschäftliche Anforderungen anpassen. Für Clusterbereitstellungen ist mindestens ein Systemadministrator erforderlich, der mit Linux-Systemen vertraut ist und die Komponenten verwalten kann.
Standard-Cluster
Für die meisten Standardbereitstellungen reicht ein Cluster identischer Dienstknoten aus. Alle Knoten im Cluster sind gleich konfiguriert und befinden sich alle im selben Load-Balancer-Pool. Keiner der Knoten in dieser Konfiguration würde Looker-Nutzeranfragen, Rendering-Aufgaben, geplante Aufgaben oder API-Anfragen mit höherer oder geringerer Wahrscheinlichkeit bearbeiten.
Diese Art der Konfiguration ist geeignet, wenn die meisten Anfragen direkt von einem Looker-Nutzer stammen, der Abfragen ausführt und mit Looker interagiert. Das Verfahren funktioniert nicht mehr, wenn eine große Anzahl von Anfragen von einem Scheduler, einem Renderer oder einer anderen Quelle kommt. In diesem Fall ist es sinnvoll, bestimmte Dienstknoten für Aufgaben wie Zeitpläne und Rendering zu verwenden.
Nutzer planen beispielsweise häufig, dass Daten am Montagmorgen bereitgestellt werden. Wenn ein Nutzer am Montagmorgen versucht, Looker-Abfragen auszuführen, kann es zu Leistungsproblemen kommen, während Looker den Rückstand an geplanten Anfragen abarbeitet. Durch Erhöhen der Anzahl der Dienstknoten bietet der Cluster einen proportionalen Anstieg des Durchsatzes für alle Looker-Funktionen.
Das folgende Diagramm zeigt, wie Anfragen an Looker, die vom Nutzer, von Apps und von Skripts gestellt werden, auf eine geclusterte Looker-Instanz verteilt werden.
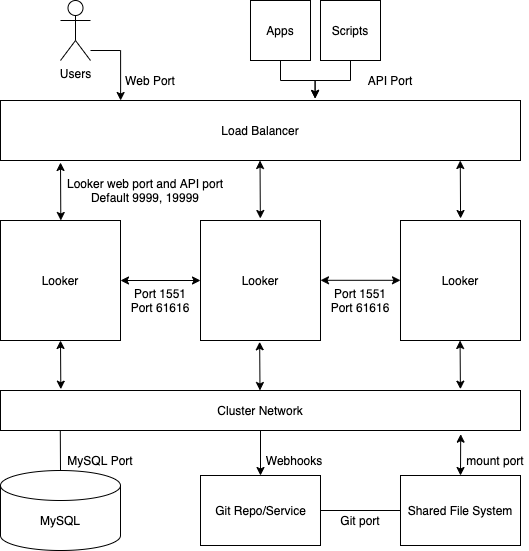
Vorteile
- Ein Standardcluster maximiert den allgemeinen Durchsatz bei minimaler Konfiguration der Clustertopologie.
- Die Java VM leidet unter Leistungseinbußen, wenn der zugewiesene Arbeitsspeicher 64 GB erreicht. Aus diesem Grund ist die horizontale Skalierung effektiver als die vertikale Skalierung.
- Eine Clusterkonfiguration sorgt für Dienstredundanz und Failover.
Best Practices
- Jeder Looker-Knoten sollte auf einer eigenen dedizierten VM gehostet werden.
- Der Load-Balancer, der der Ingress-Punkt des Clusters ist, sollte ein Layer-4-Load-Balancer sein. Es sollte ein langes Zeitlimit (3.600 Sekunden) haben, mit einem signierten SSL-Zertifikat ausgestattet sein und für die Portweiterleitung von 443 (https) zu 9999 (Port, auf dem der Looker-Server empfängt) konfiguriert sein.
- Wir empfehlen, dass Ihre Bereitstellung Speicher mit 2 IOPS pro GB hat.
Entwicklung/Staging/Produktion
Für Anwendungsfälle, bei denen die maximale Verfügbarkeit von Inhalten für Endnutzer Priorität hat, empfehlen wir separate Looker-Umgebungen, um Entwicklungs- und Analysearbeiten zu trennen. Da Änderungen an der Produktionsumgebung hinter isolierten Entwicklungs- und Testumgebungen erfolgen, wird mit dieser Architektur eine möglichst stabile Produktionsumgebung aufrechterhalten.
Für diese Vorteile müssen die miteinander verbundenen Umgebungen eingerichtet und ein robuster Release-Zyklus eingeführt werden. Für eine Bereitstellung in der Entwicklungs-, Staging- und Produktionsumgebung ist außerdem ein Team von Entwicklern erforderlich, die sich mit der Looker API und Git für die Workflow-Verwaltung auskennen.
Das folgende Diagramm zeigt den Fluss von Inhalten zwischen LookML-Entwicklern, die Inhalte in der Entwicklungsinstanz entwickeln, Qualitätssicherungstestern, die die Inhalte in der Qualitätssicherungsinstanz testen, und Nutzern, Apps und Skripts, die die Inhalte in der Produktionsinstanz verwenden.

Vorteile
- Die LookML- und Inhaltsvalidierung erfolgt in einer Nicht-Produktionsumgebung. So können alle Änderungen an der Modelllogik gründlich geprüft werden, bevor sie für Produktionsnutzer verfügbar sind.
- Instanzweite Funktionen wie Labs-Funktionen oder Authentifizierungsprotokolle können isoliert getestet werden, bevor sie in der Produktionsumgebung aktiviert werden.
- Datengruppen- und Caching-Richtlinien können in einer Nicht-Produktionsumgebung getestet werden.
- Tests im Looker-Produktionsmodus sind von Produktionsumgebungen entkoppelt, die für die Bereitstellung von Inhalten für Endnutzer verantwortlich sind.
- Looker-Releases können in einer Nicht-Produktionsumgebung getestet werden. So haben Sie ausreichend Zeit, neue Funktionen, Workflow-Änderungen und Probleme zu testen, bevor Sie die Produktionsumgebung aktualisieren.
Best Practices
- Isolieren Sie die verschiedenen Aktivitäten, die gleichzeitig stattfinden, in mindestens drei separaten Instanzen:
- Entwicklungsinstanz: Entwickler verwenden die Entwicklungsumgebung, um Code zu committen, Tests durchzuführen, Fehler zu beheben und sicher Fehler zu machen.
- QA-Instanz: Wird auch als Test- oder Staging-Umgebung bezeichnet. Hier führen Entwickler manuelle und automatisierte Tests aus. Die QA-Umgebung ist komplex und kann viele Ressourcen beanspruchen.
- Produktionsinstanz: Hier wird Wert für Kunden und/oder das Unternehmen geschaffen. Die Produktionsumgebung ist sehr gut sichtbar und sollte fehlerfrei sein.
- Einen dokumentierten, wiederholbaren Workflow für den Releasezyklus beibehalten.
- Wenn eine große Anzahl von Entwicklern und QA-Testern bedient werden muss, können die Entwickler- und/oder QA-Instanzen gruppiert werden. Unabhängig davon, ob es sich um eine eigenständige VM oder einen VM-Cluster handelt, unterliegen die Entwicklungs- und QA-Instanzen denselben architektonischen Überlegungen, die zuvor in den entsprechenden Abschnitten beschrieben wurden.
Hoher Planungsthroughput
Für Anwendungsfälle, die einen hohen Durchsatz bei der geplanten Datenbereitstellung und zeitnahe, zuverlässige Bereitstellungen erfordern, empfehlen wir, dass die Konfiguration einen Cluster mit einem Pool von Knoten umfasst, die ausschließlich für die Planung vorgesehen sind. Diese Konfiguration trägt dazu bei, dass Web- und eingebettete Anwendungen schnell und reaktionsschnell bleiben. Für diese Vorteile müssen Knoten mit benutzerdefinierten Startoptionen und geeigneten Load-Balancing-Regeln eingerichtet werden, wie im folgenden Diagramm dargestellt und in den Abschnitten Vorteile und Best Practices für diese Option beschrieben.
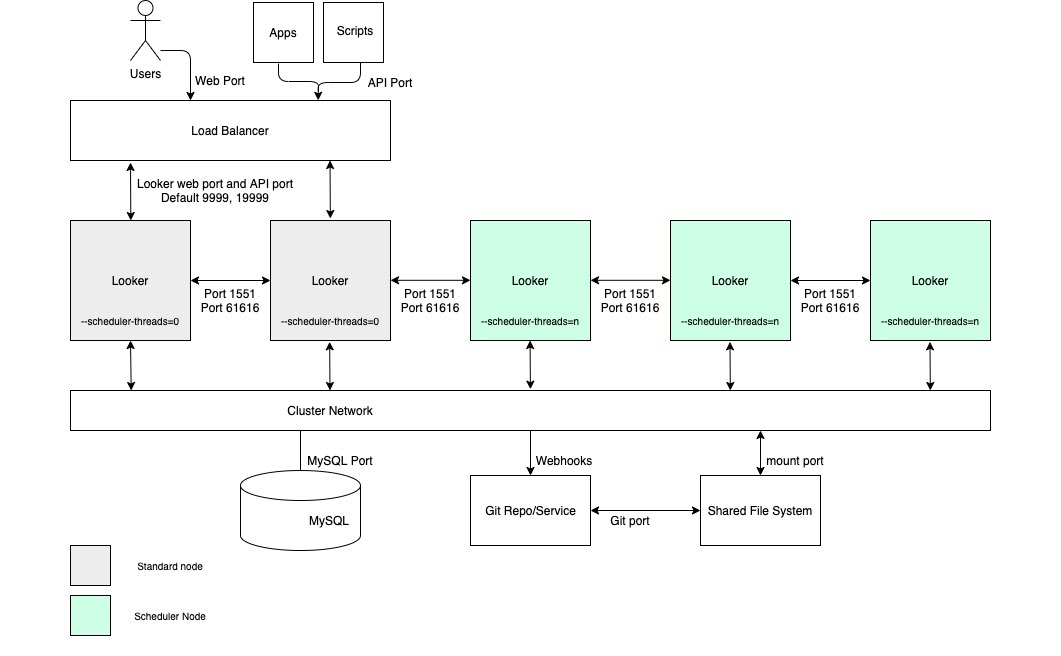
Vorteile
- Wenn Sie Knoten für eine bestimmte Funktion reservieren, werden Ressourcen für die Planung von Entwicklungs- und Ad-hoc-Analysefunktionen getrennt.
- Nutzer können LookML entwickeln und Inhalte untersuchen, ohne Zyklen von Knoten zu beanspruchen, die für die Verarbeitung geplanter Datenübermittlungen zuständig sind.
- Hoher Nutzer-Traffic, der an die regulären Knoten weitergeleitet wird, beeinträchtigt geplante Arbeitslasten, die von Planungsknoten bereitgestellt werden, nicht.
Best Practices
- Jeder Looker-Knoten sollte auf einer eigenen dedizierten VM gehostet werden.
- Der Load-Balancer, der der Ingress-Punkt des Clusters ist, sollte ein Layer-4-Load-Balancer sein. Es sollte ein langes Zeitlimit (3.600 Sekunden) haben, mit einem signierten SSL-Zertifikat ausgestattet sein und für die Portweiterleitung von 443 (https) zu 9999 (Port, auf dem der Looker-Server empfängt) konfiguriert sein.
- Lassen Sie Scheduler-Knoten in Load-Balancing-Regeln aus, damit sie keinen Endnutzer-Traffic und keine internen API-Anfragen verarbeiten.
- Wir empfehlen, dass Ihre Bereitstellung Speicher mit 2 IOPS pro GB hat.
Hoher Rendering-Durchsatz
Für Anwendungsfälle, die einen hohen Durchsatz beim Rendern von Berichten erfordern, empfehlen wir, einen Cluster mit einem Pool von Knoten zu konfigurieren, die ausschließlich für das Rendern vorgesehen sind. Das Rendern einer PDF-Datei oder eines PNG-/JPEG-Bildes ist in Looker ein relativ ressourcenaufwendiger Vorgang. Das Rendern kann speicher- und CPU-intensiv sein. Wenn Linux unter Speicherdruck steht, kann es einen laufenden Prozess beenden. Da die Speichernutzung eines Rendering-Jobs nicht im Voraus bestimmt werden kann, kann das Starten eines Rendering-Jobs dazu führen, dass der Looker-Prozess beendet wird. Durch die Konfiguration dedizierter Rendering-Knoten können Rendering-Jobs optimal abgestimmt werden, während die Reaktionsfähigkeit der interaktiven und eingebetteten Anwendung erhalten bleibt.
Für diese Vorteile müssen Knoten mit benutzerdefinierten Startoptionen und geeigneten Lastenausgleichsregeln eingerichtet werden, wie im folgenden Diagramm dargestellt und in den Abschnitten Vorteile und Best Practices für diese Option beschrieben. Außerdem benötigen Rendering-Knoten möglicherweise mehr Hostressourcen als Standardknoten, da der Rendering-Dienst von Looker von Drittanbieter-Chromium-Prozessen abhängt, die sich CPU-Zeit und Arbeitsspeicher teilen.
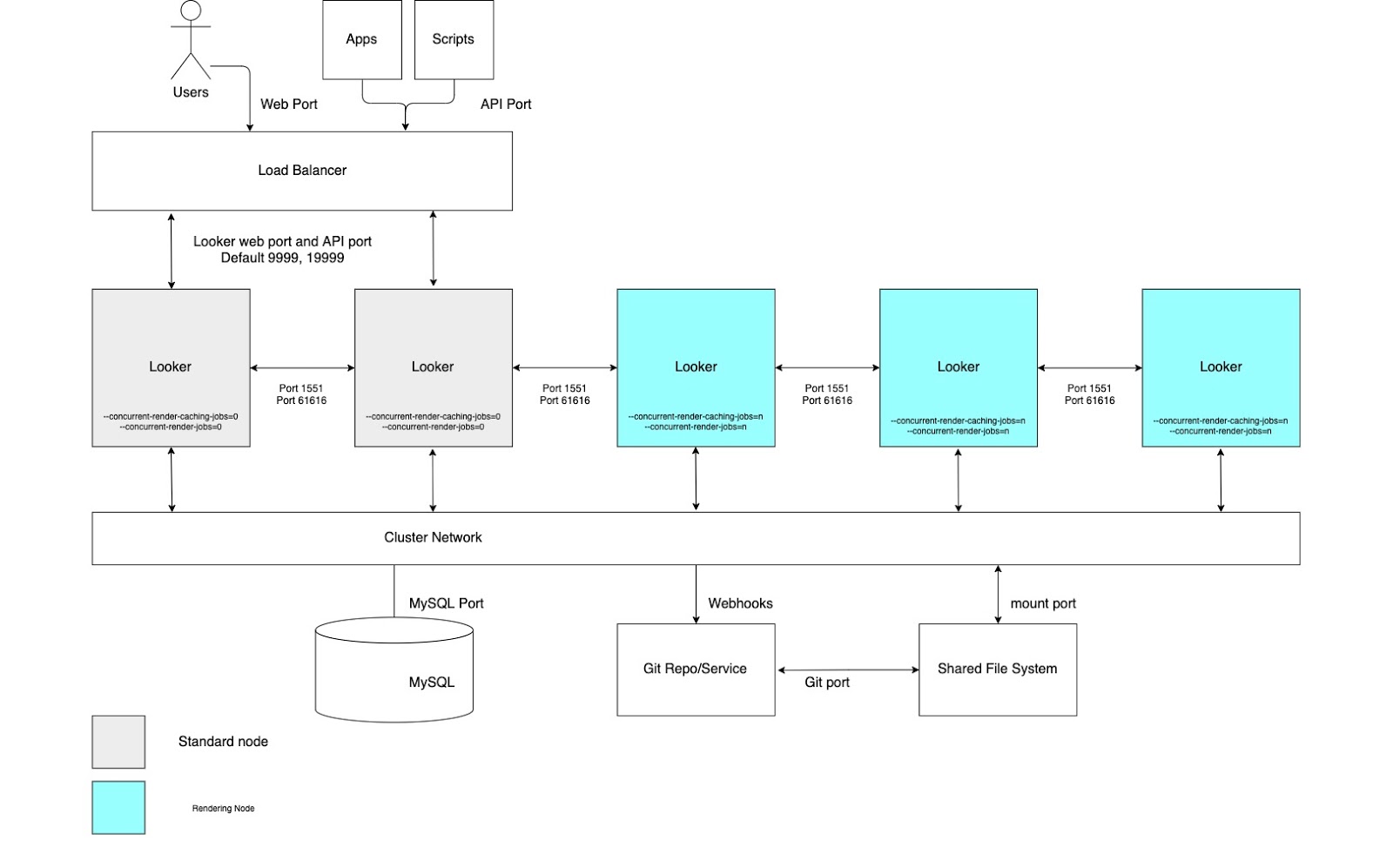
Vorteile
- Durch die Zuweisung von Knoten für eine bestimmte Funktion werden Ressourcen für das Rendern von Entwicklungs- und Ad-hoc-Analysefunktionen getrennt.
- Nutzer können LookML entwickeln und Inhalte untersuchen, ohne Zyklen von den Knoten zu beanspruchen, die für das Rendern von PNGs und PDFs zuständig sind.
- Hoher Nutzer-Traffic, der an die regulären Knoten weitergeleitet wird, beeinträchtigt nicht die Rendering-Arbeitslasten, die von Rendering-Knoten verarbeitet werden.
Best Practices
- Jeder Looker-Knoten sollte auf einer eigenen dedizierten VM gehostet werden.
- Der Load-Balancer, der der Ingress-Punkt des Clusters ist, sollte ein Layer-4-Load-Balancer sein. Es sollte ein langes Zeitlimit (3.600 Sekunden) haben, mit einem signierten SSL-Zertifikat ausgestattet sein und für die Portweiterleitung von 443 (https) zu 9999 (Port, auf dem der Looker-Server empfängt) konfiguriert sein.
- Rendering-Knoten aus Load-Balancing-Regeln ausschließen, damit sie keinen Endnutzer-Traffic und keine internen API-Anfragen verarbeiten.
- Weisen Sie Java in den Rendering-Knoten relativ weniger Arbeitsspeicher zu, um den Prozessen von Chromium einen größeren Arbeitsspeicherpuffer zu geben. Weisen Sie Java nicht 60 %, sondern 40–50 % des Speichers zu.
- Das Risiko von Speicherauslastung wurde auf den Nicht-Render-Knoten reduziert, sodass die Menge des für Looker reservierten Speichers erhöht werden kann. Anstelle des Standardwerts von 60 % sollten Sie einen höheren Wert wie 80 % in Betracht ziehen.
- Wir empfehlen, dass Ihre Bereitstellung Speicher mit 2 IOPS pro GB hat.