Para mais detalhes, consulte a página de documentação Aggregate awareness.
Introdução
Esta página é um guia para implementar a percepção de agregação em um cenário prático, incluindo a identificação de oportunidades de implementação, o valor que a percepção de agregação gera e um fluxo de trabalho simples para implementá-la em um modelo real. Esta página não é uma explicação detalhada de todos os recursos de conscientização agregada ou casos extremos, nem um catálogo exaustivo de todos os recursos.
O que é reconhecimento agregado?
No Looker, você consulta principalmente tabelas ou visualizações brutas no seu banco de dados. Às vezes, elas são tabelas derivadas persistentes (PDTs) do Looker.
Muitas vezes, você encontra conjuntos de dados ou tabelas muito grandes que, para ter um bom desempenho, exigem tabelas de agregação ou resumos.
Normalmente, você pode criar tabelas de agregação, como uma tabela orders_daily com dimensionalidade limitada. Eles precisam ser tratados e modelados separadamente na análise detalhada e não se encaixam bem no modelo. Essas limitações prejudicam a experiência do usuário quando ele precisa escolher entre várias análises detalhadas para os mesmos dados.
Agora, com o reconhecimento de agregação do Looker, é possível pré-construir tabelas agregadas em vários níveis de granularidade, dimensionalidade e agregação, além de informar ao Looker como usá-las nas análises detalhadas atuais. As consultas vão usar essas tabelas de resumo quando o Looker achar adequado, sem nenhuma entrada do usuário. Isso vai reduzir o tamanho da consulta, diminuir os tempos de espera e melhorar a experiência do usuário.
OBSERVAÇÃO:as tabelas de agregação do Looker são um tipo de tabela derivada persistente (PDT). Isso significa que as tabelas agregadas têm os mesmos requisitos de banco de dados e conexão que as PDTs.Para saber se o dialeto do banco de dados e a conexão do Looker são compatíveis com PDTs, consulte os requisitos listados na página de documentação Tabelas derivadas no Looker.
Para saber se o dialeto do seu banco de dados é compatível com o reconhecimento de agregação, consulte a página de documentação Reconhecimento de agregação.
O valor do reconhecimento agregado
Há várias propostas de valor significativas e ofertas de reconhecimento agregado para gerar mais valor com seu modelo do Looker atual:
- Melhoria de performance:a implementação da agregação de dados acelera as consultas dos usuários. O Looker vai usar uma tabela menor se ela tiver os dados necessários para concluir a consulta do usuário.
- Economia de custos:alguns dialetos cobram pelo tamanho da consulta em um modelo de consumo. Ao fazer com que o Looker consulte tabelas menores, você reduz o custo por consulta do usuário.
- Melhoria na experiência do usuário:além de uma experiência aprimorada que recupera respostas mais rapidamente, a consolidação elimina a criação redundante de análises detalhadas.
- Redução da abrangência do LookML:a substituição das estratégias de reconhecimento de agregação atuais baseadas em Liquid por uma implementação nativa e flexível aumenta a capacidade de recuperação e reduz os erros.
- Capacidade de aproveitar a LookML atual:as tabelas agregadas usam o objeto
query, que reutiliza a lógica modelada em vez de duplicar a lógica com SQL personalizado explícito.
Exemplo básico
Confira uma implementação muito simples em um modelo do Looker para demonstrar como a agregação leve pode ser. Considerando uma tabela hipotética flights no banco de dados com uma linha para cada voo registrado pela FAA, podemos modelar essa tabela no Looker com uma visualização e uma análise detalhada próprias. Confira o LookML de uma tabela de agregação que podemos definir para o Explore:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Com essa tabela de agregação, um usuário pode consultar a análise flights, e o Looker vai usar automaticamente a tabela de agregação definida na LookML para responder às consultas. O usuário não precisa informar ao Looker nenhuma condição especial: se a tabela for adequada aos campos selecionados, o Looker vai usá-la.
Os usuários com permissões see_sql podem usar os comentários na guia SQL de uma análise detalhada para saber qual tabela agregada será usada em uma consulta. Confira um exemplo da guia SQL do Looker para uma consulta que usa a tabela agregada flights:flights_by_week_and_carrier in teach_scratch:
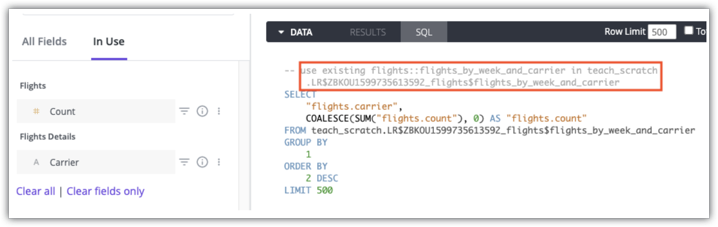
Consulte a página de documentação Reconhecimento de agregação para saber se as tabelas agregadas são usadas em uma consulta.
Identificar oportunidades
Para maximizar os benefícios do reconhecimento agregado, identifique onde ele pode ajudar na otimização ou no aumento do valor do reconhecimento agregado.
Identificar painéis com um tempo de execução alto
Uma ótima oportunidade para o reconhecimento de agregações é criar tabelas agregadas para painéis muito usados com um tempo de execução muito alto. Talvez seus usuários reclamem de painéis lentos, mas, se você tiver o see_system_activity, também poderá usar a análise do histórico de atividade do sistema do Looker para encontrar painéis com tempo de execução mais lento do que a média. Como atalho, use o seguinte URL em um navegador, substituindo HOSTNAME pelo nome da sua instância do Looker (como example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
Você vai encontrar uma visualização de análise detalhada com dados sobre os painéis da sua instância, incluindo Título, Histórico, Contagem de análises detalhadas, Proporção de cache x banco de dados e Está com desempenho pior do que a média:
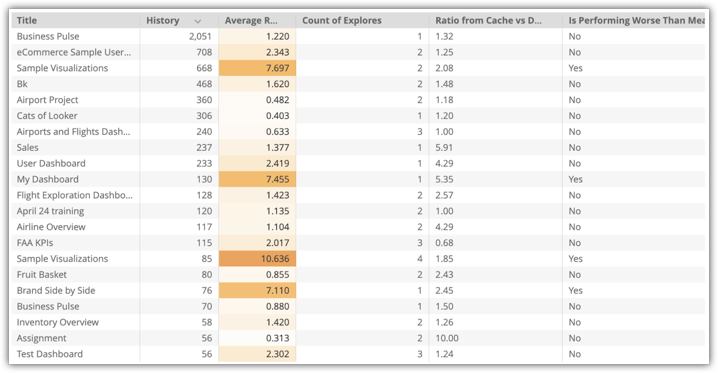
Neste exemplo, há vários painéis com alta utilização que têm uma performance pior do que a média, como o painel Exemplos de visualizações. O painel Exemplos de visualizações usa duas análises detalhadas. Portanto, uma boa estratégia seria criar tabelas agregadas para as duas.
Identificar análises lentas e muito consultadas pelos usuários
Outra oportunidade para aumentar a conscientização agregada é com as análises detalhadas que são muito consultadas pelos usuários e têm uma resposta de consulta menor que a média.
Use a Análise detalhada do histórico de atividades do sistema como ponto de partida para identificar oportunidades de otimizar as Análises detalhadas. Como atalho, use o seguinte URL em um navegador, substituindo HOSTNAME pelo nome da sua instância do Looker (como example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Você vai encontrar uma visualização de análise detalhada com dados sobre as análises detalhadas da sua instância, incluindo Análise detalhada, Modelo, Contagem de execuções de consultas, Contagem de usuários e Tempo médio de execução em segundos:

Na análise detalhada do histórico, é possível identificar os seguintes tipos de análises detalhadas na sua instância:
- Análises consultadas pelos usuários (em vez de consultas da API ou de entregas programadas)
- Análises detalhadas consultadas com frequência
- Análises com desempenho ruim (em relação a outras análises)
No exemplo anterior de análise detalhada do histórico de atividades do sistema, as análises detalhadas flights e order_items são prováveis candidatas para a implementação da agregação de dados de conscientização.
Identificar campos muito usados em consultas
Por fim, você pode identificar outras oportunidades no nível dos dados ao entender os campos que os usuários costumam incluir em consultas e filtros.
Como atalho, use o seguinte URL em um navegador, substituindo HOSTNAME pelo nome da sua instância do Looker (como example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Substitua os filtros conforme necessário. Você vai ver uma análise detalhada com uma visualização de gráfico de barras que indica o número de vezes que um campo foi usado em uma consulta:
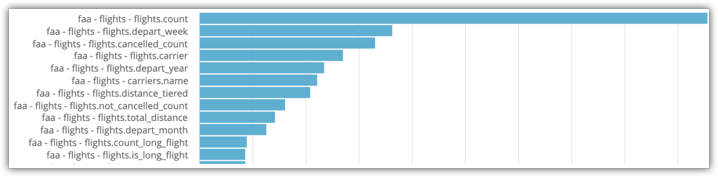
No exemplo de análise detalhada da atividade do sistema mostrado na imagem, é possível ver que flights.count e flights.depart_week são os dois campos mais selecionados para a análise detalhada. Portanto, esses campos são bons candidatos para inclusão em tabelas agregadas.
Dados concretos como esse são úteis, mas há elementos subjetivos que vão orientar seus critérios de seleção. Por exemplo, ao analisar os quatro campos anteriores, é possível presumir que os usuários costumam consultar o número de voos programados e cancelados e que querem detalhar esses dados por semana e por companhia aérea. Este é um exemplo de uma combinação clara, lógica e real de campos e métricas.
Resumo
As etapas nesta página de documentação servem como um guia para encontrar dashboards, análises detalhadas e campos que precisam ser considerados para otimização. Também é importante entender que os três podem ser mutuamente exclusivos: os dashboards problemáticos podem não ser alimentados pelas análises detalhadas problemáticas, e a criação de tabelas agregadas com os campos usados com frequência pode não ajudar esses dashboards. É possível que sejam três implementações de reconhecimento agregado distintas.
Como criar tabelas de agregação
Depois de identificar oportunidades para aumentar o reconhecimento agregado, crie tabelas agregadas que atendam melhor a essas oportunidades. Consulte a página de documentação Conscientização agregada para informações sobre os campos, as medidas e os períodos compatíveis com tabelas agregadas, além de outras diretrizes para criar essas tabelas.
OBSERVAÇÃO:as tabelas agregadas não precisam corresponder exatamente à sua consulta para serem usadas. Se a consulta for na granularidade semanal e você tiver uma tabela de resumo diário, o Looker vai usar a tabela agregada em vez da tabela bruta no nível de carimbo de data/hora. Da mesma forma, se você tiver uma tabela agregada resumida no nívelbrandedatee um usuário consultar apenas no nívelbrand, essa tabela ainda será uma candidata a ser usada pelo Looker para reconhecimento de agregação.
A compatibilidade com agregação está disponível para as seguintes métricas:
- Medidas padrão : medidas do tipo SOMA, CONTAGEM, MÉDIA, MÍNIMO e MÁXIMO
- Métricas compostas : métricas do tipo NUMBER, STRING, YESNO e DATE
- Medidas distintas aproximadas : dialetos que podem usar a funcionalidade HyperLogLog
A agregação não é compatível com as seguintes métricas:
- Medidas distintas:como a distinção só pode ser calculada em dados atômicos e não agregados, as medidas
*_DISTINCTnão são compatíveis fora dessas aproximações que usam o HyperLogLog. - Medidas com base na cardinalidade:assim como as medidas distintas, as medianas e os percentis não podem ser pré-agregados e não são compatíveis.
OBSERVAÇÃO:se você souber de uma possível consulta do usuário com tipos de métricas que não são compatíveis com a otimização de agregação, crie uma tabela agregada que seja uma correspondência exata de uma consulta. Uma tabela agregada que é uma correspondência exata da consulta pode ser usada para responder a uma consulta com tipos de medidas que, de outra forma, não seriam compatíveis com o reconhecimento de agregação.
Granularidade da tabela de agregação
Antes de criar tabelas para combinações de dimensões e métricas, determine padrões comuns de uso e seleção de campos para criar tabelas agregadas que serão usadas com a maior frequência possível e com o maior impacto. Todos os campos usados na consulta (selecionados ou filtrados) precisam estar na tabela agregada para que ela seja usada na consulta. No entanto, como observado anteriormente, a tabela agregada não precisa ser uma correspondência exata de uma consulta para ser usada por ela. É possível responder a muitas consultas de usuários em potencial em uma única tabela agregada e ainda ter grandes ganhos de performance.
No exemplo de identificação de campos muito usados em consultas, há duas dimensões (flights.depart_week e flights.carrier) que são selecionadas com muita frequência, além de duas métricas (flights.count e flights.cancelled_count). Portanto, seria lógico criar uma tabela agregada que use todos os quatro campos. Além disso, criar uma única tabela agregada para flights_by_week_and_carrier resulta em um uso mais frequente do que duas tabelas agregadas diferentes para flights_by_week e flights_by_carrier.
Confira um exemplo de tabela agregada que podemos criar para consultas nos campos comuns:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Seus usuários comerciais, evidências anedóticas e dados da atividade do sistema do Looker podem ajudar no processo de tomada de decisões.
Equilibrar aplicabilidade e desempenho
O exemplo a seguir mostra uma consulta de análise detalhada dos campos "Flights Depart Week", "Flights Details Carrier", "Flights Count" e "Flights Detailed Cancelled Count" da tabela agregada flights_by_week_and_carrier:
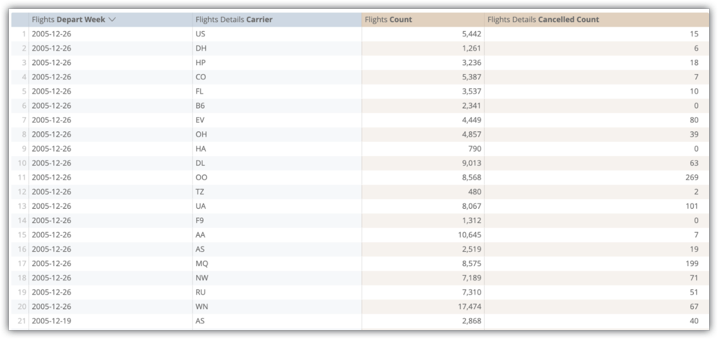
A execução dessa consulta na tabela de banco de dados original levou 15,8 segundos e verificou 38 milhões de linhas sem junções usando o Amazon Redshift. A rotação da consulta, que seria uma operação normal do usuário, levou 29,5 segundos.
Depois de implementar a tabela agregada flights_by_week_and_carrier, a consulta subsequente levou 7,2 segundos e verificou 4.592 linhas. Isso representa uma redução de 99,98% no tamanho da tabela. A rotação da consulta levou 9,8 segundos.
Na análise detalhada "Uso de campos de atividade do sistema", podemos ver com que frequência nossos usuários incluem esses campos nas consultas. Neste exemplo, flights.count foi usado 47.848 vezes, flights.depart_week foi usado 18.169 vezes, flights.cancelled_count foi usado 16.570 vezes e flights.carrier foi usado 13.517 vezes.
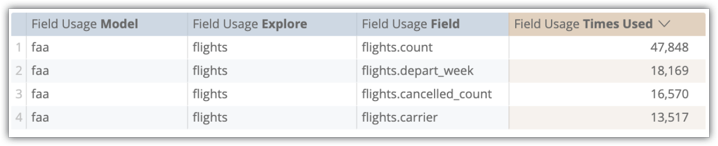
Mesmo que estimemos de forma modesta que 25% dessas consultas usaram todos os quatro campos da maneira mais simples (seleção simples, sem rotação), 3.379 x 8, 6 segundos = 8 horas e 4 minutos de tempo de espera agregado do usuário eliminados.
OBSERVAÇÃO:o modelo de exemplo usado aqui é muito básico. Esses resultados não devem ser usados como comparativo de mercado ou estrutura de referência para seu modelo.
Depois de aplicar o mesmo fluxo ao nosso modelo de e-commerce order_items — a análise detalhada mais usada na instância —, os resultados são os seguintes:
| Origem | Quando a consulta foi executada | Linhas verificadas |
|---|---|---|
| Tabela de base | 13,1 segundos | 285.000 |
| Tabela de agregação | 5,1 segundos | 138.000 |
| Delta | 8 segundos | 147.000 |
Os campos usados na consulta e na tabela agregada subsequente foram brand, created_date, orders_count e total_revenue, usando duas junções. Os campos foram usados um total de 11.000 vezes. Estimando o mesmo uso combinado de ~25%, a economia agregada para os usuários seria de 6 horas e 6 minutos (8s * 2750 = 22000s). A tabela agregada levou 17,9 segundos para ser criada.
Ao analisar esses resultados, vale a pena parar um pouco e avaliar os retornos potencialmente ganhos com:
- Otimizar modelos/análises detalhadas maiores e mais complexos que têm performance "aceitável" e podem melhorar com práticas de estimativa melhores
X
- Usar a percepção agregada para otimizar modelos mais simples que são usados com mais frequência e têm desempenho ruim
Você vai notar retornos decrescentes nos seus esforços ao tentar extrair o máximo de performance do Looker e do seu banco de dados. Você precisa sempre estar ciente das expectativas de performance de referência, principalmente dos usuários comerciais, e das limitações impostas pelo banco de dados (como simultaneidade, limites de consultas, custo etc.). Não espere que o reconhecimento agregado supere essas limitações.
Além disso, ao projetar uma tabela de agregação, lembre-se de que ter mais campos resulta em uma tabela maior e mais lenta. Tabelas maiores podem otimizar mais consultas e, portanto, ser usadas em mais situações, mas não são tão rápidas quanto tabelas menores e mais simples.
Exemplo:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}Isso faz com que a tabela agregada seja usada para qualquer combinação de dimensão mostrada e para qualquer uma das medidas incluídas. Assim, ela pode ser usada para responder a muitas consultas diferentes dos usuários. Mas, para usar essa tabela em uma consulta SELECT simples de carrier e count, seria necessário verificar uma tabela de 885.000 linhas. Por outro lado, a mesma consulta exigiria apenas uma verificação de 4.592 linhas se a tabela fosse baseada em duas dimensões. A tabela de 885 mil linhas ainda representa uma redução de 97% no tamanho da tabela (das 38 milhões de linhas anteriores), mas adicionar mais uma dimensão aumenta o tamanho da tabela para 20 milhões de linhas. Assim, há retornos decrescentes à medida que você inclui mais campos na tabela agregada para aumentar a aplicabilidade dela a mais consultas.
Como criar tabelas de agregação
Tomando como exemplo a análise detalhada Voos, que identificamos como uma oportunidade de otimização, a melhor estratégia seria criar três tabelas agregadas diferentes:
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
A maneira mais fácil de criar essas tabelas agregadas é acessar a LookML de uma consulta do recurso "Explorar" ou de um painel e adicionar a LookML aos arquivos do projeto do Looker.
Depois de adicionar as tabelas agregadas ao projeto do LookML e implantar as atualizações na produção, as análises detalhadas vão usar as tabelas agregadas para as consultas dos usuários.
Persistência
Para serem acessíveis para a percepção agregada, as tabelas agregadas precisam ser mantidas no seu banco de dados. A prática recomendada é alinhar a regeneração automática dessas tabelas agregadas com sua política de armazenamento em cache usando grupos de dados. Use o mesmo grupo de dados para uma tabela agregada usada na análise detalhada associada. Se não for possível usar grupos de dados, uma opção alternativa é usar o parâmetro sql_trigger_value. Confira a seguir um valor genérico baseado em data para sql_trigger_value:
sql_trigger_value: SELECT CURRENT_DATE() ;;
Isso vai criar suas tabelas agregadas automaticamente à meia-noite todos os dias.
Lógica de período
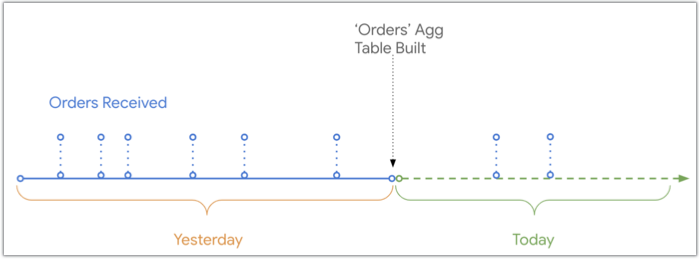
Quando o Looker cria uma tabela agregada, ele inclui dados até o momento em que a tabela foi criada. Todos os dados que foram adicionados posteriormente à tabela de base no banco de dados normalmente são excluídos dos resultados de uma consulta que usa essa tabela agregada.
Este diagrama mostra a linha do tempo de quando os pedidos foram recebidos e registrados no banco de dados em comparação com o momento em que a tabela agregada Pedidos foi criada. Há dois pedidos recebidos hoje que não vão aparecer na tabela agregada Pedidos porque foram recebidos depois da criação da tabela:
Mas o Looker pode fazer UNION de dados atualizados com a tabela agregada quando um usuário consulta um período que se sobrepõe a ela, conforme mostrado no mesmo diagrama de linha do tempo:
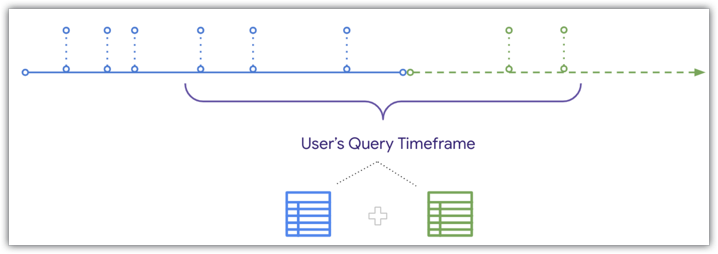
Como o Looker pode fazer UNION de dados atualizados em uma tabela agregada, se um usuário filtrar um período que se sobrepõe ao final da tabela agregada e da tabela de base, os pedidos recebidos depois da criação da tabela agregada serão incluídos nos resultados do usuário. Consulte a página de documentação Conscientização agregada para detalhes e as condições que precisam ser atendidas para unir dados atualizados a consultas de tabelas agregadas.
Resumo
Para recapitular, há três etapas fundamentais para criar uma implementação de conscientização agregada:
- Identifique oportunidades em que a otimização usando tabelas agregadas é adequada e impactante.
- Projete tabelas agregadas que ofereçam a maior cobertura para consultas comuns dos usuários, mas que ainda sejam pequenas o suficiente para reduzir o tamanho dessas consultas.
- Crie as tabelas agregadas no modelo do Looker, combinando a persistência da tabela com a persistência do cache do recurso "Explorar".