Pour en savoir plus, consultez la page de documentation Notion globale de la notoriété.
Introduction
Cette page est un guide pour implémenter la prise de conscience des agrégats dans un scénario pratique. Elle explique comment identifier les opportunités d'implémentation, la valeur que génère la prise de conscience des agrégats et un workflow simple pour l'implémenter dans un modèle réel. Cette page ne fournit pas d'explication détaillée de toutes les fonctionnalités de sensibilisation agrégée ni de tous les cas extrêmes. Elle ne constitue pas non plus un catalogue exhaustif de toutes ses fonctionnalités.
Qu'est-ce que la notoriété globale ?
Dans Looker, vous interrogez principalement les tables brutes ou les vues de votre base de données. Il s'agit parfois de tables dérivées persistantes (PDT) Looker.
Vous pouvez souvent rencontrer des ensembles de données ou des tables très volumineux qui, pour être performants, nécessitent des tables d'agrégation ou des cumuls.
En général, vous pouvez créer des tables d'agrégation telles qu'une table orders_daily contenant une dimensionnalité limitée. Elles doivent être traitées et modélisées séparément dans Explorer, et ne s'intègrent pas facilement au modèle. Ces limites entraînent une mauvaise expérience utilisateur lorsque l'utilisateur doit choisir entre plusieurs explorations pour les mêmes données.
Grâce à la reconnaissance des agrégats de Looker, vous pouvez désormais préconstruire des tables agrégées à différents niveaux de granularité, de dimensionnalité et d'agrégation. Vous pouvez également indiquer à Looker comment les utiliser dans les explorations existantes. Looker utilisera ensuite ces tables récapitulatives lorsque cela sera approprié, sans aucune intervention de l'utilisateur. Cela permettra de réduire la taille des requêtes et les temps d'attente, et d'améliorer l'expérience utilisateur.
REMARQUE : Les tables agrégées de Looker sont un type de table dérivée persistante (PDT). Cela signifie que les tables agrégées ont les mêmes exigences en termes de base de données et de connexion que les PDT.Pour savoir si votre dialecte de base de données et votre connexion Looker sont compatibles avec les tables PDT, consultez les exigences listées sur la page de documentation Tables dérivées dans Looker.
Pour savoir si votre dialecte de base de données est compatible avec la reconnaissance des agrégats, consultez la page de documentation Reconnaissance des agrégats.
La valeur de la notoriété globale
L'agrégation de la couverture offre plusieurs propositions de valeur importantes pour générer une valeur supplémentaire à partir de votre modèle Looker existant :
- Amélioration des performances : l'implémentation de la reconnaissance d'agrégats accélère les requêtes utilisateur. Looker utilisera une table plus petite si elle contient les données nécessaires pour répondre à la requête de l'utilisateur.
- Économies : certains dialectes facturent la taille des requêtes selon un modèle de consommation. En demandant à Looker d'interroger des tables plus petites, vous réduirez le coût par requête utilisateur.
- Amélioration de l'expérience utilisateur : en plus d'une expérience améliorée qui permet d'obtenir des réponses plus rapidement, la consolidation élimine la création d'explorations redondantes.
- Empreinte LookML réduite : le remplacement des stratégies de reconnaissance des agrégats existantes basées sur Liquid par une implémentation native flexible permet d'accroître la résilience et de réduire le nombre d'erreurs.
- Possibilité d'exploiter le code LookML existant : les tables agrégées utilisent l'objet
query, qui réutilise la logique modélisée existante au lieu de la dupliquer avec du code SQL personnalisé explicite.
Exemple de base
Voici une implémentation très simple dans un modèle Looker pour montrer à quel point la reconnaissance des agrégats légers peut être. Prenons l'exemple d'une table flights hypothétique dans la base de données, avec une ligne pour chaque vol enregistré par la FAA. Nous pouvons modéliser cette table dans Looker avec sa propre vue et son propre Explore. Voici le code LookML d'une table agrégée que nous pouvons définir pour l'exploration :
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Avec ce tableau agrégé, un utilisateur peut interroger l'exploration flights. Looker utilisera automatiquement le tableau agrégé défini dans le code LookML pour répondre aux requêtes. L'utilisateur n'a pas besoin d'informer Looker de conditions spéciales : si la table correspond aux champs qu'il sélectionne, Looker l'utilisera.
Les utilisateurs disposant des autorisations see_sql peuvent utiliser les commentaires de l'onglet SQL d'une exploration pour voir quelle table agrégée sera utilisée pour une requête. Voici un exemple d'onglet SQL Looker pour une requête qui utilise la table agrégée flights:flights_by_week_and_carrier in teach_scratch :
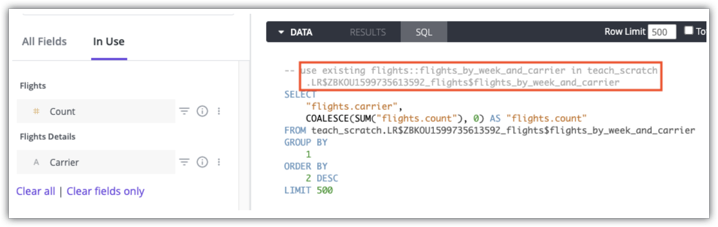
Pour savoir si des tables agrégées sont utilisées pour une requête, consultez la page de documentation sur la conscience de l'agrégation.
Identifier les opportunités
Pour maximiser les avantages de la notoriété agrégée, vous devez identifier où elle peut jouer un rôle dans l'optimisation ou dans la génération de la valeur de la notoriété agrégée.
Identifier les tableaux de bord dont le temps d'exécution est élevé
Une excellente occasion de créer des tables agrégées est de le faire pour les tableaux de bord très utilisés et dont le temps d'exécution est très élevé. Vos utilisateurs peuvent vous signaler des tableaux de bord lents, mais si vous avez see_system_activity, vous pouvez également utiliser l'explorateur "Historique de l'activité système" de Looker pour trouver les tableaux de bord dont le temps d'exécution est plus lent que la moyenne. Pour faire plus simple, vous pouvez utiliser l'URL suivante dans un navigateur, en remplaçant HOSTNAME par le nom de votre instance Looker (par exemple, example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
Vous verrez une visualisation "Explorer" avec des données sur les tableaux de bord de votre instance, y compris Titre, Historique, Nombre d'explorations, Ratio du cache par rapport à la base de données et Performances inférieures à la moyenne :

Dans cet exemple, plusieurs tableaux de bord à forte utilisation sont moins performants que la moyenne, comme le tableau de bord Exemples de visualisations. Le tableau de bord Exemples de visualisations utilise deux explorations. Une bonne stratégie consiste donc à créer des tables agrégées pour ces deux explorations.
Identifier les explorations lentes et fréquemment interrogées par les utilisateurs
Une autre opportunité de sensibilisation globale concerne les Explorations qui sont fréquemment interrogées par les utilisateurs et dont le temps de réponse aux requêtes est inférieur à la moyenne.
Vous pouvez utiliser l'outil Explorer de l'historique de l'activité système comme point de départ pour identifier les opportunités d'optimisation des Explorers. Pour faire plus simple, vous pouvez utiliser l'URL suivante dans un navigateur, en remplaçant HOSTNAME par le nom de votre instance Looker (par exemple, example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Vous verrez une visualisation Explorer avec des données sur les explorations de votre instance, y compris Explorer, Modèle, Nombre d'exécutions de requêtes, Nombre d'utilisateurs et Durée d'exécution moyenne en secondes :

Dans l'explorateur "Historique", vous pouvez identifier les types d'explorations suivants dans votre instance :
- Explorations interrogées par les utilisateurs (par opposition aux requêtes provenant de l'API ou des livraisons planifiées)
- Explorations souvent interrogées
- Explorations peu performantes (par rapport aux autres)
Dans l'exemple précédent d'exploration de l'historique des activités système, les explorations flights et order_items sont des candidats probables pour l'implémentation de la prise de conscience agrégée.
Identifier les champs fréquemment utilisés dans les requêtes
Enfin, vous pouvez identifier d'autres opportunités au niveau des données en comprenant les champs que les utilisateurs incluent généralement dans les requêtes et les filtres.
Pour faire plus simple, vous pouvez utiliser l'URL suivante dans un navigateur, en remplaçant HOSTNAME par le nom de votre instance Looker (par exemple, example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Remplacez les filtres en conséquence. Vous verrez une exploration avec un graphique à barres qui indique le nombre de fois qu'un champ a été utilisé dans une requête :
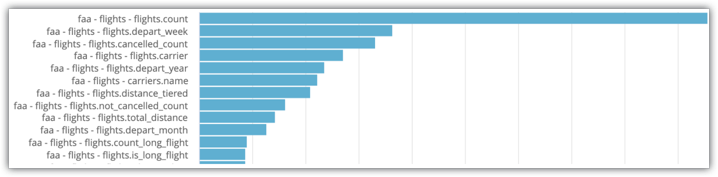
Dans l'exemple d'exploration de l'activité système illustré dans l'image, vous pouvez voir que flights.count et flights.depart_week sont les deux champs les plus souvent sélectionnés pour l'exploration. Ces champs sont donc de bons candidats pour être inclus dans les tableaux agrégés.
Ces données concrètes sont utiles, mais des éléments subjectifs guideront vos critères de sélection. Par exemple, en examinant les quatre champs précédents, vous pouvez supposer sans risque que les utilisateurs consultent généralement le nombre de vols programmés et le nombre de vols annulés, et qu'ils souhaitent ventiler ces données par semaine et par compagnie aérienne. Il s'agit d'un exemple clair, logique et concret de combinaison de champs et de métriques.
Résumé
Les étapes décrites sur cette page de documentation devraient vous aider à trouver les tableaux de bord, les explorations et les champs à prendre en compte pour l'optimisation. Il est également important de comprendre que ces trois éléments peuvent s'exclure mutuellement : les tableaux de bord problématiques ne sont pas forcément alimentés par les explorations problématiques, et la création de tableaux agrégés avec les champs couramment utilisés peut ne pas aider du tout ces tableaux de bord. Il est possible qu'il s'agisse de trois implémentations distinctes de la notoriété agrégée.
Concevoir des tables agrégées
Une fois que vous avez identifié les opportunités de sensibilisation globale, vous pouvez concevoir les tableaux agrégés qui répondront le mieux à ces opportunités. Consultez la page de documentation Connaissance des agrégats pour en savoir plus sur les champs, les mesures et les périodes acceptés dans les tables agrégées, ainsi que sur les autres consignes de conception de ces tables.
REMARQUE : Les tables agrégées n'ont pas besoin de correspondre exactement à votre requête pour être utilisées. Si votre requête est au niveau de précision de la semaine et que vous disposez d'une table de consolidation quotidienne, Looker utilisera votre table agrégée au lieu de votre table brute au niveau de l'horodatage. De même, si vous disposez d'un tableau agrégé au niveaubrandetdate, et qu'un utilisateur interroge uniquement le niveaubrand, ce tableau peut toujours être utilisé par Looker pour l'agrégation.
La prise en compte des agrégats est compatible avec les mesures suivantes :
- Mesures standards : mesures de type SUM, COUNT, AVERAGE, MIN et MAX
- Mesures composites : mesures de type NUMBER, STRING, YESNO et DATE
- Mesures distinctes approximatives : dialectes pouvant utiliser la fonctionnalité HyperLogLog
La notoriété globale n'est pas acceptée pour les métriques suivantes :
- Mesures distinctes : comme la distinction ne peut être calculée que sur des données atomiques non agrégées, les mesures
*_DISTINCTne sont pas prises en charge en dehors de ces approximations qui utilisent HyperLogLog. - Mesures basées sur la cardinalité : comme pour les mesures distinctes, les médianes et les centiles ne peuvent pas être pré-agrégés et ne sont pas acceptés.
REMARQUE : Si vous connaissez une requête utilisateur potentielle avec des types de mesures qui ne sont pas compatibles avec la reconnaissance des agrégats, vous pouvez créer une table agrégée qui correspond exactement à une requête. Une table agrégée qui correspond exactement à la requête peut être utilisée pour répondre à une requête avec des types de mesures qui ne seraient pas compatibles avec la prise en compte de l'agrégation.
Précision des tables agrégées
Avant de créer des tableaux pour les combinaisons de dimensions et de mesures, vous devez déterminer les modèles d'utilisation et les sélections de champs courants afin de créer des tableaux agrégés qui seront utilisés aussi souvent que possible et qui auront le plus d'impact. Notez que tous les champs utilisés dans la requête (qu'ils soient sélectionnés ou filtrés) doivent figurer dans la table agrégée pour que celle-ci puisse être utilisée pour la requête. Toutefois, comme indiqué précédemment, la table agrégée ne doit pas nécessairement correspondre exactement à une requête pour être utilisée pour cette requête. Vous pouvez répondre à de nombreuses requêtes utilisateur potentielles dans une seule table agrégée tout en bénéficiant de gains de performances importants.
Dans l'exemple Identifier les champs fréquemment utilisés dans les requêtes, deux dimensions (flights.depart_week et flights.carrier) sont sélectionnées très souvent, ainsi que deux mesures (flights.count et flights.cancelled_count). Il serait donc logique de créer un tableau agrégé qui utilise ces quatre champs. De plus, la création d'une seule table agrégée pour flights_by_week_and_carrier entraînera une utilisation plus fréquente des tables agrégées que la création de deux tables agrégées différentes pour les tables flights_by_week et flights_by_carrier.
Voici un exemple de table agrégée que nous pourrions créer pour les requêtes sur les champs communs :
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Les utilisateurs de votre entreprise, les données anecdotiques et les données de l'activité du système Looker peuvent vous aider à prendre des décisions.
Équilibrer l'applicabilité et les performances
L'exemple suivant montre une requête Explore des champs "Semaine de départ des vols", "Compagnie aérienne (détails des vols)", "Nombre de vols" et "Nombre de vols annulés (détails)" de la table agrégée flights_by_week_and_carrier :
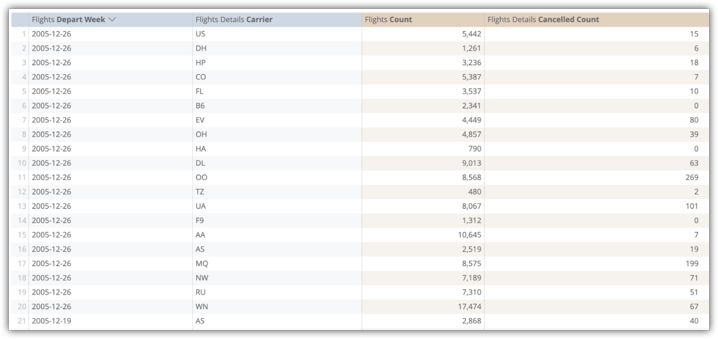
L'exécution de cette requête à partir de la table de base de données d'origine a pris 15,8 secondes et a analysé 38 millions de lignes sans aucune jointure à l'aide d'Amazon Redshift. La requête a été pivotée, ce qui est une opération utilisateur normale, et cela a pris 29,5 secondes.
Après l'implémentation de la table agrégée flights_by_week_and_carrier, la requête suivante a pris 7,2 secondes et a analysé 4 592 lignes. Cela représente une réduction de 99,98 % de la taille de la table. Le tableau croisé dynamique de la requête a pris 9,8 secondes.
Dans l'exploration "Utilisation des champs d'activité système", nous pouvons voir à quelle fréquence nos utilisateurs incluent ces champs dans les requêtes. Dans cet exemple, flights.count a été utilisé 47 848 fois, flights.depart_week 18 169 fois, flights.cancelled_count 16 570 fois et flights.carrier 13 517 fois.

Même si nous avons estimé très modestement que 25 % de ces requêtes utilisaient les quatre champs de la manière la plus simple possible (sélection simple, sans tableau croisé dynamique), 3 379 x 8, 6 secondes = 8 heures et 4 minutes de temps d'attente cumulé des utilisateurs ont été éliminées.
REMARQUE : Le modèle d'exemple utilisé ici est très basique. Vous ne devez pas utiliser ces résultats comme benchmark ou cadre de référence pour votre modèle.
Après avoir appliqué exactement le même flux à notre modèle e-commerce order_items – l'onglet "Explorer" le plus utilisé dans l'instance –, les résultats sont les suivants :
| Source | Durée de la requête | Lignes analysées |
|---|---|---|
| Table de base | 13,1 secondes | 285 000 |
| Table agrégée | 5,1 secondes | 138 000 |
| Delta | 8 secondes | 147 000 |
Les champs utilisés dans la requête et le tableau agrégé suivant étaient brand, created_date, orders_count et total_revenue, avec deux jointures. Les champs avaient été utilisés 11 000 fois au total. En estimant la même utilisation combinée d'environ 25 %, l'économie globale pour les utilisateurs serait de 6 heures et 6 minutes (8 s * 2 750 = 22 000 s). La création du tableau agrégé a pris 17,9 secondes.
En examinant ces résultats, il est intéressant de prendre un moment pour évaluer les retours potentiels obtenus à partir des éléments suivants :
- Optimisation des modèles/explorations plus volumineux et plus complexes qui présentent des performances "acceptables" et qui peuvent être améliorées grâce à de meilleures pratiques de modélisation
contre
- Utiliser la notoriété globale pour optimiser les modèles plus simples qui sont utilisés plus fréquemment et qui sont peu performants
Vous constaterez une diminution des rendements de vos efforts lorsque vous tenterez d'obtenir les dernières performances de Looker et de votre base de données. Vous devez toujours être conscient des attentes de base en termes de performances, en particulier de la part des utilisateurs professionnels, et des limites imposées par votre base de données (telles que la simultanéité, les seuils de requête, le coût, etc.). Ne vous attendez pas à ce que la connaissance globale surmonte ces limites.
De plus, lorsque vous concevez une table agrégée, n'oubliez pas que plus elle contient de champs, plus elle sera volumineuse et lente. Les tables plus grandes peuvent optimiser davantage de requêtes et donc être utilisées dans plus de situations, mais elles ne seront pas aussi rapides que les tables plus petites et plus simples.
Exemple :
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}Le tableau agrégé sera alors utilisé pour toute combinaison de dimensions affichée et pour toutes les mesures incluses. Il pourra donc répondre à de nombreuses requêtes utilisateur différentes. Toutefois, pour utiliser cette table pour une simple requête SELECT de carrier et count, il faudrait analyser une table de 885 000 lignes. En revanche, la même requête ne nécessiterait qu'une analyse de 4 592 lignes si la table était basée sur deux dimensions. La table de 885 000 lignes représente toujours une réduction de 97 % de la taille de la table (par rapport aux 38 millions de lignes précédentes), mais l'ajout d'une dimension supplémentaire augmente la taille de la table à 20 millions de lignes. Par conséquent, les rendements diminuent à mesure que vous incluez plus de champs dans votre tableau agrégé pour augmenter son applicabilité à davantage de requêtes.
Créer des tables agrégées
En reprenant l'exemple Vols que nous avons identifié comme une opportunité d'optimisation, la meilleure stratégie serait de créer trois tables agrégées différentes :
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
Le moyen le plus simple de créer ces tables agrégées consiste à obtenir le code LookML de la table agrégée à partir d'une requête Explorer ou d'un tableau de bord, puis à ajouter le code LookML aux fichiers de votre projet Looker.
Une fois que vous avez ajouté les tables agrégées à votre projet LookML et déployé les mises à jour en production, vos explorations utiliseront les tables agrégées pour les requêtes de vos utilisateurs.
Persistance
Pour être accessibles à la sensibilisation globale, les tables agrégées doivent être conservées dans votre base de données. Il est recommandé d'aligner la régénération automatique de ces tables agrégées sur votre stratégie de mise en cache en utilisant des groupes de données. Vous devez utiliser le même groupe de données pour une table agrégée que celui utilisé pour l'exploration associée. Si vous ne pouvez pas utiliser de groupes de données, vous pouvez utiliser le paramètre sql_trigger_value à la place. L'exemple suivant montre une valeur générique basée sur la date pour sql_trigger_value :
sql_trigger_value: SELECT CURRENT_DATE() ;;
Vos tables agrégées seront ainsi créées automatiquement à minuit chaque jour.
Logique de période
Lorsque Looker crée une table agrégée, il inclut les données jusqu'au moment où la table agrégée a été créée. Toutes les données qui ont été ajoutées à la table de base dans la base de données sont normalement exclues des résultats d'une requête utilisant cette table agrégée.
Ce diagramme montre la chronologie des commandes reçues et enregistrées dans la base de données par rapport au moment où la table agrégée Commandes a été créée. Deux commandes reçues aujourd'hui ne figureront pas dans le tableau agrégé Commandes, car elles ont été reçues après la création de ce tableau :
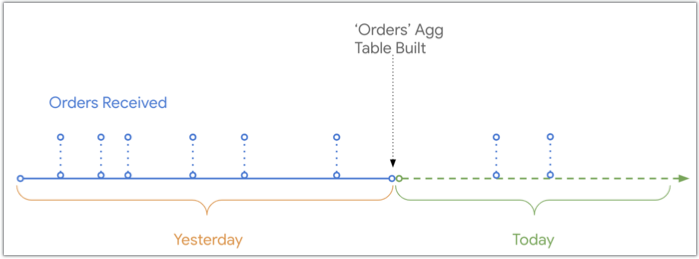
Toutefois, Looker peut UNIFIER les données récentes à la table agrégée lorsqu'un utilisateur interroge une période qui chevauche la table agrégée, comme illustré dans le même diagramme chronologique :
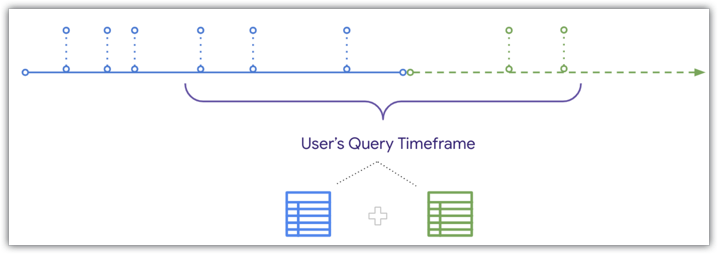
Comme Looker peut utiliser UNION pour ajouter des données récentes à un tableau agrégé, si un utilisateur filtre les données pour une période qui chevauche la fin du tableau agrégé et du tableau de base, les commandes reçues après la création du tableau agrégé seront incluses dans les résultats de l'utilisateur. Pour en savoir plus sur les conditions à remplir pour fusionner des données récentes avec des requêtes de tables agrégées, consultez la page de documentation Sensibilisation globale.
Résumé
Pour récapituler, la création d'une implémentation de la notoriété agrégée comporte trois étapes fondamentales :
- Identifiez les opportunités d'optimisation à l'aide de tableaux agrégés qui sont appropriées et efficaces.
- Concevez des tables agrégées qui couvrent la plupart des requêtes utilisateur courantes tout en restant suffisamment petites pour réduire la taille de ces requêtes.
- Créez les tables agrégées dans le modèle Looker, en associant la persistance de la table à celle du cache de l'exploration.