Para obtener más detalles, consulta la página de documentación de Aggregate awareness.
Introducción
En esta página, se explica cómo implementar el conocimiento de agregación en una situación práctica, lo que incluye identificar oportunidades de implementación, el valor que impulsa el conocimiento de agregación y un flujo de trabajo simple para implementarlo en un modelo real. Esta página no es una explicación detallada de todas las funciones de conciencia agregada ni de los casos extremos, ni tampoco un catálogo exhaustivo de todas sus funciones.
¿Qué es la conciencia agregada?
En Looker, la mayoría de las consultas se realizan en tablas o vistas sin procesar de tu base de datos. A veces, se trata de tablas derivadas persistentes (PDT) de Looker.
A menudo, es posible que te encuentres con conjuntos de datos o tablas muy grandes que, para tener un buen rendimiento, requieren tablas de agregación o resúmenes.
Por lo general, puedes crear tablas de agregación, como una tabla orders_daily que contenga una dimensionalidad limitada. Estos deben tratarse y modelarse por separado en Explorar, y no se ajustan bien al modelo. Estas limitaciones generan experiencias del usuario deficientes cuando el usuario debe elegir entre varios Explores para los mismos datos.
Ahora, con el conocimiento de agregaciones de Looker, puedes crear previamente tablas de agregación con varios niveles de detalle, dimensionalidad y agregación, y puedes informar a Looker cómo usarlas en los Explorar existentes. Luego, las consultas aprovecharán estas tablas de resumen cuando Looker lo considere apropiado, sin ninguna entrada del usuario. Esto reducirá el tamaño de las búsquedas, los tiempos de espera y mejorará la experiencia del usuario.
NOTA: Las tablas de agregación de Looker son un tipo de tabla derivada persistente (PDT). Esto significa que las tablas de agregación tienen los mismos requisitos de base de datos y conexión que las PDT.Para saber si tu dialecto de base de datos y tu conexión de Looker admiten PDT, consulta los requisitos que se indican en la página de documentación Tablas derivadas en Looker.
Para saber si tu dialecto de base de datos admite el reconocimiento de agregados, consulta la página de documentación Aggregate awareness.
El valor del reconocimiento agregado
Existen varias propuestas de valor significativas que agregan ofertas de reconocimiento para generar valor adicional a partir de tu modelo de Looker existente:
- Mejora del rendimiento: La implementación del conocimiento de los agregados acelerará las consultas de los usuarios. Looker usará una tabla más pequeña si contiene los datos necesarios para completar la consulta del usuario.
- Ahorro de costos: Algunos dialectos cobran según el tamaño de la consulta en un modelo de consumo. Si Looker consulta tablas más pequeñas, se reducirá el costo por consulta del usuario.
- Mejora de la experiencia del usuario: Además de una experiencia mejorada que recupera respuestas más rápido, la consolidación elimina la creación redundante de Explorar.
- Huella de LookML reducida: Reemplazar las estrategias existentes de reconocimiento de agregados basadas en Liquid por una implementación nativa y flexible genera una mayor resiliencia y menos errores.
- Capacidad de aprovechar el LookML existente: Las tablas agregadas usan el objeto
query, que reutiliza la lógica modelada existente en lugar de duplicar la lógica con SQL personalizado explícito.
Ejemplo básico
A continuación, se muestra una implementación muy simple en un modelo de Looker para demostrar lo liviana que puede ser la función de reconocimiento de agregados. Dada una tabla hipotética flights en la base de datos con una fila para cada vuelo registrado a través de la FAA, podemos modelar esta tabla en Looker con su propia vista y Explorar. A continuación, se muestra el código LookML de una tabla conjunta que podemos definir para la Exploración:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Con esta tabla agregada, un usuario puede consultar el Explorar flights y Looker aprovechará automáticamente la tabla agregada definida en LookML y la usará para responder las consultas. El usuario no tendrá que informar a Looker sobre ninguna condición especial: si la tabla se ajusta a los campos que selecciona el usuario, Looker la usará.
Los usuarios con permisos de see_sql pueden usar los comentarios de la pestaña SQL de un Explorar para ver qué tabla agregada se usará para una consulta. Este es un ejemplo de la pestaña SQL de Looker para una consulta que usa la tabla agregada flights:flights_by_week_and_carrier in teach_scratch:
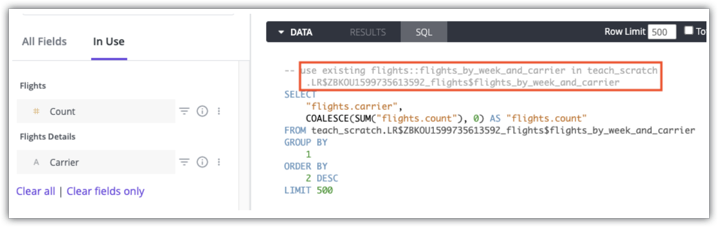
Consulta la página de documentación Aggregate awareness para obtener detalles sobre cómo determinar si se usan tablas agregadas para una consulta.
Identifica oportunidades
Para maximizar los beneficios del reconocimiento agregado, debes identificar dónde puede desempeñar un papel en la optimización o en el aumento del valor del reconocimiento agregado.
Identifica los paneles con un tiempo de ejecución alto
Una gran oportunidad para el conocimiento agregado es crear tablas agregadas para los paneles muy utilizados con un tiempo de ejecución muy alto. Es posible que tus usuarios te comenten que los paneles son lentos, pero, si tienes see_system_activity, también puedes usar el Explorar historial de actividad del sistema de Looker para encontrar paneles con un tiempo de ejecución más lento que el promedio. Como atajo, puedes usar la siguiente URL en un navegador y reemplazar HOSTNAME por el nombre de tu instancia de Looker (por ejemplo, example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=dashboard.title,dashboard.link,history.count,history.average_runtime,history.cache_result_query_count,history.database_result_query_count,query.count_of_explores&f[history.created_date]=30+days&f[dashboard.title]=-NULL%2C-Limejump+Dashboard&sorts=history.count+desc&limit=500&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22gray%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_column_widths%22%3A%7B%22dashboard.link%22%3A80%2C%22history.average_runtime%22%3A94%2C%22history.count%22%3A96%7D%2C%22series_cell_visualizations%22%3A%7B%22history.count%22%3A%7B%22is_active%22%3Afalse%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%232196F3%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22constraints%22%3A%7B%22min%22%3A%7B%22type%22%3A%22minimum%22%7D%2C%22mid%22%3A%7B%22type%22%3A%22number%22%2C%22value%22%3A0%7D%2C%22max%22%3A%7B%22type%22%3A%22maximum%22%7D%7D%2C%22mirror%22%3Atrue%2C%22reverse%22%3Atrue%2C%22stepped%22%3Afalse%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%2C%22hidden_fields%22%3A%5B%22history.cache_result_query_count%22%2C%22history.database_result_query_count%22%2C%22dashboard.link%22%5D%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22dashboard.title%22%3A%5B%7B%22type%22%3A%22%21null%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22%22%7D%2C%7B%7D%5D%2C%22id%22%3A2%2C%22error%22%3Afalse%7D%2C%7B%22type%22%3A%22%21%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Limejump+Dashboard%22%7D%2C%7B%7D%5D%2C%22id%22%3A3%2C%22error%22%3Afalse%7D%5D%7D&dynamic_fields=%5B%7B%22table_calculation%22%3A%22ratio_from_cache_vs_database%22%2C%22label%22%3A%22Ratio+from+Cache+vs+Database%22%2C%22expression%22%3A%22%24%7Bhistory.cache_result_query_count%7D%2F%24%7Bhistory.database_result_query_count%7D%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3A%22decimal_2%22%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22number%22%7D%2C%7B%22table_calculation%22%3A%22is_performing_worse_than_mean%22%2C%22label%22%3A%22Is+Performing+Worse+Than+Mean%22%2C%22expression%22%3A%22%24%7Bhistory.average_runtime%7D%3Emean%28%24%7Bhistory.average_runtime%7D%29%22%2C%22value_format%22%3Anull%2C%22value_format_name%22%3Anull%2C%22_kind_hint%22%3A%22measure%22%2C%22_type_hint%22%3A%22yesno%22%7D%5D&origin=share-expanded" rel="undefined">this System Activity History Explore link
Verás una visualización de Explorar con datos sobre los paneles de tu instancia, incluidos Título, Historial, Cantidad de exploraciones, Proporción de caché en comparación con la base de datos y ¿El rendimiento es peor que el promedio?:

En este ejemplo, hay varios paneles con un uso alto que tienen un rendimiento inferior al promedio, como el panel Sample Visualizations. El panel Sample Visualizations usa dos Exploraciones, por lo que una buena estrategia sería crear tablas agregadas para ambas.
Identifica las Exploraciones que son lentas y que los usuarios consultan con frecuencia
Otra oportunidad para generar conciencia agregada se da con los Explorar que los usuarios consultan con frecuencia y que tienen una respuesta de consulta inferior al promedio.
Puedes usar el Explorar historial de actividad del sistema como punto de partida para identificar oportunidades de optimización de los Explorar. Como atajo, puedes usar la siguiente URL en un navegador y reemplazar HOSTNAME por el nombre de tu instancia de Looker (por ejemplo, example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/history?fields=query.view,history.query_run_count,user.count,query.model,history.average_runtime&f[history.created_date]=30+days&f[history.source]=Explore&sorts=history.query_run_count+desc&limit=15&query_timezone=America%2FLos_Angeles&vis=%7B%22show_view_names%22%3Afalse%2C%22show_row_numbers%22%3Atrue%2C%22transpose%22%3Afalse%2C%22truncate_text%22%3Atrue%2C%22hide_totals%22%3Afalse%2C%22hide_row_totals%22%3Afalse%2C%22size_to_fit%22%3Atrue%2C%22table_theme%22%3A%22white%22%2C%22limit_displayed_rows%22%3Afalse%2C%22enable_conditional_formatting%22%3Atrue%2C%22header_text_alignment%22%3A%22left%22%2C%22header_font_size%22%3A%2212%22%2C%22rows_font_size%22%3A%2212%22%2C%22conditional_formatting_include_totals%22%3Afalse%2C%22conditional_formatting_include_nulls%22%3Afalse%2C%22show_sql_query_menu_options%22%3Afalse%2C%22show_totals%22%3Atrue%2C%22show_row_totals%22%3Atrue%2C%22series_labels%22%3A%7B%22user.count%22%3A%22User+Count%22%7D%2C%22series_column_widths%22%3A%7B%22query.model%22%3A179%2C%22query.view%22%3A128%7D%2C%22series_cell_visualizations%22%3A%7B%22history.query_run_count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A106%7D%2C%22user.count%22%3A%7B%22is_active%22%3Atrue%2C%22__FILE%22%3A%22system__activity%2Fcontent_activity.dashboard.lookml%22%2C%22__LINE_NUM%22%3A108%7D%7D%2C%22conditional_formatting%22%3A%5B%7B%22type%22%3A%22along+a+scale...%22%2C%22value%22%3Anull%2C%22background_color%22%3A%22%233EB0D5%22%2C%22font_color%22%3Anull%2C%22color_application%22%3A%7B%22collection_id%22%3A%22bdo%22%2C%22palette_id%22%3A%22bdo-diverging-0%22%2C%22options%22%3A%7B%22steps%22%3A5%2C%22reverse%22%3Atrue%7D%7D%2C%22bold%22%3Afalse%2C%22italic%22%3Afalse%2C%22strikethrough%22%3Afalse%2C%22fields%22%3A%5B%22history.average_runtime%22%5D%7D%5D%2C%22type%22%3A%22looker_grid%22%2C%22truncate_column_names%22%3Afalse%2C%22series_types%22%3A%7B%7D%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22history.created_date%22%3A%5B%7B%22type%22%3A%22past%22%2C%22values%22%3A%5B%7B%22constant%22%3A%2230%22%2C%22unit%22%3A%22day%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22history.source%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22Explore%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Verás una visualización de Explorar con datos sobre las Exploraciones de tu instancia, incluidos Explorar, Modelo, Recuento de ejecuciones de consultas, Recuento de usuarios y Tiempo de ejecución promedio en segundos:

En el Explorador de historial, puedes identificar los siguientes tipos de Exploradores en tu instancia:
- Exploraciones que consultan los usuarios (a diferencia de las consultas de la API o las consultas de las entregas programadas)
- Exploraciones que se consultan con frecuencia
- Exploraciones con un rendimiento bajo (en relación con otras exploraciones)
En el ejemplo anterior de Explorar el historial de actividad del sistema, los Exploradores flights y order_items son candidatos probables para la implementación de la función de conocimiento agregado.
Identifica los campos que se usan con frecuencia en las consultas
Por último, puedes identificar otras oportunidades a nivel de los datos si comprendes los campos que los usuarios suelen incluir en las búsquedas y los filtros.
Como atajo, puedes usar la siguiente URL en un navegador y reemplazar HOSTNAME por el nombre de tu instancia de Looker (por ejemplo, example.cloud.looker.com).
https://HOSTNAME/explore/system__activity/field_usage?fields=field_usage.model,field_usage.explore,field_usage.field,field_usage.times_used&f[field_usage.model]=faa%2C%22advanced_data_analyst_bootcamp%22&f[field_usage.explore]=flights%2C%22order_items%22&sorts=field_usage.times_used+desc&limit=500&query_timezone=America%2FNew_York&vis=%7B%22x_axis_gridlines%22%3Afalse%2C%22y_axis_gridlines%22%3Atrue%2C%22show_view_names%22%3Afalse%2C%22show_y_axis_labels%22%3Atrue%2C%22show_y_axis_ticks%22%3Atrue%2C%22y_axis_tick_density%22%3A%22default%22%2C%22y_axis_tick_density_custom%22%3A5%2C%22show_x_axis_label%22%3Atrue%2C%22show_x_axis_ticks%22%3Atrue%2C%22y_axis_scale_mode%22%3A%22linear%22%2C%22x_axis_reversed%22%3Afalse%2C%22y_axis_reversed%22%3Afalse%2C%22plot_size_by_field%22%3Afalse%2C%22trellis%22%3A%22%22%2C%22stacking%22%3A%22%22%2C%22limit_displayed_rows%22%3Atrue%2C%22legend_position%22%3A%22center%22%2C%22point_style%22%3A%22none%22%2C%22show_value_labels%22%3Afalse%2C%22label_density%22%3A25%2C%22x_axis_scale%22%3A%22auto%22%2C%22y_axis_combined%22%3Atrue%2C%22ordering%22%3A%22none%22%2C%22show_null_labels%22%3Afalse%2C%22show_totals_labels%22%3Afalse%2C%22show_silhouette%22%3Afalse%2C%22totals_color%22%3A%22%23808080%22%2C%22limit_displayed_rows_values%22%3A%7B%22show_hide%22%3A%22show%22%2C%22first_last%22%3A%22first%22%2C%22num_rows%22%3A%2215%22%7D%2C%22series_types%22%3A%7B%7D%2C%22type%22%3A%22looker_bar%22%2C%22defaults_version%22%3A1%7D&filter_config=%7B%22field_usage.model%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22faa%2Cadvanced_data_analyst_bootcamp%22%7D%2C%7B%7D%5D%2C%22id%22%3A0%2C%22error%22%3Afalse%7D%5D%2C%22field_usage.explore%22%3A%5B%7B%22type%22%3A%22%3D%22%2C%22values%22%3A%5B%7B%22constant%22%3A%22flights%2Corder_items%22%7D%2C%7B%7D%5D%2C%22id%22%3A1%2C%22error%22%3Afalse%7D%5D%7D&origin=share-expanded
Reemplaza los filtros según corresponda. Verás una exploración con una visualización de gráfico de barras que indica la cantidad de veces que se usó un campo en una búsqueda:
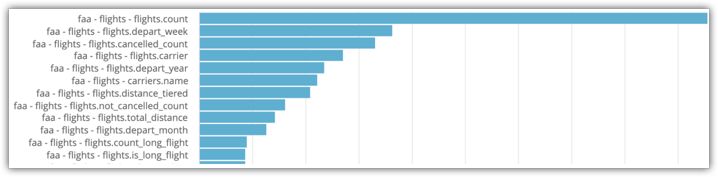
En el ejemplo de Explorador de actividad del sistema que se muestra en la imagen, puedes ver que flights.count y flights.depart_week son los dos campos que se seleccionan con mayor frecuencia para el Explorador. Por lo tanto, esos campos son buenos candidatos para incluir en las tablas de agregación.
Los datos concretos como estos son útiles, pero hay elementos subjetivos que guiarán tus criterios de selección. Por ejemplo, si observas los cuatro campos anteriores, puedes suponer con certeza que los usuarios suelen consultar la cantidad de vuelos programados y la cantidad de vuelos cancelados, y que quieren desglosar esos datos por semana y por aerolínea. Este es un ejemplo de una combinación clara, lógica y real de campos y métricas.
Resumen
Los pasos que se indican en esta página de documentación deben servir como guía para encontrar los paneles, las funciones de Explorar y los campos que se deben tener en cuenta para la optimización. También vale la pena comprender que los tres pueden ser mutuamente excluyentes: es posible que los paneles problemáticos no se basen en los Explorar problemáticos, y la creación de tablas agregadas con los campos de uso común tal vez no ayude en absoluto a esos paneles. Es posible que se trate de tres implementaciones discretas de reconocimiento agregado.
Diseña tablas de datos agregados
Después de identificar las oportunidades para el conocimiento agregado, puedes diseñar tablas agregadas que aborden mejor estas oportunidades. Consulta la página de documentación Aggregate awareness para obtener información sobre los campos, las medidas y los períodos admitidos en las tablas agregadas, así como otros lineamientos para diseñar tablas agregadas.
NOTA: Las tablas agregadas no necesitan ser una coincidencia exacta para que se use tu búsqueda. Si tu consulta tiene un nivel de detalle semanal y tienes una tabla de resumen diario, Looker usará tu tabla de agregación en lugar de tu tabla sin procesar a nivel de la marca de tiempo. Del mismo modo, si tienes una tabla agregada que se acumula hasta el nivel debrandydate, y un usuario realiza una consulta solo a nivel debrand, esa tabla sigue siendo candidata para que Looker la use para el conocimiento de los agregados.
El conocimiento de la agregación es compatible con las siguientes medidas:
- Medidas estándar: Medidas de tipo SUM, COUNT, AVERAGE, MIN y MAX
- Medidas compuestas: Son medidas de tipo NUMBER, STRING, YESNO y DATE.
- Medidas aproximadas de valores distintos: Dialectos que pueden usar la funcionalidad de HyperLogLog
El conocimiento agregado no se admite para las siguientes métricas:
- Medidas de valores distintos: Debido a que la distinción solo se puede calcular en datos atómicos y no agregados, las medidas de
*_DISTINCTno se admiten fuera de estas aproximaciones que usan HyperLogLog. - Medidas basadas en la cardinalidad: Al igual que con las medidas distintas, no se pueden agregar previamente las medianas ni los percentiles, por lo que no se admiten.
NOTA: Si conoces una posible búsqueda del usuario con tipos de medidas que no son compatibles con el conocimiento agregado, este es un caso en el que te recomendamos crear una tabla agregada que coincida exactamente con una búsqueda. Se puede usar una tabla agregada que coincida exactamente con la consulta para responder una consulta con tipos de medidas que, de otro modo, no serían compatibles con el conocimiento de agregados.
Nivel de detalle de la tabla de datos agregados
Antes de crear tablas para combinaciones de dimensiones y medidas, debes determinar patrones comunes de uso y selección de campos para crear tablas agregadas que se utilicen con la mayor frecuencia posible y tengan el mayor impacto. Ten en cuenta que todos los campos que se usen en la consulta (ya sea que se seleccionen o filtren) deben estar en la tabla de agregación para que se pueda usar la tabla en la consulta. Sin embargo, como se mencionó anteriormente, la tabla de agregados no tiene que coincidir exactamente con una consulta para que se use en ella. Puedes abordar muchas búsquedas potenciales de los usuarios en una sola tabla agregada y seguir viendo grandes aumentos en el rendimiento.
En el ejemplo de identificación de los campos que se usan con frecuencia en las consultas, hay dos dimensiones (flights.depart_week y flights.carrier) que se seleccionan con mucha frecuencia, así como dos medidas (flights.count y flights.cancelled_count). Por lo tanto, sería lógico compilar una tabla agregada que use los cuatro campos. Además, crear una sola tabla agregada para flights_by_week_and_carrier generará un uso más frecuente de la tabla agregada que dos tablas agregadas diferentes para las tablas flights_by_week y flights_by_carrier.
A continuación, se muestra un ejemplo de una tabla agregada que podríamos crear para las consultas sobre los campos comunes:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
Tus usuarios empresariales y la evidencia anecdótica, así como los datos de la actividad del sistema de Looker, pueden ayudarte en el proceso de toma de decisiones.
Equilibrio entre aplicabilidad y rendimiento
En el siguiente ejemplo, se muestra una consulta de Explore de los campos Flights Depart Week, Flights Details Carrier, Flights Count y Flights Detailed Cancelled Count de la tabla de agregados flights_by_week_and_carrier:

Ejecutar esta consulta desde la tabla de la base de datos original tardó 15.8 segundos y analizó 38 millones de filas sin ninguna unión con Amazon Redshift. Cambiar el enfoque de la búsqueda, lo que sería una operación normal del usuario, tardó 29.5 segundos.
Después de implementar la tabla de agregación flights_by_week_and_carrier, la consulta posterior tardó 7.2 segundos y analizó 4,592 filas. Esto representa una reducción del 99.98% en el tamaño de la tabla. La rotación de la consulta tardó 9.8 segundos.
En el Explorador de uso de campos de actividad del sistema, podemos ver con qué frecuencia nuestros usuarios incluyen estos campos en las consultas. En este ejemplo, flights.count se usó 47,848 veces, flights.depart_week se usó 18,169 veces, flights.cancelled_count se usó 16,570 veces y flights.carrier se usó 13,517 veces.

Incluso si estimamos de forma muy modesta que el 25% de estas búsquedas usaron los 4 campos de la manera más simple (selección simple, sin pivote), 3, 379 búsquedas x 8.6 segundos = 8 horas y 4 minutos de tiempo de espera agregado del usuario eliminados.
NOTA: El modelo de ejemplo que se usa aquí es muy básico. Estos resultados no deben usarse como comparativa ni marco de referencia para tu modelo.
Después de aplicar el mismo flujo a nuestro modelo de comercio electrónico order_items, el Explore más utilizado en la instancia, los resultados son los siguientes:
| Fuente | Tiempo de consulta | Filas analizadas |
|---|---|---|
| Tabla base | 13.1 segundos | 285,000 |
| Tabla conjunta | 5.1 segundos | 138,000 |
| Delta | 8 segundos | 147,000 |
Los campos que se usaron en la consulta y en la tabla agregada posterior fueron brand, created_date, orders_count y total_revenue, con dos uniones. Los campos se habían usado un total de 11,000 veces. Si se estima el mismo uso combinado de aproximadamente el 25%, el ahorro agregado para los usuarios sería de 6 horas y 6 minutos (8 s * 2,750 = 22,000 s). La tabla de datos agregados tardó 17.9 segundos en compilarse.
Si observas estos resultados, vale la pena detenerse un momento para evaluar los retornos que se podrían obtener de lo siguiente:
- Optimizar modelos o Exploraciones más grandes y complejos que tienen un rendimiento "aceptable" y pueden mejorar su rendimiento con mejores prácticas de modelado
versus
- Usar la conciencia agregada para optimizar modelos más simples que se usan con mayor frecuencia y tienen un rendimiento deficiente
Verás una disminución en el rendimiento de tus esfuerzos a medida que intentes obtener el último bit de rendimiento de Looker y tu base de datos. Siempre debes tener en cuenta las expectativas de rendimiento de referencia, en especial las de los usuarios empresariales, y las limitaciones que impone tu base de datos (como la simultaneidad, los umbrales de consultas, el costo, etcétera). No esperes que la conciencia agregada supere estas limitaciones.
Además, cuando diseñes una tabla de agregación, recuerda que tener más campos generará una tabla de agregación más grande y lenta. Las tablas más grandes pueden optimizar más consultas y, por lo tanto, se pueden usar en más situaciones, pero no serán tan rápidas como las tablas más pequeñas y simples.
Por ejemplo:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week,flights.distance, flights.arrival_week,flights.cancelled]
measures: [cancelled_count, count, flights.average_distance, flights.total_distance]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}Esto hará que se use la tabla agregada para cualquier combinación de dimensiones que se muestre y para cualquiera de las métricas incluidas, por lo que esta tabla se puede usar para responder muchas consultas de los usuarios diferentes. Sin embargo, para usar esta tabla en una consulta SELECT simple de carrier y count, se requeriría un análisis de una tabla de 885,000 filas. En cambio, la misma consulta solo requeriría un análisis de 4,592 filas si la tabla se basara en dos dimensiones. La tabla de 885,000 filas sigue siendo una reducción del 97% en el tamaño de la tabla (de las 38 millones de filas anteriores), pero agregar una dimensión más aumenta el tamaño de la tabla a 20 millones de filas. Por lo tanto, los retornos disminuyen a medida que incluyes más campos en tu tabla de agregación para aumentar su aplicabilidad a más consultas.
Cómo compilar tablas de datos agregados
Tomando como ejemplo la función Explorar vuelos que identificamos como una oportunidad de optimización, la mejor estrategia sería crear tres tablas agregadas diferentes para ella:
-
flights_by_week_and_carrier -
flights_by_month_and_distance -
flights_by_year
La forma más sencilla de compilar estas tablas conjuntas es obtener el LookML de la tabla conjunta de una consulta de Explorar o de un panel y agregar el LookML a los archivos de tu proyecto de Looker.
Una vez que agregues las tablas agregadas a tu proyecto de LookML y realices la implementación de las actualizaciones en producción, tus Exploraciones aprovecharán las tablas agregadas para las consultas de tus usuarios.
Persistencia
Para que sean accesibles para la detección agregada, las tablas agregadas deben persistir en tu base de datos. La práctica recomendada es alinear la regeneración automática de estas tablas agregadas con tu política de almacenamiento en caché aprovechando los grupos de datos. Debes usar el mismo grupo de datos para una tabla agregada que se usa para la Exploración asociada. Si no puedes usar grupos de datos, una opción alternativa es usar el parámetro sql_trigger_value. A continuación, se muestra un valor genérico basado en la fecha para sql_trigger_value:
sql_trigger_value: SELECT CURRENT_DATE() ;;
Esto compilará tus tablas agregadas automáticamente a la medianoche todos los días.
Lógica de período
Cuando Looker compila una tabla agregada, incluye datos hasta el momento en que se compiló la tabla agregada. Por lo general, los datos que se hayan agregado posteriormente a la tabla base de la base de datos se excluirían de los resultados de una consulta que use esa tabla agregada.
En este diagrama, se muestra la línea de tiempo de cuándo se recibieron y registraron los pedidos en la base de datos en comparación con el momento en que se creó la tabla agregada Orders. Hoy se recibieron dos pedidos que no estarán presentes en la tabla agregada Pedidos, ya que se recibieron después de que se creó la tabla agregada:

Sin embargo, Looker puede UNIR datos nuevos a la tabla de agregados cuando un usuario consulta un período que se superpone con la tabla de agregados, como se muestra en el mismo diagrama de la línea de tiempo:
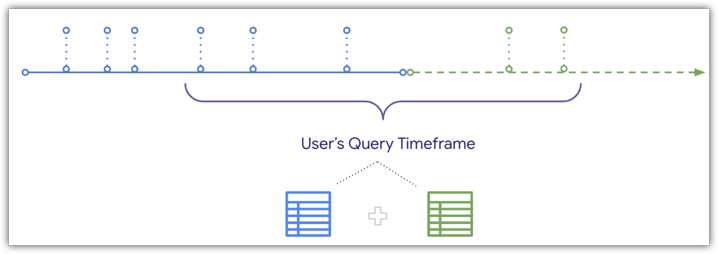
Dado que Looker puede realizar una operación UNION de datos recientes en una tabla agregada, si un usuario filtra por un período que se superpone con el final de la tabla agregada y la tabla base, los pedidos recibidos después de que se creó la tabla agregada se incluirán en los resultados del usuario. Consulta la página de documentación Aggregate awareness para obtener detalles y conocer las condiciones que se deben cumplir para unir datos nuevos a las consultas de tablas agregadas.
Resumen
En resumen, para crear una implementación de la métrica de reconocimiento agregado, debes seguir tres pasos fundamentales:
- Identificar oportunidades en las que la optimización con tablas agregadas es adecuada y tiene un gran impacto
- Diseña tablas agregadas que proporcionen la mayor cobertura para las consultas de los usuarios comunes y que, al mismo tiempo, sean lo suficientemente pequeñas como para reducir el tamaño de esas consultas.
- Compila las tablas agregadas en el modelo de Looker y vincula la persistencia de la tabla con la persistencia de la caché de Explore.