Esta página explora os padrões de arquitetura mais comuns para uma implementação alojada pelo cliente e descreve as práticas recomendadas para a respetiva implementação. Para usar esta página de forma eficaz, deve estar familiarizado com os conceitos e as práticas de arquitetura de sistemas.
Estratégia de fluxo de trabalho
Depois de identificar a auto-hospedagem como uma opção viável para a sua implementação do Looker, o passo seguinte é elaborar a estratégia a ser usada pela implementação.
- Faça uma avaliação. Identifique uma lista de candidatos de fluxos de trabalho planeados e existentes.
- Liste os padrões de arquitetura aplicáveis. Começando pelos fluxos de trabalho candidatos identificados, identifique os padrões de arquitetura aplicáveis.
- Priorize e selecione o padrão de arquitetura ideal. Alinhe o padrão de arquitetura com as tarefas e os resultados mais importantes.
- Configure os componentes de arquitetura e implemente a aplicação Looker. Implemente o anfitrião, as dependências de terceiros e a topologia de rede necessários para estabelecer ligações seguras de clientes.
Opções de arquitetura
Máquina virtual dedicada
Uma opção é executar o Looker como uma única instância numa máquina virtual (VM) dedicada. Uma única instância pode publicar cargas de trabalho exigentes ao dimensionar verticalmente o anfitrião e aumentar os conjuntos de threads predefinidos. No entanto, a sobrecarga de processamento da gestão de um grande conjunto de memória Java sujeita o escalamento vertical à lei dos rendimentos decrescentes. Geralmente, é aceitável para cargas de trabalho pequenas a médias. O diagrama seguinte representa as configurações predefinidas e opcionais entre uma instância do Looker que está a ser executada numa VM dedicada, os repositórios locais e remotos, os servidores SMTP e as origens de dados que estão realçadas nas secções Vantagens e Práticas recomendadas para esta opção.
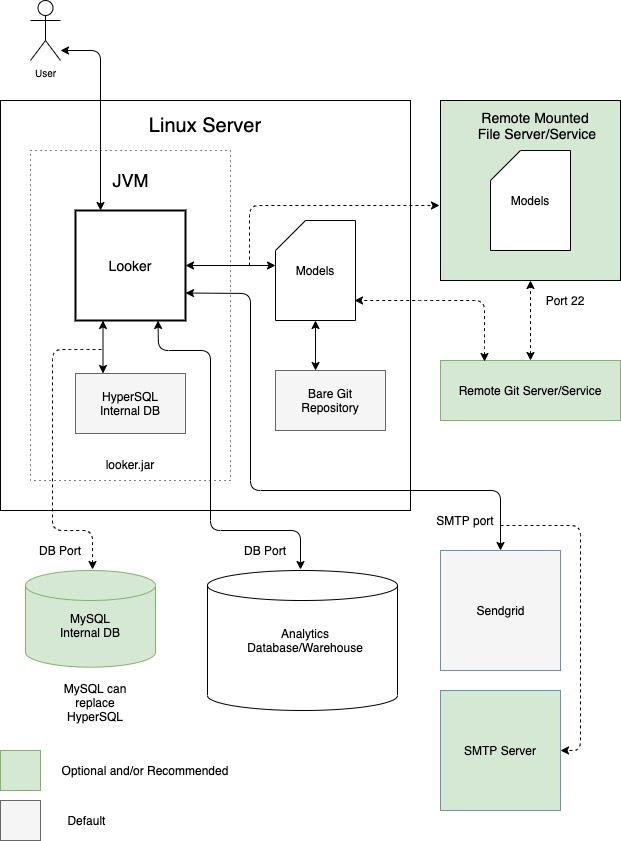
Vantagens
- Uma VM dedicada é fácil de implementar e manter.
- A base de dados interna está alojada na aplicação Looker.
- Os modelos do Looker, o repositório Git, o servidor SMTP e os componentes da base de dados de back-end podem ser configurados local ou remotamente.
- Pode substituir o servidor SMTP predefinido do Looker pelo seu próprio para notificações por email e tarefas agendadas.
Práticas recomendadas
- Por predefinição, o Looker pode gerar repositórios Git simples para um projeto. Recomendamos que configure um repositório Git remoto para redundância.
-
Por predefinição, o Looker começa com uma base de dados HyperSQL na memória. Esta base de dados é prática e leve, mas pode ter problemas de desempenho com uma utilização intensa. Recomendamos a utilização de uma base de dados MySQL para implementações maiores. Recomendamos a migração para uma base de dados MySQL remota assim que o ficheiro
~/looker/.db/looker.scriptatingir 600 MB. - A implementação do Looker tem de ser validada em relação ao serviço de licenciamento do Looker. É necessário tráfego de saída na porta 443.
- Uma implementação de VM dedicada pode ser dimensionada verticalmente através do aumento dos recursos disponíveis e dos conjuntos de threads do Looker. No entanto, o aumento da RAM está sujeito à lei dos rendimentos decrescentes quando atinge 64 GB, uma vez que os eventos de recolha de lixo são de thread único e param todas as outras threads para execução. Os nós com 16 CPUs e 64 GB de RAM representam um bom equilíbrio entre preço e desempenho.
- Recomendamos que a sua implementação tenha armazenamento com 2 operações por segundo (IOPS) por GB.
Cluster de VMs
Executar o Looker como um cluster de instâncias em várias VMs é um padrão flexível que beneficia da comutação por falha e da redundância do serviço. A escalabilidade horizontal permite um maior débito sem incorrer em inchaço da memória nem custos excessivos de recolha de lixo. Os nós têm a opção de dedicação da carga de trabalho, o que permite adaptar várias opções de implementação a diferentes requisitos empresariais. As implementações de clusters requerem, pelo menos, um administrador de sistemas familiarizado com os sistemas Linux e capaz de gerir os componentes.
Cluster padrão
Para a maioria das implementações padrão, um cluster de nós de serviço idênticos é suficiente. Todos os nós no cluster estão configurados da mesma forma e estão todos no mesmo conjunto do equilibrador de carga. Nenhum dos nós nesta configuração teria maior ou menor probabilidade de publicar pedidos de utilizadores do Looker, uma tarefa de renderização, uma tarefa agendada, um pedido de API, etc.
Este tipo de configuração é adequado quando a maioria dos pedidos provém diretamente de um utilizador do Looker que está a executar consultas e a interagir com o Looker. Começa a falhar quando um grande número de pedidos provém de um programador, um motor de renderização ou outra origem. Neste caso, é vantajoso designar determinados nós de serviço para processar tarefas como horários e renderização.
Por exemplo, os utilizadores agendam frequentemente as entregas de dados para serem executadas na manhã de segunda-feira. Um utilizador que tente executar consultas do Looker na manhã de segunda-feira pode ter problemas de desempenho enquanto o Looker trabalha no backlog de pedidos agendados. Ao aumentar o número de nós de serviço, o cluster oferece um aumento proporcional no débito em todas as capacidades do Looker.
O diagrama seguinte representa como os pedidos ao Looker feitos pelo utilizador, pelas apps e pelos scripts são equilibrados numa instância do Looker agrupada.
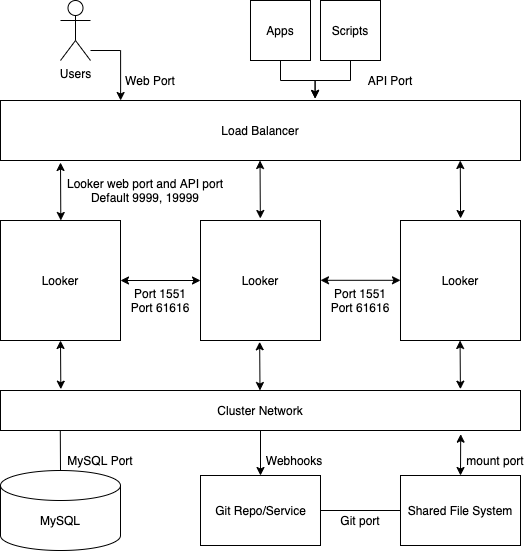
Vantagens
- Um cluster padrão maximiza o débito geral com uma configuração mínima da topologia do cluster.
- A VM Java sofre uma degradação do desempenho no limite de memória alocada de 64 GB. É por isso que o escalamento horizontal tem retornos maiores do que o escalamento vertical.
- Uma configuração de cluster garante a redundância e a comutação por falha do serviço.
Práticas recomendadas
- Cada nó do Looker deve ser alojado na sua própria VM dedicada.
- O balanceador de carga, que é o ponto de entrada do cluster, deve ser um balanceador de carga de camada 4. Deve ter um limite de tempo longo (3600 segundos), estar equipado com um certificado SSL assinado e estar configurado para o encaminhamento de portas de 443 (https) para 9999 (porta na qual o servidor do Looker escuta).
- Recomendamos que a sua implementação tenha armazenamento com 2 IOPS por GB.
Dev/Staging/Prod
Para exemplos de utilização que dão prioridade ao tempo de atividade máximo do conteúdo para os utilizadores finais, recomendamos ambientes do Looker separados para compartimentar o trabalho de desenvolvimento e o trabalho analítico. Ao restringir as alterações do ambiente de produção a ambientes de programação e teste isolados, esta arquitetura mantém um ambiente de produção o mais estável possível.
Estas vantagens requerem a configuração dos ambientes interligados e a adoção de um ciclo de lançamento robusto. Uma implementação de desenvolvimento/preparação/produção também requer uma equipa de programadores familiarizados com a API Looker e o Git para a administração do fluxo de trabalho.
O diagrama seguinte representa o fluxo de conteúdo entre os programadores de LookML que desenvolvem conteúdo na instância de desenvolvimento, os testadores de controlo de qualidade (CQ) que testam o conteúdo na instância de CQ e os utilizadores, as apps e os scripts que consomem o conteúdo na instância de produção.

Vantagens
- A validação do LookML e do conteúdo ocorre num ambiente de não produção, o que garante que todas as modificações à lógica do modelo podem ser exaustivamente avaliadas antes de chegarem aos utilizadores de produção.
- As funcionalidades ao nível da instância, como as funcionalidades do Labs ou os protocolos de autenticação, podem ser testadas isoladamente antes de serem ativadas no ambiente de produção.
- Os grupos de dados e as políticas de colocação em cache podem ser testados num ambiente de não produção.
- Os testes do modo de produção do Looker estão separados dos ambientes de produção responsáveis pela publicação para os utilizadores finais.
- Os lançamentos do Looker podem ser testados num ambiente de não produção, o que dá tempo suficiente para testar novas funcionalidades, alterações ao fluxo de trabalho e problemas antes de atualizar o ambiente de produção.
Práticas recomendadas
- Isolar as várias atividades que ocorrem em simultâneo em, pelo menos, três instâncias separadas:
- Instância de desenvolvimento: os programadores usam o ambiente de desenvolvimento para confirmar código, realizar experiências, corrigir erros e cometer erros em segurança.
- Instância de controlo de qualidade: também conhecida como ambiente de teste ou preparação, é onde os programadores executam testes manuais e automáticos. O ambiente de controlo de qualidade é complexo e pode consumir muitos recursos.
- Instância de produção: é aqui que o valor é criado para os clientes e/ou a empresa. A produção é um ambiente altamente visível e deve estar livre de erros.
- Mantenha um fluxo de trabalho do ciclo de lançamento documentado e repetível.
- Se for necessário publicar um grande volume de programadores e testadores de controlo de qualidade, as instâncias de desenvolvimento e/ou controlo de qualidade podem ser agrupadas. Quer sejam deixadas como uma VM autónoma ou um cluster de VMs, as instâncias de desenvolvimento e controlo de qualidade estão sujeitas às mesmas considerações de arquitetura apresentadas anteriormente nas respetivas secções.
Alto rendimento de agendamento
Para exemplos de utilização que requerem um débito de entrega de dados agendado elevado e entregas fiáveis e atempadas, recomendamos que a configuração inclua um cluster com um conjunto de nós dedicados exclusivamente ao agendamento. Esta configuração ajuda a manter a Web e as aplicações incorporadas rápidas e com capacidade de resposta. Estas vantagens requerem a configuração de nós com opções de arranque personalizadas e regras de equilíbrio de carga adequadas, conforme representado no diagrama seguinte e descrito nas secções Vantagens e Práticas recomendadas para esta opção.
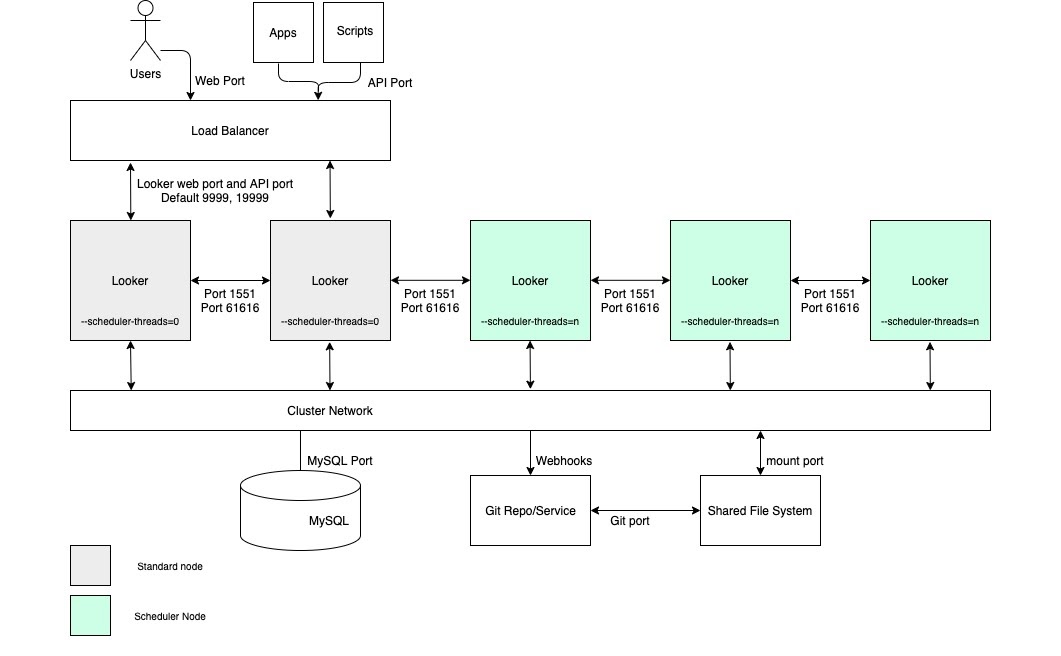
Vantagens
- A dedicação de nós a uma função específica compartimenta os recursos para agendamento a partir de funções de desenvolvimento e de estatísticas ad hoc.
- Os utilizadores podem desenvolver LookML e explorar conteúdo sem usar ciclos de nós responsáveis pela manutenção das entregas de dados agendadas.
- O elevado tráfego de utilizadores encaminhado para os nós normais não impede as cargas de trabalho agendadas processadas pelos nós de agendamento.
Práticas recomendadas
- Cada nó do Looker deve ser alojado na sua própria VM dedicada.
- O balanceador de carga, que é o ponto de entrada do cluster, deve ser um balanceador de carga de camada 4. Deve ter um limite de tempo longo (3600 segundos), estar equipado com um certificado SSL assinado e estar configurado para o encaminhamento de portas de 443 (https) para 9999 (porta na qual o servidor do Looker escuta).
- Omita os nós do programador das regras de equilíbrio de carga para que não publiquem tráfego de utilizadores finais nem pedidos de API internos.
- Recomendamos que a sua implementação tenha armazenamento com 2 IOPS por GB.
Débito de renderização elevado
Para exemplos de utilização que requerem um elevado débito de relatórios de renderização, recomendamos que configure um cluster com um conjunto de nós exclusivamente dedicados à renderização. A renderização de um ficheiro PDF ou de uma imagem PNG/JPEG é uma operação relativamente dispendiosa em termos de recursos no Looker. A renderização pode exigir muita memória e CPU e, quando o Linux está sob pressão de memória, pode terminar um processo em execução. Uma vez que não é possível determinar antecipadamente a utilização de memória de uma tarefa de renderização, o início de uma tarefa de renderização pode resultar na eliminação do processo do Looker. A configuração de nós de renderização dedicados permite uma otimização ideal das tarefas de renderização, ao mesmo tempo que preserva a capacidade de resposta da aplicação interativa e incorporada.
Estas vantagens requerem a configuração de nós com opções de arranque personalizadas e regras de equilíbrio de carga adequadas, conforme ilustrado no diagrama seguinte e explicado nas secções Vantagens e Práticas recomendadas para esta opção. Além disso, os nós de renderização podem exigir mais recursos do anfitrião do que os nós padrão, uma vez que o serviço de renderização do Looker depende de processos do Chromium de terceiros que partilham tempo de CPU e memória.
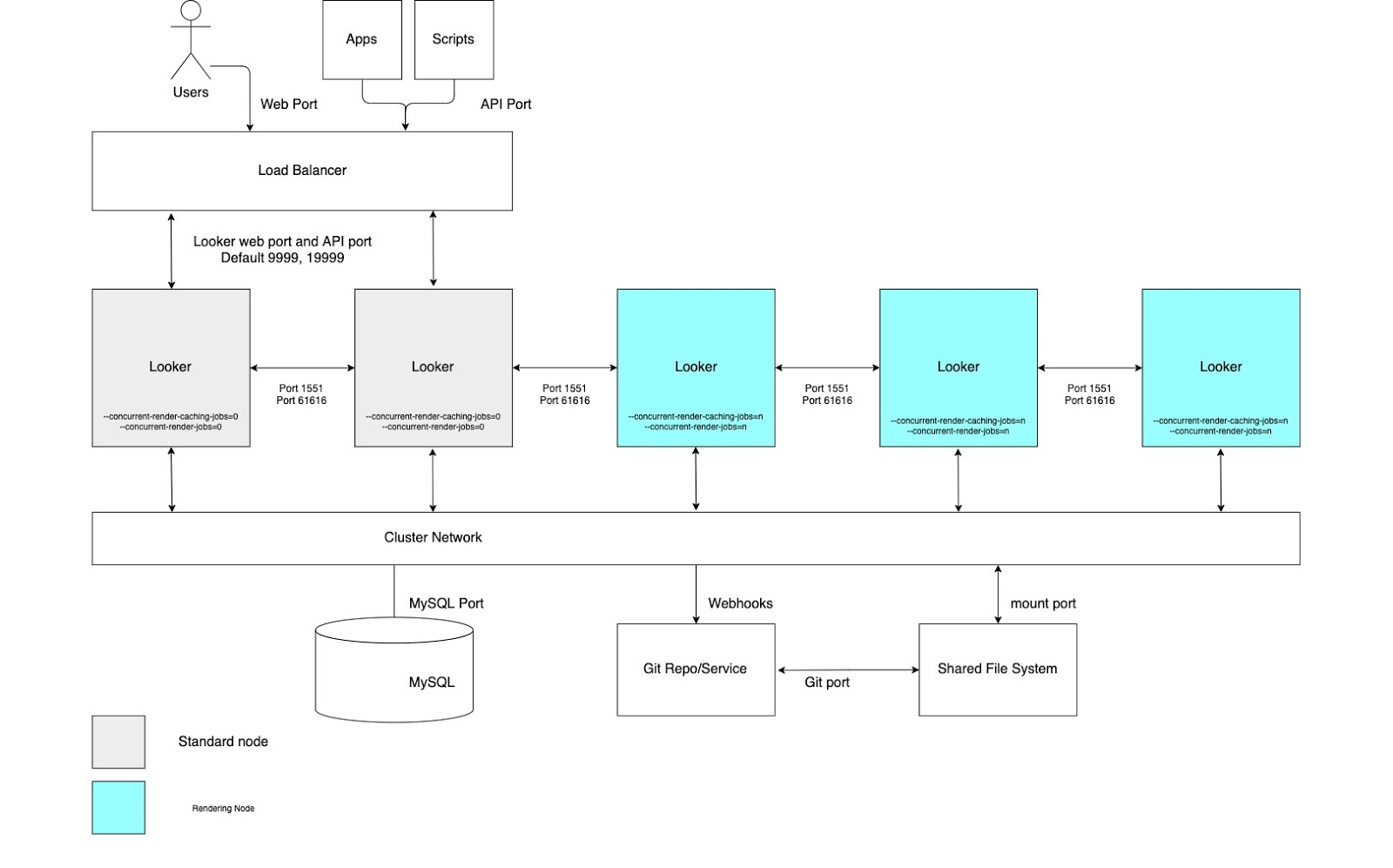
Vantagens
- A dedicação de nós a uma função específica compartimenta os recursos para a renderização das funções de desenvolvimento e de estatísticas ad hoc.
- Os utilizadores podem desenvolver LookML e explorar conteúdo sem usar ciclos dos nós responsáveis pela renderização de PNGs e PDFs.
- O elevado tráfego de utilizadores encaminhado para os nós normais não impede as cargas de trabalho de renderização que são processadas pelos nós de renderização.
Práticas recomendadas
- Cada nó do Looker deve ser alojado na sua própria VM dedicada.
- O balanceador de carga, que é o ponto de entrada do cluster, deve ser um balanceador de carga de camada 4. Deve ter um limite de tempo longo (3600 segundos), estar equipado com um certificado SSL assinado e estar configurado para o encaminhamento de portas de 443 (https) para 9999 (porta na qual o servidor do Looker escuta).
- Omitir nós de renderização das regras de equilíbrio de carga para que não publiquem tráfego de utilizadores finais nem pedidos de API internos.
- Atribuir relativamente menos memória ao Java nos nós de renderização para dar aos processos do Chromium uma memória intermédia maior. Em vez de atribuir 60% da memória ao Java, atribua 40 a 50%.
- O risco de pressão na memória foi reduzido nos nós de não renderização, pelo que a quantidade de memória dedicada ao Looker pode ser aumentada. Em vez dos 60% predefinidos, considere um número mais elevado, como 80%.
- Recomendamos que a sua implementação tenha armazenamento com 2 IOPS por GB.