Para ver detalhes adicionais, consulte a página de documentação Aggregate awareness.
Introdução
Esta página é um guia para implementar a notoriedade agregada num cenário prático, incluindo a identificação de oportunidades de implementação, o valor que a notoriedade agregada gera e um fluxo de trabalho simples para a implementar num modelo real. Esta página não é uma explicação detalhada de todas as funcionalidades de sensibilização agregada ou casos extremos, nem um catálogo exaustivo de todas as respetivas funcionalidades.
O que é a notoriedade agregada?
No Looker, as consultas são feitas principalmente em tabelas ou vistas não processadas na sua base de dados. Por vezes, estas são tabelas derivadas persistentes (PDTs) do Looker.
Muitas vezes, pode encontrar conjuntos de dados ou tabelas muito grandes que, para terem um bom desempenho, requerem tabelas de agregação ou resumos.
Normalmente, pode criar tabelas de agregação, como uma tabela orders_daily que contenha uma dimensionalidade limitada. Estes têm de ser tratados separadamente e modelados separadamente na funcionalidade Explorar, e não se enquadram bem no modelo. Estas limitações resultam em experiências do utilizador deficientes quando o utilizador tem de escolher entre várias explorações para os mesmos dados.
Agora, com a notoriedade agregada do Looker, pode pré-construir tabelas agregadas a vários níveis de detalhe, dimensionalidade e agregação, e pode informar o Looker de como as usar em análises detalhadas existentes. As consultas vão, então, tirar partido destas tabelas agregadas quando o Looker considerar adequado, sem qualquer introdução do utilizador. Isto reduz o tamanho das consultas, diminui os tempos de espera e melhora a experiência do utilizador.
NOTA: as tabelas agregadas do Looker são um tipo de tabela derivada persistente (PDT). Isto significa que as tabelas agregadas têm os mesmos requisitos de base de dados e de ligação que as PDTs.Para ver se o dialeto da base de dados e a ligação do Looker podem suportar PDTs, consulte os requisitos indicados na página de documentação Tabelas derivadas no Looker.
Para ver se o dialeto da sua base de dados suporta a deteção de agregados, consulte a página de documentação Deteção de agregados.
O valor da notoriedade agregada
Existem várias propostas de valor significativas que agregam ofertas de notoriedade para gerar valor adicional a partir do seu modelo do Looker existente:
- Melhoria do desempenho: a implementação da notoriedade agregada torna as consultas dos utilizadores mais rápidas. O Looker usa uma tabela mais pequena se contiver os dados necessários para concluir a consulta do utilizador.
- Poupanças de custos: determinados dialetos cobram pelo tamanho da consulta num modelo de consumo. Ao fazer com que o Looker consulte tabelas mais pequenas, reduz o custo por consulta do utilizador.
- Melhoria da experiência do utilizador: além de uma experiência melhorada que obtém respostas mais rapidamente, a consolidação elimina a criação redundante de explorações.
- Redução da área de LookML: a substituição das estratégias de notoriedade agregadas existentes baseadas em Liquid por uma implementação nativa flexível leva a uma maior resiliência e a menos erros.
- Capacidade de tirar partido do LookML existente: as tabelas agregadas usam o objeto
query, que reutiliza a lógica modelada existente em vez de duplicar a lógica com SQL personalizado explícito.
Exemplo básico
Segue-se uma implementação muito simples num modelo do Looker para demonstrar como a visibilidade agregada simples pode ser. Tendo em conta uma tabela hipotética flights na base de dados com uma linha para cada voo registado através da FAA, podemos modelar esta tabela no Looker com a sua própria vista e explorar. Segue-se o LookML de uma tabela agregada que podemos definir para a exploração:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Com esta tabela agregada, um utilizador pode consultar a flightsexploração e o Looker tira automaticamente partido da tabela agregada definida no LookML e usa a tabela agregada para responder a consultas. O utilizador não tem de informar o Looker de quaisquer condições especiais: se a tabela for adequada aos campos que o utilizador selecionar, o Looker usa essa tabela.
Os utilizadores com autorizações see_sql podem usar os comentários no separador SQL de uma exploração para ver que tabela agregada vai ser usada para uma consulta. Segue-se um exemplo do separador SQL do Looker para uma consulta que usa a tabela agregada flights:flights_by_week_and_carrier in teach_scratch:
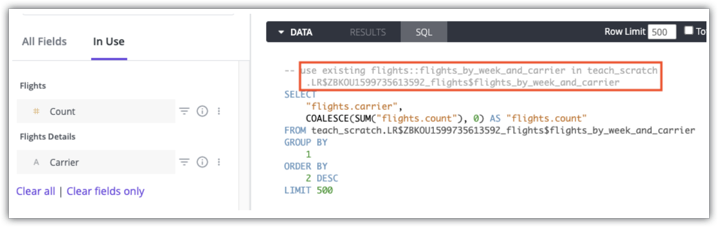
Consulte a página de documentação Consciência agregada para ver detalhes sobre como determinar se as tabelas agregadas são usadas para uma consulta.
Identificar oportunidades
Para maximizar as vantagens da notoriedade agregada, deve identificar onde a notoriedade agregada pode desempenhar um papel na otimização ou no aumento do valor da notoriedade agregada.
Identifique painéis de controlo com um tempo de execução elevado
Uma excelente oportunidade para a agregação de dados é criar tabelas agregadas para painéis de controlo muito usados com um tempo de execução muito elevado. Pode receber feedback dos seus utilizadores sobre a lentidão dos painéis de controlo, mas, se tiver o see_system_activity, também pode usar o System Activity History Explore do Looker para encontrar painéis de controlo com um tempo de execução mais lento do que a média. Em alternativa, pode usar o seguinte URL num navegador, substituindo HOSTNAME pelo nome da sua instância do Looker (como example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
É apresentada uma visualização de exploração com dados sobre os painéis de controlo da sua instância, incluindo Título, Histórico, Quantidade de explorações, Rácio da cache vs. base de dados e O desempenho é inferior à média:
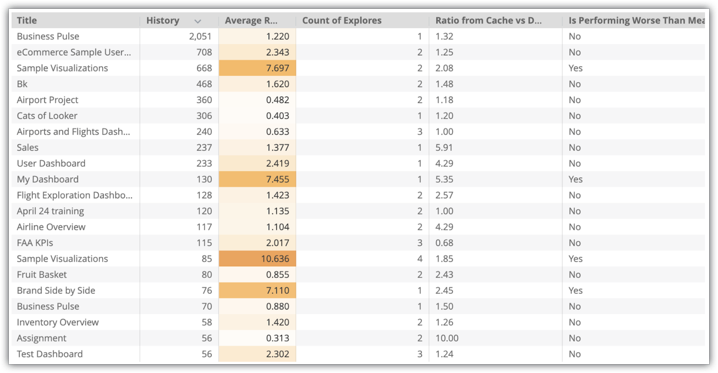
Neste exemplo, existem vários painéis de controlo com uma utilização elevada que têm um desempenho inferior à média, como o painel de controlo Exemplos de visualizações. O painel de controlo Sample Visualizations usa dois Explorers, pelo que uma boa estratégia seria criar tabelas agregadas para ambos os Explorers.
Identifique explorações lentas e com muitas consultas por parte dos utilizadores
Outra oportunidade para a notoriedade agregada é com as explorações que são consultadas com frequência pelos utilizadores e têm uma resposta de consulta inferior à média.
Pode usar a opção Histórico de atividade do sistema Explorar como ponto de partida para identificar oportunidades de otimização das explorações. Em alternativa, pode usar o seguinte URL num navegador, substituindo HOSTNAME pelo nome da sua instância do Looker (como example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
É apresentada uma visualização de exploração com dados sobre as explorações da sua instância, incluindo Explorar, Modelo, Número de execuções de consultas, Número de utilizadores e Tempo de execução médio em segundos:

No conteúdo de Explorar Histórico, pode identificar os seguintes tipos de conteúdo de Explorar na sua instância:
- Explorações consultadas pelos utilizadores (em oposição a consultas da API ou consultas de envios agendados)
- Explorações que são consultadas com frequência
- Explorações com um desempenho fraco (em relação a outras explorações)
No exemplo anterior de exploração do histórico de atividade do sistema, as explorações flights e order_items são candidatos prováveis para a implementação da consciencialização agregada.
Identifique os campos que são muito usados em consultas
Por último, pode identificar outras oportunidades ao nível dos dados compreendendo os campos que os utilizadores incluem frequentemente em consultas e filtros.
Em alternativa, pode usar o seguinte URL num navegador, substituindo HOSTNAME pelo nome da sua instância do Looker (como example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Substitua os filtros em conformidade. É apresentada uma exploração com uma visualização de gráfico de barras que indica o número de vezes que um campo foi usado numa consulta:
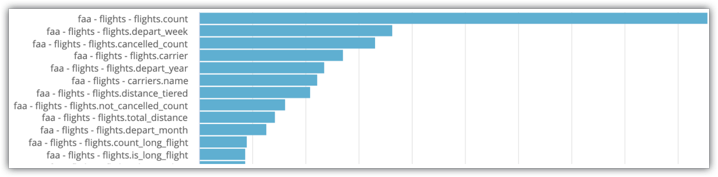
No exemplo de exploração da atividade do sistema apresentado na imagem, pode ver que flights.count e flights.depart_week são os dois campos mais frequentemente selecionados para a exploração. Por conseguinte, esses campos são bons candidatos para campos a incluir em tabelas agregadas.
Os dados concretos como estes são úteis, mas existem elementos subjetivos que vão orientar os seus critérios de seleção. Por exemplo, ao analisar os quatro campos anteriores, pode assumir com segurança que os utilizadores consultam frequentemente o número de voos agendados e o número de voos cancelados, e que querem discriminar esses dados por semana e por transportadora. Este é um exemplo de uma combinação clara, lógica e do mundo real de campos e métricas.
Resumo
Os passos nesta página de documentação devem servir como um guia para encontrar painéis de controlo, explorações e campos que têm de ser considerados para otimização. Também é importante compreender que os três podem ser mutuamente exclusivos: os painéis de controlo problemáticos podem não ser baseados nos Explores problemáticos, e a criação de tabelas agregadas com os campos usados frequentemente pode não ajudar esses painéis de controlo. É possível que se trate de três implementações de notoriedade agregadas distintas.
Conceber tabelas agregadas
Depois de identificar oportunidades de notoriedade agregada, pode criar tabelas agregadas que abordem melhor estas oportunidades. Consulte a página de documentação Consciência agregada para obter informações sobre os campos, as métricas e os intervalos de tempo suportados nas tabelas agregadas, bem como outras diretrizes para conceber tabelas agregadas.
NOTA: as tabelas agregadas não têm de corresponder exatamente à sua consulta para serem usadas. Se a sua consulta estiver ao nível de detalhe da semana e tiver uma tabela de agregação diária, o Looker usa a tabela agregada em vez da tabela não processada ao nível da data/hora. Da mesma forma, se tiver uma tabela agregada implementada ao nível debrandedatee um utilizador consultar apenas ao nível debrand, essa tabela continua a ser um candidato a ser usada pelo Looker para a notoriedade agregada.
A notoriedade agregada é suportada para as seguintes métricas:
- Medidas padrão: medidas do tipo SUM, COUNT, AVERAGE, MIN e MAX
- Medidas compostas: medidas do tipo NUMBER, STRING, YESNO e DATE
- Medidas distintas aproximadas: dialetos que podem usar a funcionalidade HyperLogLog
A notoriedade agregada não é suportada para as seguintes métricas:
- Medidas distintas: uma vez que a distinção só pode ser calculada em dados atómicos não agregados, as medidas
*_DISTINCTnão são suportadas fora destas aproximações que usam o HyperLogLog. - Medidas baseadas na cardinalidade: tal como acontece com as medidas distintas, as medianas e os percentis não podem ser pré-agregados e não são suportados.
NOTA: se souber de uma potencial consulta do utilizador com tipos de medidas que não são suportados pela notoriedade agregada, este é um caso em que pode querer criar uma tabela agregada que seja uma correspondência exata de uma consulta. Pode usar uma tabela agregada que seja uma correspondência exata da consulta para responder a uma consulta com tipos de medidas que, de outra forma, não seriam suportados para a perceção agregada.
Nível de detalhe da tabela agregada
Antes de criar tabelas para combinações de dimensões e medidas, deve determinar padrões de utilização comuns e a seleção de campos para criar tabelas agregadas que vão ser usadas com a maior frequência possível e ter o maior impacto. Tenha em atenção que todos os campos usados na consulta (quer sejam selecionados ou filtrados) têm de estar na tabela de agregação para que a tabela seja usada para a consulta. No entanto, como referido anteriormente, a tabela agregada não tem de corresponder exatamente a uma consulta para ser usada para a consulta. Pode responder a muitas potenciais consultas de utilizadores numa única tabela agregada e continuar a ver grandes ganhos de desempenho.
No exemplo de identificação de campos que são muito usados em consultas, existem duas dimensões (flights.depart_week e flights.carrier) que são selecionadas com muita frequência, bem como duas métricas (flights.count e flights.cancelled_count). Por conseguinte, seria lógico criar uma tabela agregada que usasse todos estes quatro campos. Além disso, a criação de uma única tabela agregada para flights_by_week_and_carrier resulta numa utilização mais frequente da tabela agregada do que duas tabelas agregadas diferentes para tabelas flights_by_week e flights_by_carrier.
Segue-se um exemplo de uma tabela agregada que podemos criar para consultas nos campos comuns:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Os utilizadores empresariais e as provas anedóticas, bem como os dados da atividade do sistema do Looker, podem ajudar a orientar o seu processo de tomada de decisões.
Equilibrar a aplicabilidade e o desempenho
O exemplo seguinte mostra uma consulta de exploração dos campos Flights Depart Week, Flights Details Carrier, Flights Count e Flights Detailed Cancelled Count da tabela de agregação flights_by_week_and_carrier:
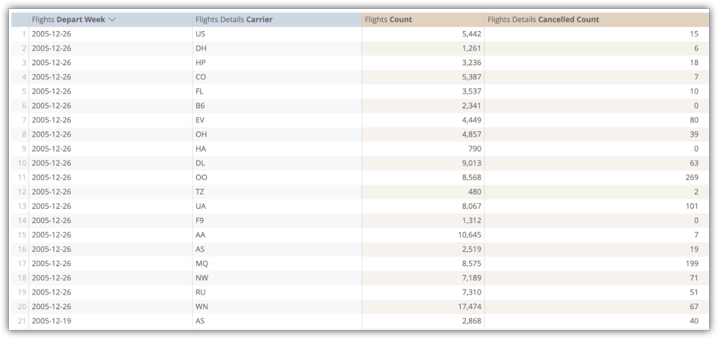
A execução desta consulta a partir da tabela de base de dados original demorou 15,8 segundos e analisou 38 milhões de linhas sem junções através do Amazon Redshift. A alteração da consulta, que seria uma operação normal do utilizador, demorou 29,5 segundos.
Após a implementação da flights_by_week_and_carriertabela de agregação, a consulta subsequente demorou 7,2 segundos e analisou 4592 linhas. Isto representa uma redução de 99,98% no tamanho da tabela. A mudança da consulta demorou 9,8 segundos.
A partir da análise detalhada de utilização de campos de atividade do sistema, podemos ver com que frequência os nossos utilizadores incluem estes campos em consultas. Neste exemplo, flights.count foi usado 47 848 vezes, flights.depart_week foi usado 18 169 vezes, flights.cancelled_count foi usado 16 570 vezes e flights.carrier foi usado 13 517 vezes.
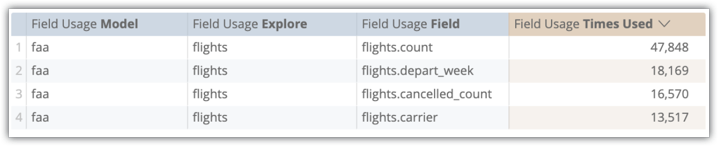
Mesmo que estimássemos modestamente que 25% destas consultas usavam todos os 4 campos da forma mais simples (seleção simples, sem dinamização), 3379 x 8, 6 segundos = 8 horas e 4 minutos no tempo de espera do utilizador agregado eliminado.
NOTA: o modelo de exemplo usado aqui é muito básico. Estes resultados não devem ser usados como uma referência ou um ponto de referência para o seu modelo.
Depois de aplicar exatamente o mesmo fluxo ao nosso modelo de comércio eletrónico order_items — a exploração mais usada na instância — os resultados são os seguintes:
| Origem | Hora da consulta | Linhas analisadas |
|---|---|---|
| Tabela base | 13,1 segundos | 285 000 |
| Tabela agregada | 5,1 segundos | 138 000 |
| Delta | 8 segundos | 147 000 |
Os campos usados na consulta e na tabela de agregação subsequente foram brand, created_date, orders_count e total_revenue, com duas junções. Os campos tinham sido usados um total de 11 000 vezes. Estimando a mesma utilização combinada de ~25%, a poupança agregada para os utilizadores seria de 6 horas e 6 minutos (8 s * 2750 = 22 000 s). A tabela agregada demorou 17,9 segundos a ser criada.
Analisando estes resultados, vale a pena dedicar algum tempo a avaliar os retornos potencialmente obtidos com:
- Otimizar modelos/explorações maiores e mais complexos que tenham um desempenho "aceitável" e que possam ver melhorias no desempenho com melhores práticas de modelagem
versus
- Usar a notoriedade agregada para otimizar modelos mais simples que são usados com mais frequência e têm um desempenho fraco
Vai verificar retornos decrescentes nos seus esforços à medida que tenta obter o último fragmento de desempenho do Looker e da sua base de dados. Deve ter sempre em atenção as expetativas de desempenho de base, particularmente dos utilizadores empresariais, e as limitações impostas pela sua base de dados (como a concorrência, os limites de consultas, o custo, etc.). Não deve esperar que a notoriedade agregada ultrapasse estas limitações.
Além disso, ao criar uma tabela agregada, lembre-se de que ter mais campos resulta numa tabela agregada maior e mais lenta. As tabelas maiores podem otimizar mais consultas e, por isso, ser usadas em mais situações, mas não são tão rápidas como as tabelas mais pequenas e simples.
Por exemplo:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}Isto resulta na utilização da tabela agregada para qualquer combinação de dimensões apresentadas e para qualquer uma das medidas incluídas. Assim, esta tabela pode ser usada para responder a muitas consultas de utilizadores diferentes. No entanto, para usar esta tabela para uma simples consulta SELECT de carrier e count, seria necessária uma análise de uma tabela de 885 000 linhas. Em contraste, a mesma consulta só exigiria uma análise de 4592 linhas se a tabela fosse baseada em duas dimensões. A tabela de 885 mil linhas continua a representar uma redução de 97% no tamanho da tabela (em comparação com as 38 milhões de linhas anteriores). No entanto, a adição de mais uma dimensão aumenta o tamanho da tabela para 20 milhões de linhas. Como tal, os retornos diminuem à medida que inclui mais campos na tabela agregada para aumentar a sua aplicabilidade a mais consultas.
Criar tabelas agregadas
Tomando o nosso exemplo do Explore Voos que identificámos como uma oportunidade de otimização, a melhor estratégia seria criar três tabelas agregadas diferentes para o mesmo:
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
A forma mais fácil de criar estas tabelas agregadas é obter o LookML da tabela agregada a partir de uma consulta de exploração ou a partir de um painel de controlo e adicionar o LookML aos ficheiros do projeto do Looker.
Depois de adicionar as tabelas agregadas ao seu projeto LookML e implementar as atualizações na produção, as suas explorações vão tirar partido das tabelas agregadas para as consultas dos utilizadores.
Persistência
Para serem acessíveis para a notoriedade agregada, as tabelas agregadas têm de ser mantidas na sua base de dados. É uma prática recomendada alinhar a regeneração automática destas tabelas agregadas com a sua política de colocação em cache através da utilização de grupos de dados. Deve usar o mesmo grupo de dados para uma tabela agregada que é usada para a exploração associada. Se não puder usar grupos de dados, tem como opção alternativa usar o parâmetro sql_trigger_value. O exemplo seguinte mostra um valor genérico baseado na data para sql_trigger_value:
sql_trigger_value: SELECT CURRENT_DATE() ;;
Isto cria automaticamente as tabelas agregadas todos os dias à meia-noite.
Lógica do prazo
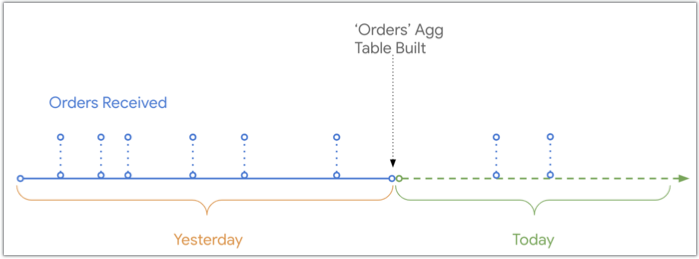
Quando o Looker cria uma tabela agregada, inclui dados até ao momento em que a tabela agregada foi criada. Normalmente, todos os dados que foram anexados posteriormente à tabela base na base de dados são excluídos dos resultados de uma consulta que usa essa tabela agregada.
Este diagrama mostra a cronologia de quando as encomendas foram recebidas e registadas na base de dados, em comparação com o momento em que a tabela agregada Encomendas foi criada. Existem duas encomendas recebidas hoje que não vão estar presentes na tabela agregada Encomendas, uma vez que foram recebidas após a criação da tabela agregada:
No entanto, o Looker pode UNIR dados atualizados à tabela agregada quando um utilizador consulta um período que se sobrepõe à tabela agregada, conforme representado no mesmo diagrama da cronologia:
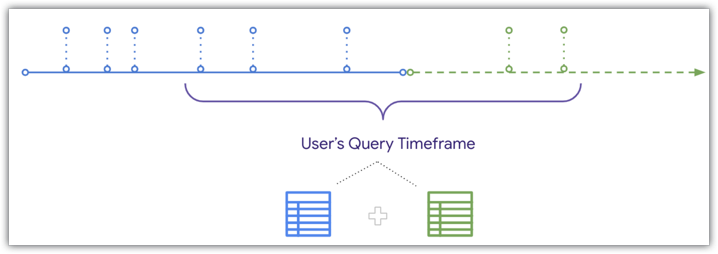
Uma vez que o Looker pode UNIR dados atualizados a uma tabela agregada, se um utilizador filtrar por um período que se sobreponha ao final da tabela agregada e da tabela base, as encomendas recebidas após a criação da tabela agregada são incluídas nos resultados do utilizador. Consulte a página de documentação Consciência agregada para ver detalhes e as condições que têm de ser cumpridas para unir dados atualizados a consultas de tabelas agregadas.
Resumo
Em resumo, para criar uma implementação de notoriedade agregada, existem três passos fundamentais:
- Identificar oportunidades em que a otimização através de tabelas agregadas é adequada e tem impacto.
- Conceba tabelas agregadas que ofereçam a maior cobertura para consultas comuns dos utilizadores, mas que continuem a ser suficientemente pequenas para reduzir o tamanho dessas consultas.
- Crie as tabelas agregadas no modelo do Looker, sincronizando a persistência da tabela com a persistência da cache de exploração.