本页探讨了客户托管部署最常见的架构模式,并介绍了实现这些模式的最佳实践。如需有效使用本页面,您应熟悉系统架构概念和实践。
工作流策略
在确定自托管是 Looker 实现的可行方案后,下一步是详细说明部署将要服务的策略。
- 进行评估。确定计划的和现有的工作流的候选列表。
- 列出适用的架构模式。从确定的候选工作流开始,确定适用的架构模式。
- 确定优先级并选择最佳架构模式。使架构模式与最重要的任务和结果保持一致。
- 配置架构组件并部署 Looker 应用。实现建立安全客户端连接所需的主机、第三方依赖项和网络拓扑。
架构选项
专用虚拟机
一种选择是在专用虚拟机 (VM) 中以单个实例的形式运行 Looker。单个实例可以通过纵向伸缩主机和增加默认线程池来处理高要求的工作负载。不过,管理大型 Java 堆的处理开销会使纵向伸缩受到边际收益递减规律的制约。对于中小型工作负载,这通常是可以接受的。下图展示了在专用虚拟机中运行的 Looker 实例、本地和远程代码库、SMTP 服务器以及优势和最佳实践部分中针对此选项重点介绍的数据源之间的默认设置和可选设置。
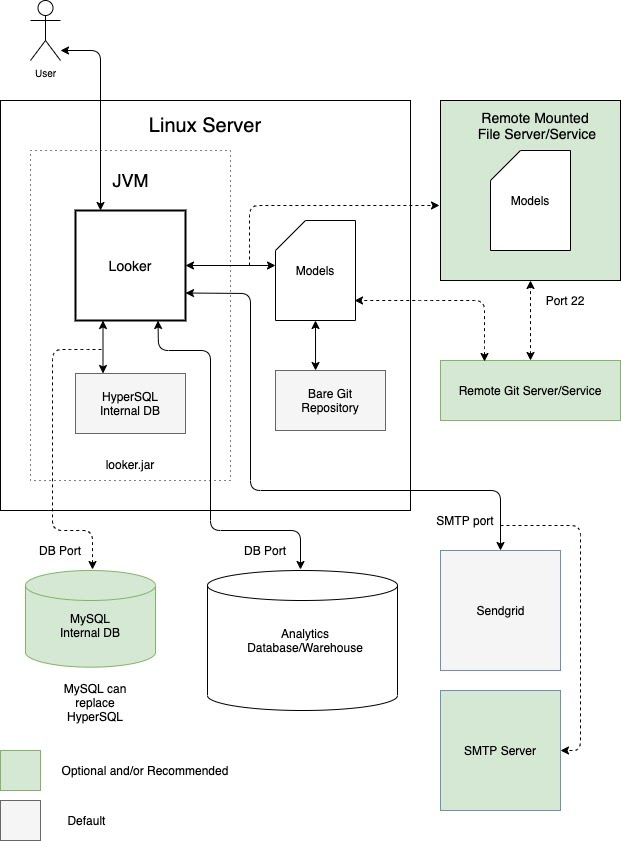
优点
- 专用虚拟机易于部署和维护。
- 内部数据库托管在 Looker 应用中。
- Looker 模型、Git 代码库、SMTP 服务器和后端数据库组件可以在本地或远程配置。
- 您可以将 Looker 的默认 SMTP 服务器替换为自己的服务器,以便发送电子邮件通知和执行预定任务。
最佳做法
- 默认情况下,Looker 可以为项目生成裸 Git 代码库。建议设置远程 Git 代码库以实现冗余。
-
默认情况下,Looker 会从内存中的 HyperSQL 数据库开始。此数据库方便轻巧,但在大量使用时可能会遇到性能问题。对于规模较大的部署,我们建议使用 MySQL 数据库。我们建议在
~/looker/.db/looker.script文件达到 600 MB 时迁移到远程 MySQL 数据库。 - 您的 Looker 部署需要针对 Looker 许可服务进行验证;需要通过端口 443 发送出站流量。
- 专用虚拟机部署可以通过增加可用资源和 Looker 线程池进行纵向扩缩。不过,一旦 RAM 达到 64 GB,增加 RAM 的回报就会递减,因为垃圾回收事件是单线程的,并且会暂停所有其他线程来执行。具有 16 个 CPU 和 64 GB RAM 的节点在价格和性能之间取得了良好的平衡。
- 我们建议您的部署使用每 GB 存储空间每秒 2 次操作 (IOPS) 的存储空间。
虚拟机集群
以跨多个虚拟机的实例集群形式运行 Looker 是一种灵活的模式,可受益于服务故障切换和冗余。横向可伸缩性可提高吞吐量,而不会导致堆膨胀和过高的垃圾收集成本。节点可以选择工作负载专用,从而根据不同的业务需求量身定制多种部署选项。集群部署需要至少一名熟悉 Linux 系统并能够管理组件部分的系统管理员。
标准集群
对于大多数标准部署,由相同服务节点组成的集群就足够了。集群中的所有节点都以相同的方式配置,并且都位于同一负载平衡器池中。在此配置中,所有节点服务 Looker 用户请求、渲染任务、预定任务、API 请求等的可能性都相同。
如果大多数请求直接来自正在运行查询并与 Looker 互动的 Looker 用户,则适合采用这种配置。当大量请求来自调度器、渲染器或其他来源时,它会开始崩溃。在这种情况下,指定某些服务节点来处理调度和渲染等任务是有益的。
例如,用户通常会安排在周一早上运行数据交付。如果用户在周一早上尝试运行 Looker 查询,可能会遇到性能问题,因为 Looker 正在处理积压的已安排请求。通过增加服务节点数量,集群可使 Looker 的所有功能在吞吐量方面实现相应提升。
下图展示了用户、应用和脚本向 Looker 发出的请求如何在集群 Looker 实例之间实现平衡。
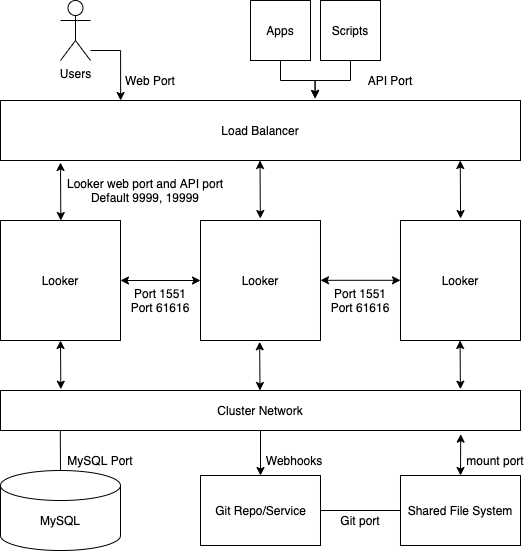
优点
- 标准集群可通过最少的集群拓扑配置最大限度地提高总体吞吐量。
- Java 虚拟机的性能会在分配的内存达到 64 GB 阈值时下降;这就是为什么横向伸缩比纵向伸缩更有回报。
- 集群配置可确保服务冗余和故障切换。
最佳做法
- 每个 Looker 节点都应托管在各自专用的虚拟机中。
- 作为集群入口点的负载均衡器应为第 4 层负载均衡器。它应具有较长的超时时间(3,600 秒),配备已签名的 SSL 证书,并配置为从 443(https)端口转发到 9999(Looker 服务器监听的端口)。
- 我们建议您的部署使用每 GB 2 IOPS 的存储空间。
开发/预发布/生产
对于优先考虑向最终用户提供尽可能长的内容正常运行时间的应用场景,我们建议使用单独的 Looker 环境来区分开发工作和分析工作。通过将生产环境变更限制在隔离的开发和测试环境中,此架构可尽可能保持生产环境的稳定性。
要获得这些好处,您需要设置互联环境并采用可靠的发布周期。开发/预发布/生产环境部署还需要一个熟悉 Looker API 和 Git 的开发者团队,以便进行工作流管理。
下图展示了 LookML 开发者(在开发实例上开发内容)、质量保证 (QA) 测试人员(在 QA 实例上测试内容)以及在生产环境实例上使用内容的用户、应用和脚本之间的内容流。
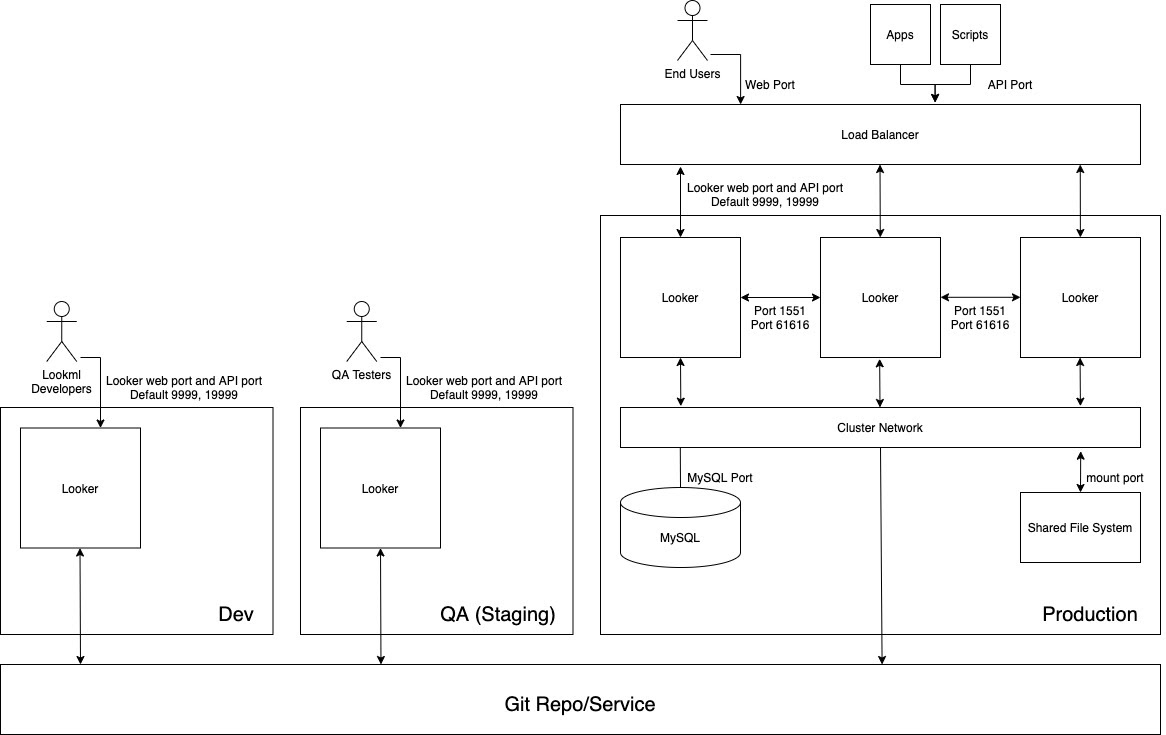
优点
- LookML 和内容验证在非生产环境中进行,确保在向生产用户发布之前,对模型逻辑的任何修改都可以经过全面审查。
- 在生产环境中启用实例级功能(例如实验室功能或身份验证协议)之前,可以先单独测试这些功能。
- 可以在非生产环境中测试数据组和缓存政策。
- Looker 生产模式测试与负责为最终用户提供服务的生产环境分离。
- 您可以在非生产环境中测试 Looker 版本,从而有充足的时间来测试新功能、工作流变更和问题,然后再更新生产环境。
最佳做法
- 隔离至少三个单独实例中同时发生的各种活动:
- 开发实例:开发者使用开发环境提交代码、进行实验、修复 bug 并安全地犯错。
- QA 实例:也称为测试或预演环境,开发者在此环境中运行手动和自动测试。QA 环境非常复杂,可能会消耗大量资源。
- 生产环境实例:这是为客户和/或企业创造价值的地方。生产环境是高度可见的环境,应无错误。
- 维护有据可查且可重复的发布周期工作流。
- 如果需要为大量开发者和质量检查测试人员提供服务,则可以对开发和/或质量检查实例进行集群化。无论是作为独立虚拟机还是虚拟机集群,开发和 QA 实例都需遵循相应部分中之前展示的相同架构注意事项。
高调度吞吐量
对于需要高计划数据传送吞吐量以及及时可靠传送的用例,我们建议配置包含一个节点池的集群,该节点池专门用于调度。此配置有助于确保 Web 应用和嵌入式应用快速响应。如需享受这些优势,您需要设置具有自定义启动选项和适当的负载均衡规则的节点,如以下图表所示,并如该选项的优势和最佳实践部分中所述。
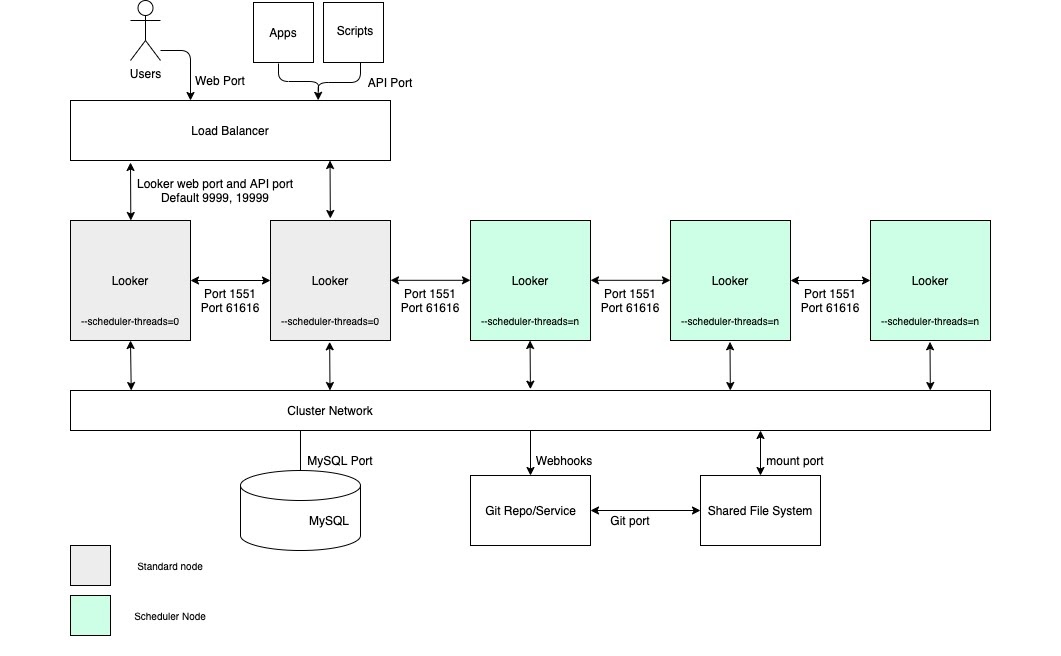
优点
- 为特定功能专用节点可将资源从开发和临时分析功能中分离出来,以便进行调度。
- 用户可以开发 LookML 并探索内容,而不会占用负责处理预定数据传送的节点的周期。
- 流向常规节点的高用户流量不会妨碍调度节点所服务的已调度工作负载。
最佳做法
- 每个 Looker 节点都应托管在各自专用的虚拟机中。
- 作为集群入口点的负载均衡器应为第 4 层负载均衡器。它应具有较长的超时时间(3,600 秒),配备已签名的 SSL 证书,并配置为从 443(https)端口转发到 9999(Looker 服务器监听的端口)。
- 从负载均衡规则中省略调度程序节点,以便它们不处理最终用户流量和内部 API 请求。
- 我们建议您的部署使用每 GB 2 IOPS 的存储空间。
高渲染吞吐量
对于需要高渲染报告吞吐量的使用情形,我们建议配置一个节点池专门用于渲染的集群。在 Looker 中,渲染 PDF 文件或 PNG/JPEG 图片是一项相对耗费资源的操作。渲染可能会占用大量内存和 CPU,当 Linux 内存不足时,可能会终止正在运行的进程。由于无法提前确定渲染作业的内存用量,因此启动渲染作业可能会导致 Looker 进程被终止。配置专用渲染节点可优化调整渲染作业,同时保持交互式应用和嵌入式应用的响应速度。
如需享受这些优势,您需要设置具有自定义启动选项和适当的负载平衡规则的节点,如以下图表所示,并如本选项的优势和最佳实践部分中所述。此外,渲染节点可能需要比标准节点更多的宿主资源,因为 Looker 的渲染服务依赖于共享 CPU 时间和内存的第三方 Chromium 进程。
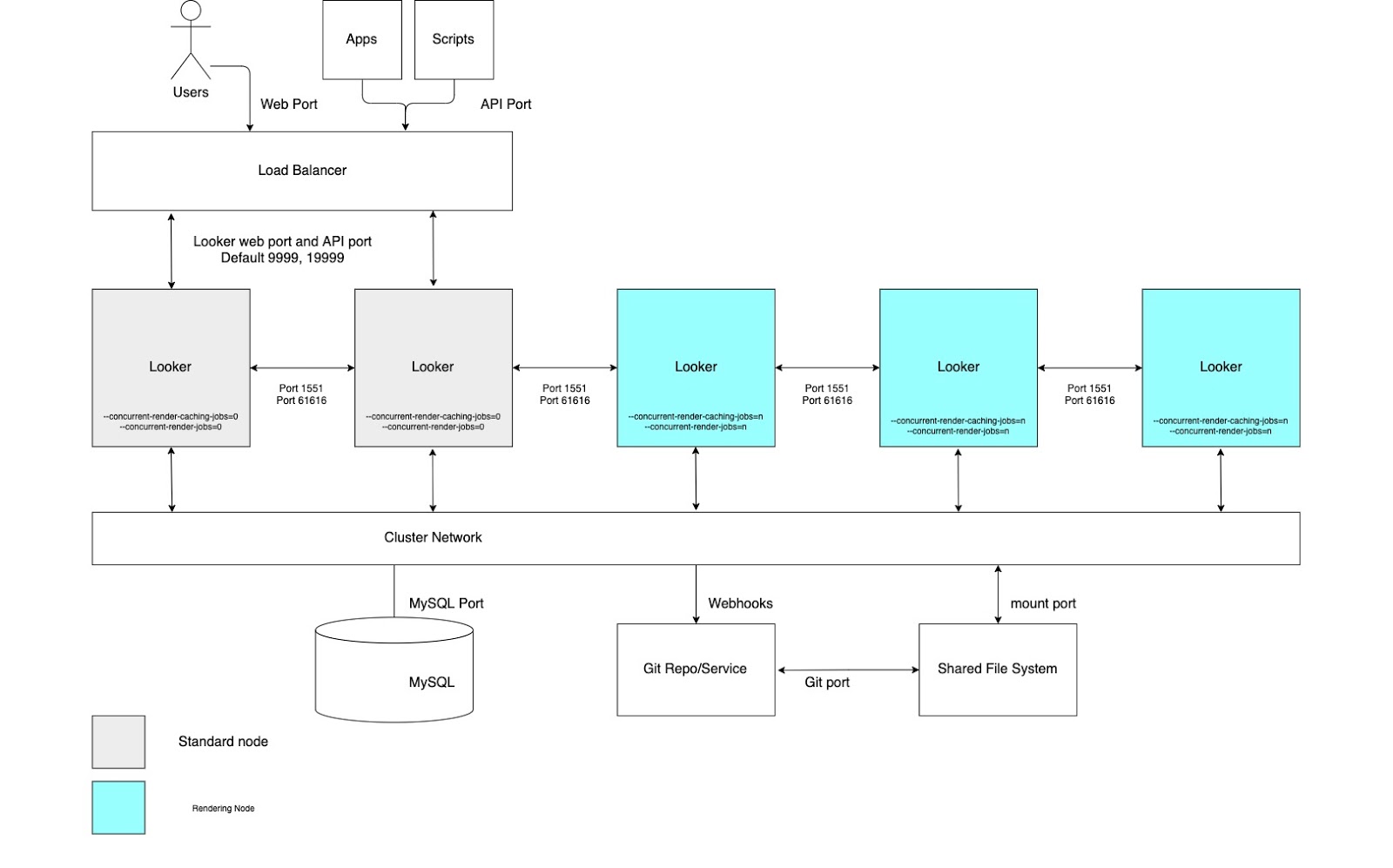
优点
- 为特定功能专用节点可将用于渲染的资源与开发和临时分析功能隔离开来。
- 用户可以开发 LookML 和探索内容,而不会占用负责渲染 PNG 和 PDF 的节点的周期。
- 流向常规节点的高用户流量不会妨碍由渲染节点提供服务的渲染工作负载。
最佳做法
- 每个 Looker 节点都应托管在各自专用的虚拟机中。
- 作为集群入口点的负载均衡器应为第 4 层负载均衡器。它应具有较长的超时时间(3,600 秒),配备已签名的 SSL 证书,并配置为从 443(https)端口转发到 9999(Looker 服务器监听的端口)。
- 从负载均衡规则中省略了渲染节点,因此这些节点不会处理最终用户流量和内部 API 请求。
- 在渲染节点中为 Java 分配相对较少的内存,以便为 Chromium 的进程提供更大的内存缓冲区。不要为 Java 分配 60% 的内存,而是分配 40-50% 的内存。
- 非渲染节点上的内存压力风险已降低,因此可以增加分配给 Looker 的内存量。建议您考虑使用更高的百分比,例如 80%,而不是默认的 60%。
- 我们建议您的部署使用每 GB 2 IOPS 的存储空间。