Per ulteriori dettagli, consulta la pagina della documentazione relativa alla consapevolezza aggregata.
Introduzione
Questa pagina è una guida per l'implementazione della consapevolezza aggregata in uno scenario pratico, tra cui l'identificazione delle opportunità di implementazione, il valore che genera la consapevolezza aggregata e un semplice flusso di lavoro per implementarla in un modello reale. Questa pagina non è una spiegazione approfondita di tutte le funzionalità di consapevolezza aggregata o di tutti i casi limite, né un catalogo esaustivo di tutte le sue funzionalità.
Che cos'è la notorietà aggregata?
In Looker, le query vengono eseguite principalmente su tabelle o viste non elaborate nel database. A volte si tratta di tabelle derivate permanenti (PDT) di Looker.
Spesso potresti incontrare tabelle o set di dati molto grandi che, per essere efficienti, richiedono tabelle di aggregazione o roll-up.
In genere, puoi creare tabelle di aggregazione come una tabella orders_daily che contiene una dimensionalità limitata. Questi devono essere trattati e modellati separatamente in Esplora e non si adattano perfettamente al modello. Queste limitazioni comportano esperienze utente scadenti quando l'utente deve scegliere tra più esplorazioni per gli stessi dati.
Ora, con la consapevolezza degli aggregati di Looker, puoi pre-costruire tabelle aggregate a vari livelli di granularità, dimensionalità e aggregazione e puoi comunicare a Looker come utilizzarle all'interno delle esplorazioni esistenti. Le query utilizzeranno queste tabelle di riepilogo quando Looker lo riterrà opportuno, senza alcun input utente'utente. In questo modo, la dimensione delle query verrà ridotta, i tempi di attesa diminuiranno e l'esperienza utente migliorerà.
NOTA:le tabelle aggregate di Looker sono un tipo di tabella derivata permanente (PDT). Ciò significa che le tabelle aggregate hanno gli stessi requisiti di database e connessione delle PDT.Per verificare se il dialetto del database e la connessione Looker possono supportare le PDT, consulta i requisiti elencati nella pagina della documentazione Tabelle derivate in Looker.
Per verificare se il dialetto del tuo database supporta la consapevolezza degli aggregati, consulta la pagina della documentazione Consapevolezza degli aggregati.
Il valore della notorietà aggregata
Esistono diverse proposte di valore significative che offrono consapevolezza aggregata per generare valore aggiuntivo dal tuo modello Looker esistente:
- Miglioramento delle prestazioni: l'implementazione del riconoscimento degli aggregati renderà più veloci le query degli utenti. Looker utilizzerà una tabella più piccola se contiene i dati necessari per completare la query dell'utente.
- Risparmio sui costi:alcuni dialetti vengono addebitati in base alle dimensioni della query in un modello di consumo. Se Looker esegue query su tabelle più piccole, il costo per query utente sarà inferiore.
- Miglioramento dell'esperienza utente: oltre a un'esperienza migliorata che recupera le risposte più rapidamente, il consolidamento elimina la creazione ridondante di esplorazioni.
- Impronta LookML ridotta:la sostituzione delle strategie di riconoscimento degli aggregati esistenti basate su Liquid con un'implementazione nativa flessibile comporta una maggiore resilienza e un numero inferiore di errori.
- Possibilità di sfruttare LookML esistente:le tabelle aggregate utilizzano l'oggetto
query, che riutilizza la logica modellata esistente anziché duplicarla con SQL personalizzato esplicito.
Esempio di base
Ecco un'implementazione molto semplice in un modello Looker per dimostrare quanto possa essere leggero il riconoscimento degli aggregati. Data una tabella ipotetica flights nel database con una riga per ogni volo registrato tramite la FAA, possiamo modellare questa tabella in Looker con una propria visualizzazione ed esplorazione. Ecco il codice LookML per una tabella aggregata che possiamo definire per l'esplorazione:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Con questa tabella aggregata, un utente può eseguire query nell'esplorazione flights e Looker utilizzerà automaticamente la tabella aggregata definita in LookML e la userà per rispondere alle query. L'utente non dovrà comunicare a Looker condizioni speciali: se la tabella è adatta ai campi selezionati dall'utente, Looker la utilizzerà.
Gli utenti con autorizzazioni see_sql possono utilizzare i commenti nella scheda SQL di un'esplorazione per vedere quale tabella aggregata verrà utilizzata per una query. Ecco un esempio della scheda SQL di Looker per una query che utilizza la tabella aggregata flights:flights_by_week_and_carrier in teach_scratch:
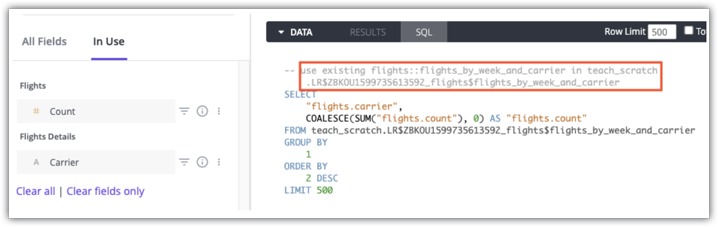
Per informazioni dettagliate su come determinare se le tabelle aggregate vengono utilizzate per una query, consulta la pagina della documentazione Riconoscimento degli aggregati.
Identificare le opportunità
Per massimizzare i vantaggi della notorietà aggregata, devi identificare in quali casi può svolgere un ruolo nell'ottimizzazione o nell'aumento del valore della notorietà aggregata.
Identificare i dashboard con un runtime elevato
Un'ottima opportunità per il riconoscimento degli aggregati è creare tabelle aggregate per le dashboard molto utilizzate con un runtime molto elevato. Potresti ricevere segnalazioni dai tuoi utenti in merito alla lentezza delle dashboard, ma se hai see_system_activity, puoi anche utilizzare l'esplorazione della cronologia dell'attività di sistema di Looker per trovare le dashboard con un runtime più lento della media. Come scorciatoia, puoi utilizzare il seguente URL in un browser, sostituendo HOSTNAME con il nome dell'istanza di Looker (ad esempio example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
Verrà visualizzata una visualizzazione di Esplora con i dati sulle dashboard della tua istanza, tra cui Titolo, Cronologia, Conteggio delle esplorazioni, Rapporto tra cache e database e Rendimento inferiore alla media:
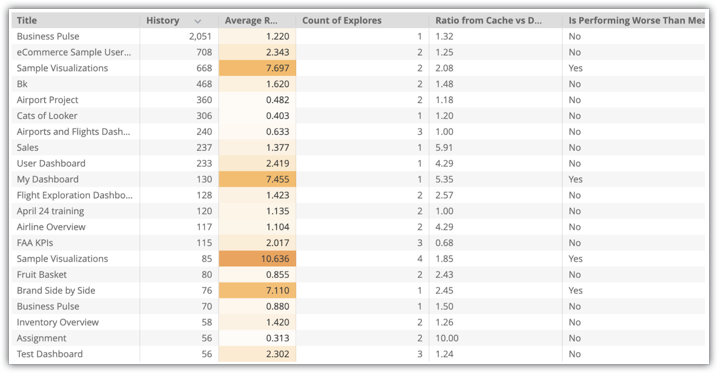
In questo esempio, ci sono diverse dashboard con un utilizzo elevato che hanno un rendimento inferiore alla media, come la dashboard Visualizzazioni di esempio. La dashboard Visualizzazioni di esempio utilizza due esplorazioni, quindi una buona strategia sarebbe quella di creare tabelle aggregate per entrambe.
Identificare le esplorazioni lente e con molte query degli utenti
Un'altra opportunità per la consapevolezza aggregata è rappresentata dalle esplorazioni per le quali gli utenti eseguono molte query e che hanno una risposta alla query inferiore alla media.
Puoi utilizzare l'esplorazione della cronologia attività di sistema come punto di partenza per identificare le opportunità di ottimizzazione delle esplorazioni. Come scorciatoia, puoi utilizzare il seguente URL in un browser, sostituendo HOSTNAME con il nome dell'istanza di Looker (ad esempio example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Verrà visualizzata una visualizzazione di Esplora con i dati relativi alle esplorazioni della tua istanza, tra cui Esplora, Modello, Conteggio esecuzioni query, Conteggio utenti e Tempo di esecuzione medio in secondi:

In Esplora cronologia puoi identificare i seguenti tipi di esplorazioni nella tua istanza:
- Esplorazioni su cui gli utenti eseguono query (anziché query dall'API o da consegne pianificate)
- Esplorazioni spesso richieste
- Esplorazioni con un rendimento scarso (rispetto ad altre esplorazioni)
Nell'esempio precedente di esplorazione della cronologia dell'attività di sistema, le esplorazioni flights e order_items sono candidati probabili per l'implementazione della consapevolezza aggregata.
Identifica i campi utilizzati di frequente nelle query
Infine, puoi identificare altre opportunità a livello di dati comprendendo i campi che gli utenti includono comunemente nelle query e nei filtri.
Come scorciatoia, puoi utilizzare il seguente URL in un browser, sostituendo HOSTNAME con il nome dell'istanza di Looker (ad esempio example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Sostituisci i filtri di conseguenza. Vedrai un'esplorazione con una visualizzazione a grafico a barre che indica il numero di volte in cui un campo è stato utilizzato in una query:
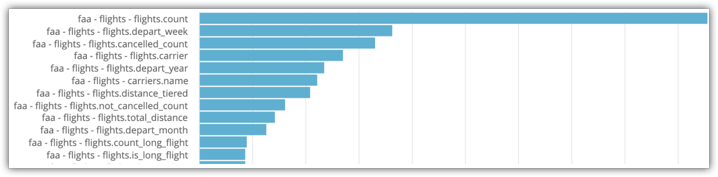
Nell'esplorazione Attività di sistema mostrata nell'immagine, puoi vedere che flights.count e flights.depart_week sono i due campi selezionati più di frequente per l'esplorazione. Pertanto, questi campi sono buoni candidati per essere inclusi nelle tabelle aggregate.
Dati concreti come questi sono utili, ma ci sono elementi soggettivi che guideranno i tuoi criteri di selezione. Ad esempio, esaminando i quattro campi precedenti, puoi presumere con certezza che gli utenti consultino spesso il numero di voli programmati e il numero di voli cancellati e che vogliano analizzare questi dati sia per settimana che per compagnia aerea. Questo è un esempio di combinazione chiara, logica e reale di campi e metriche.
Riepilogo
I passaggi descritti in questa pagina della documentazione devono fungere da guida per trovare dashboard, esplorazioni e campi da prendere in considerazione per l'ottimizzazione. È anche importante capire che tutti e tre potrebbero escludersi a vicenda: le dashboard problematiche potrebbero non essere basate sulle esplorazioni problematiche e la creazione di tabelle aggregate con i campi di uso comune potrebbe non essere utile per queste dashboard. È possibile che si tratti di tre implementazioni distinte del riconoscimento degli aggregati.
Progettazione di tabelle aggregate
Dopo aver identificato le opportunità per la consapevolezza aggregata, puoi progettare tabelle aggregate che rispondano al meglio a queste opportunità. Consulta la pagina della documentazione relativa alla consapevolezza aggregata per informazioni sui campi, sulle metriche e sui periodi di tempo supportati nelle tabelle aggregate, nonché su altre linee guida per la progettazione di tabelle aggregate.
NOTA:le tabelle aggregate non devono corrispondere esattamente alla query per essere utilizzate. Se la query ha una granularità settimanale e disponi di una tabella di riepilogo giornaliera, Looker utilizzerà la tabella aggregata anziché quella non elaborata a livello di timestamp. Allo stesso modo, se hai una tabella aggregata di cui è stato eseguito il rollup a livello dibrandedatee un utente esegue una query solo a livello dibrand, la tabella è comunque un candidato per l'utilizzo da parte di Looker per la consapevolezza dell'aggregazione.
La consapevolezza degli aggregati è supportata per le seguenti misure:
- Misure standard : misure di tipo SUM, COUNT, AVERAGE, MIN e MAX
- Misure composite: misure di tipo NUMBER, STRING, YESNO e DATE
- Misure distinte approssimative : dialetti che possono utilizzare la funzionalità HyperLogLog
La consapevolezza aggregata non è supportata per le seguenti misure:
- Misure distinte:poiché la distinzione può essere calcolata solo su dati atomici non aggregati, le misure
*_DISTINCTnon sono supportate al di fuori di queste approssimazioni che utilizzano HyperLogLog. - Misure basate sulla cardinalità:come per le misure distinte, mediane e percentili non possono essere pre-aggregate e non sono supportati.
NOTA: se conosci una potenziale query utente con tipi di misure non supportati dalla consapevolezza aggregata, questo è un caso in cui potresti voler creare una tabella aggregata che corrisponda esattamente a una query. Una tabella aggregata che corrisponde esattamente alla query può essere utilizzata per rispondere a una query con tipi di misura che altrimenti non sarebbero supportati per la consapevolezza dell'aggregazione.
Granularità della tabella aggregata
Prima di creare tabelle per combinazioni di dimensioni e misure, devi determinare i pattern di utilizzo e la selezione dei campi comuni per creare tabelle aggregate che verranno utilizzate il più spesso possibile con il massimo impatto. Tieni presente che tutti i campi utilizzati nella query (selezionati o filtrati) devono essere presenti nella tabella aggregata affinché la tabella possa essere utilizzata per la query. Tuttavia, come indicato in precedenza, la tabella aggregata non deve corrispondere esattamente a una query per essere utilizzata per la query. Puoi rispondere a molte potenziali query degli utenti all'interno di una singola tabella aggregata e ottenere comunque un notevole miglioramento delle prestazioni.
Dall'esempio di identificazione dei campi utilizzati di frequente nelle query, sono presenti due dimensioni (flights.depart_week e flights.carrier) selezionate molto spesso, nonché due misure (flights.count e flights.cancelled_count). Pertanto, sarebbe logico creare una tabella aggregata che utilizzi tutti e quattro questi campi. Inoltre, la creazione di una singola tabella aggregata per flights_by_week_and_carrier comporterà un utilizzo più frequente della tabella aggregata rispetto a due tabelle aggregate diverse per le tabelle flights_by_week e flights_by_carrier.
Ecco un esempio di tabella aggregata che potremmo creare per le query sui campi comuni:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Gli utenti aziendali e le prove aneddotiche, nonché i dati dell'attività di sistema di Looker, possono aiutarti a guidare il processo decisionale.
Equilibrio tra applicabilità e rendimento
Il seguente esempio mostra una query di esplorazione dei campi Flights Depart Week, Flights Details Carrier, Flights Count e Flights Detailed Cancelled Count della tabella aggregata flights_by_week_and_carrier:
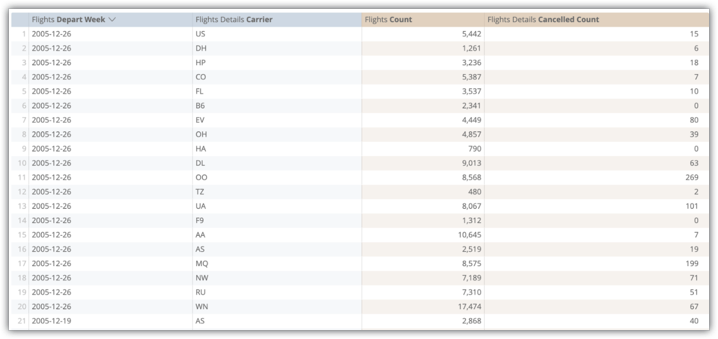
L'esecuzione di questa query dalla tabella di database originale ha richiesto 15,8 secondi e ha analizzato 38 milioni di righe senza join utilizzando Amazon Redshift. Il pivot della query, che sarebbe una normale operazione dell'utente, ha richiesto 29,5 secondi.
Dopo l'implementazione della tabella aggregata flights_by_week_and_carrier, la query successiva ha impiegato 7,2 secondi e ha analizzato 4592 righe. Si tratta di una riduzione delle dimensioni della tabella del 99,98%. La rotazione della query ha richiesto 9,8 secondi.
Dall'esplorazione Utilizzo dei campi dell'attività di sistema, possiamo vedere la frequenza con cui gli utenti includono questi campi nelle query. In questo esempio, flights.count è stato utilizzato 47.848 volte, flights.depart_week 18.169 volte, flights.cancelled_count 16.570 volte e flights.carrier 13.517 volte.
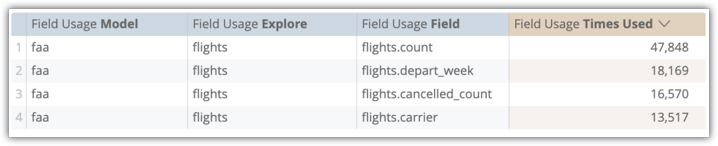
Anche se abbiamo stimato in modo molto modesto che il 25% di queste query utilizzava tutti e quattro i campi nel modo più semplice (selezione semplice, senza pivot), 3379 x 8, 6 secondi = 8 ore e 4 minuti di tempo di attesa aggregato degli utenti eliminato.
NOTA:il modello di esempio utilizzato qui è molto semplice. Questi risultati non devono essere utilizzati come benchmark o quadro di riferimento per il tuo modello.
Dopo aver applicato lo stesso flusso al nostro modello di e-commerce order_items, l'esplorazione più utilizzata nell'istanza, i risultati sono i seguenti:
| Origine | Ora di esecuzione della query | Righe scansionate |
|---|---|---|
| Tabella base | 13,1 secondi | 285.000 |
| Tabella aggregata | 5,1 secondi | 138.000 |
| Delta | 8 secondi | 147.000 |
I campi utilizzati nella query e nella successiva tabella aggregata erano brand, created_date, orders_count e total_revenue, utilizzando due unioni. I campi erano stati utilizzati un totale di 11.000 volte. Stimando lo stesso utilizzo combinato di circa il 25%, il risparmio aggregato per gli utenti sarebbe di 6 ore e 6 minuti (8 secondi * 2750 = 22.000 secondi). La creazione della tabella aggregata ha richiesto 17,9 secondi.
Esaminando questi risultati, vale la pena fare un passo indietro e valutare i rendimenti potenzialmente ottenuti da:
- Ottimizzazione di modelli/Esplorazioni più grandi e complessi che hanno prestazioni "accettabili" e che possono migliorare grazie a pratiche di modellazione migliori
rispetto a
- Utilizzo della consapevolezza aggregata per ottimizzare i modelli più semplici, utilizzati più di frequente e con un rendimento scarso
Man mano che cerchi di ottenere l'ultimo bit di rendimento da Looker e dal tuo database, vedrai rendimenti decrescenti per i tuoi sforzi. Devi sempre essere consapevole delle aspettative di rendimento di base, in particolare degli utenti aziendali, e delle limitazioni imposte dal tuo database (come concorrenza, soglie di query, costi e così via). Non dovresti aspettarti che la consapevolezza aggregata superi queste limitazioni.
Inoltre, quando progetti una tabella aggregata, ricorda che avere più campi comporterà una tabella aggregata più grande e più lenta. Le tabelle più grandi possono ottimizzare più query e quindi essere utilizzate in più situazioni, ma non saranno veloci come le tabelle più piccole e semplici.
Ad esempio:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}In questo modo, la tabella aggregata viene utilizzata per qualsiasi combinazione di dimensioni mostrate e per qualsiasi misura inclusa, quindi può essere utilizzata per rispondere a molte query utente diverse. Tuttavia,per utilizzare questa tabella per una semplice query SELECT di carrier e count sarebbe necessaria una scansione di una tabella di 885.000 righe. Al contrario, la stessa query richiederebbe solo la scansione di 4592 righe se la tabella fosse basata su due dimensioni. La tabella da 885.000 righe rappresenta comunque una riduzione del 97% delle dimensioni della tabella (rispetto alle 38 milioni di righe precedenti), ma l'aggiunta di un'altra dimensione aumenta le dimensioni della tabella a 20 milioni di righe. Pertanto, i rendimenti diminuiscono man mano che includi più campi nella tabella aggregata per aumentare la sua applicabilità a più query.
Creazione di tabelle aggregate
Prendendo come esempio Voli Esplora, che abbiamo identificato come opportunità di ottimizzazione, la strategia migliore sarebbe quella di creare tre diverse tabelle aggregate:
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
Il modo più semplice per creare queste tabelle aggregate è ottenere il LookML della tabella aggregata da una query Explore o da una dashboard e aggiungere il LookML ai file di progetto Looker.
Una volta aggiunte le tabelle aggregate al progetto LookML e implementati gli aggiornamenti in produzione, le esplorazioni utilizzeranno le tabelle aggregate per le query degli utenti.
Persistenza
Per essere accessibili per la consapevolezza aggregata, le tabelle aggregate devono essere persistenti nel database. La best practice prevede di allineare la rigenerazione automatica di queste tabelle aggregate ai tuoi criteri di memorizzazione nella cache utilizzando i datagroup. Devi utilizzare lo stesso gruppo di dati per una tabella aggregata utilizzata per l'esplorazione associata. Se non puoi utilizzare i gruppi di dati, un'opzione alternativa è utilizzare il parametro sql_trigger_value. Di seguito è riportato un valore generico basato sulla data per sql_trigger_value:
sql_trigger_value: SELECT CURRENT_DATE() ;;
In questo modo, le tabelle aggregate verranno create automaticamente ogni giorno a mezzanotte.
Logica del periodo di tempo
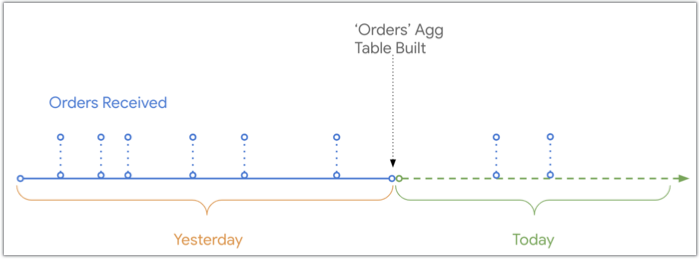
Quando Looker crea una tabella aggregata, include i dati fino al momento in cui è stata creata. Qualsiasi dato aggiunto successivamente alla tabella di base nel database viene normalmente escluso dai risultati di una query che utilizza quella tabella aggregata.
Questo diagramma mostra la cronologia di quando gli ordini sono stati ricevuti e registrati nel database rispetto al momento in cui è stata creata la tabella aggregata Ordini. Oggi sono stati ricevuti due ordini che non saranno presenti nella tabella aggregata Ordini, in quanto sono stati ricevuti dopo la creazione della tabella aggregata:
Tuttavia, Looker può UNIRE i dati aggiornati alla tabella aggregata quando un utente esegue una query per un periodo di tempo che si sovrappone alla tabella aggregata, come illustrato nello stesso diagramma della cronologia:
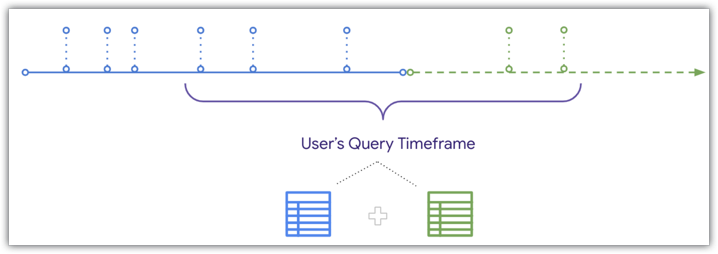
Poiché Looker può unire i dati aggiornati a una tabella aggregata, se un utente filtra un periodo di tempo che si sovrappone alla fine sia della tabella aggregata che di quella di base, gli ordini ricevuti dopo la creazione della tabella aggregata verranno inclusi nei risultati dell'utente. Per informazioni dettagliate e per conoscere le condizioni da soddisfare per unire i dati aggiornati alle query delle tabelle aggregate, consulta la pagina della documentazione Consapevolezza aggregata.
Riepilogo
Ricapitolando, per creare un'implementazione del riconoscimento degli aggregati, sono necessari tre passaggi fondamentali:
- Identifica le opportunità in cui l'ottimizzazione tramite le tabelle aggregate è appropriata e ha un impatto.
- Progetta tabelle aggregate che forniscano la massima copertura per le query utente comuni, rimanendo comunque abbastanza piccole da ridurre sufficientemente le dimensioni di queste query.
- Crea le tabelle aggregate nel modello Looker, associando la persistenza della tabella a quella della cache di Esplora.